shell 编程开发
熟练的 使用 shell 编程。
author: cdxiaodong
作者: cdxiaodong
请配合上面的scripts文件夹食用 如果需要shell脚本的可以联系我。
无偿制作有趣的,关于网络安全的脚本
学习shell编程
参考:
《跟老男孩学Linux运维:Shell编程实战》
《Linux Shell核心编程实战》
目录:
[TOC]
1开始起飞
1.1脚本执行方式
1.sh文件权限 这个就不讲了
bash 和sh 可以直接执行 不行这样的话直接chmod 777
2.开启子进程执行的方式
关于是否开启子进程,我们首先要了解什么是子进程,一般可以通过pstree命令来查看进程树,了解进程之间的关系。

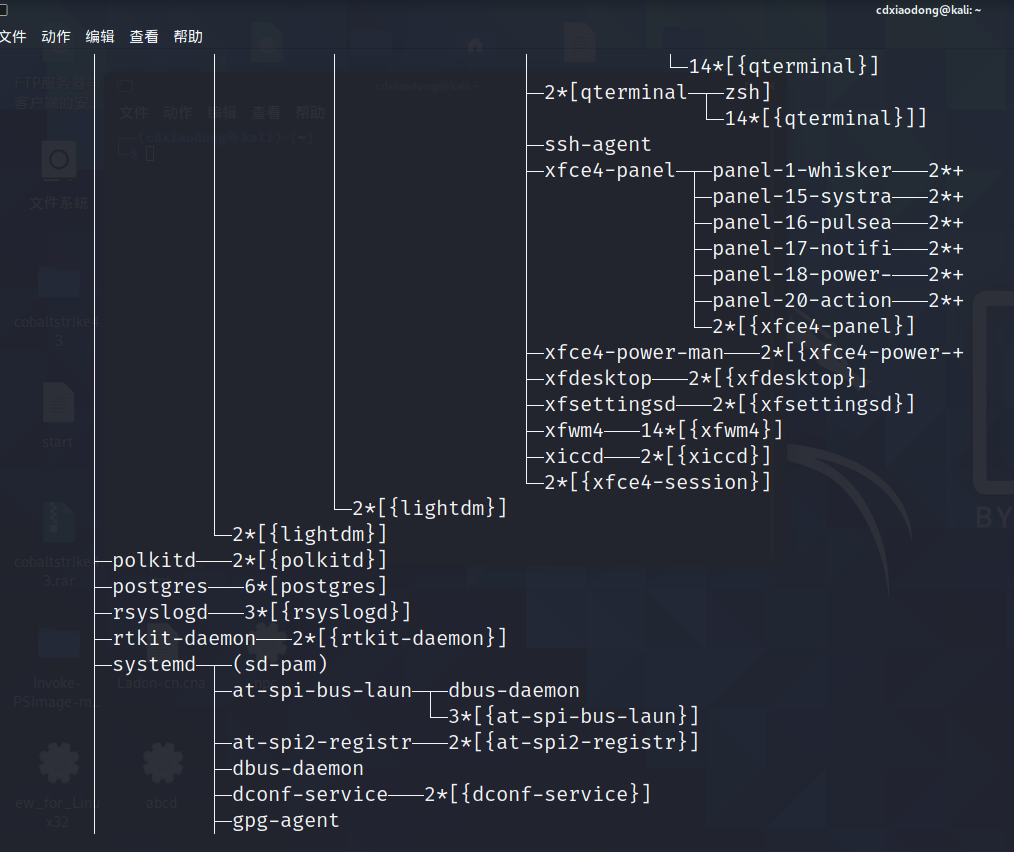
通过以上输出,我们可以看到计算机启动的第一个进程是systemd,然后在这个进程下启动了N个子进程,如NetworkManager、atd、chronyd、sshd这些都是systemd的子进程。而在sshd进程下又有2个sshd的子进程,在2个sshd子进程下又开启了bash解释器子进程,而且在其中一个bash进程下面还执行了一条pstree命令。对于刚才我们说的不管是直接执行脚本,还是使用bash或sh这样的解释器执行脚本,都是会开启子进程的。
下面通过一个脚本文件演示效果
首先,打开一个命令终端,在该命令终端中编写脚本文件,并执行脚本文件。
然后,开启一个命令终端,在这个终端中通过pstree命令观察进程树。

通过输出可以看到,在bash终端下开启了一个子进程脚本文件,通过脚本文件执行了一条sleep命令。
回到第一个终端,使用Ctrl+C组合键终止前面执行的脚本文件,使用bash命令再次执行该脚本。

最后,在第二个终端上使用pstree命令观察实验结果。

结果类似,在bash进程下开启了一个bash子进程,在bash子进程下执行了一条sleep命令。
3.不开启子进程的执行方式
下面我们来看看不开启子进程的执行方式的案例,与之前的实验类似,我们需要开启两个命令终端。
首先,打开第一个终端,这次使用source或.(点)命令来执行脚本文件。

或者

然后,我们再打开第二个终端,通过pstree命令观察结果。
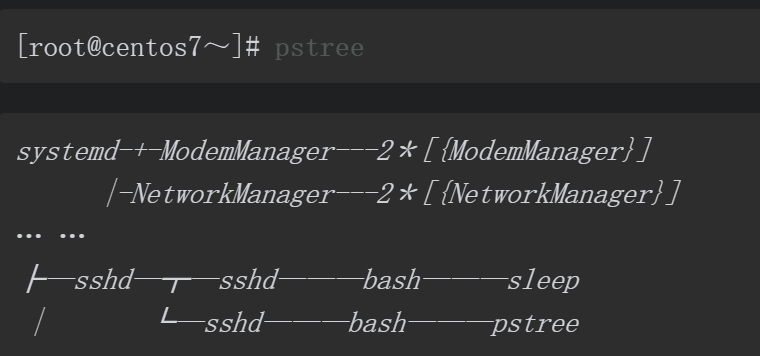
通过实验结果可以看到,脚本文件中的sleep命令是直接在bash终端下执行的。最后,我们编写一个特殊的脚本文件,内容如下。

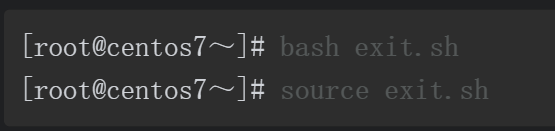
你可能已经发现了,source命令不开启子进程执行脚本文件会导致整个终端被关闭
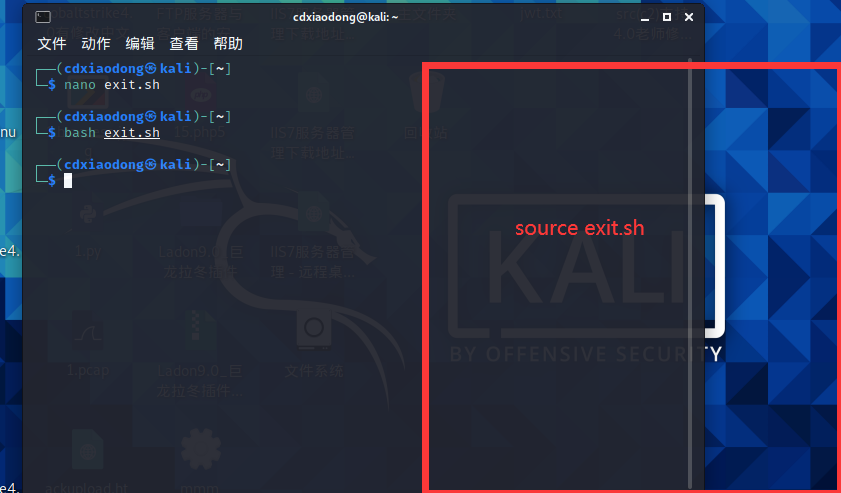
这是因为 source exit.sh的话是不开启子进程来运行的,也就是在此命令窗里面运行,
所以直接执行的exit 导致命令窗口退出。
1.2如何在脚本文件中实现输入于输出
1.使用echo命令创建一个脚本文件菜单
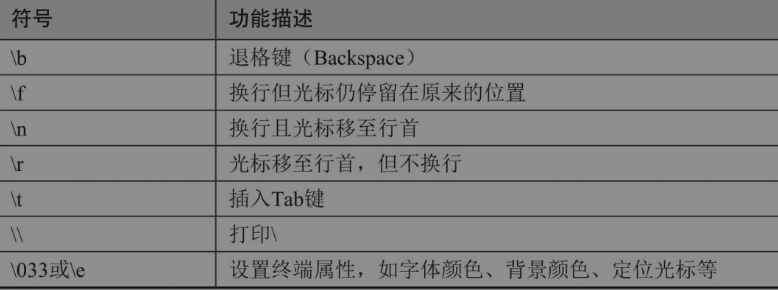
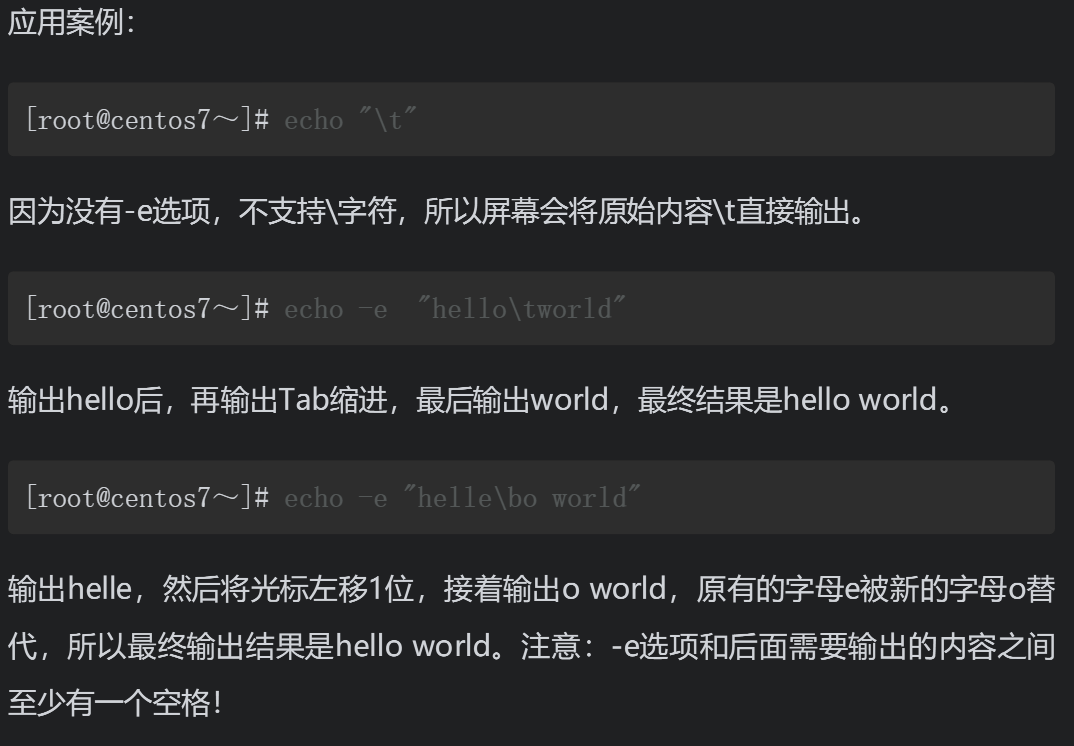
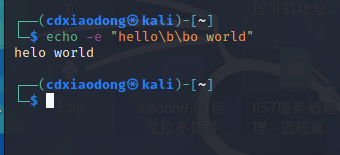
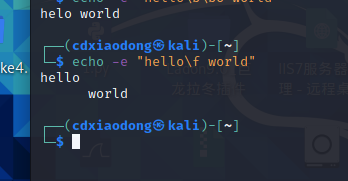
输出hello,换行但光标仍旧停留在原来的位置,也就是字母o后面的这个位置,然后输出world。
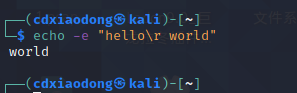
\r会让光标返回行首
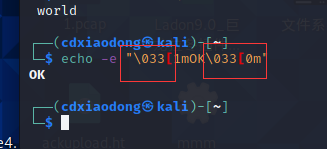
加粗显示OK, \033或\e后面跟不同的代码可以设置不同的终端属性,1m是让终端粗体显示字符串,后面的OK就是需要显示的字符串内容,最后\033[0m是在加粗输出OK后,关闭终端的属性设置。如果最后没有使用0m关闭属性设置,则之后终端中所有的字符串都使用粗体显示。执行下面这条命令后,会发现除了OK加粗显示,后面在终端中输出的所有字符串都加粗显示。

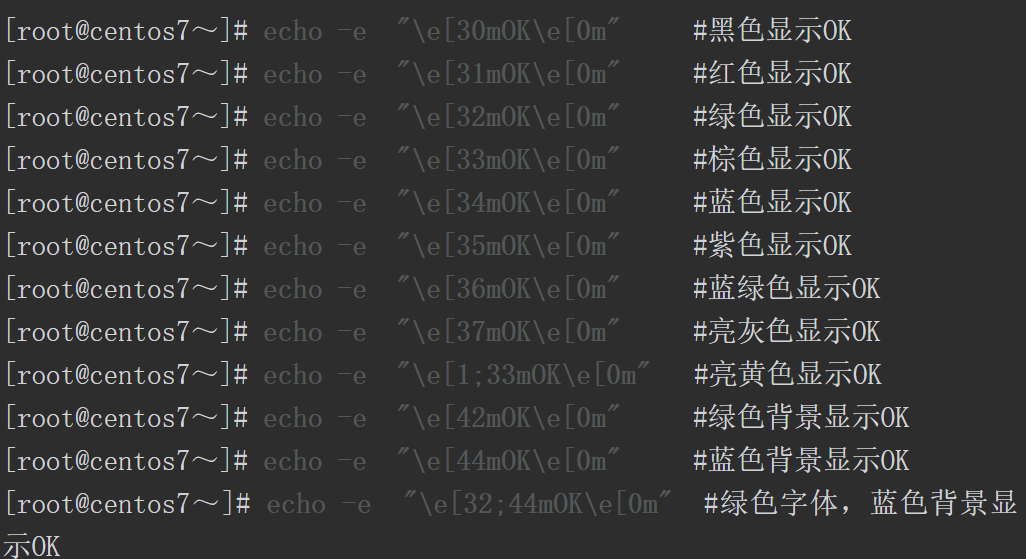
除了可以定义终端的字体颜色、样式、背景,还可以使用H定义位置属性。例如,可以通过下面的命令在屏幕的第3行、第10列显示OK。
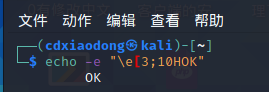

在看透第三行显示ok
最后,我们使用echo命令编写一个更有趣的脚本文件菜单!下面这个脚本文件,首先使用clear命令将整个屏幕清空,然后使用echo命令设置终端属性,打印了一个有颜色、有排版的个性化菜单。至于具体的颜色搭配,各位读者可以根据自己的需求进行个性化设计。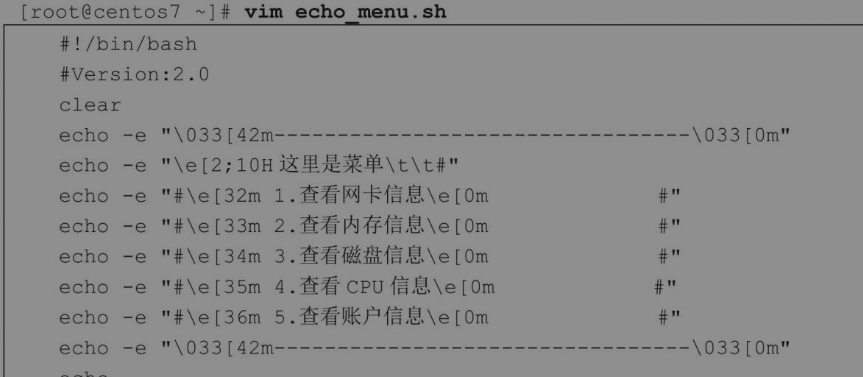
2.扩展知识,使用printf命令创建一个脚本菜单Linux系统中除了echo命令可以输出信息,还可以使用printf命令实现相同的效果。
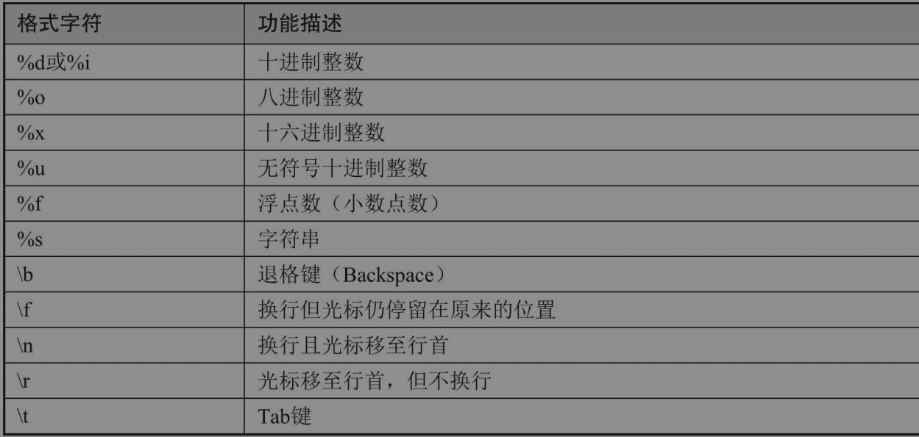
功能描述:printf命令可以格式化输出数据。
printf命令的语法格式如下。

应用案例
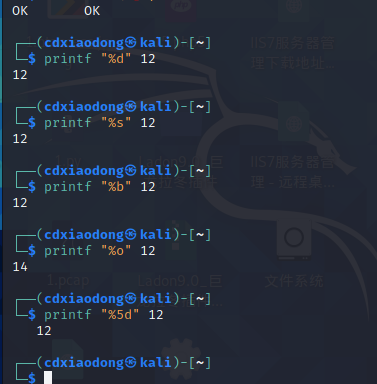
左对齐输出12,输出的内容占用10个字符宽度,12占用2个字符宽度,后面跟了8个空格位置。默认printf命令输出内容后不会换行,使用\n命令符可以在输出内容后换行。

类似于echo、
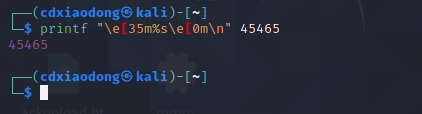
只不过利用编程语言的特性 将45465用%secho进去
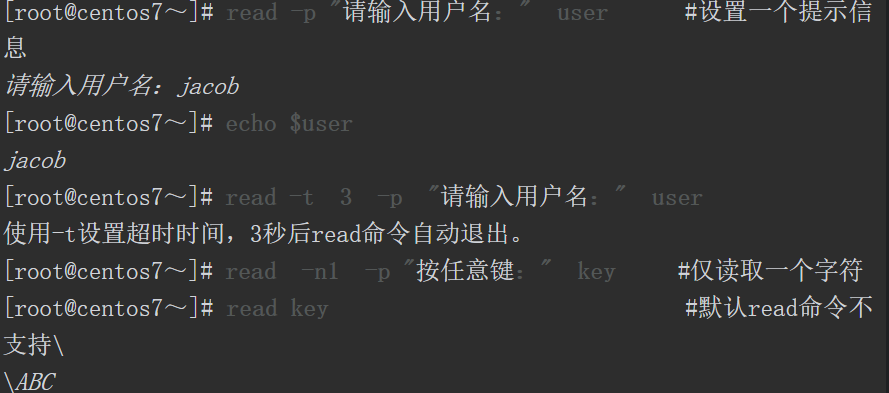
3.使用read命令读取用户的输入信息
前面我们学习了在Shell脚本中实现输出数据的方法,接下来探讨如何解决输入的问题,在Shell脚本中允许使用read命令实现数据的输入功能。
功能描述:read命令可以从标准输入读取一行数据。
read命令的语法格式如下。

如果未指定变量名,则默认变量名称为REPLY。read命令常用的选项如下所示。

从标准输入中读取数据,这里通过键盘输入了123, read命令则从标准输入读取这个123,并将该字符串赋值给变量key1,对于key1这个变量,我们可以使用echo$key1显示该变量的值。
应用案例:

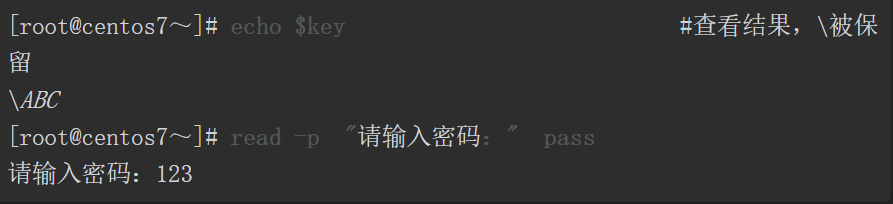
注意,这里提示输入密码后,当用户输入密码123时,计算机将密码的明文显示在屏幕上,这不是我们想看到的效果!怎么办?read命令支持-s选项,这个选项可以让用户输入的任何数据都不显示,但read命令依然可以读取用户输入的数据,只是数据不显示而已。
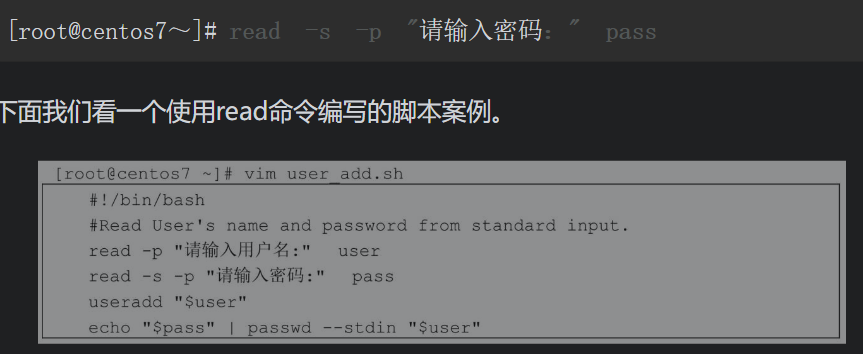
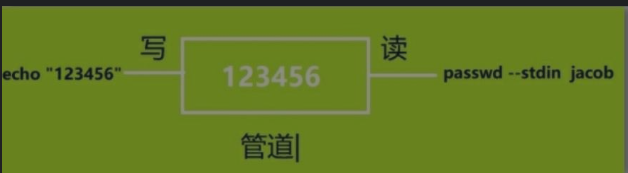
这个脚本通过read命令读取用户输入的用户名和密码,并且在读取用户输入的密码时,不直接在屏幕上显示密码的内容,这样更安全。用户输入的用户名和密码分别保存在user和pass这两个变量中,下面就通过$调用变量中的值,使用useradd命令创建一个系统账户,使用passwd命令给用户配置密码。直接使用passwd修改密码默认采用人机交互的方式配置密码,需要人为手动输入密码,并且要重复输入两次。这里我们使用了一个|符号,这个符号就像管道,它的作用是将前一个命令的输出结果,通过管道传给后一个命令,作为后一个命令的输入。
有时候,在Linux系统中我们需要完成一个复杂的任务,但是某一个命令可能无法完成这个任务,此时,我们就需要使用管道把两个或多个命令组合在一起来完成这样的任务。
如图下所示,类似于传输水的管道,Linux系统的管道,可以将命令1的输出结果(数据),存储到管道中,然后让命令2从管道中读取数据,并对数据做进一步的处理。

下面我们看几个管道的案例。

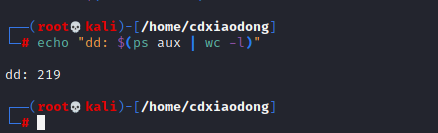
who这条命令,可以帮助我们查看有哪些账户在什么时间登录了计算机。但是,当计算机的登录信息非常多时,需要人为记录登录的数量就很不方便,而Linux系统中的wc命令可以统计行数,但wc命令是需要数据的,给wc若干行数据,这个命令就可以自动统计数据的行数。我们可以使用管道将who和wc命令结合在一起使用。
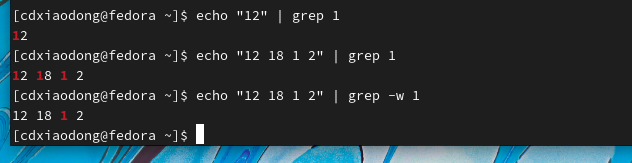
ss命令可以查看Linux系统中所有服务监听的端口列表。但是ss命令自身没有灵活的过滤功能,而grep命令有比较强大灵活的过滤功能,这样的话也可以通过管道将这两个命令结合在一起使用。
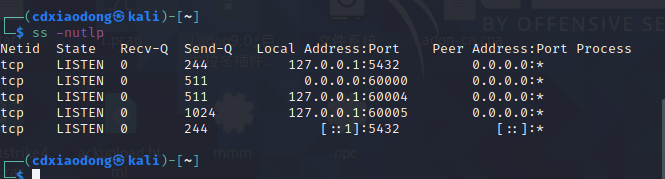
配合grep使用
再比如,ss命令可以查看Linux系统中所有服务监听的端口列表。但是ss命令自身没有灵活的过滤功能,而grep命令有比较强大灵活的过滤功能,这样的话也可以通过管道将这两个命令结合在一起使用。

很明显,没有使用grep命令过滤的数据量比较多,看起来不够清晰,而ss命令把自己输出的数据存入管道后,grep命令再从管道中读取数据,在众多数据中过滤出包含sshd的数据行,最后输出结果就只有两行数据。这样能比较简单明了地看到我们需要的数据。
很明显,没有使用grep命令过滤的数据量比较多,看起来不够清晰,而ss命令把自己输出的数据存入管道后,grep命令再从管道中读取数据,在众多数据中过滤出包含sshd的数据行,最后输出结果就只有两行数据。这样能比较简单明了地看到我们需要的数据。

echo命令默认会把输出结果显示在屏幕上,而有了管道后,echo命令可以把输出的123456存储到管道中,passwd再从管道中读取123456,来修改系统账户jacob的密码。
1.3输入与输出的重定向
这个反弹shell学习的时候有相关接触过
在大多数系统中,一般会默认把输出信息显示在屏幕上,而标准的输入信息则通过键盘获取。但在编写脚本时,当有些命令的输出信息我们不能或不希望显示在屏幕上(脚本执行时,大量的输出信息反而会让用户感到迷茫)。此时,不如先把输出的信息暂时写入文件中,后期需要时,再读取文件,提取需要的信息。对于默认的标准输入信息也会有类似的问题,在Linux系统中当我们使用mail命令发送邮件时,程序需要读取邮件的正文,默认通过读取键盘的输入数据作为正文,这样会让脚本进入交互模式,因为读取键盘信息是需要人为手动输入的。此时,如果能改变默认的输入方式,不再从键盘读取数据,而是从提前准备好的文件中读取数据,就可以让mail程序在需要时自动读取文件内容,自动发送邮件,而不需要人为的手动交互。这样脚本的自动化效果会更好。
在Linux系统中输出可以分为标准输出和标准错误输出。标准输出的文件描述符为1,标准错误输出的文件描述符为2。而标准输入的文件描述符则为0。
如果希望改变输出信息的方向,可以使用>或>>符号将输出信息重定向到文件中。使用1>或1>>可以将标准输出信息重定向到文件(1可以忽略不写,默认值就是1),也可以使用2>或2>>将错误的输出信息重定向到文件。这里使用>符号将输出信息重定向到文件,如果文件不存在,则系统会自动创建该文件,如果文件已经存在,则系统会将该文件的所有内容覆盖(原有数据会丢失!)。而使用>>符号将输出信息重定向到文件,如果文件不存在,则系统会自动创建该文件,如果文件已经存在,则系统会将输出的信息追加到该文件原有信息的末尾。
下面的例子中,echo命令本来会将数据输出显示在屏幕上,但如果使用重定向后就可以将输出的信息导出到文件中。
如果一条命令既有标准输出(正确输出),又有错误输出,该如何重定向呢?
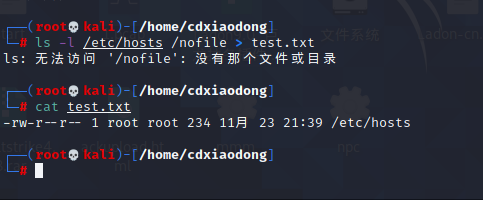
只重定向标准输出 不重定向错误输出
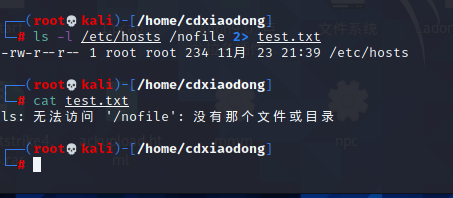
只重定向错误输出 不重定向标准输出
其实,我们可以将标准输出和错误输出分别重定向到不同的文件,也可以同时将它们重定向到相同的文件。
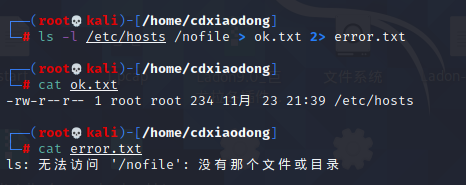
使用&>符号可以同时将标准输出和错误输出都重定向到一个文件(覆盖),也可以使用&>>符号实现追加重定向。
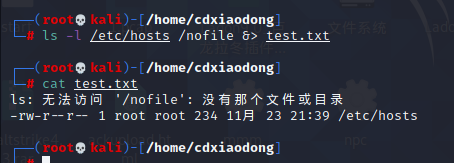
最后,我们还可以使用2>&1将错误输出重定向到标准正确输出,也可以使用1>&2将标准正确输出重定向到错误输出。
下面的命令虽然都在屏幕上显示了结果。第一条命令虽然是报错信息,却是从标准正确的通道显示在屏幕上的。而第二条命令虽然原本没有错误信息,但通过将正确信息重定向到错误输出,最后的hello是通过错误输出的通道显示在屏幕上的。
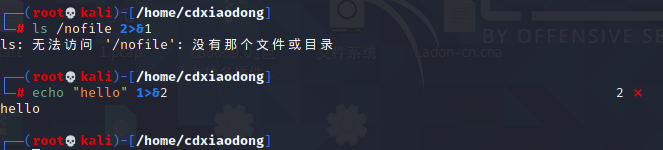
是ls命令对比。正常情况下,因为系统没有/nofile文件,所以ls命令会报错,报错信息会通过错误输出的通道传递给显示器。但当我们使用2>&1命令时,就会把错误信息重定向到标准正确输出,虽然屏幕最终也会显示报错信息,却是通过标准输出通道传递给显示器的。

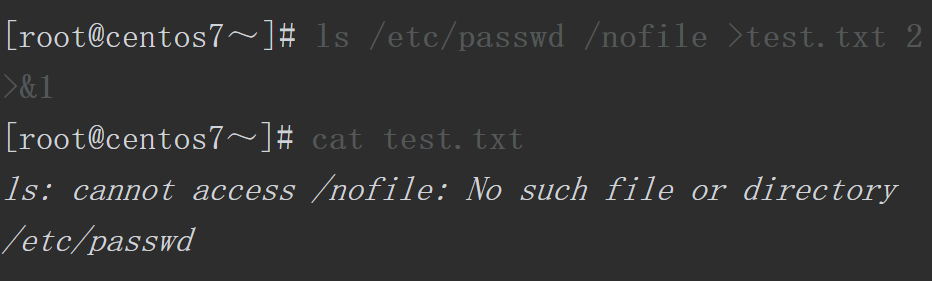
正常情况下,echo命令会通过标准输出将消息显示在屏幕上。而当我们使用1>&2时,系统就会把正确的输出信息重定向到错误输出,虽然屏幕上最终也显示了hello,却是通过错误输出通道传递给显示器的。

结合这种特殊的重定向方式,我们还可以将标准输出重定向到文件,然后将错误输出重定向到标准正确输出。最终把正确的和错误的信息都导入文件中,如下所示。

Linux系统中有一个特殊的设备/dev/null,这是一个黑洞。无论往该文件中写入多少数据,都会被系统吞噬、丢弃。如果有些输出信息是我们不再需要的,则可以使用重定向将输出信息导入该设备文件中。注意:数据一旦导入黑洞将无法找回。
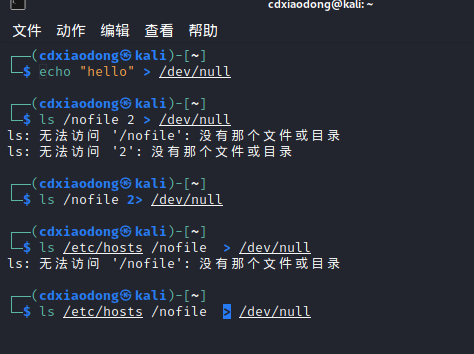
除了可以对输出进行重定向,还可以对输入进行重定向。默认标准输入为键盘鼠标。但键盘需要人为的交互才可以完成输入。比如下面的mail命令,执行完命令后程序就会进入等待用户输入邮件内容的状态,只要用户不输入内容,并使用独立的一行点表示邮件内容结束,mail程序就会一直停留在该状态。
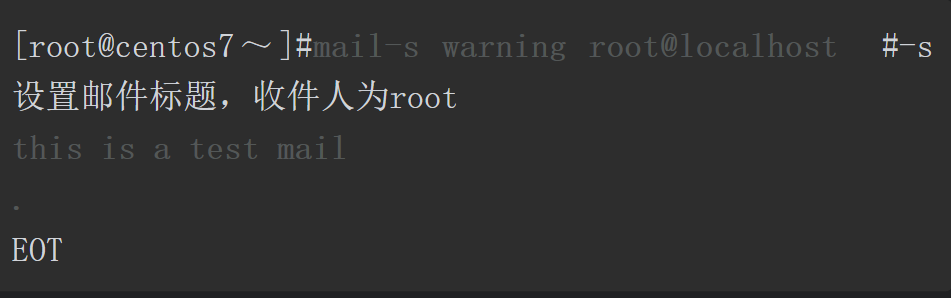
以上所有邮件正文都需要人工手动输入,而未来当我们需要使用脚本自动发送邮件时,这就存在问题。为了解决这个问题,我们可以使用<符号进行输入重定向。<符号后面需要跟一个文件名,这样可以让程序不再从键盘读取输入数据,而从文件中读取数据。
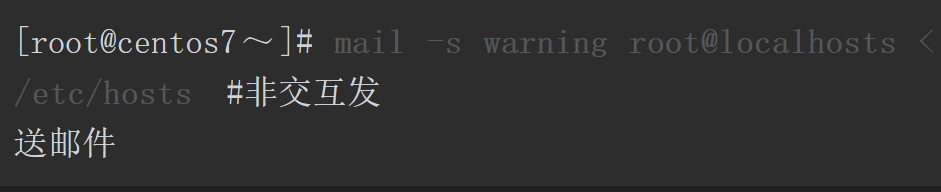
如果我们希望自动非交互地发送邮件,而又没有提前准备文件,可以吗?
可以使用<<符号实现相同的效果。这样脚本就不需要依赖邮件内容的文件即可独立运行。使用<<符号可以将数据内容重定向传递给前面的一个命令,作为命令的输入。
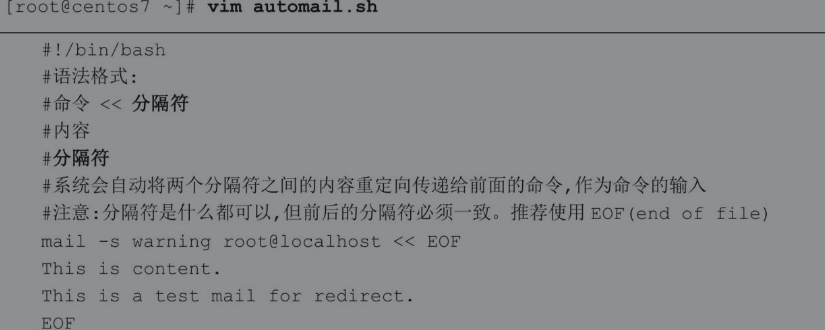
<<符号(也被称为Here Document)代表你需要的内容在这里。下面看一个cat通过Here Document读取数据,再通过输出重定向将数据导出到文件的例子。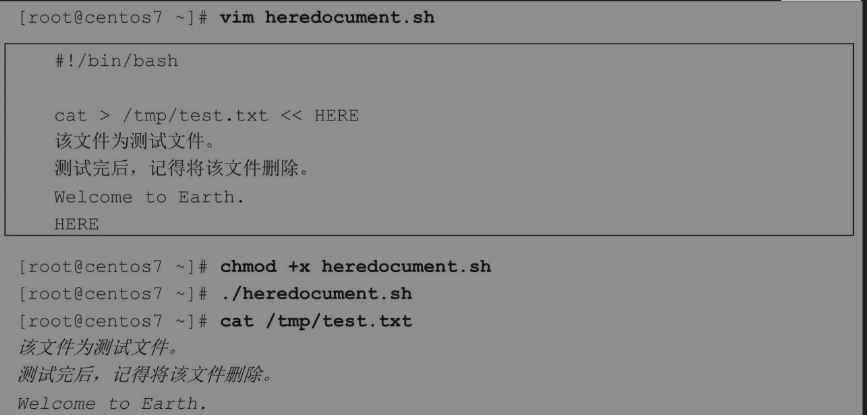
在Linux系统中经常会使用fdisk命令对磁盘进行分区,但该命令是交互式的,而我们现在需要编写脚本实现自动分区、自动格式化、自动挂载分区等操作。针对这种问题,也可以通过HereDocument来解决。下面我们来编写一个这样的自动分区脚本。

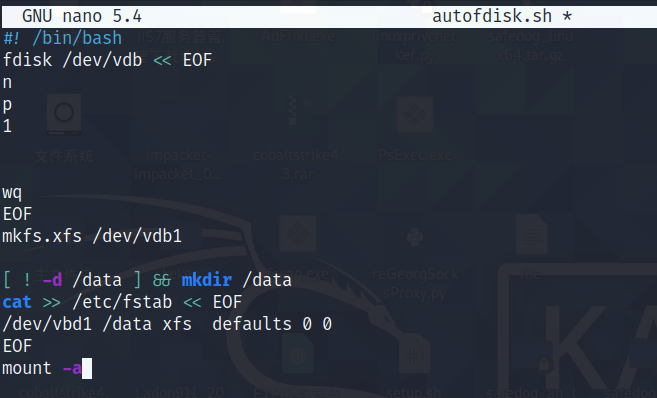
分析一下里面的各个指令:
1 | |
1 | |
EOF配合cat支持多行字符输出
在编写脚本时为了提高代码的可读性,往往需要在代码中添加额外的缩进。然而,使用<<将数据导入程序时,如果内容里面有缩进,则连同缩进的内容都会传递给程序。而此时的Tab键仅仅起缩进的作用,我们并不希望传递给程序。如果需要,可以使用<<-符号重定向输入的方式实现,这样系统会忽略掉所有数据内容及分隔符(EOF)前面的Tab键。使用这种方式仅可以忽略Tab键,如果Here Document的正文内容有空格缩进,则无效。

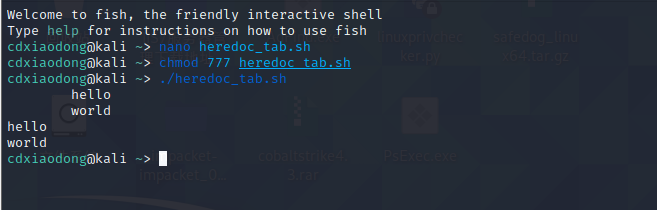
总结: 2是错误1是对 &在>前是输入 &在>后是输出
1.4各种引号的正确使用
1)单引号与双引号
在编写脚本时我们经常需要用到引号,而Shell支持多种引号,如””(双引号)、’’(单引号)、``(反引号)、\(转义符号)。这么多的符号,都是在什么情况下使用的呢?下面我们看几个案例。

创建a b c三个文件

创建一个名为a b c的文件
这里可以看出双引号的作用是引用一个整体,计算机会把引号中的所有内容当作一个整体看待。而不使用双引号时,创建的是三个不同的文件。当后期需要删除文件时,也会出现类似的问题。
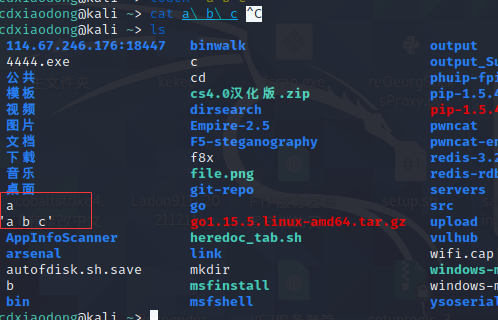
这样的输出结果很容易让人误解,这里到底有几个文件?文件名到底是什么?
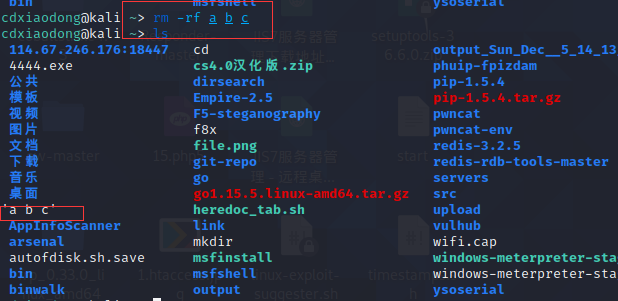

因为这里没有使用双引号,所以系统理解的是需要删除a、b和c这三个文件,但其实现在系统中没有这三个文件,而只有一个文件,名称为“a b c”,其中空格也是文件名的一部分,这个文件应怎么删除呢?

通过使用双引号,成功删除了这个文件。在Linux系统中,除了可以使用双引号引用一个整体,还可以使用单引号引用一个整体,同时单引号还有另外一个功能,即可以屏蔽特殊符号(将特殊符号的特殊含义屏蔽,转化为字符表面的名义)
上面两条命令因为没有特殊符号,所以使用双引号或单引号的作用是一样的。但是,当有特殊符号时,单引号和双引号不能互换,比如下面的例子。

在Shell中,#符号有特殊含义,是注释符号。#符号及#符号后面的内容都会被程序理解为注释,而不会被执行,这条命令本来想通过屏幕输出一个#符号,但实际的输出结果却是空白行。如果我们希望输出这个#号,则可以使用单引号,将#符号的特殊含义屏蔽掉。
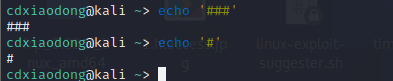
另外,在Shell中$符号有提取变量值的特殊含义,而当我们需要直接使用$这个符号时,也需要使用单引号的屏蔽功能。

其实,在Linux中具有屏蔽功能的除单引号外,还有\符号,虽然\符号也可以实现屏蔽转义的功能,但\符号仅可以转义其后面的第一个符号,而单引号可以屏蔽引号内所有的特殊符号
2)命令替换
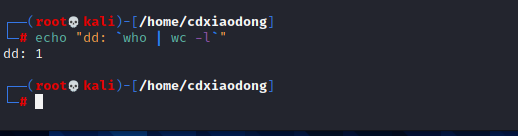
最后,我们来了解``符号(反引号),反引号是一个命令替换符号,它可以使用命令的输出结果替代命令,下面我们看一个例子。

使用上面这条命令可以把/var/log目录下的所有数据备份到/root目录下,但是备份的文件名是固定的。如果需要系统执行计划任务,实现在每周星期五备份一次数据,然后新的备份就会把原有的备份文件覆盖(因为文件名是固定的)。到最后发现其实仅备份了最后一周的数据,前面的所有数据全部丢失!怎么解决这个问题呢?

这条命令依然使用tar命令进行备份。但是,因为使用了``符号实现命令替换,所以这里备份的文件名不再是date,而是date命令执行后的输出结果,即使用命令的输出结果替换date命令本身的字符串,最后备份的文件名类似log-20180725.tar.gz。文件名中具体的时间根据执行命令时的计算机系统时间而定。再看几个例子。

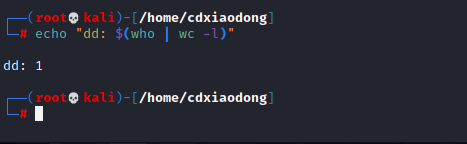
反引号虽然很好用,但也有其自身的缺陷,比如容易跟单引号混淆,不支持嵌套(反引号中再使用反引号),为了解决这些问题,人们又设计了$()组合符号,功能也是命令替换,而且支持嵌套功能,如下面的这些案例所示。
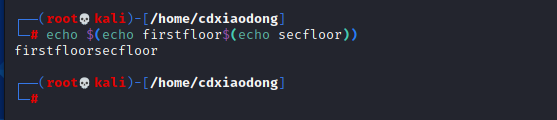
$与(中间不要有空格哦,不然会这样
1.5变量
变量名示例
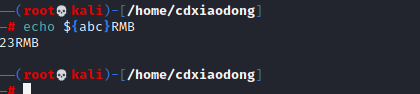
其次,当需要读取变量值时,需要在变量名前添加一个美元符号“$”;而当变量名与其他非变量名的字符混在一起时,需要使用{}分隔。
最后,如果需要取消变量的定义,则可以使用unset命令删除变量。
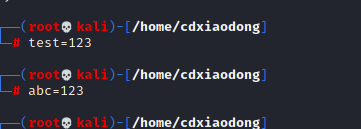
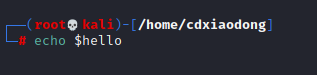
上面这条命令的返回值为空,因为没有定义一个名称是hello的变量,而且实际需要输出的应该是123hello。此时就需要使用{}分隔变量名和其他字符。
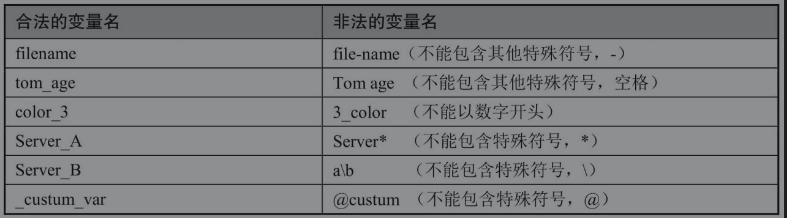
虽然这三条命令都没有使用{}分隔变量名与其他字符,但最后返回值也不为空白,因为Shell变量名称仅可以由字母、数字、下画线组成,不可能包括特殊符号(如横线、冒号、空格等),所以系统不会把特殊符号当作变量名的一部分,系统会理解变量名为test,后面是其他跟变量名无关的字符串。下面我们看一个简单的使用变量的案例。

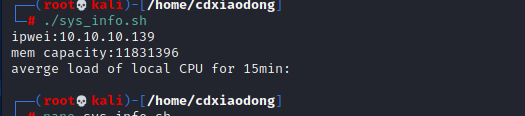
1 | |
这个脚本中定义了三个变量,三个变量值都是命令的返回结果,因此每次执行脚本时变量值都有可能发生变化。但是,不管变量值怎么变化,脚本都可以在最后正常地输出这些变量值

将多个a合并为一个a
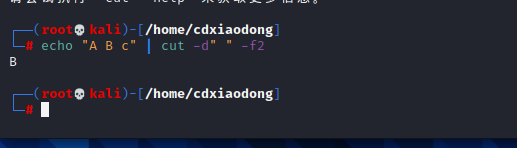
以空格为分隔符 获取第二列
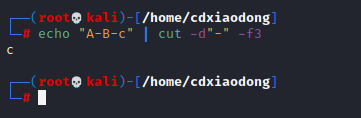
以-为分隔符 获取第三列
上面介绍的是用户自定义变量,接下来了解系统预设变量。系统预设变量,顾名思义就是系统已经预先设置好的变量,不需要用户自己定义便可以直接使用的变量。系统预设变量基本都是以大写字母或使用部分特殊符号为变量名[插图]。表1-5中列举了系统中常见的系统预设变量。

系统预设变量可以细分为:环境变量、位置变量、预定义变量、自定义变量。在实际编写脚本时能够在合适的地方应用合适的变量即可,这里不再细化讲解。
编写脚本案例并调用这些系统预设变量,查看执行效果。
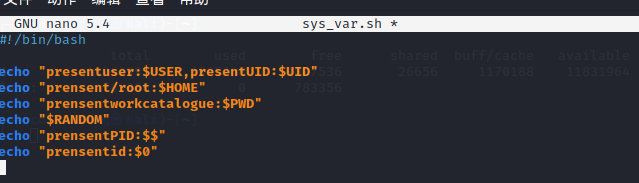
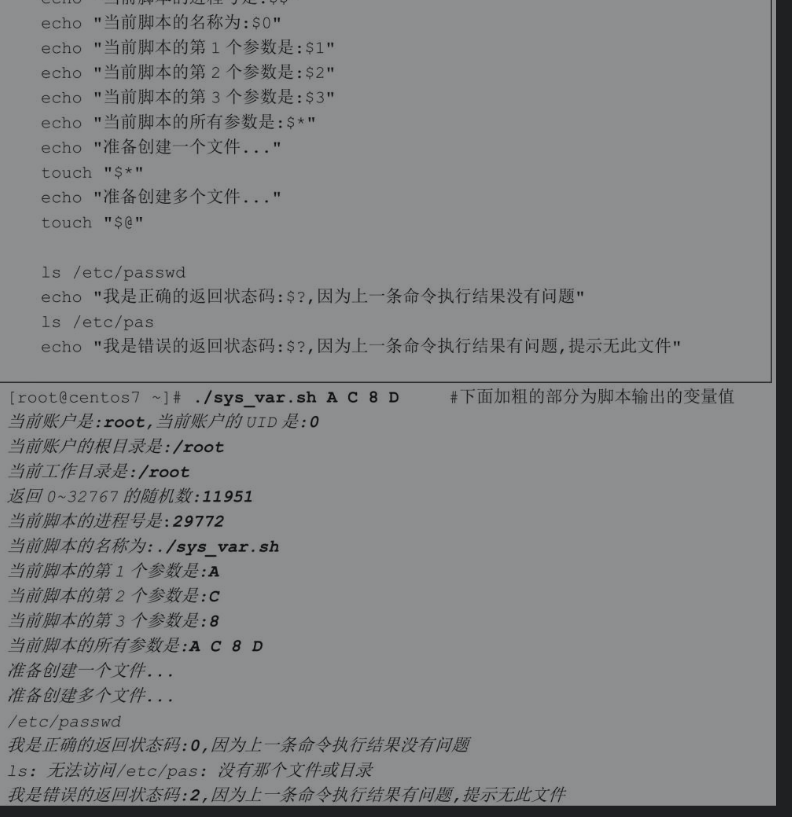
因为“$*”将所有参数视为一个整体,因此创建了一个名称为“AC 8 D”的文件,空格也是文件名的一部分。而“$@”将所有参数视为独立的个体,因为touch名称创建了4个文件,分别是A、C、8、D,使用ls -l命令可以查看得更清楚。
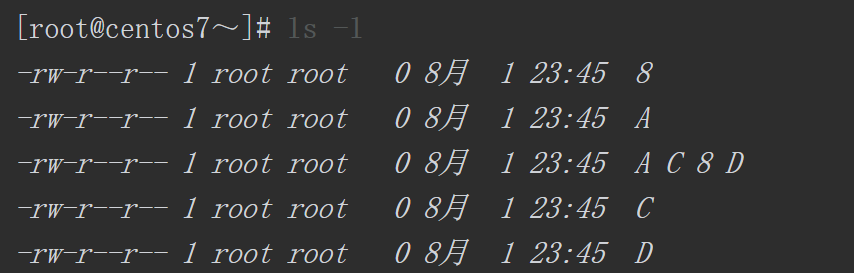
$? ”返回上一条命令的退出状态代码,脚本中先执行ls/etc/passwd,当这个命令被正确地执行后,“$0”返回的结果为0。而当执行ls /etc/pass命令时,因为pass文件不存在,所以该命令报错无法找到该文件。此时,“$? ”返回的退出状态码为2(正确为0,错误为非0,但根据错误的情况不同,每个程序返回的具体数字也会有所不同)。
1.6数据过滤与正则表达式
grep

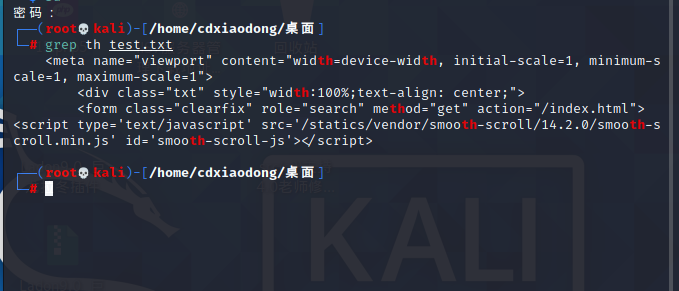
在test.txt文件中过滤包含th关键词的行
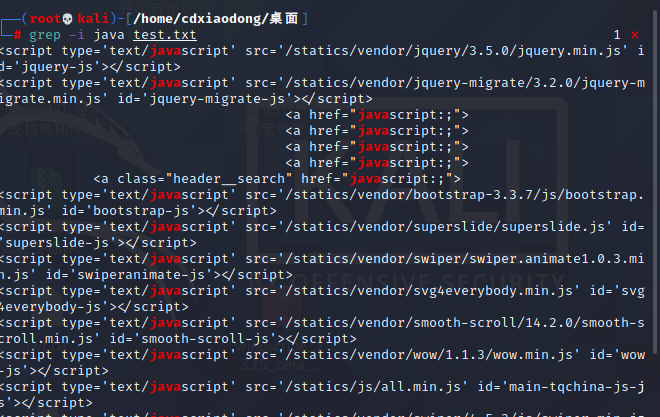
在txt文件中查找包含java的行
正则表达式
这个东西不是看一遍就会了
我之前也为此看了一整本书 但是还是不会
实战利用才是解决记忆的方法

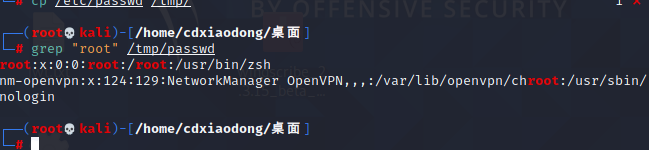
匹配含有root的行
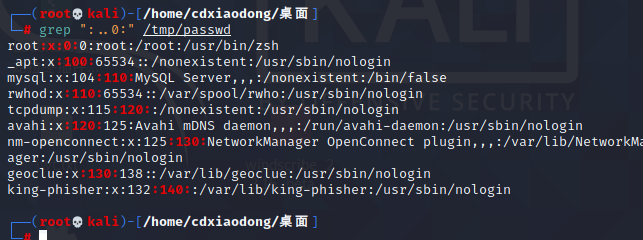
查找与“0:”之间包含任意两个字符的字符串,并且显示改行
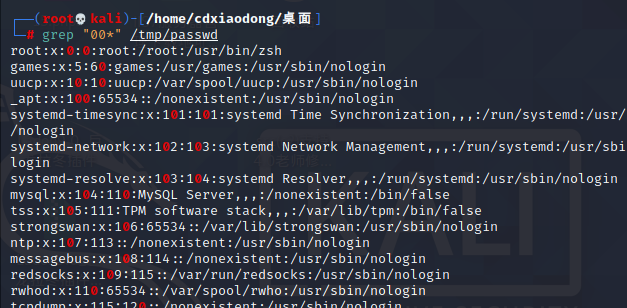
查找至少一个0的行 (第一个必须出现 第二个可以出现0或多次)

查找含有oot或者ost的行
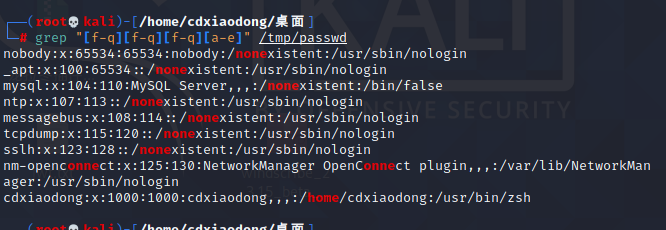
查找包含四个字符按照上述排列的行
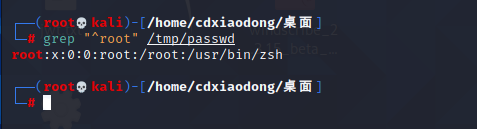
查找以root开头的行

查找以bash结尾的行
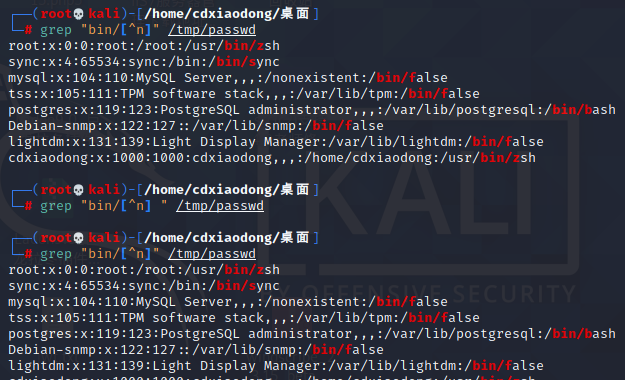
查找bin后面不跟n的行
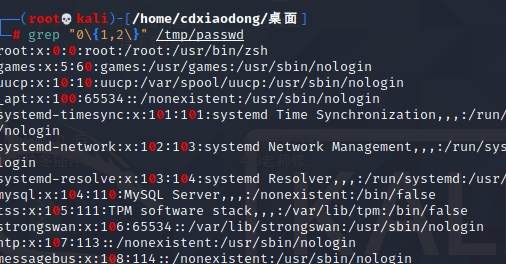
查找0最少一次最多两次的行
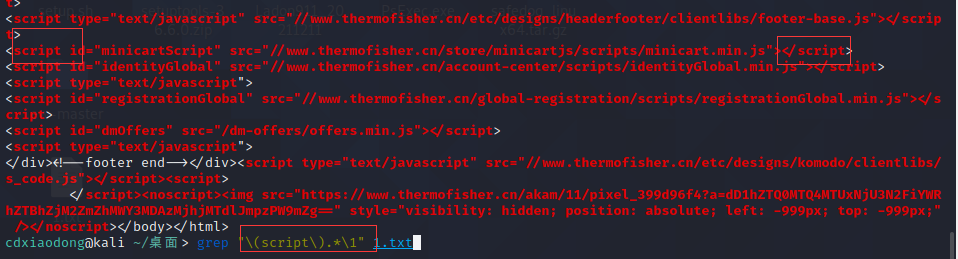
grep “(script).*\1” 1.txt
查找两个root之间可以是任意字符的行。注意:这里用\ (root\)
将root保留、后面\1再次调用root,相当与前面复制root 后面粘贴root


自动去掉文件空白行 注意记得在$前添加\ 不然无法执行


过滤文件的非空白行
font color = ‘yellow’>扩展正则表达式

再看几个使用扩展正则表达式的案例,由于输出信息与基本正则表达式类似,这里仅写出命令而不再打印输出信息。另外grep命令默认不支持扩展正则表达式,需要使用grep -E或者使用egrep命令进行扩展正则表达式的过滤。
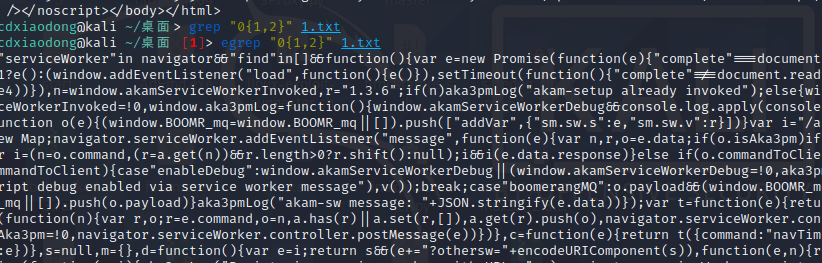

找出0出现1此或者两次的行

小写的e不行
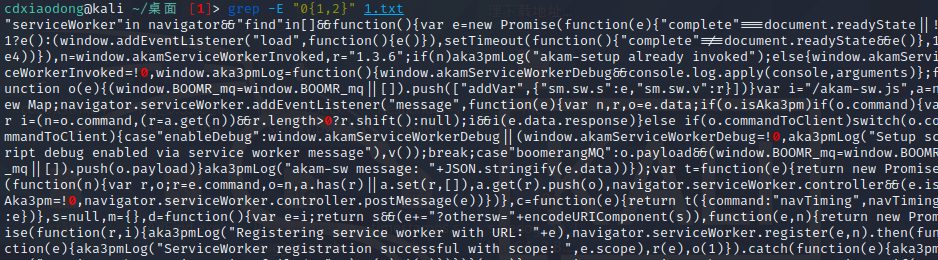
直接查找至少一个0的行
POSIX规范的正则表达式
由于基本正则表达式会有语系的问题,所以这里需要了解POSIX规范的正则表达式规则。例如,在基本正则表达式中可以使用a~z来匹配所有字母,但如果需要匹配的对象是中文字符怎么办呢?或是像“ن”这样的阿拉伯语字符怎么办?所以使用a~z匹配仅针对英语语系中的所有字母,POSIX其实是由一系列规范组成的,这里仅介绍POSIX正则表达式规范。POSIX正则表达式规范帮助我们解决语系问题,另外POSIX规范的正则表达式也比较接近于自然语言

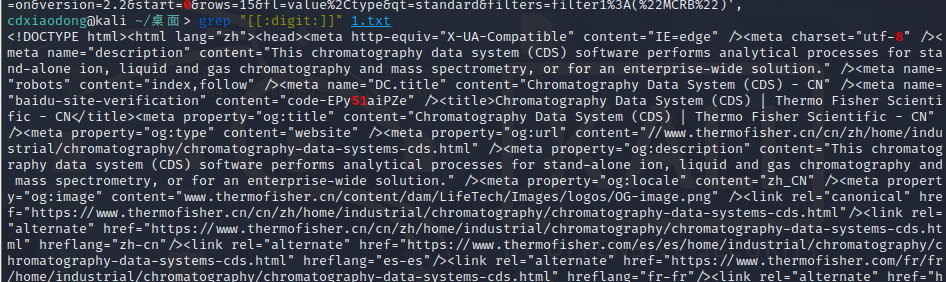
匹配所有数字字符 (注意: 不是把行提取出来哦)
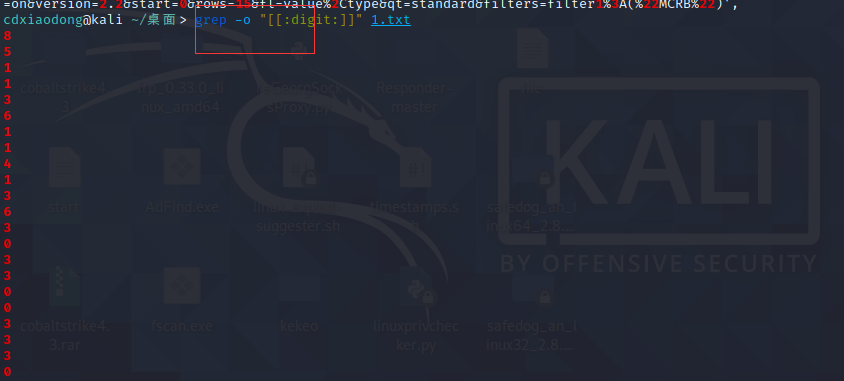
但是针对这种模式 有个缺点
不能只把有这个特征的行找出来
但是我们可以grep -o把匹配的那些字符弄出来
font color = ‘yellow’>GNU规范
Linux中的GNU软件一般支持转义元字符,这些转义元字符有:\b(边界字符,匹配单词的开始或结尾), \B(与\b为反义词,\Bthe\B不会匹配单词the,仅会匹配the在中间的单词,如atheist), \w(等同于[[:alnum:]]), \W(等同于[^[:alnum:]])。另外有部分软件支持使用\d表示任意数字,\D表示任意非数字。\s表示任意空白字符(空格、制表符等), \S表示任意非空白字符。
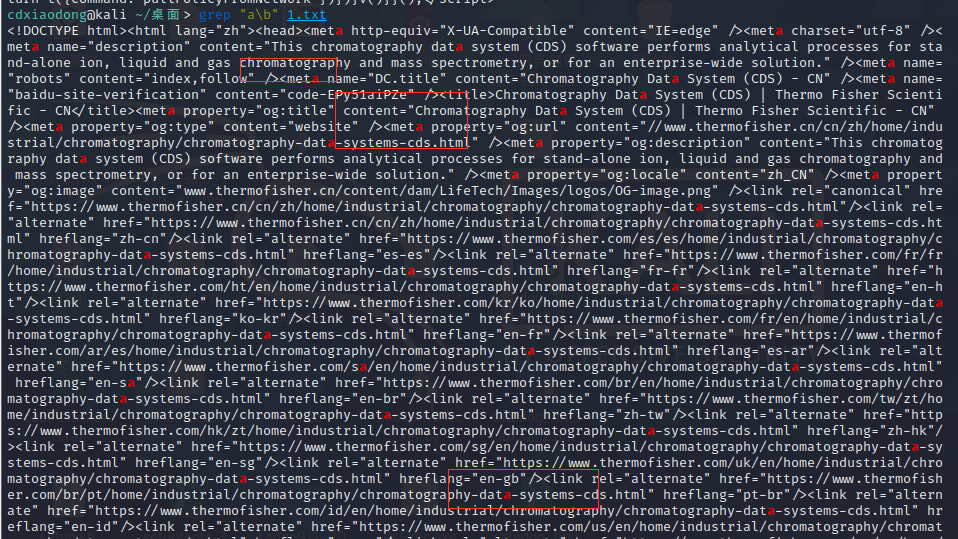
匹配a结尾的字符 当然单词a也是以a结尾
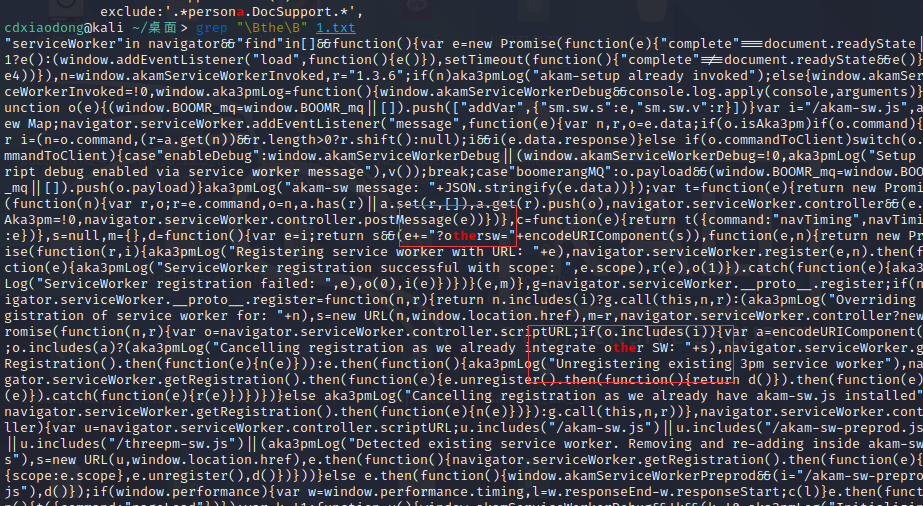
就是the在单词的中间
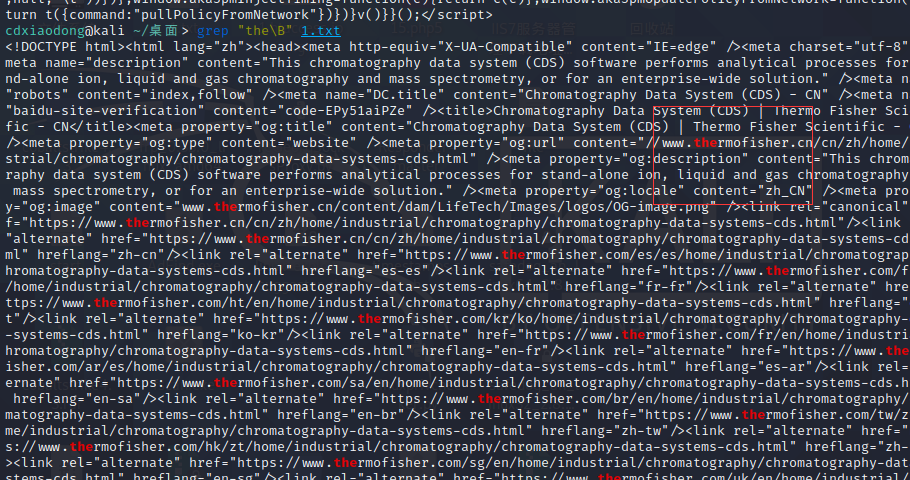
就是the在单词的头部

-P使用perl的正则
1.7各种各样的算数运算
Shell支持多种算术运算,可以使用$((表达式))、$[表达式]、let表达式进行整数的算术运算,注意这些命令无法执行小数运算;使用bc命令可以进行小数运算。

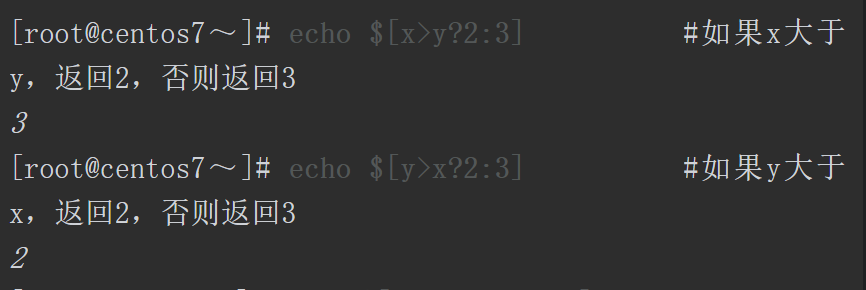
接下来,学习使用内置命令let进行算术运算的案例。注意,使用let命令计算时,默认不会输出运算的结果,一般需要将运算的结果赋值给变量,通过变量查看运算结果。另外,使用let命令对变量进行计算时,不需要在变量名前添加$符号。
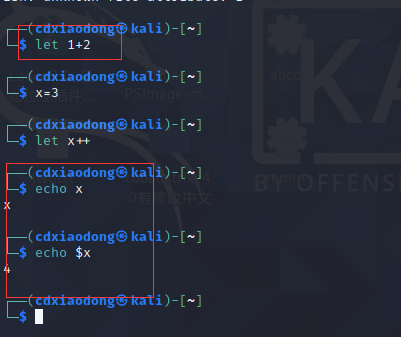
let是无法直接输出明文的 但是却可以进行运算
然后echo输出
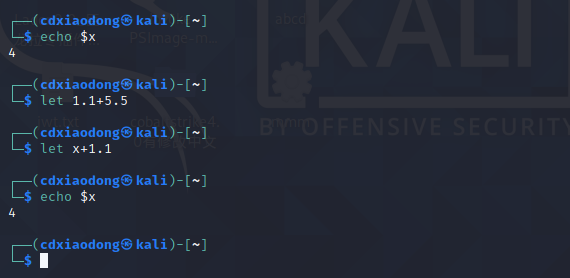
let无法进行小速点的运算
Bash仅支持对整数的四则运算,不支持对小数的运算。如果我们需要在脚本中对任意精度的小数进行运算甚至编写计算函数,则可以使用bc计算器实现。bc计算器支持交互和非交互两种执行方式。
先看看在交互模式下的计算方式,一行代码为一条命令,可以进行多次计算。
(bc需要手动安装)

除了在交互模式下使用bc计算器,还可以通过非交互的方式进行计算。而且通过bc计算器的另外两个内置变量ibase(in)和obase(out)可以进行进制转换,ibase用来指定输入数字的进制,obase用来设置输出数字的进制,默认输入和输出的数字都是十进制的。
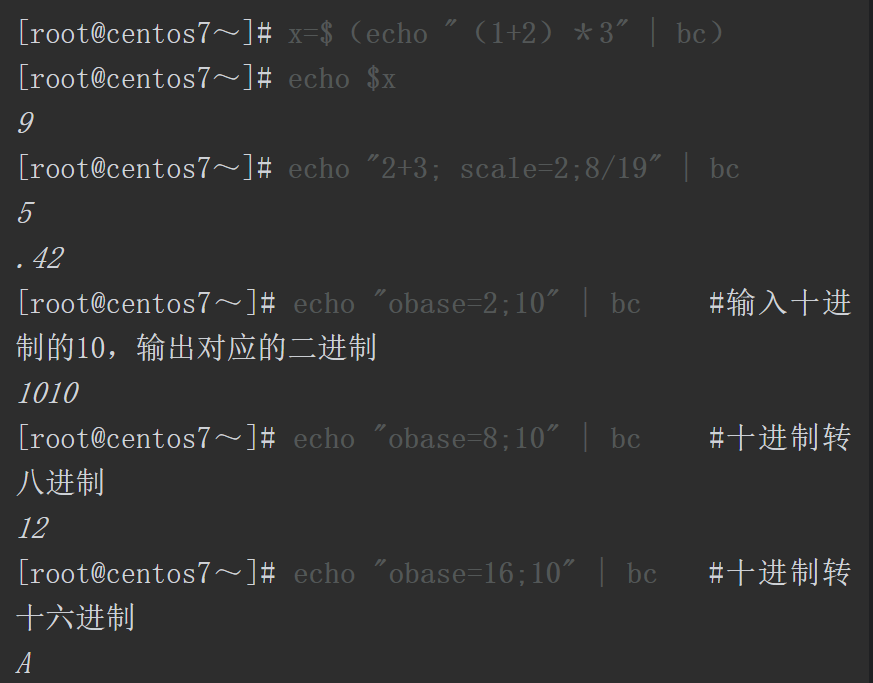
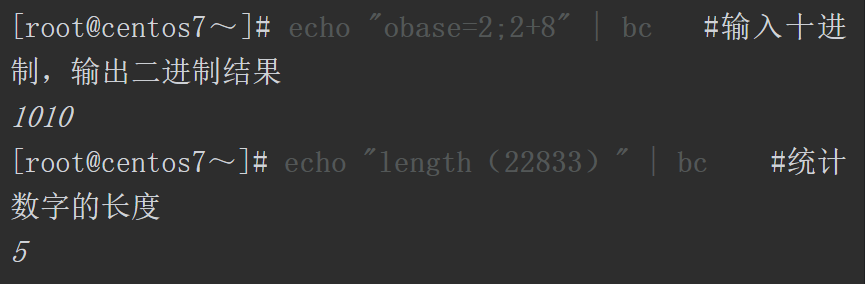
通过计算我们可以解决现实中的很多问题,下面这个需要计算结果的脚本案例中的每个部分都可以独立出来单独运行,也可以合并在一个文件中统一执行。

2很人工 有很智能的脚本
2.1智能化脚本的基础测试
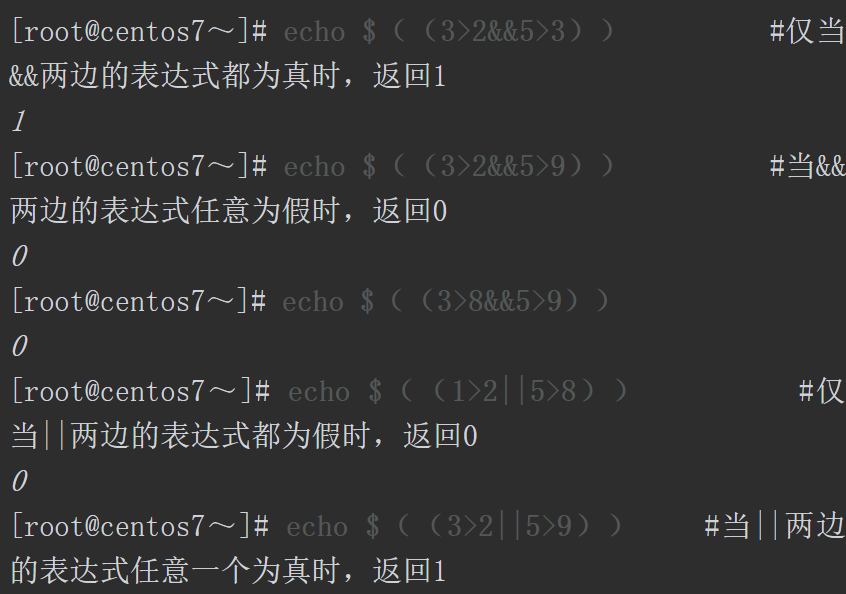
在Shell中可以使用多种方式进行条件判断,如[[表达式]]、[表达式]或者test表达式。使用条件表达式可以测试文件属性,进行字符或数字的比较。需要注意的是,不管使用哪种方式进行条件判断,系统默认都不会有任何输出结果,可以通过echo $?命令,查看上一条命令的退出状态码,或者使用&&和||操作符结合其他命令进行结果的输出操作。
警告:
表达式两边必须有空格,否则程序会出错。使用[[]]和test进行排序比较时,使用的比较符号不同。在test或[]中不能直接使用<或>符号进行排序比较。
如果需要在一行代码中输入多条命令,在Shell中可以使用;(分号)、&&(与)、||(或)这三个符号将多个命令分隔。其中;(分号)是按顺序执行命令,分号前后的命令可以没有任何逻辑关系。例如,输入“A命令;B命令”,系统会先执行A命令,不管A命令执行结果如何,都会执行B命令。整个命令的退出码以最后一条命令为准,B命令如果执行成功则退出码为0, B命令如果执行失败则退出码为非0。而使用&&(与)符号分隔多条命令时,仅当前一条命令执行成功后,才会执行&&后面的命令。例如,输入“A命令&&B命令”,系统会先执行A命令,如果A命令执行成功则执行B命令,如果A命令执行失败则不执行B命令。而整行命令的退出码取决于两条命令是否同时执行成功,如果A命令执行成功并且B命令执行也成功,则整行命令的退出码为0,而A命令或B命令中的任何一条命令执行失败,则整行命令的退出码为非0。如果使用||(或)符号分隔多条命令,仅当前一条命令不执行或执行失败后才执行后一条命令。例如,输入“A命令||B命令”,因为A命令是命令行的第一条命令,所以一定会执行,如果A命令执行成功了就不再执行B命令,如果A命令执行失败,则执行B命令,A命令和B命令为二选一的关系。A命令或B命令中有任何一条命令的退出码为0,则整行命令的退出码就是0,否则返回非0。
2.2字符串的判断与比较



下面的测试,因为当前用户是cdxiaodong,测试结果为真,所以会执行echo Y命令,而当echo Y命令执行并成功后,则不再执行echoN,结果屏幕仅显示Y。
在表达式中使用-z可以测试一个字符串是否为空,下面测试一个未定义的变量TEST,如果变量值为空则屏幕显示Y,否则显示N。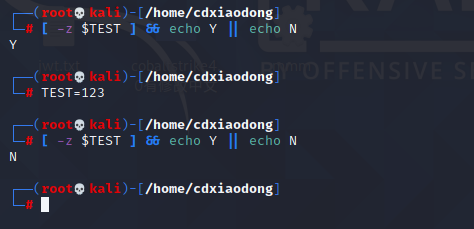
在Shell中进行条件测试时一定要注意空格问题。使用[]测试时,左方括号右边和右方括号左边都必须有空格。而且测试的比较符号两边也必须都有空格。
下面这个例子==符号两边没有空格,无论怎么测试结果都为真,编写脚本时这种Bug系统不会提示语法错误,但程序结果有可能是错误的。
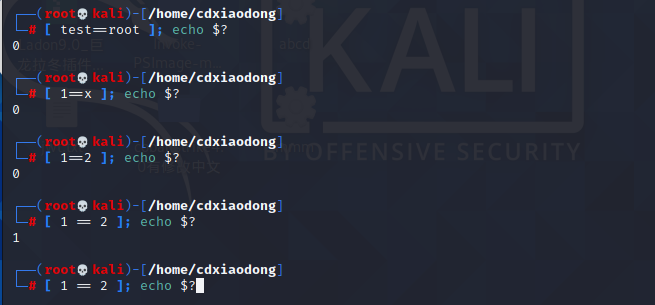
当测试一个未定义的变量时就会出故障。下面测试一个未定义的变量Jacob是否非空。为什么Jacob的度量值明明为空,但测试却说该变量值不为空呢?

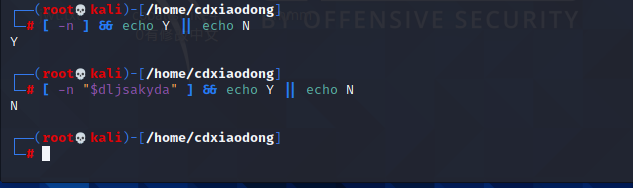
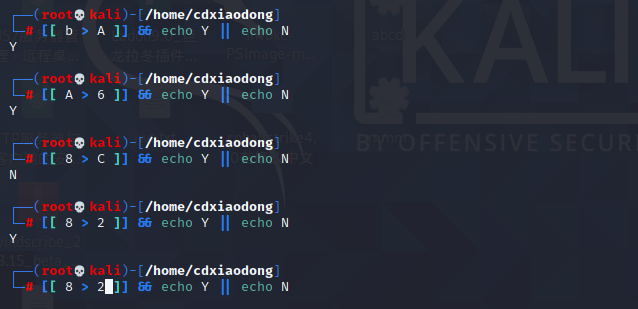
2.3整数的判断与比较
比较两个数字可能的结果有等于、不等于、大于、大于或等于、小于、小于或等于这么几种情况,在Shell脚本中支持对整数的比较判断
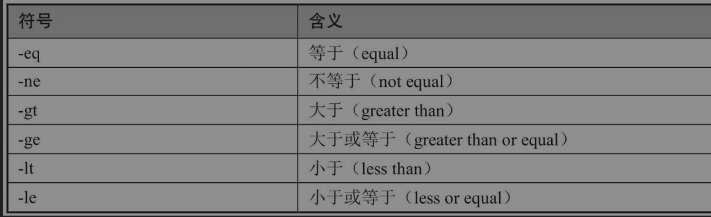
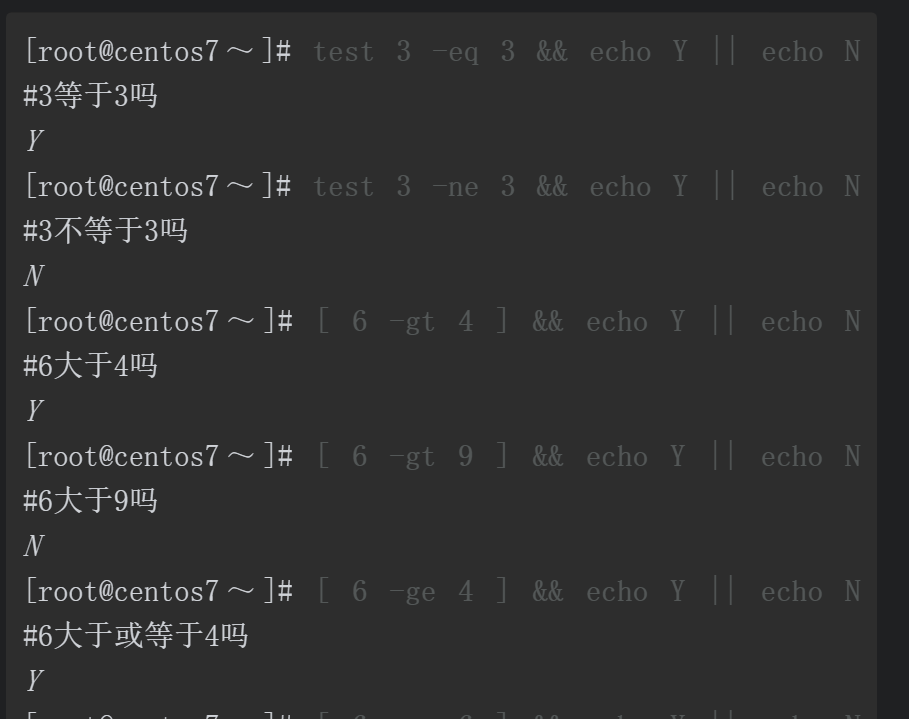
下面这个案例使用grep命令结合正则表达式,从meminfo文件中过滤当前系统剩余可用的内存容量,剩余容量以KiB为单位,最后测试剩余可用容量是否小于或等于500MiB。
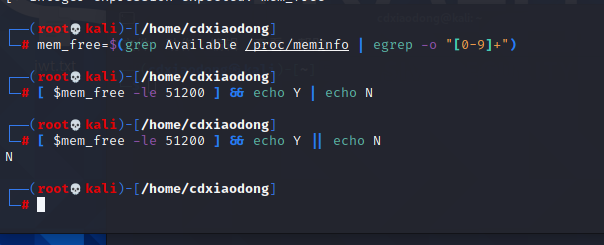
接下来使用ps命令,查看系统中所有启动的进程列表信息,结合wc命令还可以统计当前系统中已经启动的进程数量。这样,就可以判断是否启动了超过100个进程。
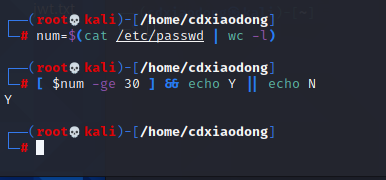
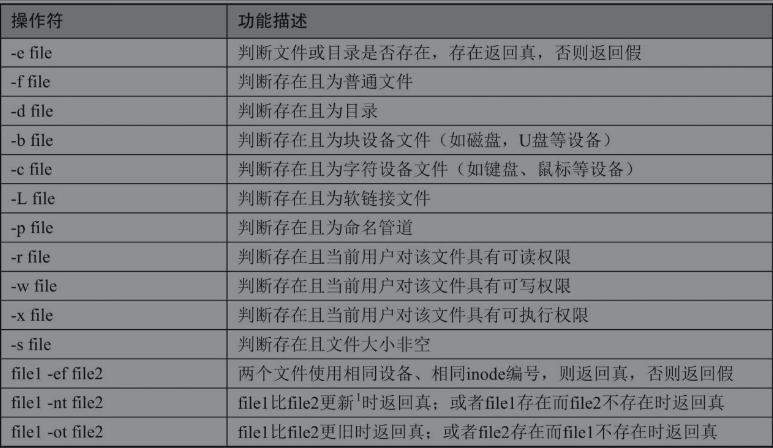
2.4文件属性的比较
Shell支持大量对文件属性的判断,常用的文件属性操作符很多
下面这个测试,假设系统中有某个磁盘设备,使用-b测试该设备是否存在,且当该设备为块设备时返回值为真,否则返回值为假。

Linux系统中的文件链接分为软链接和硬链接两种。软链接创建后,如果源文件被删除,则软链接将无法继续使用,可以跨分区和磁盘创建软链接。硬链接创建后,如果源文件被删除,则硬链接依然可以正常使用、正常读写数据,但硬链接不可以跨分区或磁盘创建。另外,硬链接与源文件使用的是相同的设备、相同的inode编号。使用ls -l[插图]命令查看硬链接文件的属性时,文件属性与普通文件是一样的,而软链接的文件属性则可以看到被l标记,表示该文件为软链接。

创建软连接

创建硬连接
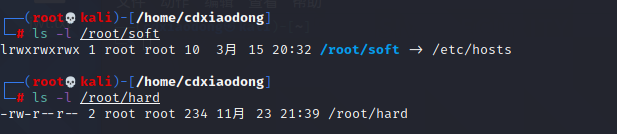
ls查看不同
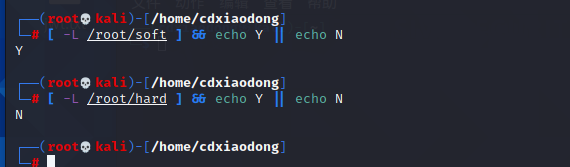
判断都是什么连接
在测试权限时需要注意,超级管理员root在没有rw权限的情况下,也是可以读写文件的,rw权限对超级管理员是无效的。但是如果文件没有x权限,哪怕是root也不可以执行该文件。

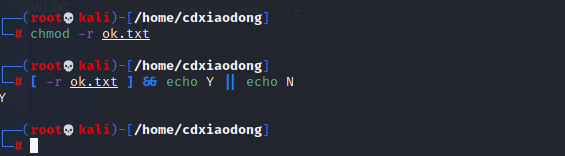
删除r权限 依然为真
因为我们是root权限
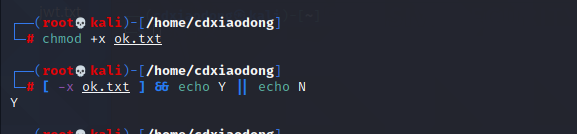
给他加x后就 为真了
默认touch命令创建的文件都是空文件,在使用-s测试文件是否为非空文件时,因为文件是空文件,所以测试结果为假。当文件中有内容时,测试文件是否为非空时,结果为真。

补充:
软件中有一些比如istat stat 等控制img块的软件都是sleuthkit等的基础软件
使用他们有一个很基础的条件。就是要知道什么是inode
这里就介绍什么是inode
inode包含文件的元信息,具体来说有以下内容:
1 | |
总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
inode的大小
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每 个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定 在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
查看每个硬盘分区的inode总数和已经使用的数量,可以使用df命令。
查看每个inode节点的大小,可以用如下命令
1 | |
像hda hdb啥的都是
硬盘文件。前提是你的虚拟机有硬盘分区而不是弄在同一块盘
像sda就是设备文件 也可以是磁盘 驱动u盘啥的
1 | |
由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
inode号码
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
这 里值得重复一遍,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或 者绰号。表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号 码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
使用ls -i命令,可以看到文件名对应的inode号码:
目录文件
ls -i命令列出整个目录文件,即文件名和inode号码:
如果要查看文件的详细信息,就必须根据inode号码,访问inode节点,读取信息。ls -l命令列出文件的详细信息。
1 | |
其原理就是先读取inode再读取文件的详细信息
硬链接
一 般情况下,文件名和inode号码是”一一对应”关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许,多个文件名指向同一个 inode号码。这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访 问。这种情况就被称为”硬链接”(hard link)。
ln命令可以创建硬链接:
1 | |
运 行上面这条命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中有一项叫做”链接数”,记录指向该inode的文 件名总数,这时就会增加1。反过来,删除一个文件名,就会使得inode节点中的”链接数”减1。当这个值减到0,表明没有文件名指向这个inode,系 统就会回收这个inode号码,以及其所对应block区域。
这里顺便说一下目录文件的”链接数”。创建目录时, 默认会生成两个目录项:”.”和”..”。前者的inode号码就是当前目录的inode号码,等同于当前目录的”硬链接”;后者的inode号码就是当 前目录的父目录的inode号码,等同于父目录的”硬链接”。所以,任何一个目录的”硬链接”总数,总是等于2加上它的子目录总数(含隐藏目录),这里的 2是父目录对其的“硬链接”和当前目录下的”.硬链接“。
软链接
除了硬链接以外,还有 一种特殊情况。文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打 开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的”软链接”(soft link)或者”符号链接(symbolic link)。
这 意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错:”No such file or directory”。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode”链接数”不会因此 发生变化。
ln -s命令可以创建软链接。
ln -s 源文文件或目录 目标文件或目录
inode的特殊作用
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象。
\1. 有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。
\2. 移动文件或重命名文件,只是改变文件名,不影响inode号码。
\3. 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
第3点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时 候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的 inode则被回收。
实际问题
在一台配置较低的Linux服务器(内存、硬盘比较小)的/data分区内创建文件时,系统提示磁盘空间不足,用df -h命令查看了一下磁盘使用情况,发现/data分区只使用了66%,还有12G的剩余空间,按理说不会出现这种问题。 后来用df -i查看了一下/data分区的索引节点(inode),发现已经用满(IUsed=100%),导致系统无法创建新目录和文件。
查找原因:
/data/cache目录中存在数量非常多的小字节缓存文件,占用的Block不多,但是占用了大量的inode。
解决方案:
1、删除/data/cache目录中的部分文件,释放出/data分区的一部分inode。
2、用软连接将空闲分区/opt中的newcache目录连接到/data/cache,使用/opt分区的inode来缓解/data分区inode不足的问题:
1 | |
2.5探究[[]]与[]的区别
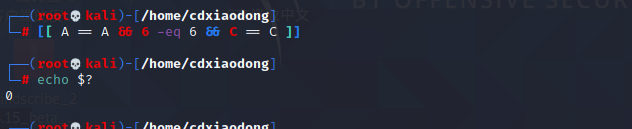
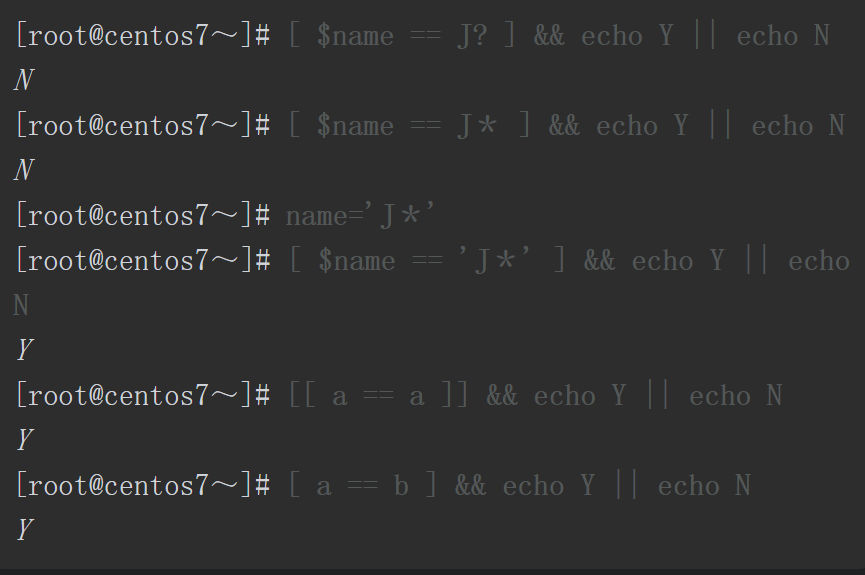
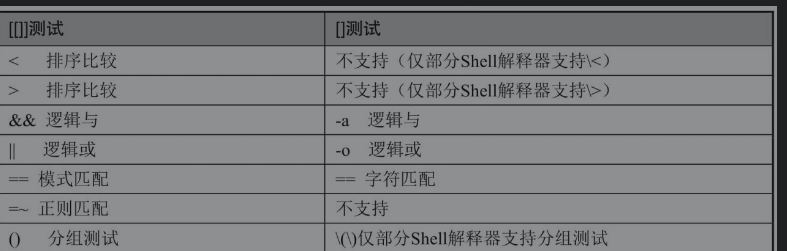
多数情况下[]和[[]]是可以通用的,两者的主要差异是:test或[]是符合POSIX标准的测试语句,兼容性更强,几乎可以运行在所有Shell解释器中,相比较而言[[]]仅可运行在特定的几个Shell解释器中(如Bash、Zsh等)。事实上,目前支持使用[[]]进行条件测试的解释器已经足够多了。使用[[]]进行测试判断时甚至可以使用正则表达式。
看两者的差异点。其中,在[[]]中使用<和>符号时,系统进行的是排序操作,而且支持在测试表达式内使用&&和||符号。在test或[]测试语句中不可以使用&&和||符号。
注意
[[ ]]中的表达式如果使用<或>进行排序比较,使用的是本地的locale语言顺序。可以使用LANG=C设置在排序时使用标准的ASCII码顺序。在ASCII码的顺序中,小写字母顺序码>大写字母顺序码>数字顺序码。
虽然[]也支持同时进行多个条件的逻辑测试,但是在[]中需要使用-a和-o进行逻辑与和逻辑或的比较操作,而[[]]中可以直接使用&&和||进行逻辑比较操作,更直观,可读性更好。

需要注意的还有比较符,在[[]]中是模式匹配,模式匹配允许使用通配符。例如,Bash常用的通配符有*、? 、[…]等。而==在test语句中仅代表字符串的精确比较,判断字符串是否一模一样。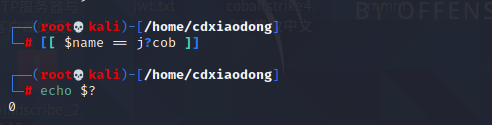
测试变量name的值是否是J和cob中间有任意单个字符?结果为真。
==同样是使用==进行比较操作,但在[]中系统进行的是字符串的比较操作,判断两个字符串是否绝对相同。==
另外,在[[]]中还支持使用=~进行正则匹配,而在[]中则完全不支持正则匹配。
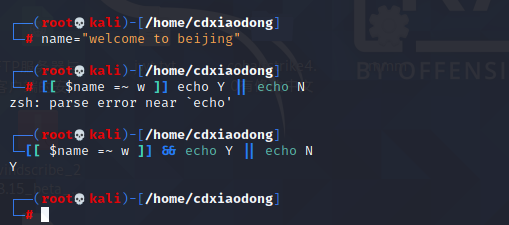
对变量name的值进行正则匹配,判断name的值是否包含字母w。
下图中列出了[[]]和[]的差异汇总信息
2.6系统性能监控脚本
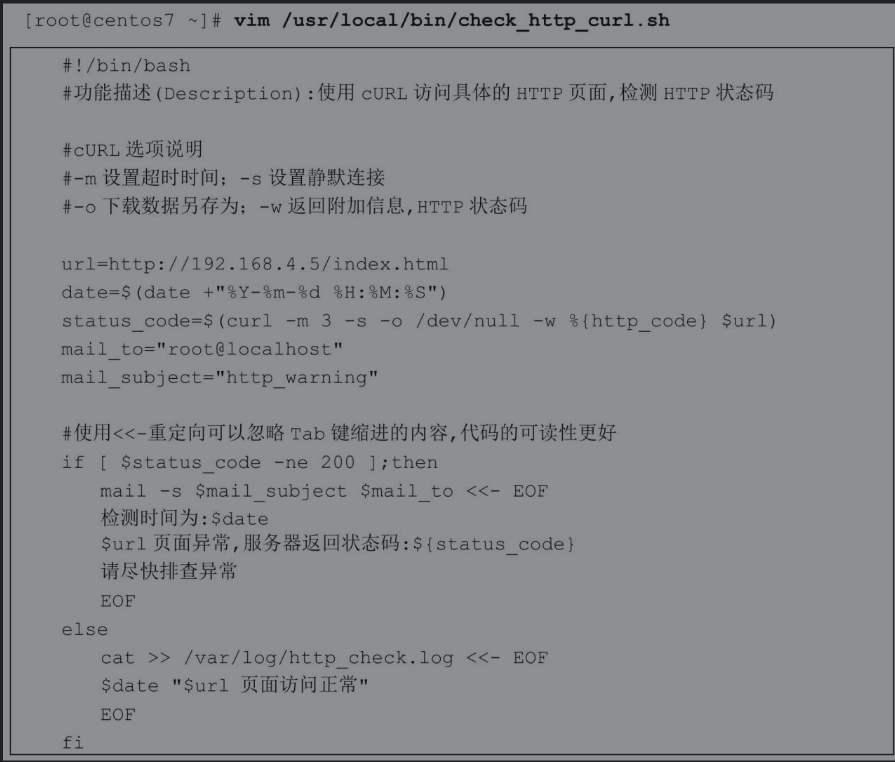
下面我们来编写一个检测系统环境、监控系统性能的脚本,并判断各项数据指标是否符合预设的阈值。如果数据有异常,那么将结果通过邮件发送给本机root账户。在实际生产环境能联网的情况下,也可以发送邮件给某个外网的邮件账户。
注意脚本中的很多预设值只是假设值,在实际生产环境中还需要根据业务和环境的需要,调整这些预设值。限于篇幅,本脚本仅获取部分性能参数指标,如果还有其他需要监控的数据,也可以使用类似的方法获取。另外,在过滤数据时暂时使用cut命令,学习后面章节的awk命令后,过滤数据会变得更简单。







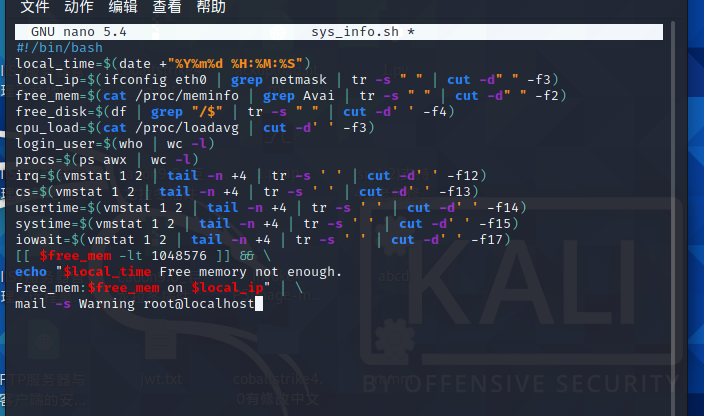
因为kali默认没装mail 这里就不作演示了
2.7实战:单支if语句
对于简单的条件判断,结合&&和||就可以完成大量的脚本。但是当脚本越写越复杂、功能越写越完善时,简单的&&和||就不足以满足需求了。
此时,选择使用if语句结合各种判断条件,功能会更加完善和强大。在Shell脚本中if语句有三种格式,分别是单分支if语句、双分支if语句和多分支if语句。下面是单分支if语句的语法格式。

if和then可以写在同一行。同一行中如果需要编写多条命令,中间需要使用分号分隔命令。所以,单分支if语句也可以写成如下格式。
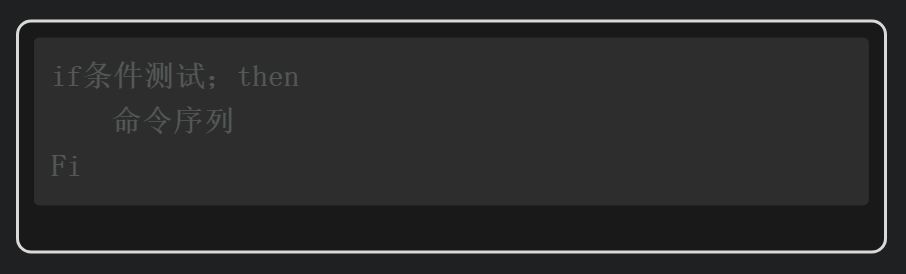
单分支if语句会检查条件测试的结果,只要返回的结果为真,那么就会执行then后面的命令序列(可以包含一条或多条命令)。但如果测试条件返回的结果为假,那么if语句就什么命令也不执行。这里的条件测试除了可以是字符串的比较测试、数字的比较测试、文件或目录属性的测试,还可以是一条或多条命令。
下面我们看一个单分支if语句的例子,读取用户输入的用户名和密码后,脚本通过if判断用户名和密码是否非空,如果非空则创建账户并设置密码,否则脚本直接结束。执行脚本,当提示输入用户名和密码时,如果我们都不输入(直接按回车键),脚本就会退出。
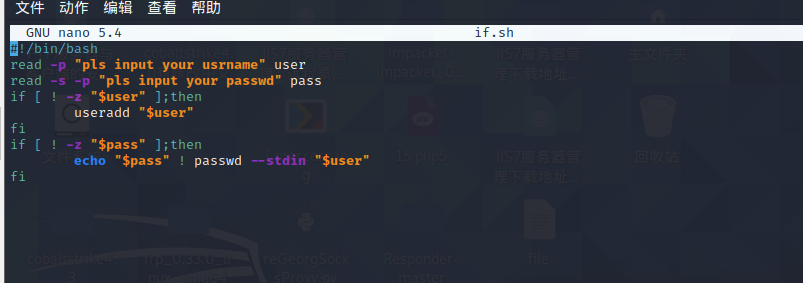
但是,上面的脚本有一个问题。当执行脚本提示输入用户名时,直接按回车键,而当提示输入密码时,正常输入一个密码,这时运行脚本就会报错。因为这样导致在账户没有创建成功的情况下,修改账户密码,结果一定会报错。因此,还需要继续优化这个脚本,可以使用嵌套if语句(在if语句里面再使用if语句)来解决该问题
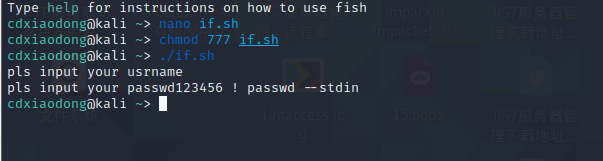
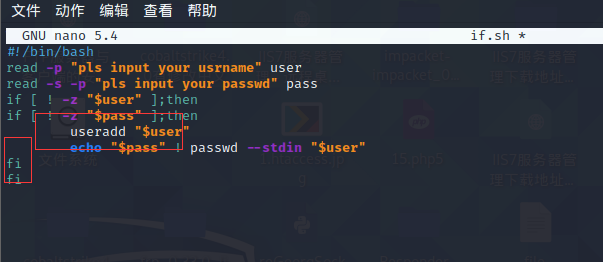

这样做的好处是,如果账户名为空,则脚本就不会执行then后面的命令,也就不会对密码做任何测试动作,更不会修改账户密码,而是直接退出脚本。如果测试账户名为非空,则进一步对密码进行测试,如果密码也非空,那么就执行then后的命令,创建账户并设置密码。
提示:if语句后面的条件测试语句不一定非要是test或[]测试语句,任何有返回值的命令都可以写在if语句后面,命令返回值为0代表执行成功(即为真),返回值非0代表执行失败(即为假)。
2.8实战:双if分支语句
与单分支if语句的格式一样,then和if可以写在同一行,也可以分开写在不同行。甚至在else和命令序列1中间添加分号将其写在同一行,但很少有人这样写,这将导致代码的可读性非常差。
1 | |
双分支if语句会检查条件测试的结果,只要测试条件返回值结果为真,就会执行命令序列1(可以包含一条或多条命令)。但如果测试条件返回值结果为假,那么就会执行命令序列2。所以双分支if语句,不管条件是否成立,都会执行特定的命令
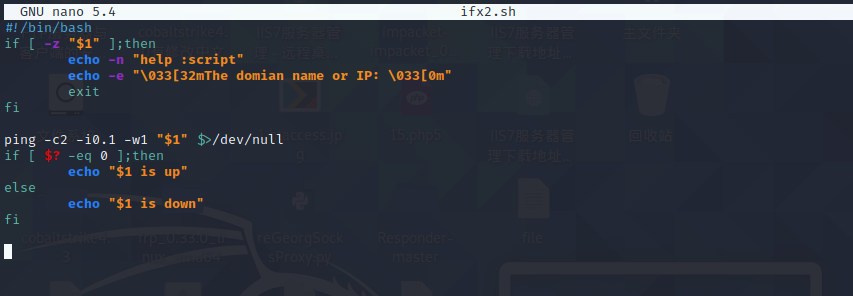
因为RPM等类似的二进制软件往往不能提供最新的版本,并且不具备自定义安装选项,所以生产环境中经常需要采用源码的方式安装软件。但采用源码的方式安装软件的步骤又比较烦琐,所以编写脚本实现自动化安装软件是非常重要的。下面看一个采用源码的方式安装软件的脚本案例。
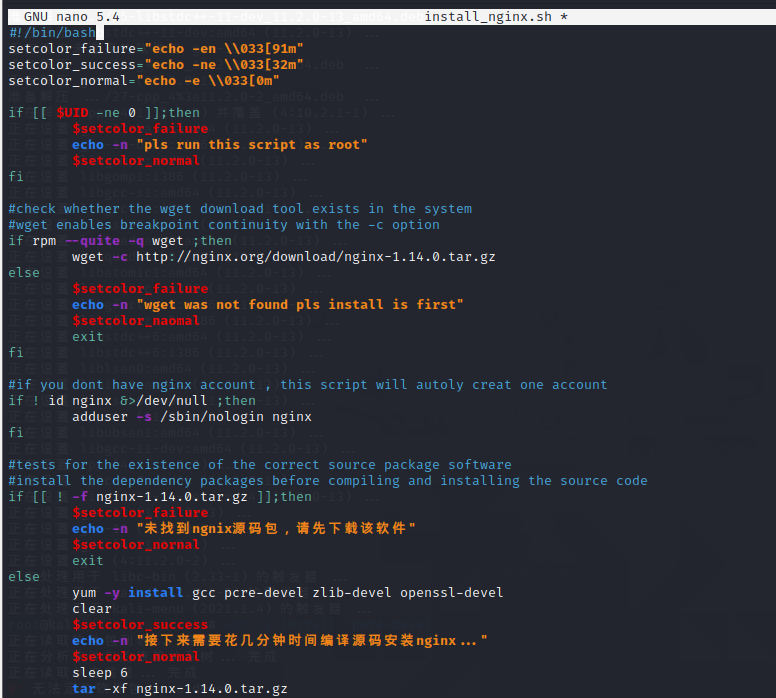
脚本的第一个功能是通过使用变量的方式,定义echo回显的颜色属性。echo命令的-n选项,可以在回显数据后不按回车键即可换行,-e选项开启右斜线(\)转义的解释功能。
通过对系统环境变量UID的比较测试,判断当前执行脚本的用户是否为管理员。如果不是管理员,则脚本直接提示错误并退出。
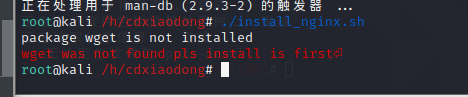
使用rpm -q可以查询某个软件是否已经安装。再通过–quiet选项,设置无论软件是否已经安装都不在屏幕上回显结果,而是通过if语句自动判断命令的执行结果是真还是假。如果未安装wget,则脚本提示错误并退出。反之,在系统中已有wget工具的情况下,联网下载Nginx源码包软件[插图]。wget命令的-c选项可以开启断点续传的功能,下载过程中如果突然断网,联网后可以从上次的断点处继续下载,而不需要将文件全部重新下载。
(rpm有个缺陷 如果是编译安装 会检测不到,像我们kali使用的apt安装的软件 用rpm是检测不到的)
可以使用骚操作
$(whereis wget) == wget
或者自定义查找
$(whereis $softname) == $softname
https://blog.csdn.net/bigwood99/article/details/105163508
但是实在不好写
建议使用type或which 当然find写入文本然后正则添加也可以
直接 type wget >/dev/null 2>&1
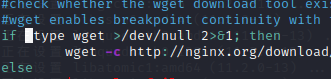
还是可以的
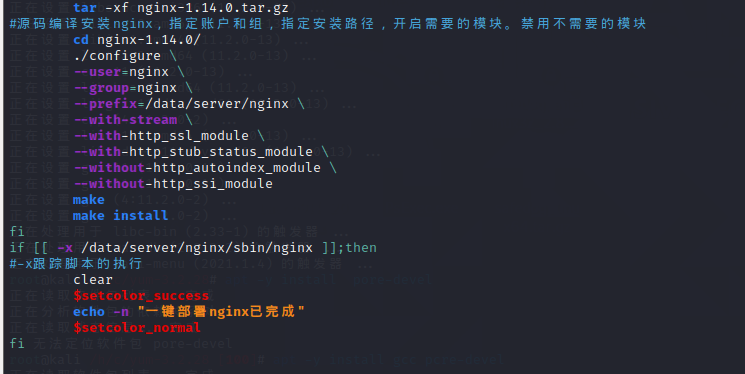
启动Nginx服务时,以普通用户的身份登录会更安全。脚本通过Id命令检查nginx账户是否已经存在,如果不存在nginx账户,则脚本会自动创建该账户。
在编译源码安装Nginx时,首先需要安装该软件包依赖的相关软件包,脚本中安装了gcc、pcre-devel、zlib-devel、openssl-devel这四个软件包,这些软件都在CentOS标准的Yum中,并且在安装openssl-devel时会自动安装zlib-devel。所以,哪怕不通过Yum明确要求安装zlib-devel,也会在安装openssl-devel时自动安装zlib-devel。Nginx是模块化的软件,可以通过<–with-模块>的方式启动某个模块的功能,不需要的功能模块,可以通过<–without-模块>的方式禁用。
2.9实战:如何监控监控http服务状态
就是nmap利用SYN+ACK
之前写yak和go的时候都拿这个入手,不过我们不用ACK
这样就叫做半半式扫描 这样更快
虽然使用Nmap可以快速地对大量端口进行扫描,但是仅使用端口扫描作为HTTP状态检查的依据,也有其自身的问题。如果服务已经启动,而且HTTP端口也已经开放给客户端,此时如果网站服务器上的网页已经被人恶意或无意删除,就会导致客户端可以成功连接服务器的80端口,但是访问页面时会报错404,说明页面文件找不到。此时不仅需要对端口进行检测,还需要对服务器返回的HTTP状态码进行检测。更有甚者,如果服务器端口已经启动,网页也还存在,但服务器被入侵,并且篡改了网页的数据,又该怎么办呢?还可以对数据的Hash值进行校验,检测网页数据是否被篡改。
如果希望在测试端口的基础上继续测试特定的页面是否可用,可以使用cURL工具进行测试。cURL是命令行的文件传输工具,支持很多种协议,如FTP、HTTP、HTTPS、IMAP、SMTP、POP3等
cURL常用的有效名称
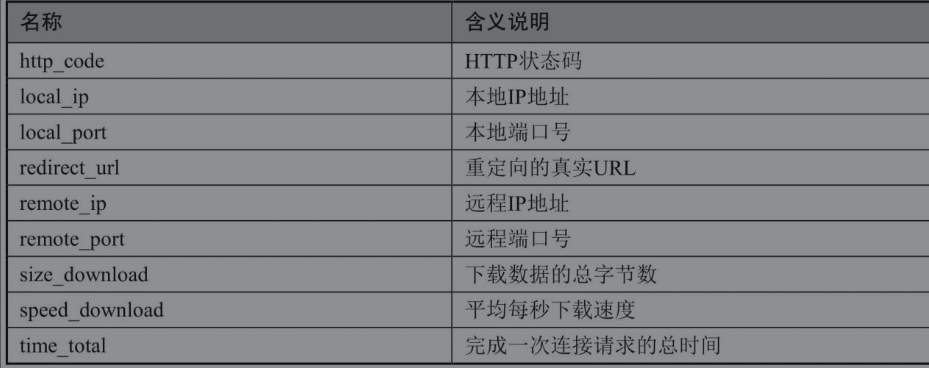
上面的脚本可以根据网页文件是否可以被访问来测试服务器的健康状态。然而,当网页的数据内容被人恶意篡改后,虽然网页依然可以被访问,但服务器的健康状态已经出问题了!此时,可以使用Hash值对数据的完整性进行校验,以防止数据被篡改。数据Hash值的特点就是当数据发生改变时Hash值也会随之改变,如果数据没变化,则Hash值永远不变。在CentOS系统中提供了md5sum、sha1sum、sha256sum、sha384sum、sha512sum等可以计算Hash值的命令。
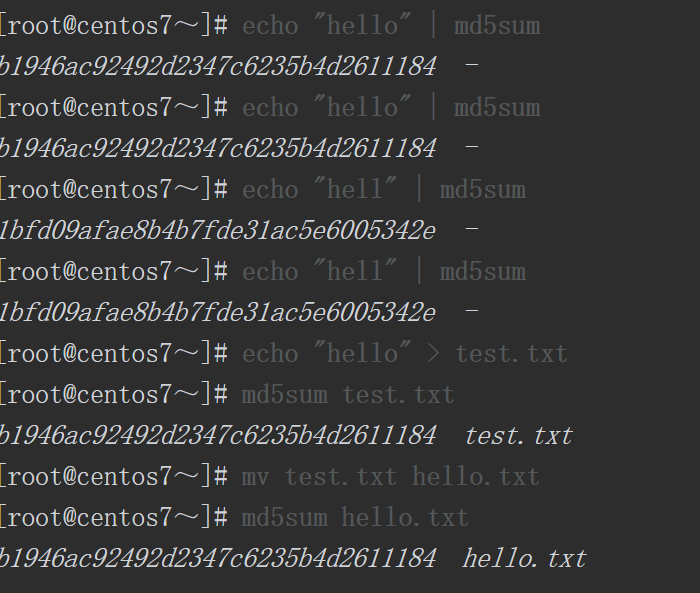

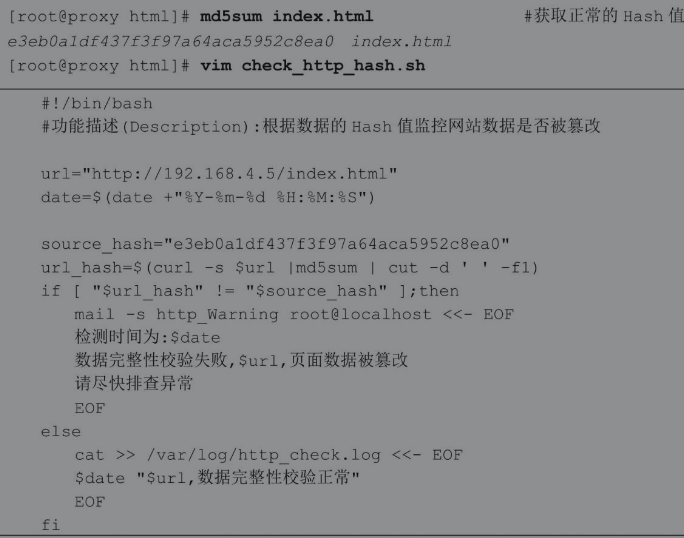
2.10实战系列:多分支if语句
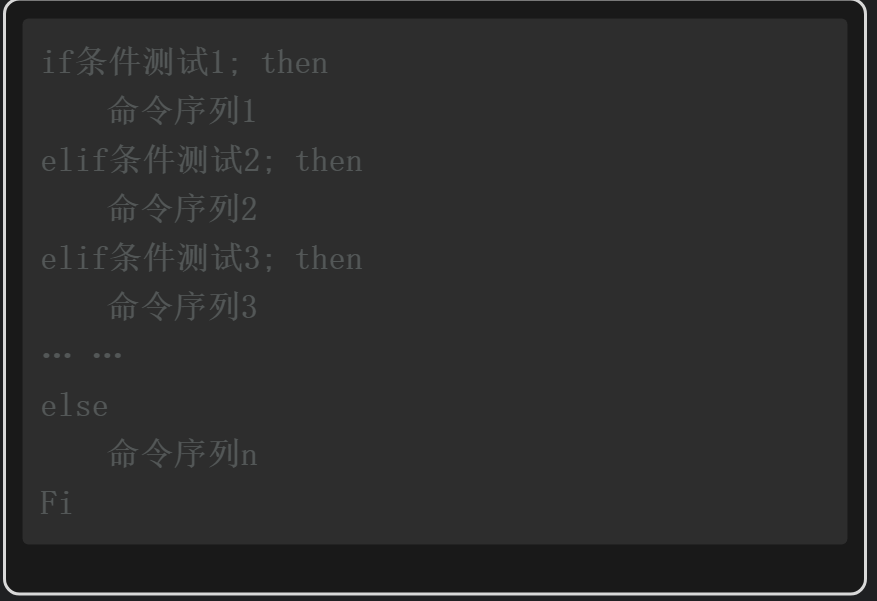
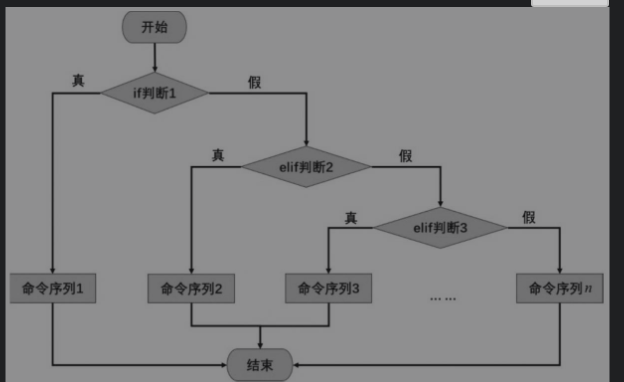
多分支if语句工作流程如图2-4所示。如果if判断1成立(结果为真),则执行命令序列1中的命令,否则继续进行elif判断;如果elif判断2成立,则执行命令序列2中的命令,否则继续进行elif判断3,依此类推。如果所有的条件判断都不成立,则执行最后else语句中的命令序列n的命令。
在CentOS7系统中提供了一个可以非交互创建磁盘分区的
parted命令的语法格式如下,常用磁盘操作指令

修改分区表类型

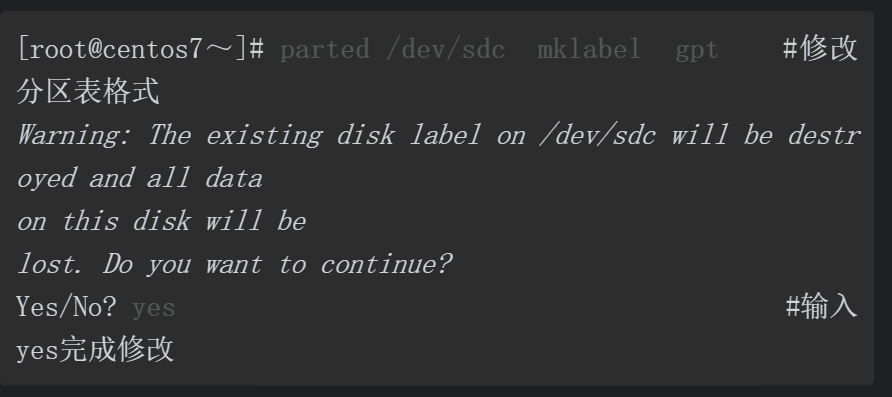
除了基本的创建与删除分区,利用parted命令还可以进行分区检查、调整分区大小、恢复误删除分区等操作,关于parted命令的更多使用方法,可以查阅man手册。接下来看如何通过脚本实现分区管理。
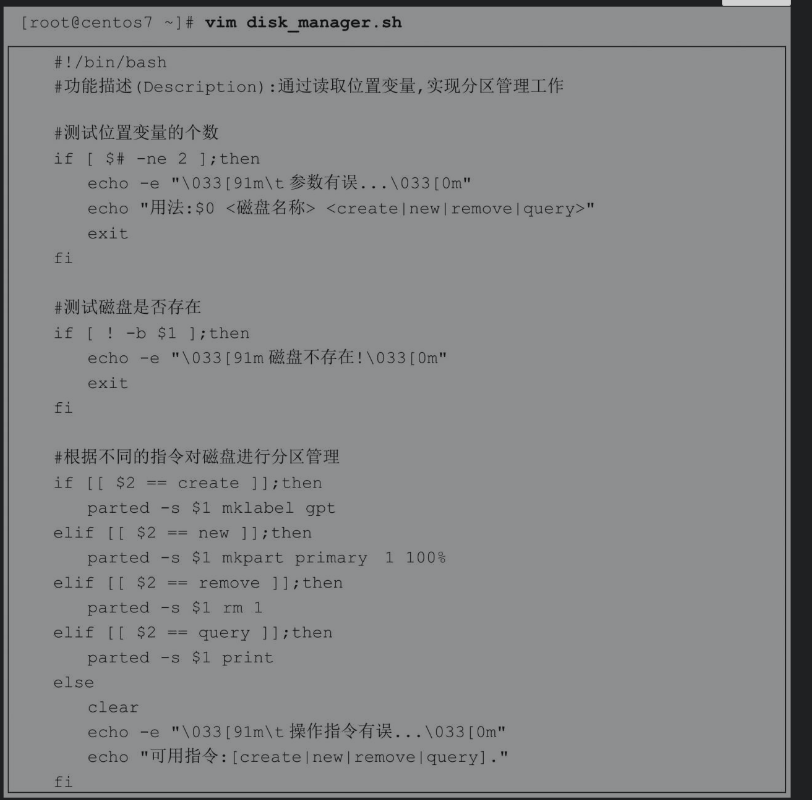
2.11实战案例:简单、高效的case语句
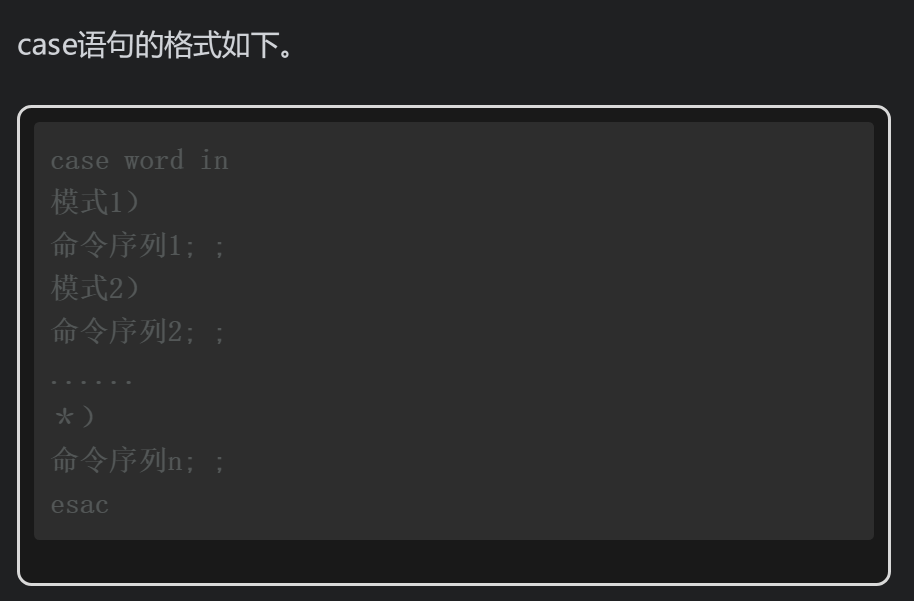
case语句还支持多个条件的匹配,语法格式如下。

上面的语法中,case命令首先会展开word关键字,然后将该关键字与下面的每个模式进行匹配比较。word关键字展开支持使用~(根目录)、变量展开$、算术运算展开$[]、命令展开$()等。每个模式匹配中也都支持与word关键字一样的展开功能。一旦case命令发现有匹配的模式,则执行对应命令序列中的命令。如果命令序列的最后使用了;;(双分号),则case命令不再对后续的模式进行匹配比较,即匹配停止。如果使用;&替代;;会导致case继续执行下一个模式匹配中附加的命令序列。如果使用;; &替代;;则会导致case继续对下一个模式进行匹配,如果匹配则执行对应命令序列中的命令。下面通过几个简单的实例学习case语句的基本语法格式。
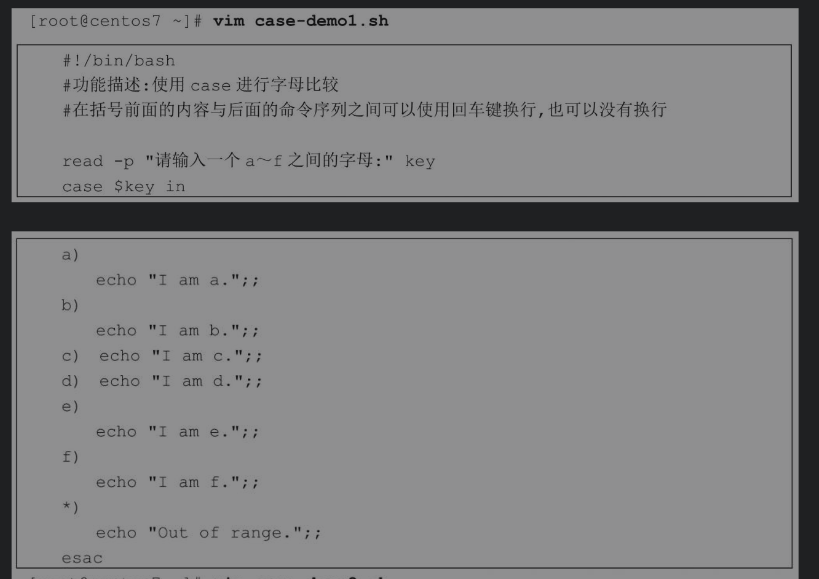

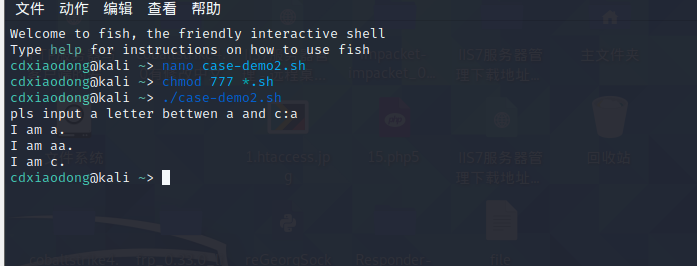
case命令可以使用管道符号(|)进行多个模式的匹配,编写有些交互脚本时需要使用这个功能。
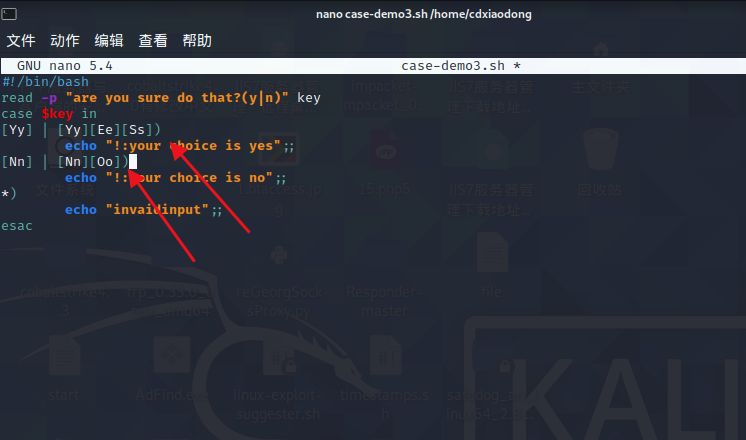
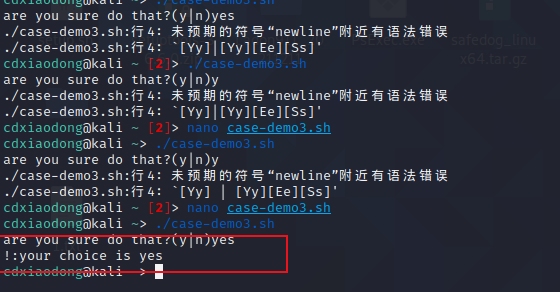
注意后面有个)
不然会报错
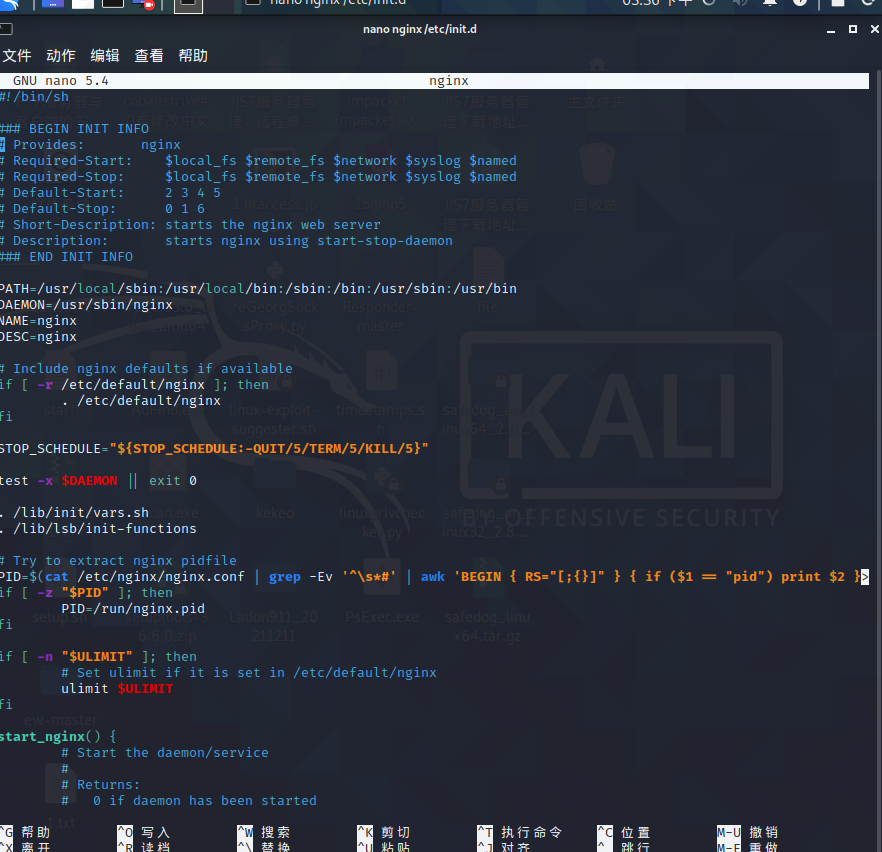
2.12 编写nginx启动脚本
case语句另一个常用的应用案例是编写CentOS6风格的服务启动脚本,在CentOS7系统中虽然使用systemctl替代了旧版本的service,但在实际生产环境中还是有大量案例需要编写旧版本的service启动脚本,而且CentOS7也向下兼容CentOS6的启动脚本。注意:CentOS6风格的service启动脚本文件必须存放在/etc/init.d/目录下。
2.13 揭秘模式匹配与通配符、扩展通配符
使用case进行模式匹配时,除了一些特殊符号,在模式匹配中出现的任何字符都仅代表其自身。在模式匹配中支持具有特殊含义的字符,通常这些符号被称为通配符,

下面通过案例看看如何使用通配符识别用户输入的内容。

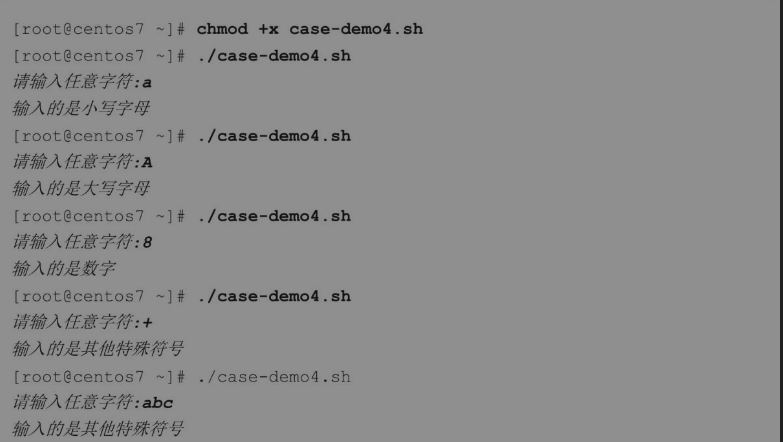
从测试脚本的执行效果可以看出,上面这个脚本仅可以识别一个字符,如果输入的内容的字符数超过一个,则全部被识别为其他特殊符号。而且在使用[A-Z]这样的排序集合时,Shell默认会根据系统的locale字符集排序,如果字符集使用不当,会导致匹配不到任何数据的情况发生,这个结果显然是不太合理的。
查看字符集


可以使用shopt命令切换影响Shell行为的控制选项,如果使用shopt命令将Shell的extglob控制选项开启,则在Shell中可以支持如表2-8所示的扩展通配符。shopt命令用于显示和设置Shell的各种属性,shopt命令不设置任何参数时,可以显示所有Shell属性及属性值。使用shopt命令的-s选项可以激活某个特定的Shell属性功能,而-u选项则可以禁用某个特定的属性功能。

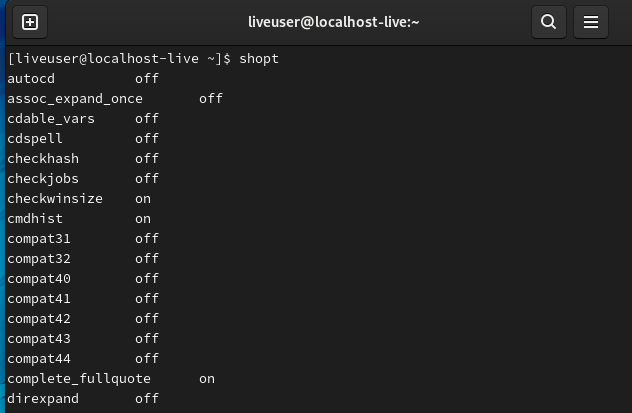
shopt #查看所有变量
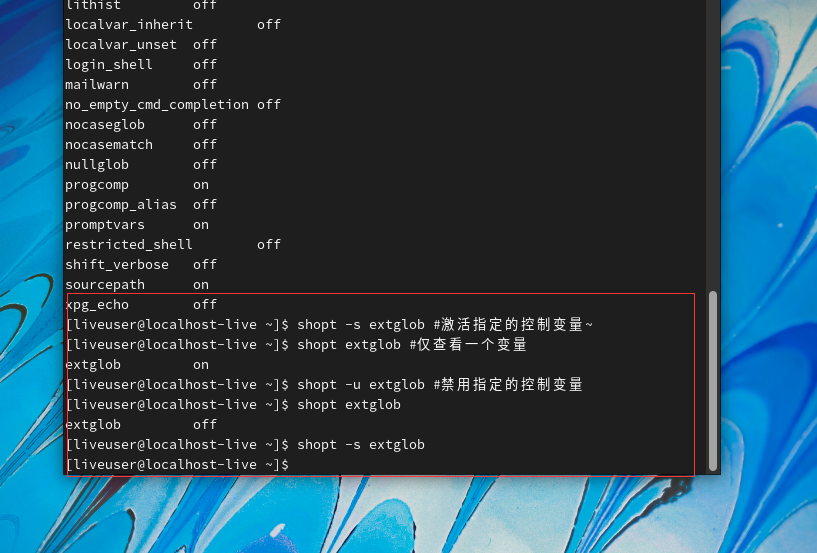
通过一个示例演示扩展通配符的作用。脚本需要结合实际执行效果反复验证并思考匹配的流程与原理。
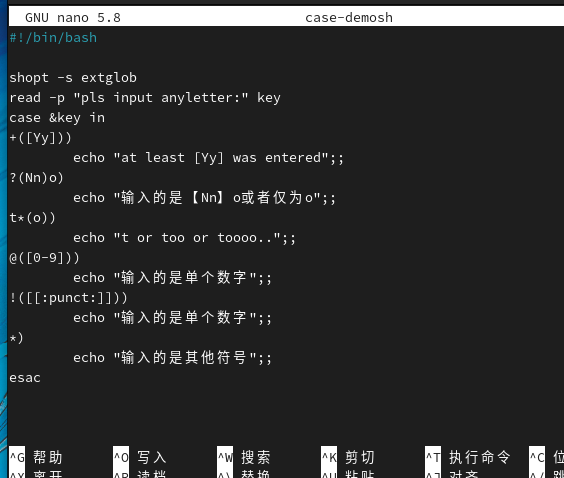
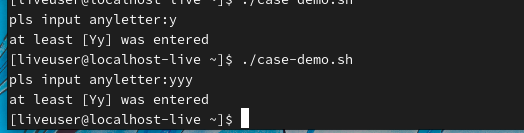
从执行结果中可以看出,+这个通配符的作用就是对模式至少进行1次匹配,所以不管输入多少个Y都会匹配成功。Y不区分大小写,因为模式中使用的[Yy]代表集合中的任意单个字符
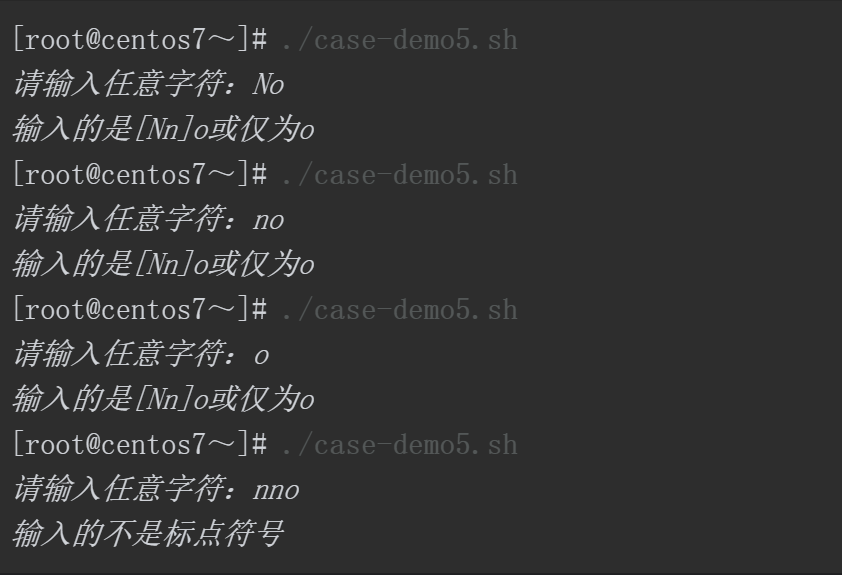
使用?通配符仅对模式进行0次或1次匹配(最多1次)。本示例中使用?对大小写的字母N进行匹配,表示N可以出现1次,也可以不出现,但最多出现1次。而后面的字母o是必须有的,没有特殊转义,也没有特殊匹配。所以执行脚本后,输入No、no或o都可以匹配成功,但是输入多于1个n则匹配失败。最终与!([[:punct:]])匹配成功,屏幕回显:”输入的不是标点符号”。

使用扩展通配符@可以指定仅对模式进行1次匹配,示例中使用@对数字进行匹配,所以当输入8或其他任意单个数字时都会匹配成功,但是输入任意多个数字则无法匹配成功。
一定要使用shopt命令先将控制变量extglob开启,否则执行脚本时会报错。
3根本停不下来的循环和中断控制
3.1for循环
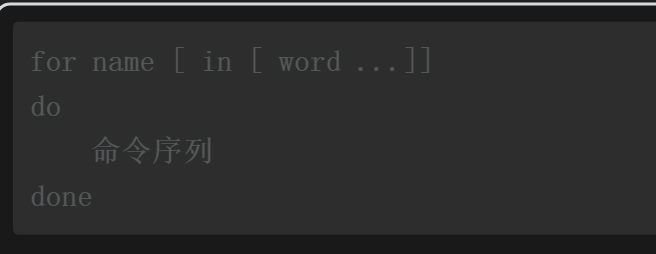
在该基本语法格式中,name是可以任意定义的变量名称,word是支持扩展的项目列表,扩展后生成一份完整的项目列表(或值列表)。name会逐一提取项目列表中的每一个值,每提取一个值就会执行一次do和done中间的命令序列。下面通过几个简单的例子演示for循环语句的基本语法。

变量name没有定义取值的范围,这个循环语句到底会循环多少次呢?如果变量name没有定义取值范围,则默认取值为$@,也就是所有位置变量的值。这样有几个位置变量,该for循环语句就循环几次。下面通过一个示例演示效果
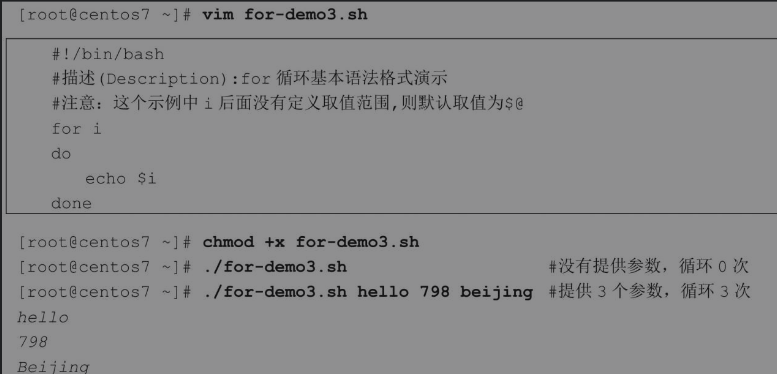
执行for-domo3.sh脚本,因为提供了3个参数,分别是hello、798和beijing,所以当第一次循环时i取值为hello,执行命令echo $i,屏幕回显hello。当第二次循环时i取值为798,执行命令echo $i,屏幕回显798。当第三次循环时i取值为beijing,执行命令echo $i,屏幕回显beijing。
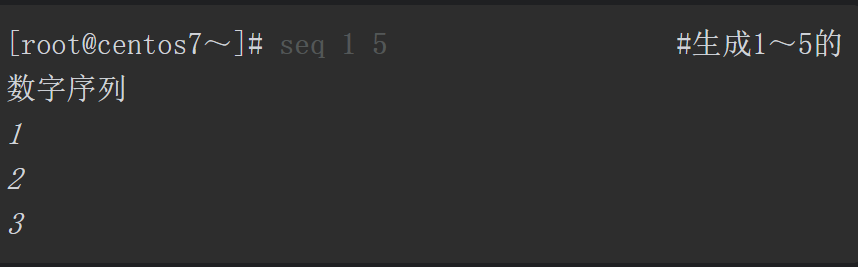
有时候脚本的循环语句需要执行成百上千次,如果每一个值都手动输入,谁也无法接受。Shell支持使用seq或{}自动生成数字序列,并且使用{}还可以自动生成字母序列。for循环语句可以对{}或seq扩展后的数据列表进行循环。

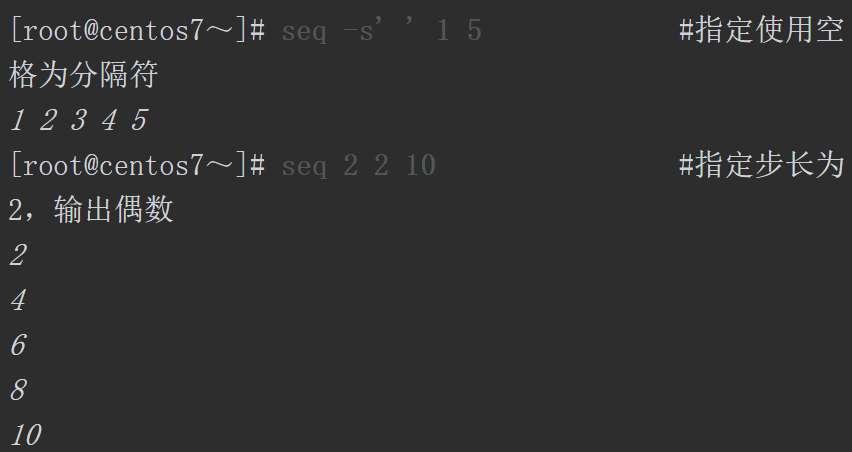
上面这条命令从1开始,最大到10,中间的步长是2。1+2=3,3+2=5,5+2=7,7+2=9, 9+2=11,因为11超出了1~10的范围,所以命令的实际最大输出结果为9。

但是,当在{}中调用其他变量时一定要注意,并不会得到我们想要的数字序列。

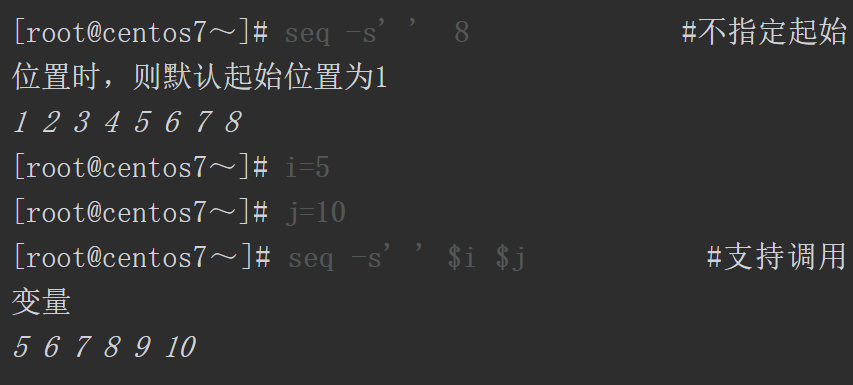
另外,还可以使用seq命令生成数字序列,并且可以调用其他变量,但该命令不支持生成字母序列。默认输出序列的分隔符是\n换行符,也可以使用-s选项自定义分隔符。

对有序的数字(年份)进行循环并判断其是否为闰年,就是一个不错的练习案例。
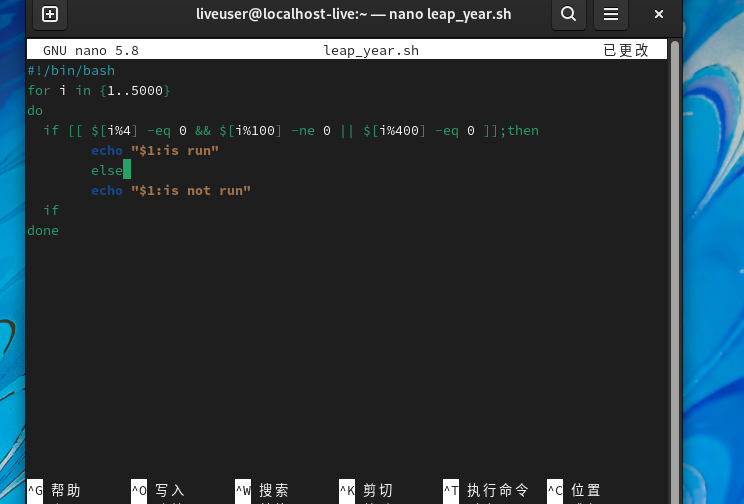
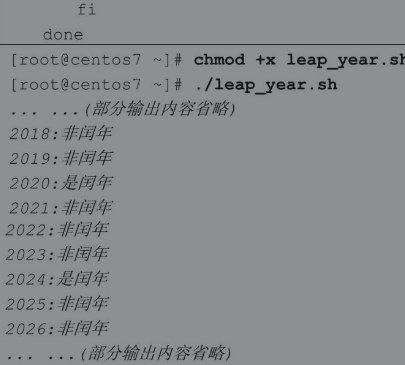
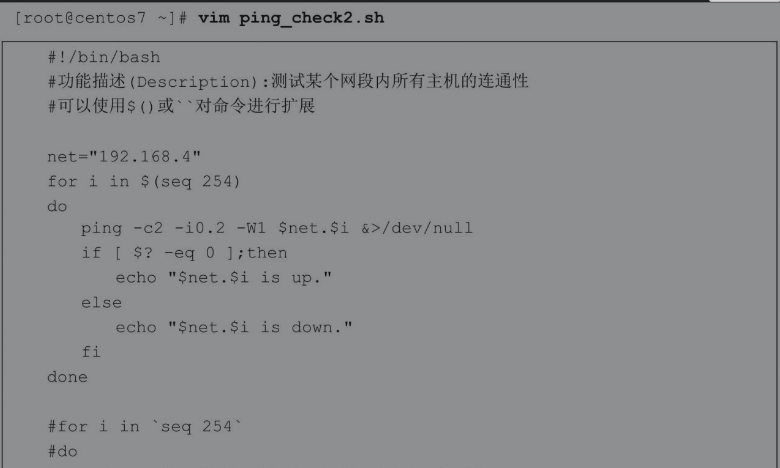
下面的脚本通过快速生成数字序列,测试某个网段内所有主机的连通性。虽然在Linux系统中可以通过安装Nmap快速测试主机的连通性,但是这些示例却可以帮助我们更好地理解for循环语句。通过大量类似案例的训练,可以为后续其他应用案例打下坚实的基础。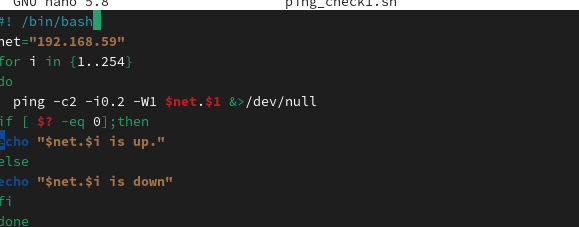
或者使用seq快速生成数字序列。因为seq是一个命令,而此时需要的是命令的执行结果,所以这里需要使用$()或``对命令进行扩展,获取命令的执行结果。
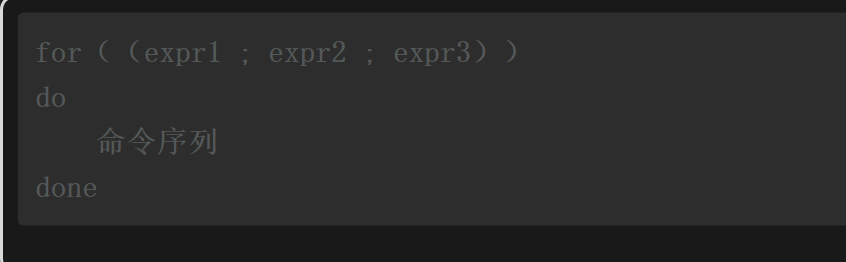
Bash Shell除了支持前面的语法格式,还支持C语言风格的for循环语法格式。熟悉C语言的开发者对for(i=1; i<=6; i++)这种语法格式肯定非常熟悉,但在Shell中需要额外添加一对括号。其基本语法格式如下
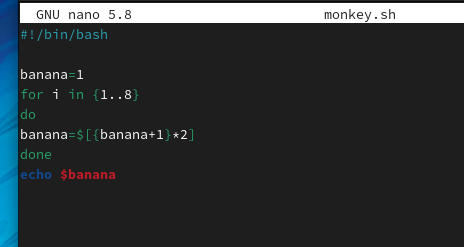
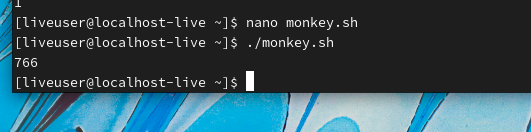
3.2实战:猴子香蕉
3.3 实战案例:进化版HTTP状态监控脚本
2.9节介绍了很多监控HTTP服务的脚本。但是,因为没有使用循环语句,所以检测结果都是以一次判断为依据的。而在实际生产环境中业务可能会发生短暂的健康抖动,从而造成服务处于不可用状态,但实际上服务是没有问题的。抖动的原因很多,如网络的问题、访问量的问题、计算机硬件的问题等。因此可以对服务做多次检测,比如3次检测都不正常,则认定为服务器故障。可以通过循环语句对特定的服务器页面进行多次检测,并设置一个失败次数的计数器,当失败次数等于3时则脚本报警,否则仅通过记录日志的形式记录状态。

3.4 神奇的循环嵌套
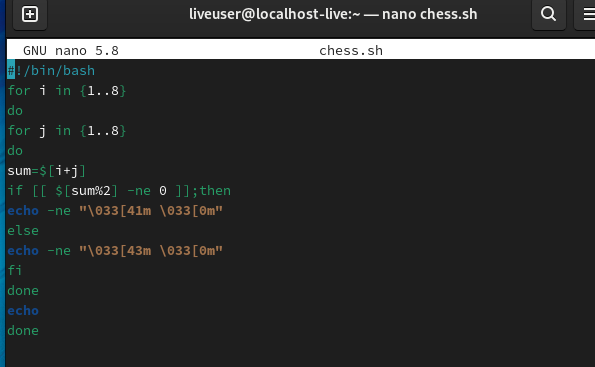
画出国际象棋棋盘
根据白色
行和列的求和为偶数
行和列的求和为奇数

3.5 非常重要的IFS
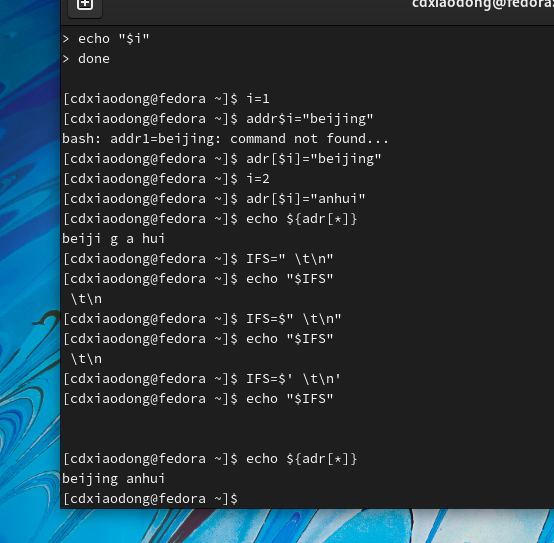
在Shell中使用内部变量IFS(Internal Field Seprator)来决定项目列表或值列表的分隔符,IFS的默认值为空格、Tab制表符或换行符。使用for循环读取项目列表或值列表时,就会根据IFS的值判断列表中值的个数,最终决定循环的次数。例如,A=”hello theworld”,当使用空格作分隔符时,变量A的值有三列。但是,当使用字母t作为分隔符时,变量A的值就有两列。所以当使用不同的分隔符时读取数据的结果也会有很大差别,这点在编写脚本时一定要注意!IFS的多个值之间是“或”关系,所以for循环在读取列表时,数据可以使用空格分隔,或使用Tab制表符分隔,或使用换行符对数据进行分隔。因为空格、Tab制表符和换行符都属于ASCII码表中的控制字符,是不可显示的内容,所以正常使用echo命令显示该变量的值时,是看不到内容的,但是可以通过od命令将数据转换为八进制数据后再查看。ASCII码表的全部内容较多
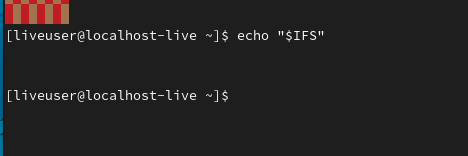
注意,当使用echo命令输出IFS的值时,因为IFS的值是空格或Tab制表符,所以无法显示具体内容。另外,因为IFS的值还可以是一个换行符,所以输出结果可以是一个独立的空白行,而echo命令在输出数据内容后又会自动进行一次换行,所以最后输出两个空白行!如果使用printf命令输出IFS值,就不会有两个空白行的情况发生,因为printf打印完内容后默认不换行。

不管是使用echo还是printf命令,在输出的结果中都无法显式地查看到具体的内容。但是,可以使用od命令将数据转换为八进制后再查看。

输出结果中的040是空格键、011是Tab制表符、012是换行符。因为IFS的原始值不容易设置,所以当需要修改IFS值时,最好提前备份其原始值
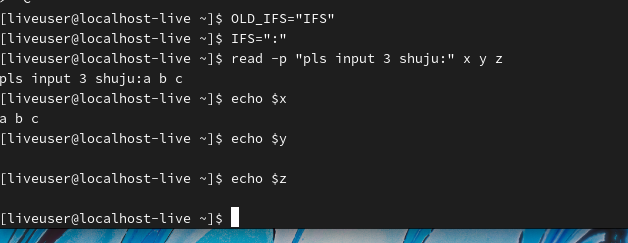
观察并分析上面这一组命令的结果可知,因为已经将IFS的值修改为冒号(:),而当通过read命令读取三个变量的值时,如果输入的3个字符是以空格为分隔符的,则系统会认为”a b c”是一个完整的数据,并将其赋值给变量x,这样就导致没有定义变量y和z的值,输出的变量y和z的值就为空。如果希望给x、y、z三个变量都赋值,就需要输入数据时使用冒号分隔数据。
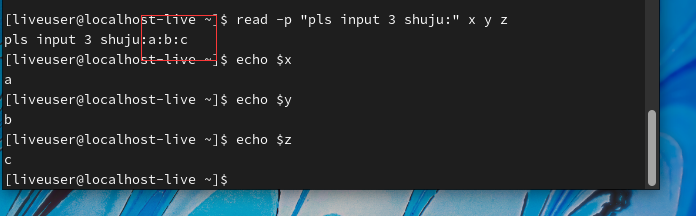
下面通过一系列的案例,再看看Shell脚本中使用for循环语句读取数据列表时,IFS对脚本又有哪些影响?

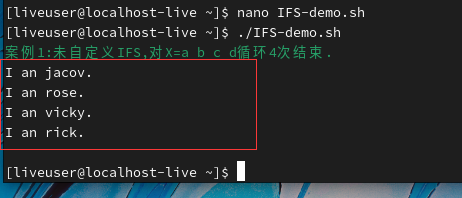
就是说只要是;.:中的任何一个都能成为分隔符
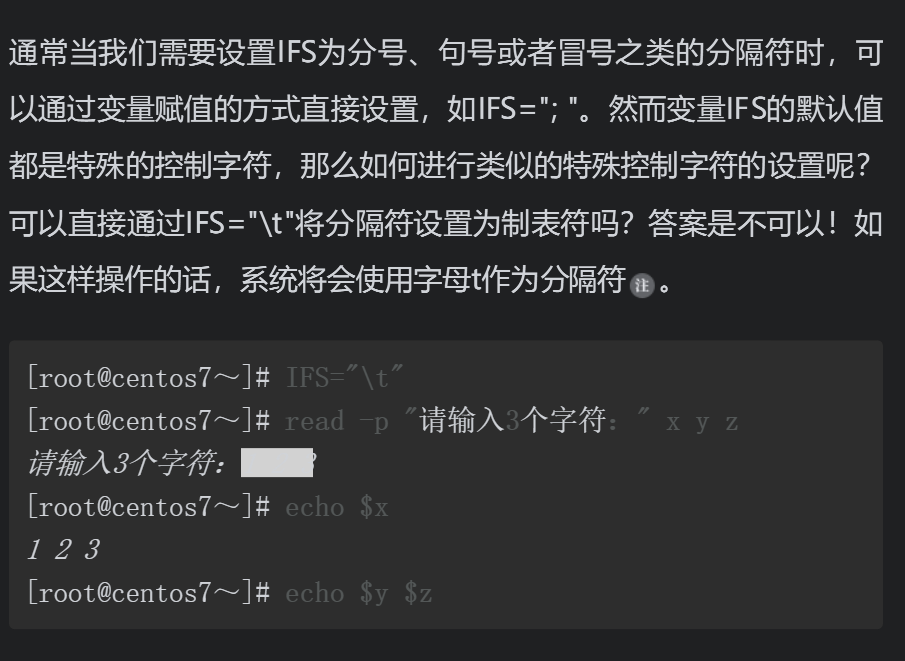
同样通过read命令读取3个变量的值,如果输入的数字字符之间使用t分隔,则系统会认为1、2和3是三个独立的值,并将这三个值分别赋值给变量x、y和z。最终使用echo命令回显变量值时,x、y和z变量都有正确的值
这也证明了,使用IFS=”\t”并不能将特殊的控制字符设置为分隔符。那么,该如何正确地将特殊的控制字符设置为系统默认的分隔符呢?当需要使用表3-2中特殊的控制字符作为分隔符时,必须使用$’string’方式进行设置,否则系统无法正确理解控制字符的含义。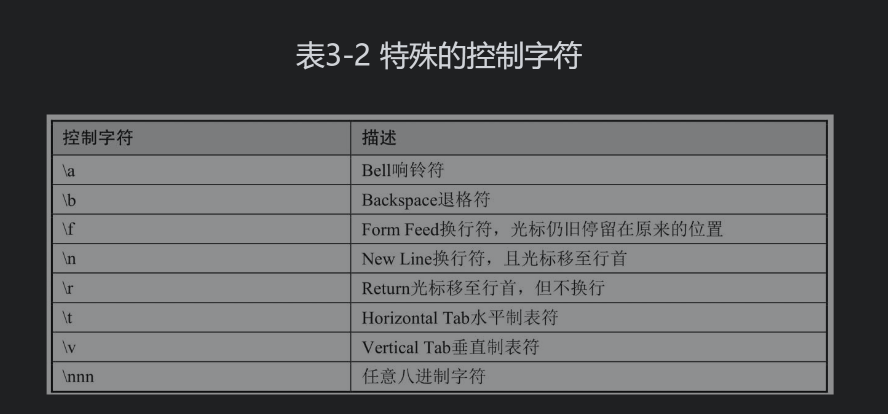
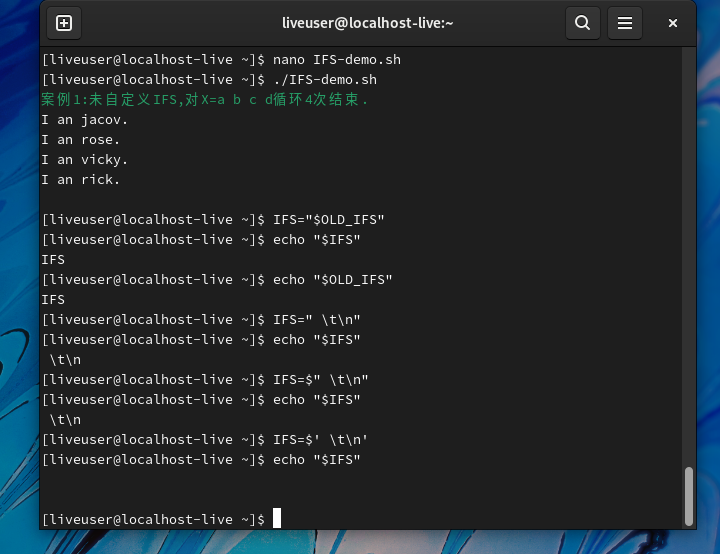
注意了 必须是‘ 而不是“
3.6 实战案例:while循环
while命令后面的条件判断只要语句命令返回码为0就代表真,否则代表假。并非仅仅可以写[]或[[]]判断,while的判断可以是任何可以执行的命令。比如编写一个实时检测服务进程状态的脚本,当Httpd服务进程启动时脚本进行持续的跟踪检测,而当Httpd服务进程关闭时则循环结束,脚本提示警告信息后退出。
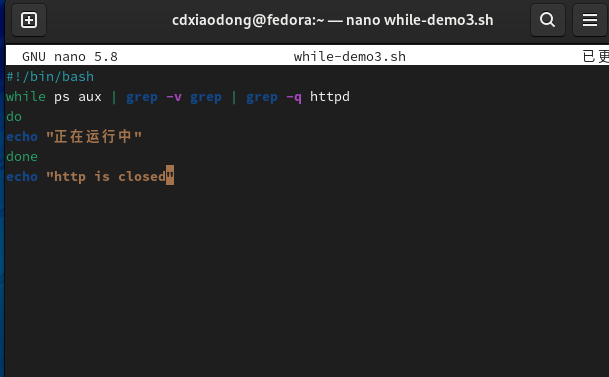

3.7死循环
前面的案例多数都是有限次数的循环脚本,但有些脚本则需要死循环执行,通常这种情况都会使用while true或while :来实现功能。在Shell中,true和:都是固定返回退出码0的空命令,这两个命令都不会进行任何实际的操作。与true相反的另一个命令为false, false命令是一个退出码为非0的空命令。

3.8 实战案例:如何通过read命令读取文件中的数据
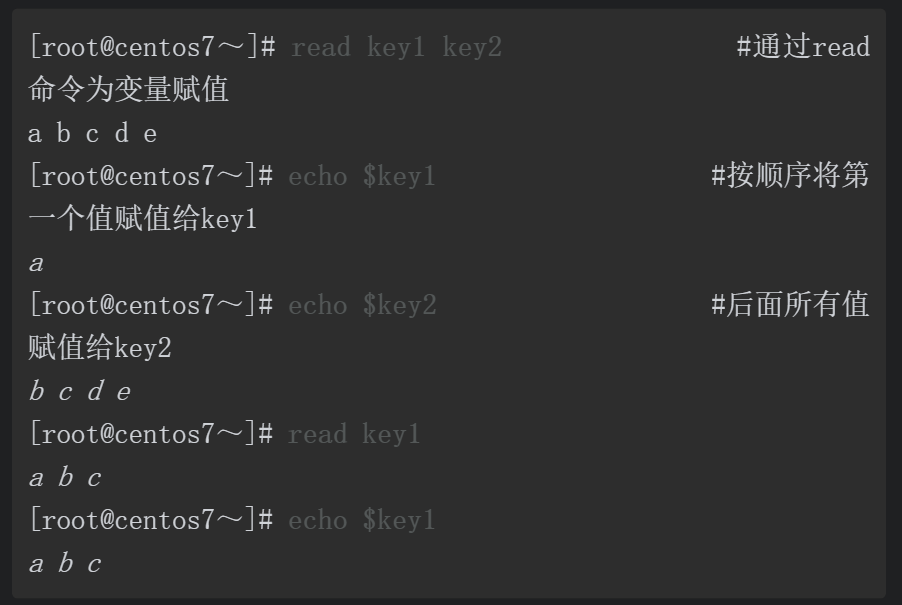
首先,回顾并了解read命令的几个特性。
当定义了三个变量,但输入时仅输入一个值时,则后两个变量的值为空。

当定义两个变量但输入三个或多个值时,则从第二个值开始及后面的所有值都会被赋值给第二个变量。如果只定义一个变量,那么不管通过键盘输入多少值都会被赋值给变量。
然后看如何结合while循环批量读取数据并通过read命令给变量赋值,基本格式如下。

开始执行while循环后,read命令会从标准输入或管道中读取数据,如果能读取到数据则执行do和done之间的所有命令,与标准while语句一样,命令执行完后会返回到while语句,继续下一次循环,直到read命令读取文件内容失败,则整个循环结束。下面通过几个简单的案例,学习基本语法格式。为此,需要先创建一个测试性的文本文件。
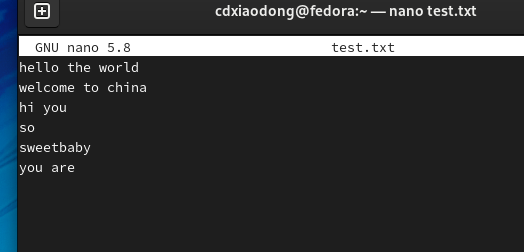
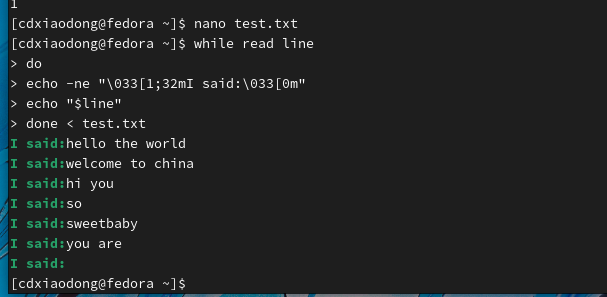
类似的方式,当使用read命令从文件中读取数据并赋值给两个变量时,每一行第一个空格前的内容会赋值给第一个变量,后面的所有内容会赋值给第二个变量。
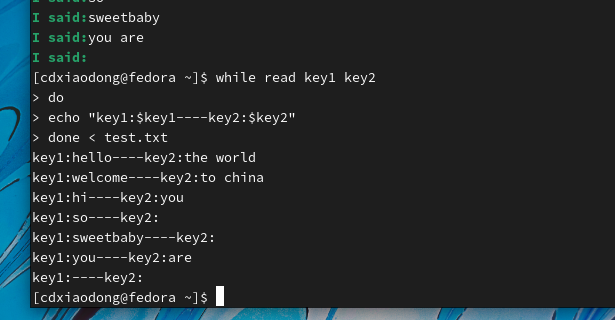
但是,如果数据文件的分隔符不是空格怎么办呢?通过read命令如何更好地处理这样的数据呢?可以通过修改IFS变量,实现自定义数据分隔符。下面看一个读取passwd文件的示例。

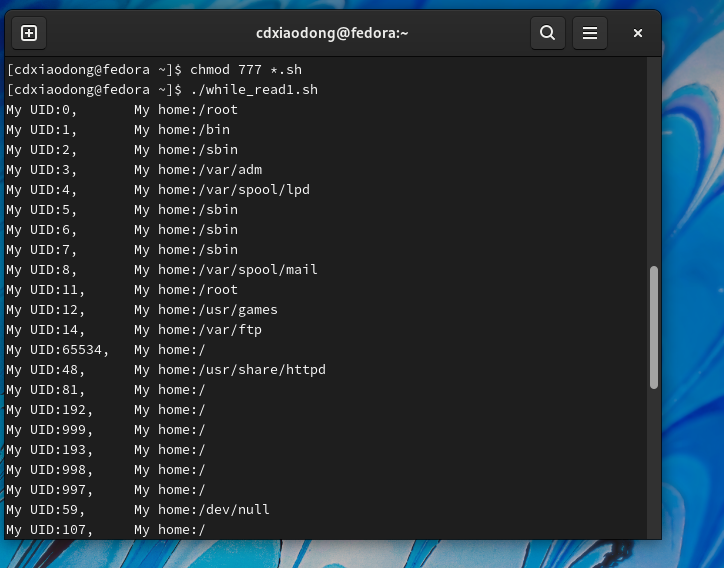
通过上面的示例,可以顺利地读取/etc/passwd文件中的每行数据。但直接在脚本开始时修改IFS变量的值,会对整个脚本都有影响,如果仅仅希望read命令在读取数据时以冒号为分隔符,同时又不影响其他程序,则可以使用如下的方式完成相同的工作。
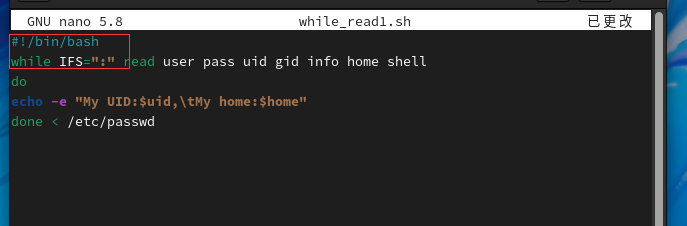
另一种语法格式是使用管道将数据传递给while循环,批量读取数据文件,下面通过一个命令行的案例,学习该语法格式。但需要注意,通常情况下使用重定向导入的方式往往比管道的效率高。

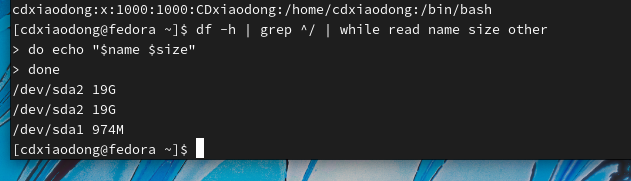
df是用来计算磁盘空间占用情况
-h是令1k计算为1000b
上面的命令首先过滤所有以/开始的分区挂载信息,然后将数据通过管道的方式传递给while循环,read命令定义了三个变量,name对应的是磁盘名称,size对应的是磁盘总容量,other对应的是其他所有信息。在while循环体内,通过echo命令输出磁盘设备名称和总容量。
3.9 until和select循环
在Shell脚本环境中还有另外两个循环语句,分别是until和select。until实现与while一样的功能,select循环主要用于创建菜单选项。
until语句的语法格式如下。
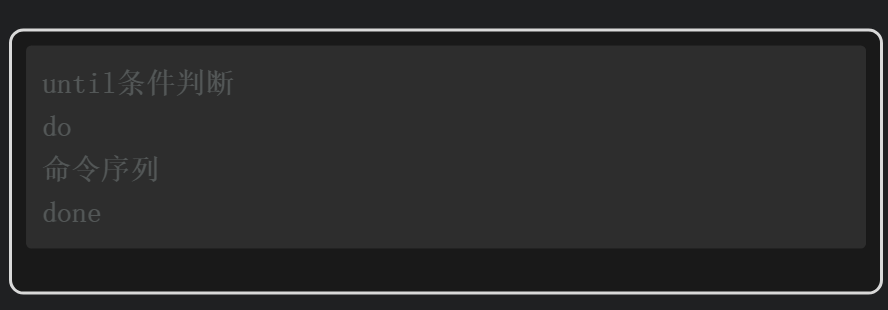
与while语句相反,until循环语句只有当条件判断结果为真时才退出循环,而当条件判断结果为假时则执行循环体中的命令。

由于until语句与while语句可以实现相同的功能,在生产环境中更多地会使用while语句编写循环脚本,所以这里也仅通过一个简单的示例学习until语句的语法格式即可。
使用select循环的主要目的是方便地创建菜单,其基本语法格式如下。
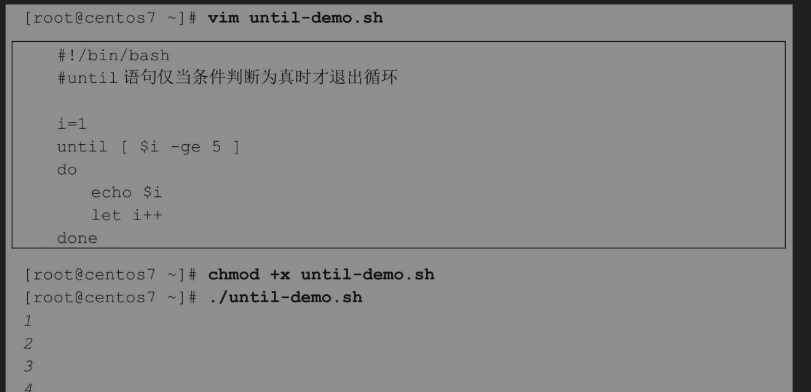
下面通过一个查看系统信息的脚本来看select语句的应用示例。
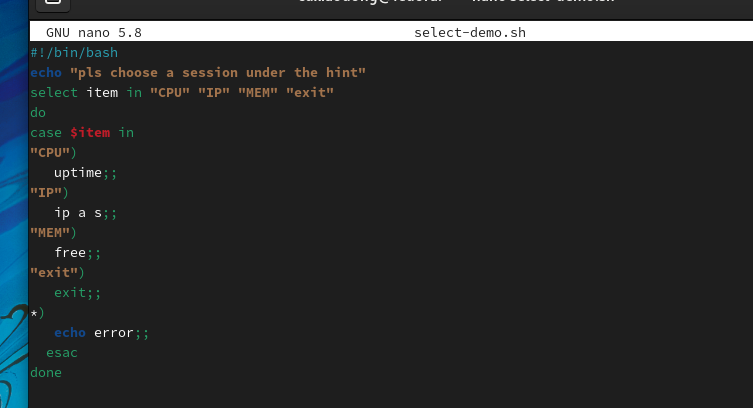
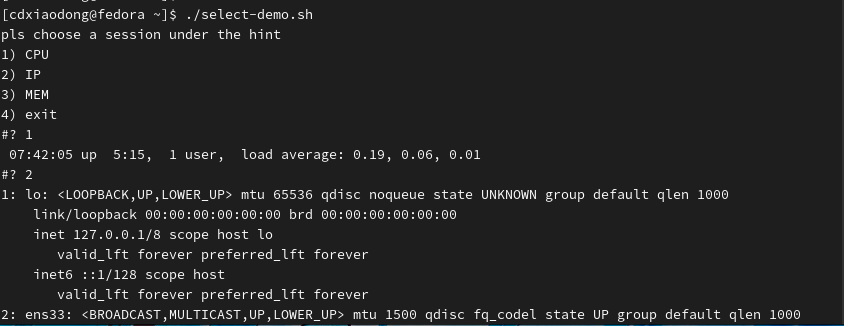
3.10 中断与退出控制
在执行循环的过程中,有时候并不希望执行完所有的循环命令!比如,如果编写了一个循环脚本,脚本会通过循环逐一访问远程某个网段(如192.168.4.0/24)内的所有主机,并试图将所有主机重启或关机。但是如果执行脚本的这台主机的IP地址也在这个网段内呢?所以,在有些特殊的情况下并不希望完整地执行完所有循环命令。Shell针对循环专门设计了中断与退出语句:continue、break和exit。
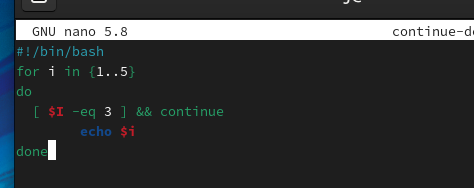
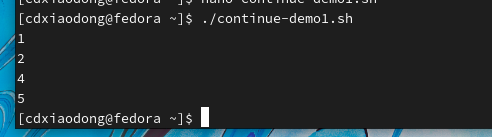
下面再学习另外一个中断命令break,该命令可以结束整个循环体,break后面的所有语句不再执行,并且整个循环提前结束。如果脚本使用了循环的嵌套功能,则break命令后面可以跟数字参数(数字要求大于或等于1),表示对第几层循环执行中断。下面通过简单示例演示它的功能。

最后看一个中断级别最高的命令exit,该命令会直接结束整个脚本,exit后面也可以跟数字参数,表示脚本的退出状态,如果没有指定数字参数,则脚本的退出状态就是上一个命令的退出状态。下面通过几个简单示例演示它的功能。
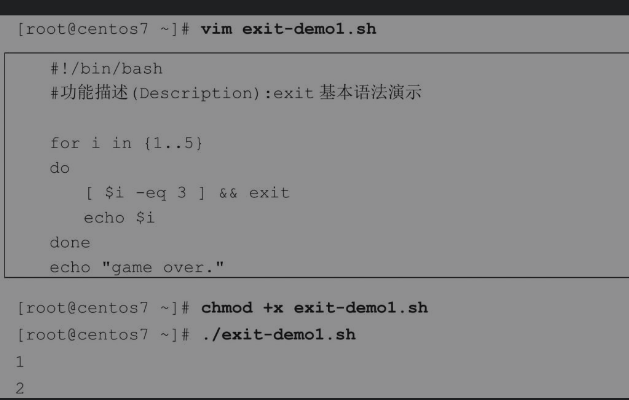
分析脚本执行结果,与break示例一样,前面两次循环正常输出数字1和2,当循环至第三次i取值为3时,exit命令被触发导致整个脚本结束,虽然循环体中后面还有echo命令,但是后面有再多命令也不会被执行。
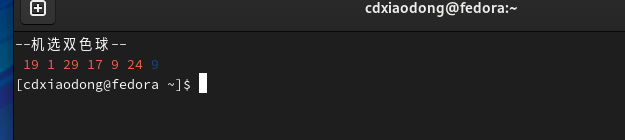
3.11 Shell小游戏之机选双色球
双色球彩票投注分为红色球和蓝色球,每注投注号码由6个红色球号码和1个蓝色球号码组成,红色球号码从1~33中选择,蓝色球号码从1~16中选择,投注时不管是红色球还是蓝色球都不允许出现重复的号码。
为了编写这样一个机选双色球的脚本,需要先了解几个技巧。
通过+=的方式,可以将任意个数的字符追加保存到一个变量中,而机选双色球中的红色球就需要这样的一个变量,在这个变量中保存所有随机的6组红色球号码。
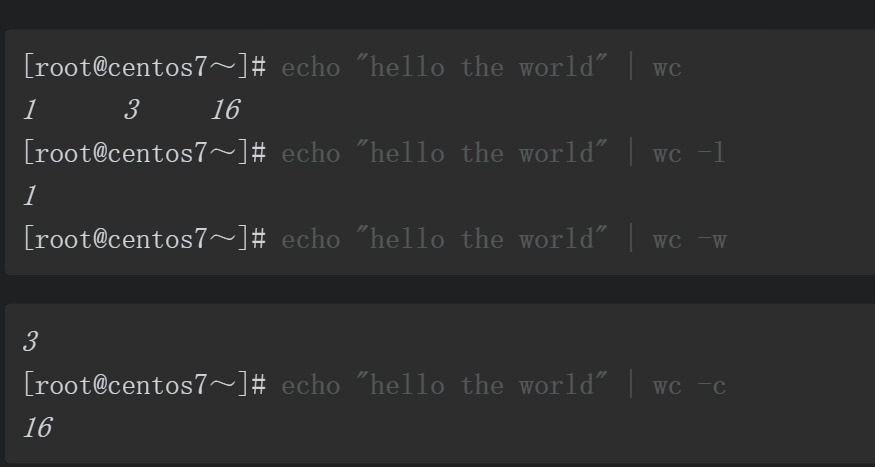
使用wc命令可以对数据进行统计操作,不同的选项输出的结果不同

4请开始你的表演,数组、Subshell与函数
4.1数组
shell支持一种特殊的变量——数组。数组是一组数据的集合,数组中的每个数据被称为一个数组元素。目前Bash仅支持一维索引数组和关联数组,Bash对数组大小没有限制。
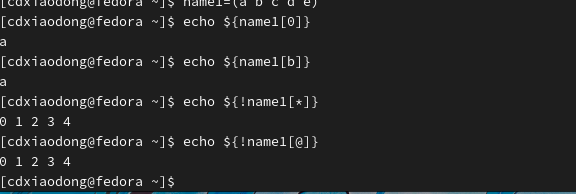
定义和调用索引数组的基本语法格式如下。
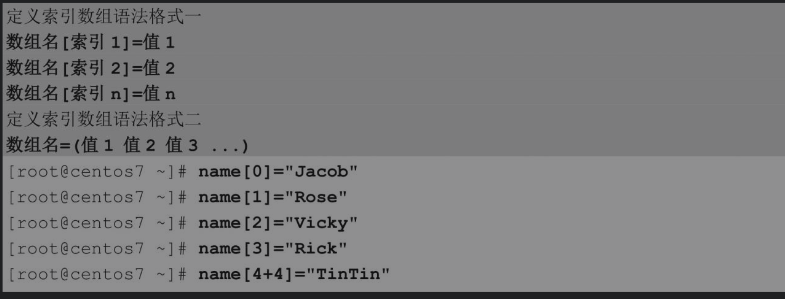
这里定义了一个变量名称为name的数组,该数组中存储了5组数据,索引(也称为下标)分别为0、1、2、3、8,索引可以是算术表达式,但要求运算的结果是整数。可以通过索引定义数组,同样也可以使用索引获取数组中某个元素的值。注意,数字索引可以是一个变量,索引可以不连续。


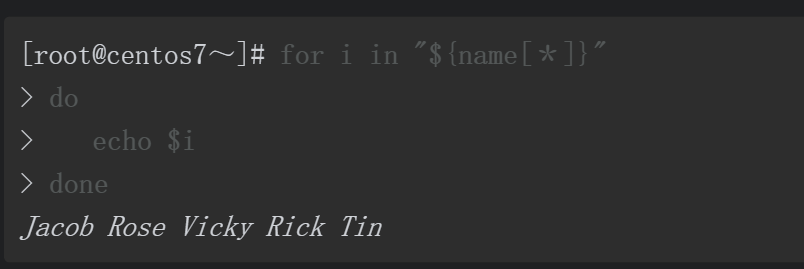
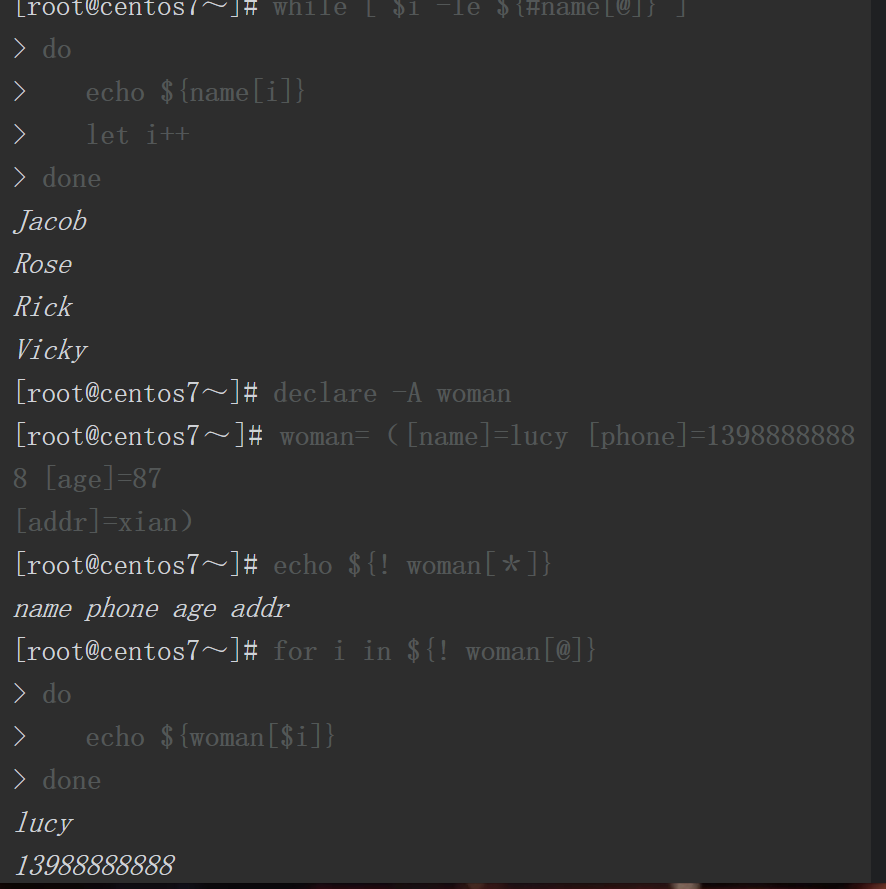
因为${name[*]}将所有数组元素视为一个整体,所以for循环仅循环一次就结束,变量i也仅取一次值,i=”Jacob Rose Vicky RickTin”。
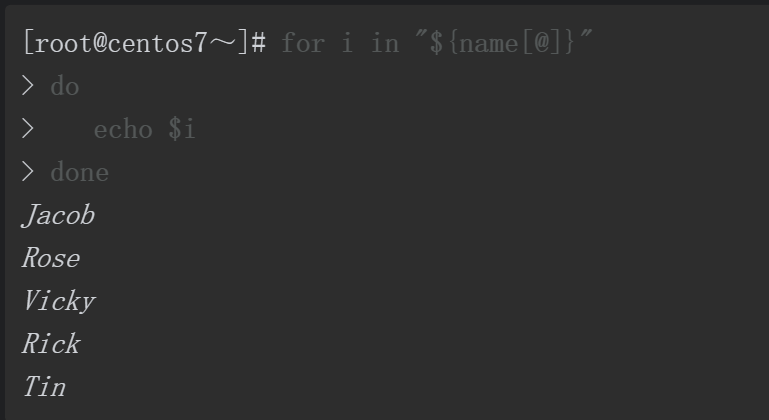
因为${name[@]}将所有数组元素视为独立的个体,所以name数组中有多少个元素,for循环就会循环多少次,每循环一次变量i获取其中一个元素的值。
在使用数组时,数组的索引也可以是变量,这个功能Shell脚本中的普通变量是不可能实现的。
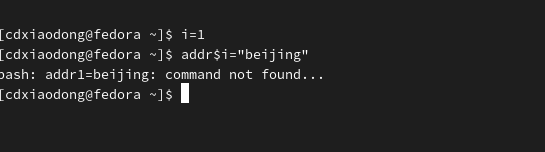
#报错,变量名不能使用变量
使用第二种方式创建数组与使用第一种方式效果一样。使用第二种方式创建的数组,虽然没有明确指定索引,但系统会默认使用以0为起始值的有序数字为索引。所有数组元素的值之间使用空格符分隔。
获取数组的所有索引
使用$()或``也可以将命令的执行结果赋值给数组变量。

df /

删掉标题 直接从第二行开始
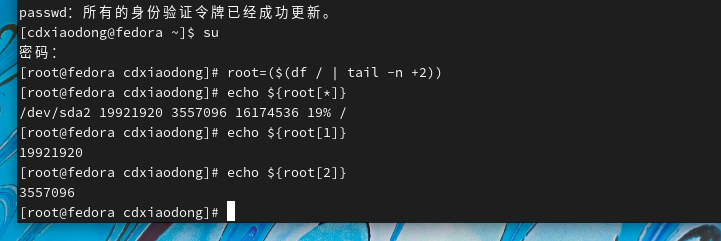
除了可以使用数字作为数组的索引,是否还可以使用其他的字符串作为数组的索引呢?从4.0版本开始Bash为我们提供了一种新的关联数组,使用关联数组,数组的下标可以是任意字符串。关联数组的索引要求具有唯一性,但索引和值可以不一样。

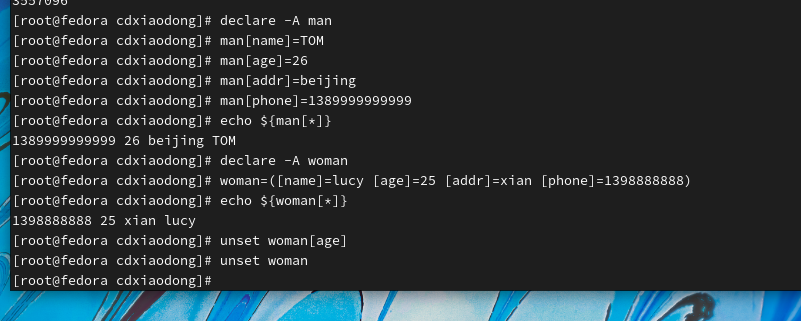
unset A【b】#删除数组中某个袁术
unset A#删除整个数组
虽然可以使用${数组名[@]}或${数组名[*]}一次性获取数组中所有元素的值,但是如何单独将数组中的每个元素值提取出来呢?使用循环可以遍历数组的所有元素的值。

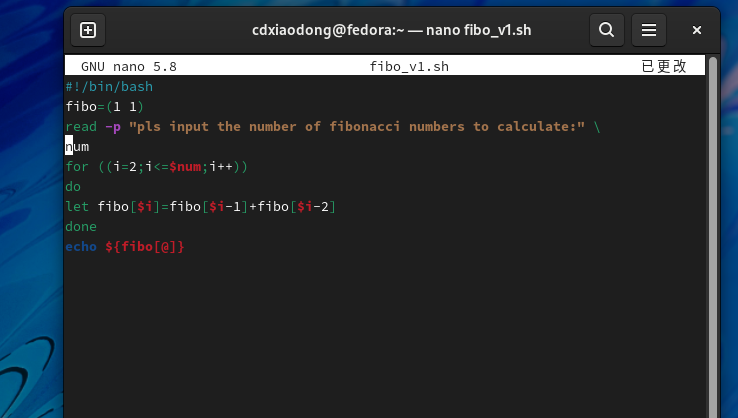
4.2 实战案例:斐波那契数列
斐波那契数列表

该数列的特点是从第3个数开始,后面的数字等于前面两个数字之和,如1+1=2,1+2=3, 2+3=5,3+5=8…
总结推导公式为:F(n)=F(n-1)+F(n-2)(n>=3, F(1)=1,F(2)=1)。
另外,该数列当n趋向无穷大时,前一项的值除以后一项的值所得结果无限接近黄金分割比例(0.618)。1/1=1, 1/2=0.5, 2/3=0.666,3/5=0.625, …,1346 269/2178 309=0.618033 988 75。因此,斐波那契数列也被称为黄金分割数列。
如何使用Shell计算斐波那契数列呢?可以将计算的数字保存到一个数组中,数组的索引就是1,2,3,4等,数组第三个元素的值等于第一个元素和第二个元素值的和,第四个元素的值等于第二个元素和第三个元素值的和。具体代码如下。

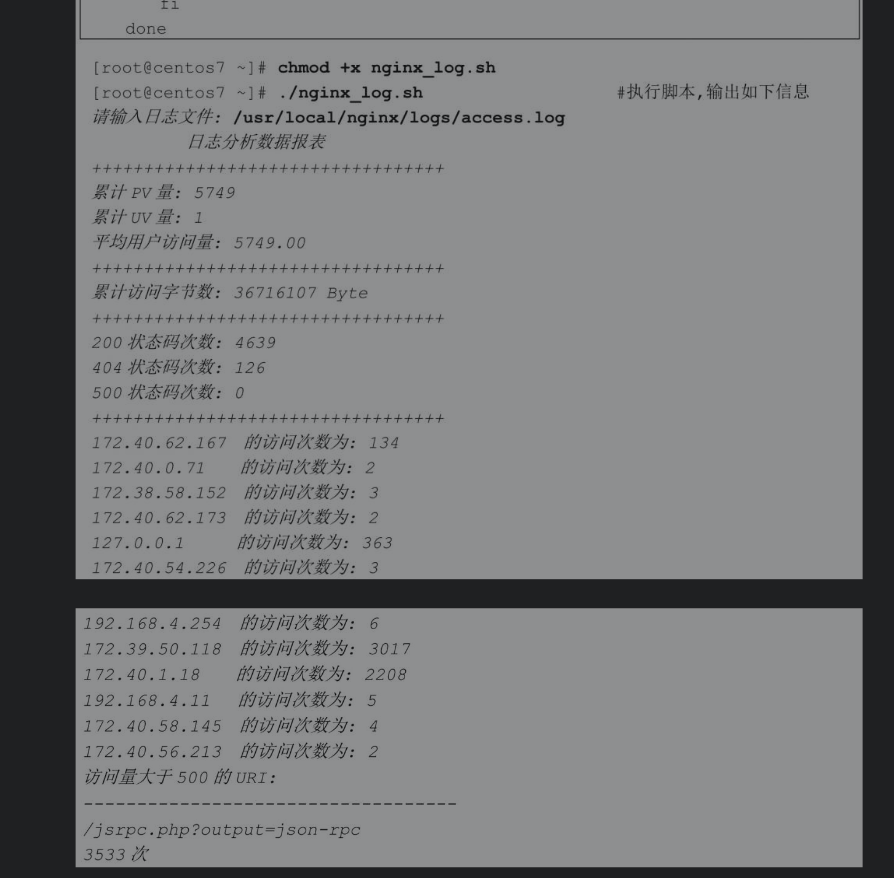
4.3 实战案例:网站日志分析脚本
通常情况下各种业务服务都会产生大量的日志文件,而对日志文件数据进行分析、统计是日常运维工作中非常重要的一个环节。通过对日志文件数据的分析,可以了解业务的运行状态、是否存在潜在的安全威胁、热点数据、时间段趋势、客户来源等信息。
使用数组可以非常方便地对数据进行存储与统计,下面以Nginx的日志文件为例,编写一个访问日志文件的分析脚本。在使用脚本分析日志文件前需要了解Nginx访问日志的内容与格式,Nginx访问日志案例如下。

在这条日志消息中,172.40.62.167是客户端的IP地址。第二列是一个固定的字符串”-“,没有任何含义。当Nginx配置了用户认证后,客户端访问网站时输入用户名和密码,则第三列的内容为用户名,如果没有配置用户认证则这一列也是固定字符串”-“。第四列方括号内的内容为服务器本地时间(客户端在什么时间访问的服务器)。第五列双引号内的内容包括客户端请求的页面和使用的协议,协议一般为HTTP/1.1或HTTP2.0。第六列为HTTP返回的状态码。第七列是Nginx服务器发送给客户端的字节数(不包括响应头的大小)。第八列告诉服务器客户端是从哪个页面链接访问的,没有通过任何链接访问时这列内容为固定字符串”-“。第九列双引号内的内容是客户端信息,包含客户端使用的操作系统及浏览器等信息。


4.4 常犯错误的SubShell
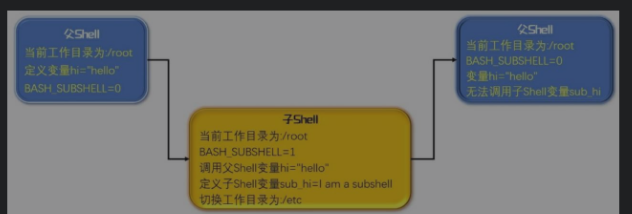
通过当前Shell启动的一个新的子进程或子Shell被称为SubShell(子Shell)。子Shell会自动继承父Shell的很多环境,如变量、工作目录、文件描述符等,但是反之,子Shell中的环境仅在子Shell中有效,父Shell无法读取子Shell的环境。例如,如果在父Shell中定义全局变量,子Shell中就可以调用该变量。但当在子Shell中定义一个局部或全局变量时,父Shell是无法读取该变量的。基于这样的特性,编写的脚本有时就可能出现潜在的问题。
如何生成子Shell呢?使用分组命令符号()就可以让命令在子Shell中运行,通过Shell变量BASH_SUBSHELL可以查看子Shell的信息,该变量的初始值为0,每启动一个子Shell该变量的值会自动加1,下面通过简单的示例验证效果。
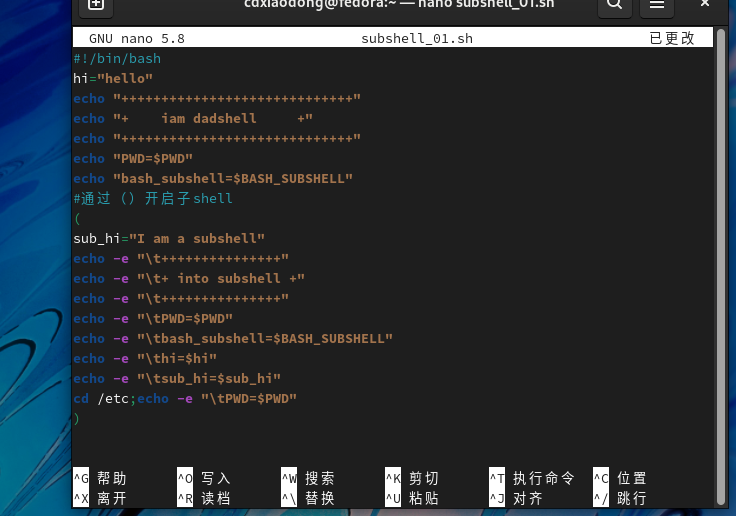

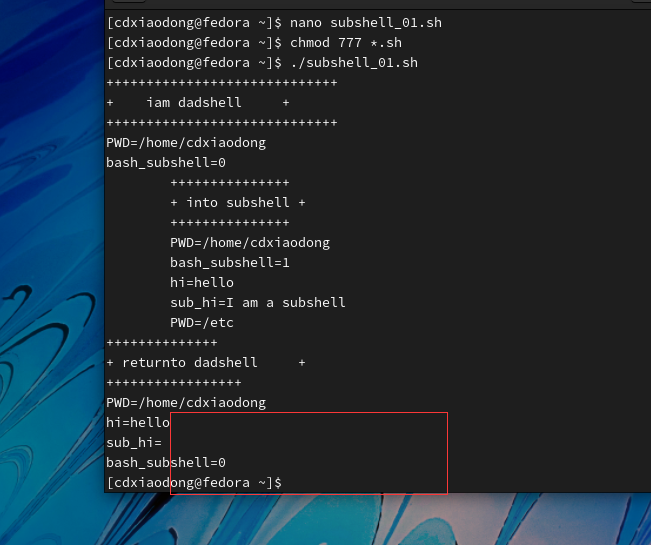
分析脚本执行结果,启动脚本后进入的Shell被认为是父Shell,当前工作目录是/root,变量BASH_SUBSHELL的值为默认初始值0。通过()启动了一个子Shell,子Shell继承了父Shell的变量与工作目录等环境信息,因此,在子Shell中当前工作目录依然是/root,父Shell定义的变量hi,在子Shell中依然可以正常使用并在屏幕上显示该变量的值,同时变量BASH_SUBSHELL的值会自动加1(结果为0+1=1)。最后为了验证父Shell不可以读取子Shell的环境信息,在子Shell中定义了一个名称为sub_hi的变量,并在子Shell中切换工作目录到/etc。当()结束脚本再次回到父Shell时,会发现子Shell切换工作目录对父Shell无效,父Shell当前工作目录依然是/root,而子Shell定义的变量sub_hi在父Shell中也无法被调用,父Shell开始时定义的变量hi依然可以使用,回到父Shell后BASH_SUBSHELL自动减1(1-1=0)。
除了()可以启动子Shell,还有别的方式可以启动子Shell吗?
使用&符号将命令放入后台会产生新的子Shell,另外使用管道符号|或者分组命令符号()也会产生新的子Shell,使用命令替换$()也会产生新的子Shell,在Shell脚本中执行一个外部命令同样会启动新的子Shell。
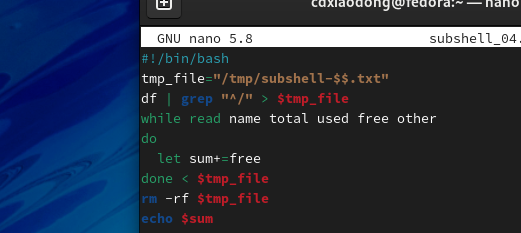
先来看一个使用管道开启子Shell后导致脚本运行错误的案例。该脚本希望通过循环读取df命令并输出第四列内容,统计所有存储设备剩余容量的总和。
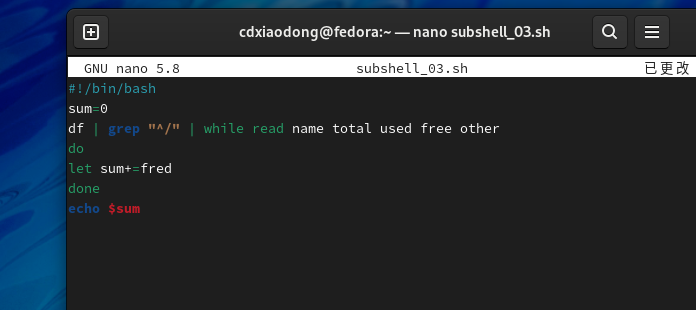

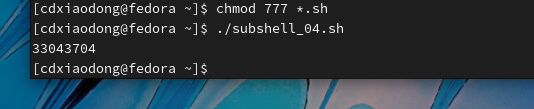
上面的脚本之所以返回值为0,是因为使用了管道符号,管道会导致整个while循环都在子Shell中执行,在子Shell中通过循环读取df命令输出的第四列值并求和,而等所有循环结束,脚本返回父Shell后,子Shell中计算的所有值在父Shell中都无法被调用。为了方便追踪错误,将上面的脚本进行适当修改,重新编写如下脚本。
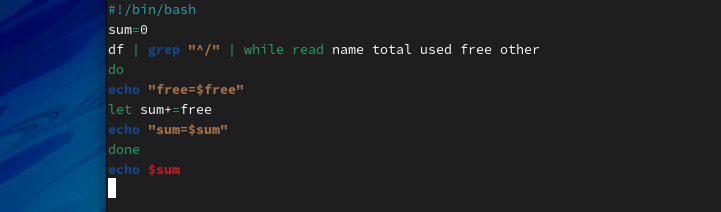

分析脚本执行结果,通过管道进入子Shell后,确实可以读取磁盘剩余容量
可以正常工作的。但是,当所有设备容量都读取完毕,循环结束后脚本会返回父Shell中,在父Shell中再次显示sum的值时,输出结果为0。
如何才可以解决这样的问题呢?通过文件重定向的方式读取文件,就不会再开启子Shell。所以,在前面的nginx_log.sh日志分析脚本中,在需要读取文件并对文件进行分析时应该使用重定向输入,而不是使用管道开启子Shell。
在脚本中使用外部命令,包括加载其他脚本也都会开启一个子Shell,所以在脚本中需要调用其他脚本时一定要使用source加载。
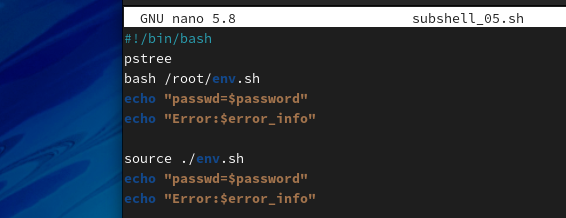
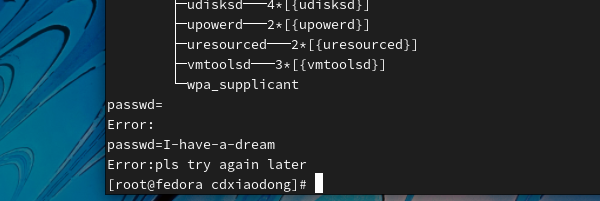
从脚本执行的结果可知,在脚本中调用外部命令pstree时,查看进程树可以看到pstree命令是在subshell_05.sh下启动的一个子进程。而通过Bash调用env.sh脚本也会产生子Shell,读取完env.sh程序返回父Shell后,再显示变量的值则为空。因此,如果需要在脚本中调用其他脚本最好使用source命令加载,使用source命令加载脚本不会开启子Shell。
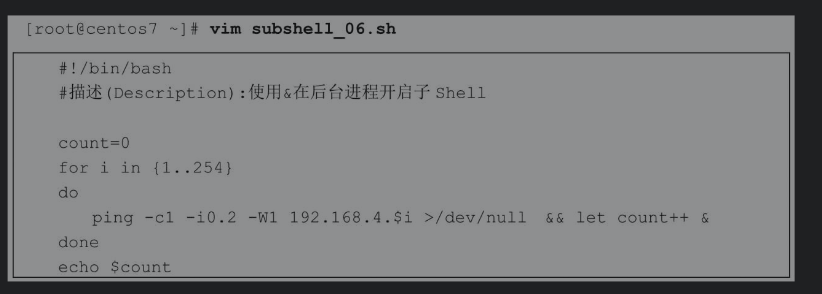
最后看一个后台进程的问题示例。前面章节中我们编写了测试某个网段内所有主机是否可以连通的脚本,但是默认仅在ping通主机1之后才会继续测试主机2,依此类推。如果测试一台主机需要3秒,254台主机就需要762秒(约12分钟),可以使用&将ping命令放入后台,这样做的好处是可以并发测试。下面的脚本通过变量count统计可以连通的主机数量,但是,因为&也会导致启动子Shell,所有子Shell中定义的计算变量的值无法在父Shell中调用,结果就导致脚本执行完成后,屏幕返回值永远为0。
4.5 启动进程的若干种方式
接下来讨论在Shell中执行命令创建进程的几种方式:fork方式、exec方式、source方式。
1)fork方式
通常情况下在系统中通过相对路径或绝对路径执行一个命令时,都会由父进程开启一个子进程,当子进程结束后再返回父进程,这种行为过程就叫作fork。当脚本中正常调用一个外部命令[插图]或其他脚本时,都会fork一个子Shell进程,我们的命令会运行在这个子Shell中。比如下面这个脚本中的所有语句都会fork一个子进程。
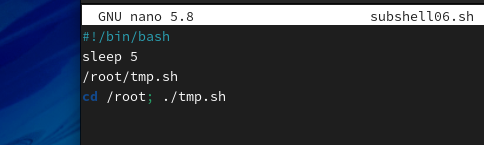
这个脚本在执行的过程中会打开另一个终端窗口,反复执行pstree可以获得如下的进程树信息。可以看出,当脚本调用一个外部命令sleep时,系统会fork一个子Shell, sleep命令是在子Shell中执行的。当脚本通过相对路径或绝对路径调用其他脚本(如tmp.sh)时,也会fork一个子进程,并且tmp.sh脚本中的命令被触发执行时也会再次fork子进程。

使用fork方式开启的子进程是父进程的一个副本,因此会自动单向继承父进程的环境,如环境变量、位置变量、资源权限、内存中的数据、信号等。但是,父进程无法继承子进程的环境。
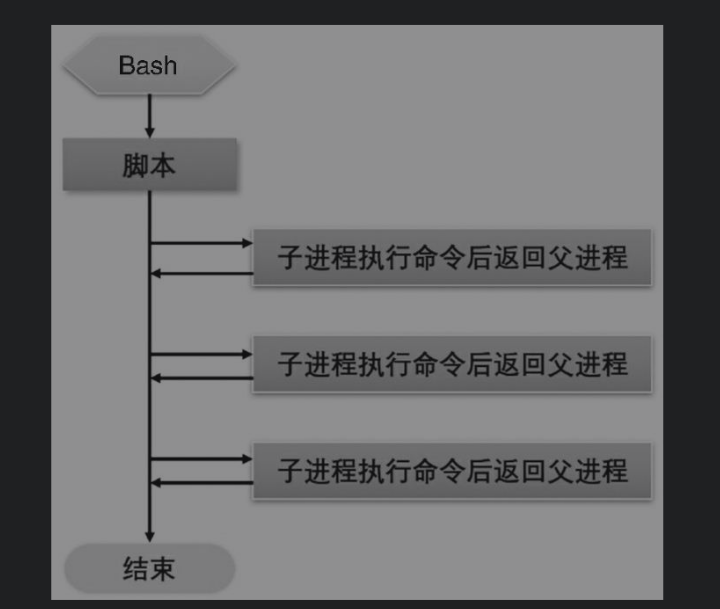
脚本开启子进程流程图
2)exec方式
也可以使用内部命令exec调用其他命令或脚本,语法格式如下。
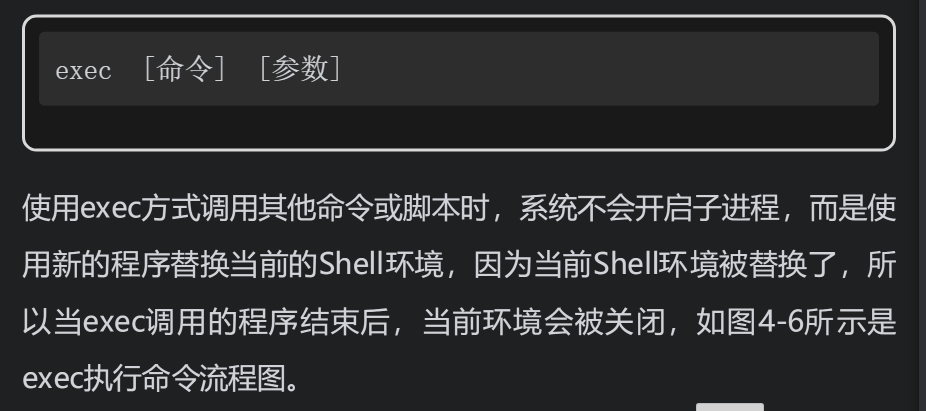
如图所示,一个脚本中包含三个命令,一个是通过exec执行ls命令,一个是使用echo命令让屏幕回显一个字符串信息,最后一个是cd命令,用于切换目录。但是,因为第一个命令使用exec调用ls,系统会使用ls命令替换当前的整个脚本,整个进程就变成了一个ls命令,当ls命令结束后进程也就结束了。原脚本中exec后面的所有命令都不会再被执行!为了防止当前脚本被覆盖,一般都会将exec写入另一个脚本,先使用fork方式调用该脚本,然后在fork的子进程中调用exec命令。下面这个脚本在执行完ls命令后会直接退出

但是有一个特例,当exec后面的参数是文件重定向时,不会替换当前Shell环境,脚本后续的其他命令也不会受到任何影响。
3)source方式
使用source命令或.(点)可以不开启子Shell,而在当前Shell环境中将需要执行的命令加载进来,执行完加载的命令后,继续执行脚本中后续的指令。
下面看一个简单的示例。

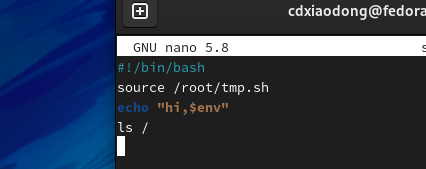

在上面的source.sh脚本中使用source命令加载/root/tmp.sh脚本,source命令会在不开启子Shell的情况下,将tmp.sh中的所有命令加载到当前Shell环境中,类似tmp.sh文件中的所有命令是编写在source.sh文件中的一样

从进程树的角度分析,如果不使用source命令加载tmp.sh,而是直接使用路径调用脚本,则进程树效果如下。
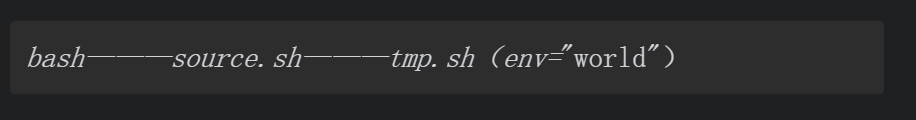
如果使用source命令加载其他脚本(如tmp.sh),则其他脚本中的命令将被载入当前Shell中直接执行,进程树效果如下。
4.6 非常实用的函数功能
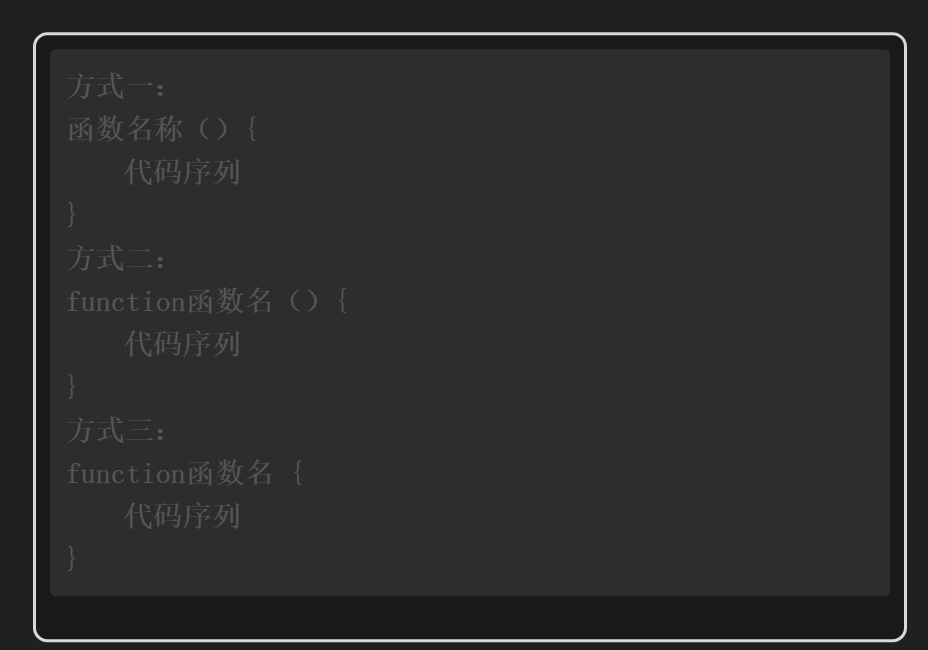
与大多数开发语言一样,Shell同样支持函数功能。函数就是给一段代码起一个别名,也就是函数名,定义函数名的规则与定义变量名的规则基本一致,但是函数名允许以数字开头。使用函数可以方便地封装某种特定功能的代码,在调用函数时不需要关心它是如何实现的,只需知道这个函数是做什么的,就可以直接调用它完成某项功能。函数必须先定义,才能被调用。合理地使用函数可以将一个大的工程分割为若干小的功能模块,代码的可读性更好,还可以有效避免代码重复。
定义函数的语法格式有多种,可以任选一种方式,调用函数时直接写函数名即可。
在命令行就可以直接演示函数的定义和调用,下面是简单的语法格式演示。
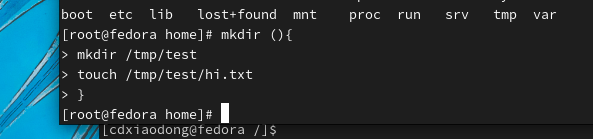
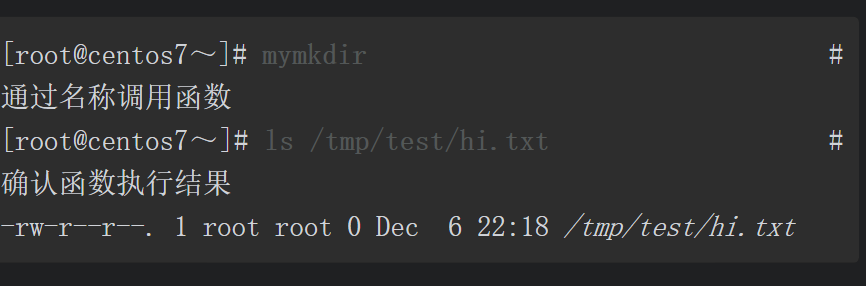
定义函数并不会导致函数内的任何命令被执行,仅当通过函数名称调用时,函数内的命令才会被触发执行。
如果需要取消函数,可以使用unset命令取消函数的定义。

在实际编写脚本时,经常会使用函数的功能给脚本编写提示信息,比如脚本的帮助或用法信息。下面就是这样的示例脚本文件。
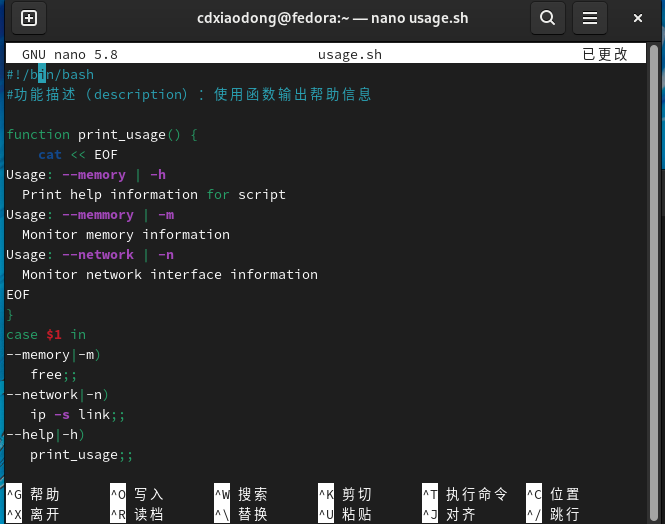

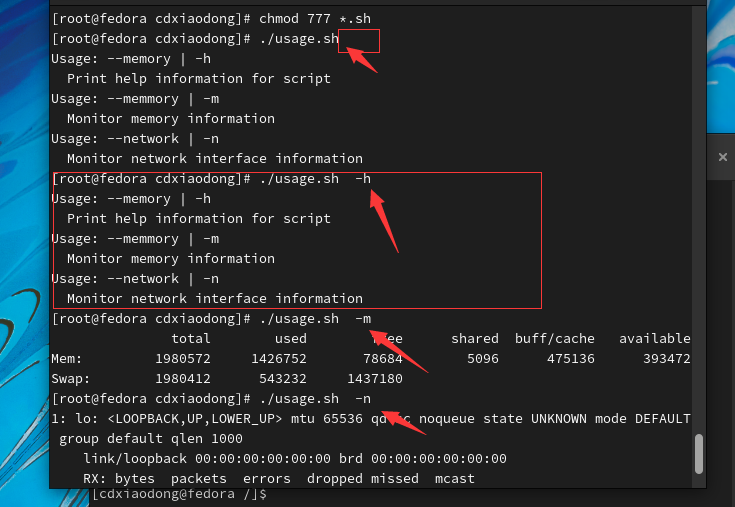
通过上面的示例可以知道,函数其实类似于别名,就是给一段代码起一个别名,当调用该别名时函数中的代码就会被触发执行。但是,前面示例中的函数并不能被反复调用,因为函数体内编写的代码用的全部都是常量,所以在第二次被调用时就会创建名称相同的目录与文件。这样的函数非常不灵活。怎么解决这个问题呢?答案是使用变量!Shell中的函数支持传递参数,可以通过向函数体内传递变量参数,确保函数可以被反复调用。
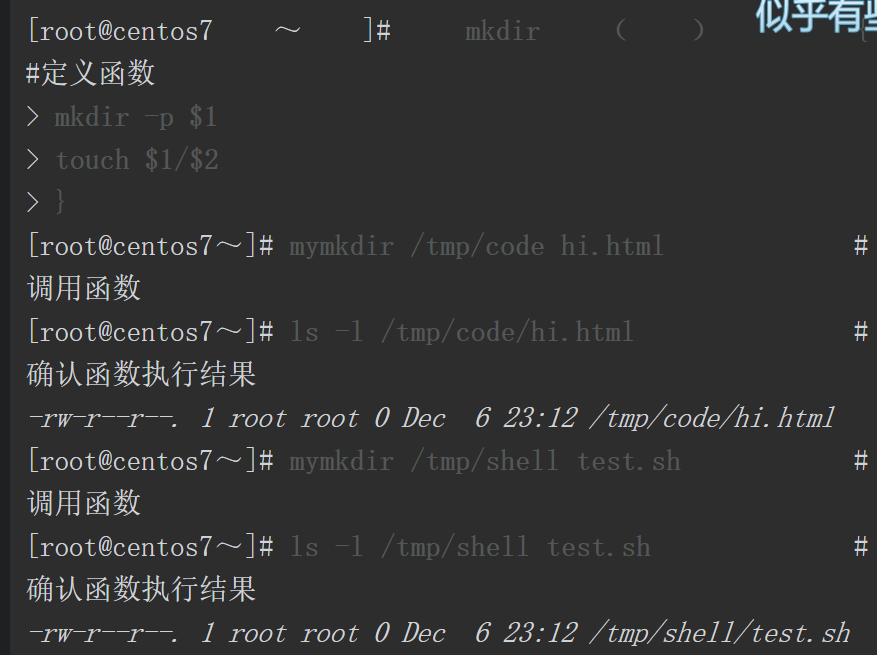
在函数体内部可以通过变量$1、$2读取位置参数,在调用函数时添加相应的参数即可,或者读取其他全局变量都可以实现传递变量参数的功能。
实现上面功能的函数代码如下。
有了这种通过位置变量传递参数的机制,就可以使用函数编写更加灵活的脚本,比如监控服务功能就可以写成函数,通过传递变量就可以编写一个通用的监控服务是否启动的脚本。
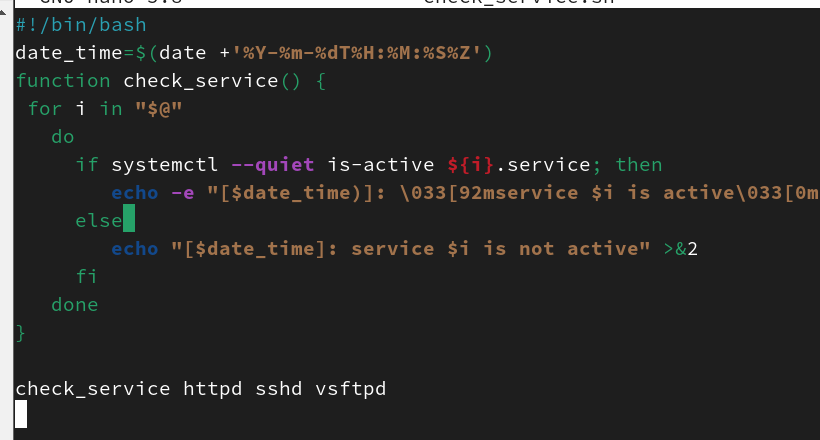
上面的脚本在调用函数时添加了不止一个参数,而在函数体内通过$@就可以读取所有位置参数,并通过for循环遍历每一个参数,在for循环内部使用if语句判断服务是否启动。这个脚本中定义的函数也可以被反复调用,每次调用时添加不同的位置参数,即可检测不同服务的状态。
4.7 变量的作用域与return返回值
Shell脚本中执行函数时并不会开启子进程,默认在函数外部或函数内部定义和使用变量的效果相同。函数外部的变量在函数内部可以直接调用,反之函数内部的变量也可以在函数外部直接调用。但这样会导致变量混淆、数据可能被错误地修改等问题,下面通过一个示例看看变量的作用域问题。
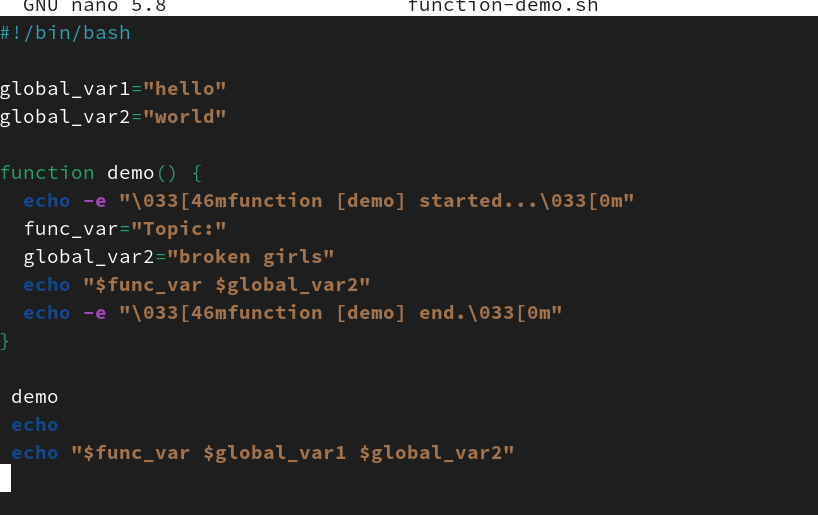

分析脚本输出结果,在demo函数外部定义的两个变量在函数内部都可以被调用,并且还可以被修改。默认global_var1和global_var2为当前Shell环境中的全局变量[插图],而执行函数不会开启子Shell,因此在函数内部也可以调用和修改变量。示例中在函数内部修改了global_var2的参数值,而在demo函数中定义的变量func_var默认也是全局变量,因此在函数外部使用echo命令调用函数内部变量func_var是可以正常显示的,而global_var2参数值在函数中被修改了,最终脚本输出的也是修改后的内容。
但是,这样的结果有时并不是我们希望看到的。在一个实际工程脚本文件中,有时会因为在函数外部和函数内部定义了相同名称的变量,从而导致数据被意外篡改!如何防止在函数内部修改函数外部的全局变量呢?可以通过local语句定义仅在函数内部有效的局部变量
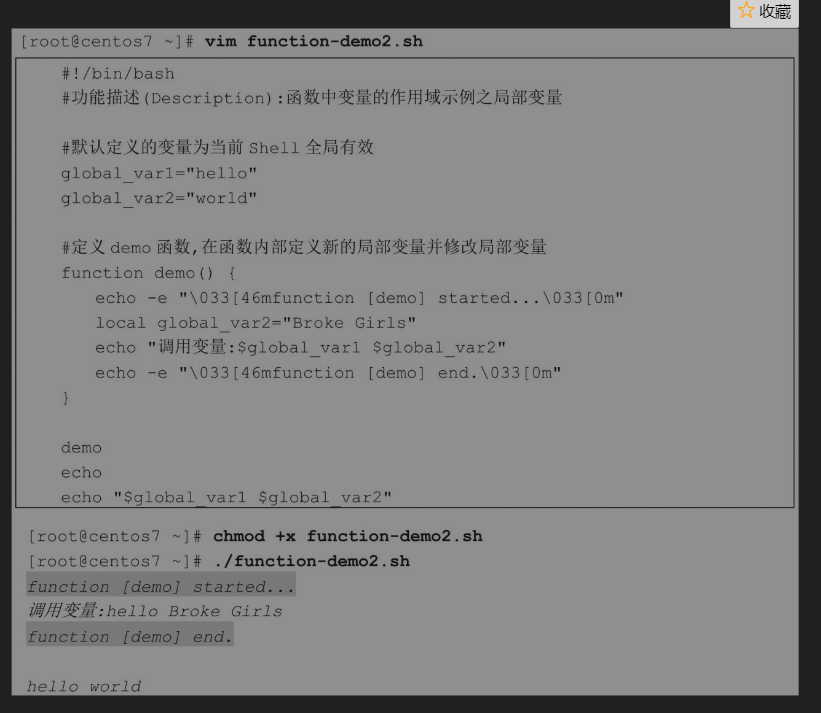
分析执行结果,首先在脚本开始时定义了两个全局变量global_var1和global_var2,然后在函数内部使用local命令定义一个与全局变量重名的局部变量global_var2,并设置新的变量值,但是这样并不会覆盖全局变量的值。在函数内部调用变量global_var1时,因为在函数内部没有与之重名的变量,所以直接显示全局变量的值。而在函数内部调用变量global_var2时,因为在函数内部定义了与全局变量重名的global_var2,系统会优先调用函数内部的局部变量,所以输出的结果为Broke Girls。最后当函数执行结束时,在函数外部再次使用echo命令调用global_var1和global_var2变量,并不会受函数的任何影响,输出结果仍然是全局变量的值:hello world。
正常情况下定义的普通变量和数组都是在当前Shell中有效的全局变量。但是使用declare定义的关联数组则是一种特殊情况,在函数外部定义的关联数组为全局变量,而在函数体内部定义的关联数组则默认是在函数内部有效的局部变量。
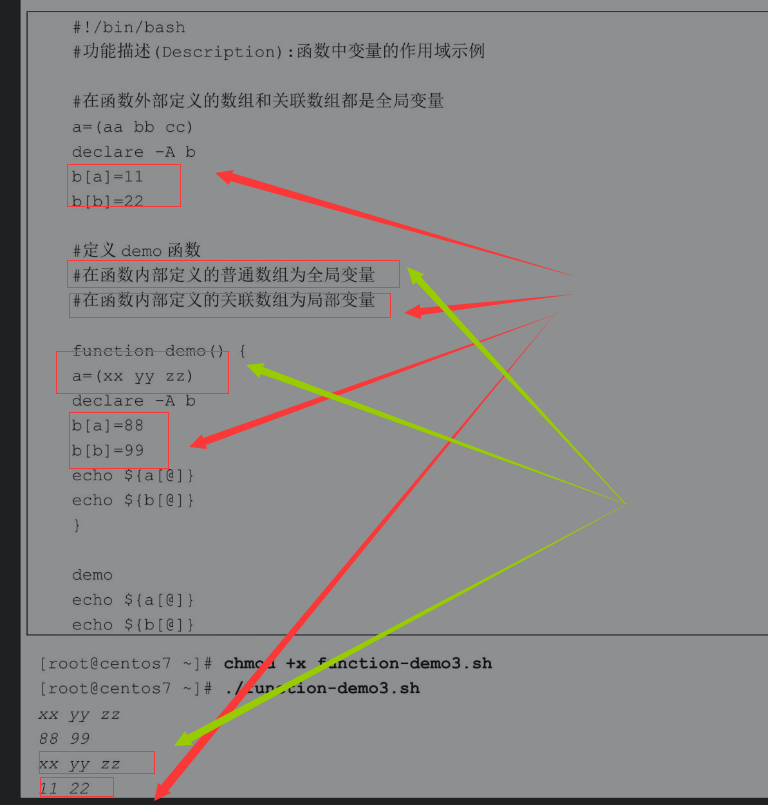
分析脚本执行结果,在函数体外定义的普通数组变量a和在函数体内定义的普通数组重名,因为默认情况下都是全局变量,所以数组变量a的值被覆盖,不管在函数内部还是外部,屏幕显示的都是覆盖后的新值(xx yy zz)。而关联数组是个特例,在函数外部定义的关联数组b为全局变量,虽然在函数内部也定义了同名的关联数组变量,但是仅在函数内部调用数组b时才显示88和99,在函数外部调用数组b时显示的结果依然是11和22。
最后还有一个注意事项,定义函数不会导致函数被执行,因此在没有调用函数时,无论是全局变量还是局部变量,都不可以在外部和内部之间相互调用。
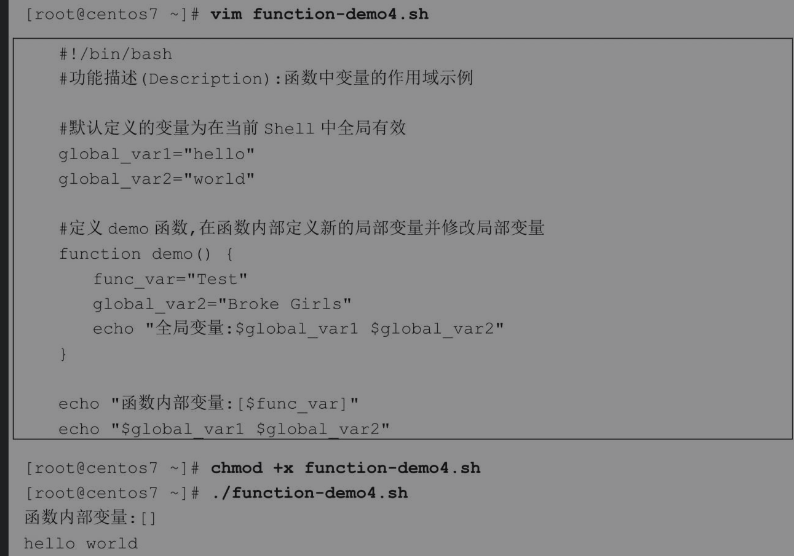
分析脚本执行结果,在这个示例中仅定义了函数,但并没有调用函数,因此在函数内部定义的变量func_var及对变量global_var2的修改实际上都没有被执行。当在函数外部使用echo命令调用func_var时实际就是空值,global_var1和global_var2变量的值也没有任何变化,最后的输出结果为hello world。
执行完函数后,默认整个函数的状态码为函数内部最后一个命令的返回值。我们在3.10节中学习了使用exit命令自定义返回码,但是在函数中如果使用了exit命令就会导致整个脚本直接退出。可以使用return命令立刻让函数中断并返回特定的状态码,并且不会影响脚本中后续的其他命令。
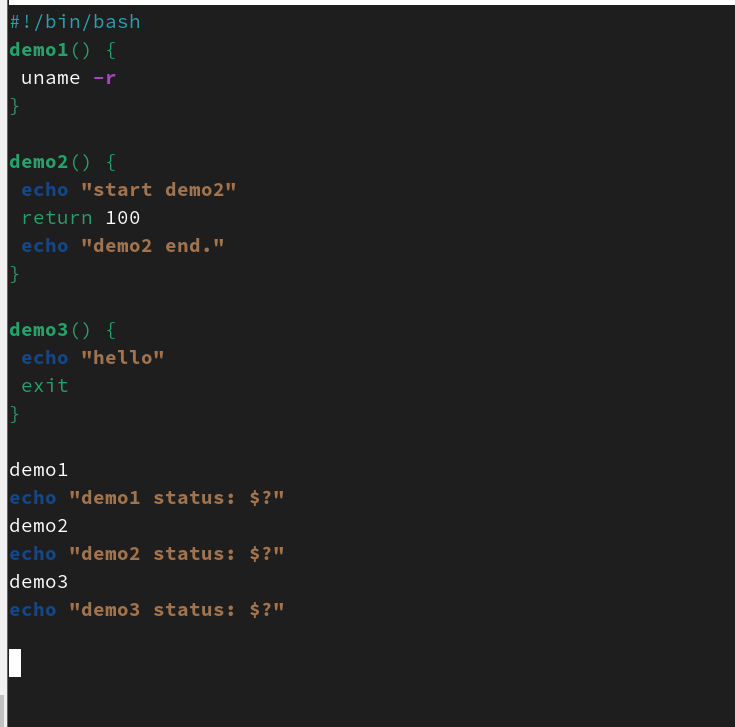
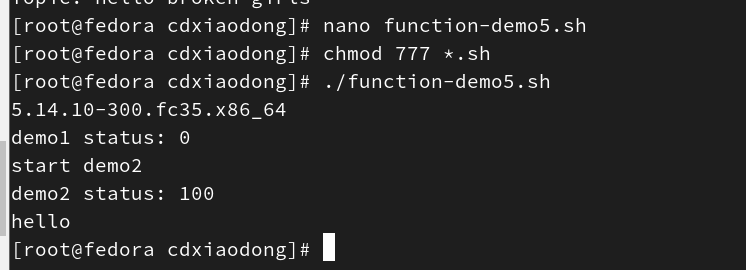
分析脚本执行结果,脚本中定义了三个函数,分别是demo1、demo2和demo3。demo1函数中没有自定义任何返回码,因此在脚本中调用demo1函数后,使用echo命令查看函数返回状态码为0(也就是函数内uname -r命令的返回码)。demo2函数使用return命令自定义的返回码为100,因为return会让函数立刻中断,所以调用demo2函数时,屏幕仅显示start demo2而不会显示demo2 end,调用完函数后,再通过echo命令查看函数的返回码为自定义的100。最后一个函数使用了exit命令,该命令不仅中断了函数,同时中断了整个脚本,因此调用demo3函数时,屏幕显示hello,然后整个脚本意外中断,并没有执行后续的echo命令,也没有显示demo3函数的返回码。
4.8 实战案例:多进程的ping脚本
前面已经使用循环语句编写过ping某个网络内所有主机连通性的脚本,但是当时的脚本并没有使用函数,也没有使用&符号开启后台子进程脚本,所以整个脚本的执行效率非常低。现在学习了函数及子Shell的知识,就可以重新优化编写功能更强大、效率更高的ping测试脚本了。
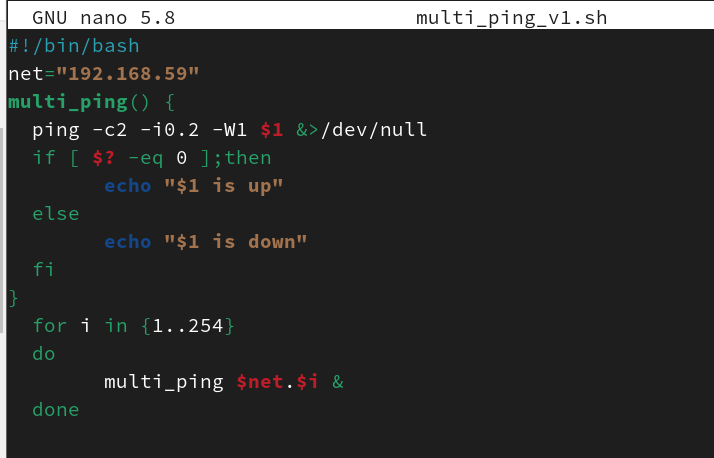
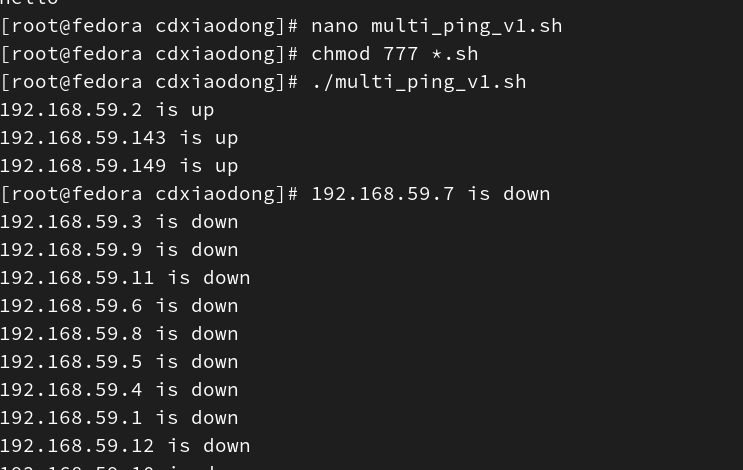
真的很快
分析脚本执行结果,因为在循环体中是以后台方式执行multi_ping函数的,所以不再需要等待第一台主机测试完成后再测试下一台主机,瞬间就可以将254台主机的测试任务都放入后台执行。屏幕的返回结果是无序的,谁先回应ping消息,屏幕就先返回谁的信息。
这样的脚本仅耗时几秒就可以测试整个网段。但是,这个脚本还是有问题!脚本瞬间将254个进程放入后台,脚本瞬间已经把所有需要执行的命令都执行完毕,然后脚本退出。所以在执行完脚本后的一瞬间,当脚本中的命令执行完后系统就返回命令行,而在系统返回命令行后,还在后台执行ping的命令会开始慢慢返回执行结果(可以连通或不能连通的信息),因此192.168.4.6 is up这个信息就显示在命令提示符的后面。更大的问题是,其实脚本执行的一瞬间就返回命令行,但是254个ping返回全部结果却需要几秒,等所有返回结果都显示在屏幕上后,屏幕就有可能宕机!因为系统早已返回命令行,命令行的提示符也已经在脚本执行后的一瞬间返回并显示了,这样就需要手动执行一个回车操作才可以继续后面的其他操作。出现这样的问题就是因为脚本退出的速度太快,解决这个问题可以使用wait命令,该命令后如果输入进程号作为参数,可以等待某个进程或后台进程结束并返回该进程的状态。如果没有指定任何参数,则wait会等待当前Shell激活的所有子进程结束,返回状态为最后一个进程的退出状态。
我们可以继续优化上面的脚本,在脚本最后添加一个wait命令,这样可以在所有的后台子进程都结束,也就是所有的ping测试都结束后,再退出脚本。
4.9 控制进程数量的核心技术——文件描述符和命名管道
经过前面的优化,一个多进程的脚本基本已经成型。但还有问题需要解决,在执行多进程脚本的同时在其他终端窗口使用ps aux命令查看进程列表,会发现同时启动了几百个进程,对于ping这样的小程序还好,如果是一个非常消耗CPU、内存、磁盘I/O资源的程序呢?启动几百个这样的程序并行执行,系统会瞬间崩溃!

我们需要想办法控制进程的数量,比如一次仅启动10个进程,等待这10个进程都结束再启动10个,依此类推。如何控制进程的数量呢?这里需要引入文件描述符和命名管道的概念
1)文件描述符
文件描述符是一个非负整数,而内核需要通过这个文件描述符才可以访问文件。当我们在系统中打开已有的文件或新建文件时,内核每次都会给特定的进程返回一个文件描述符,当进程需要对文件进行读或写操作时,都要依赖这个文件描述符进行。文件描述符就像一本书的目录页数(也叫索引),通过这个索引可以找到需要的内容。在Linux或类UNIX系统中内核默认会为每个进程创建三个标准的文件描述符,分别是0(标准输入)、1(标准输出)和2(标准错误)。通过查看/proc/PID号/fd/目录下的文件,就可以查看每个进程拥有的所有文件描述符。
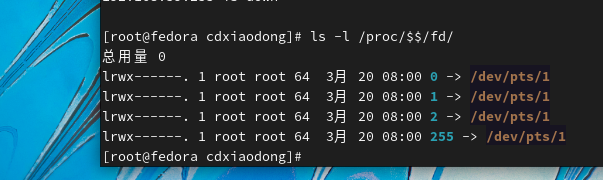
查看当前shell的文件描述符
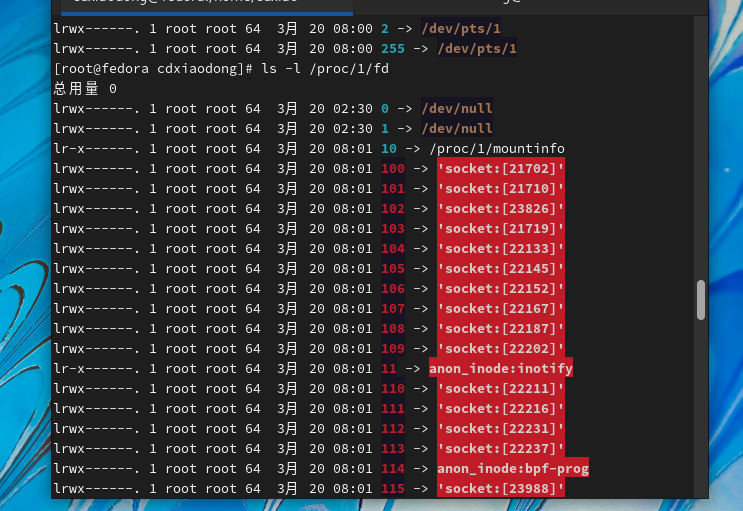
查看system的文件描述符
当打开文件时系统内核就会为特定的进程自动创建对应的文件描述符。下面通过示例演示这样一个过程,首先开启一个命令终端,在命令行中使用nano打开任意一个文件。
同时开启第二个终端窗口,通过ps命令查看vim进程的进程号,并观察该进程的文件描述符。
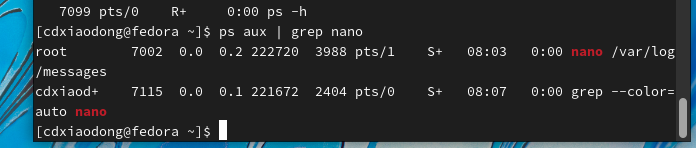

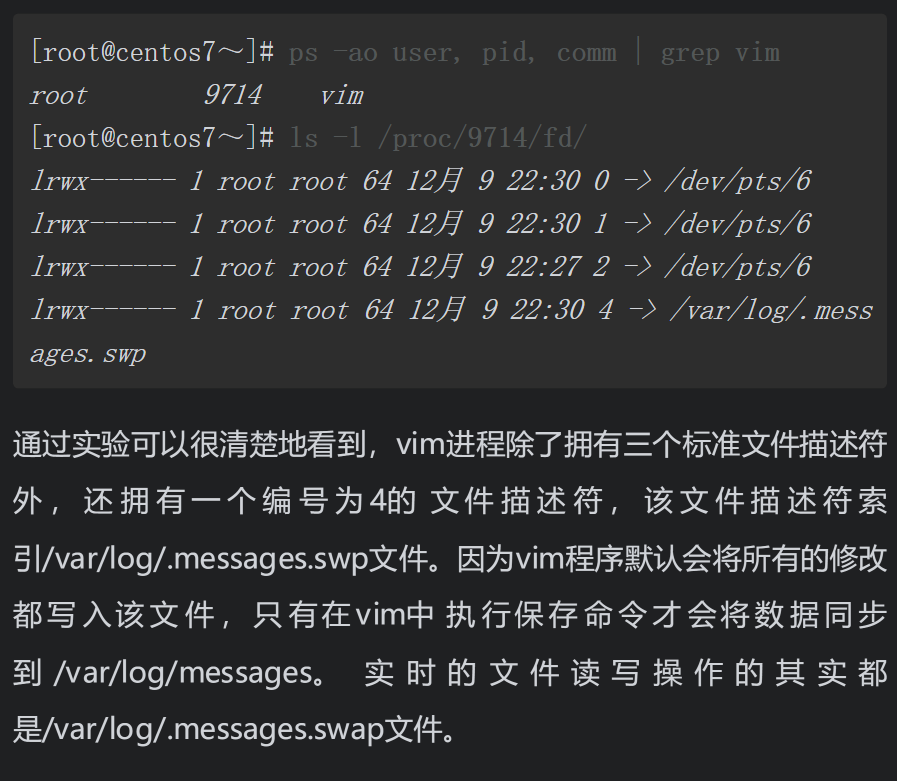
除了系统自动创建文件描述符,还可以通过命令手动自定义文件描述符。
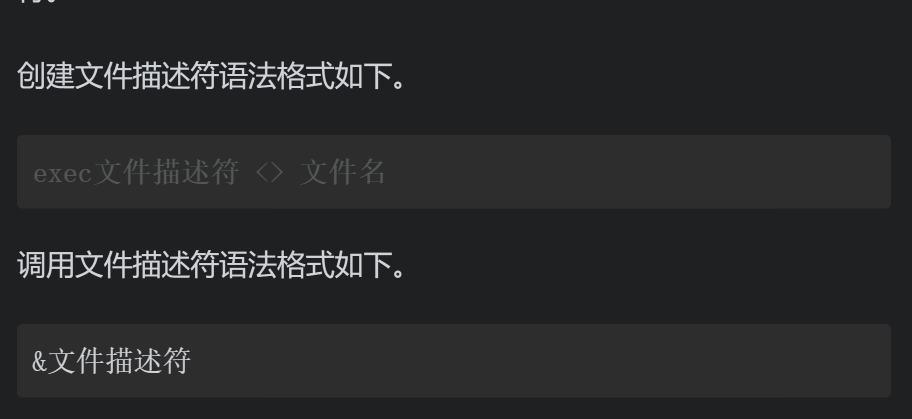
关闭文件描述符语法格式如下。

创建只可重定向输出的test文件
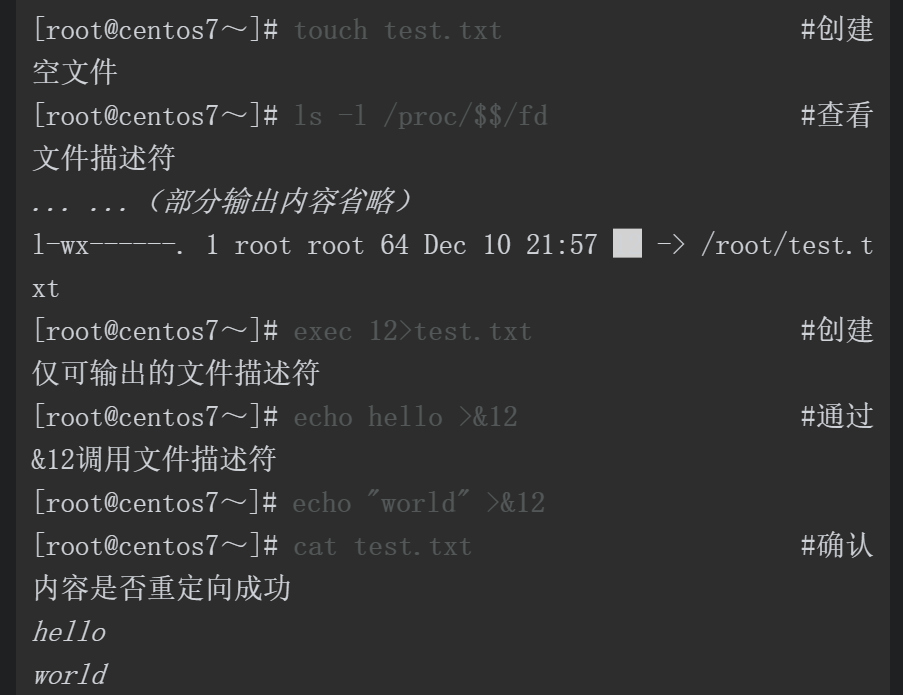
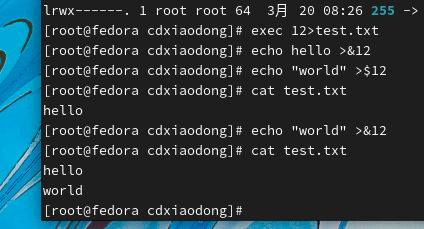
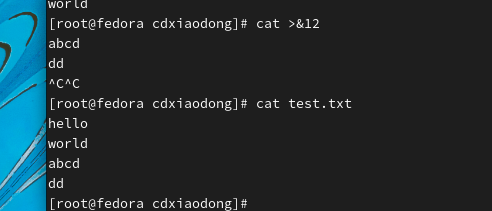
还能给在命令中调用它


关闭文件描述符

关掉后就用不了了
上面案例中首先创建了一个仅可以重定向输出的文件描述符(12),可以通过&12调用该文件描述符,使用echo将消息重定向输出到12这个文件描述符就等同于输出到文件test.txt。但是,当调用该文件描述符进行重定向导入时会失败,该文件描述符不支持重定向输入。
创建只可重定向输入的test文件
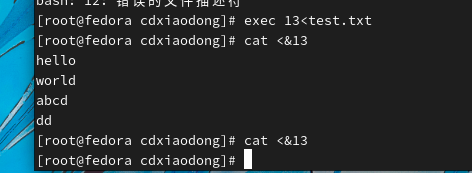
注意:文件仅能被输出一次 后面想要继续输出的话得再次exec 13<test.txt。但是重定向输出的文件可以被输入很多次

同样 重定向输入的文件不支持输出
关闭的话也就是<与>的差别
能不能创建一个既可以输出又可以实现输入功能的文件描述符呢?答案是可以的!
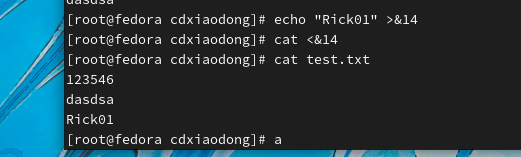
但是同样的 我们的重定向输入的文件仅可以被输出一次
关闭的话只要一个exec 14<&-就够了
下面看一个非常容易导致数据丢失的案例,在生产环境中如果不注意这样的问题,有可能会付出惨痛的代价。
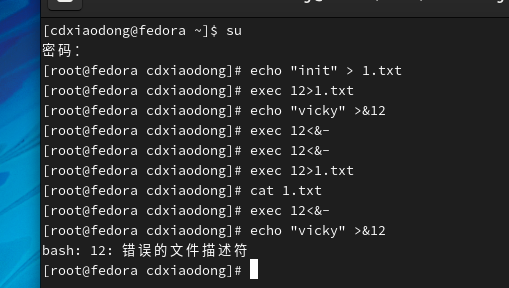
可以看到 关掉文件描述符的话用>或者<都可以
继续继续
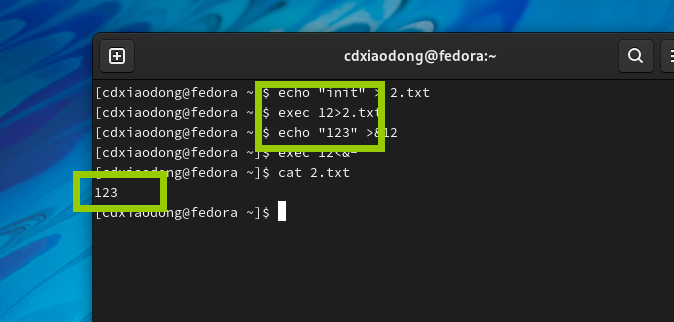
可以看到这样原数据会丢失
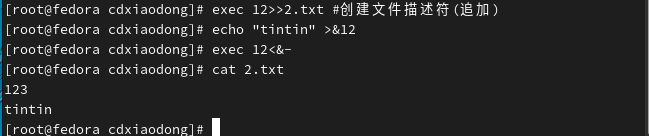
这样数据就不会覆盖
使用cat命令可以通过文件描述符读取文件的全部内容。另外,read命令后跟-u选项也可以通过文件描述符读取文件内容,但不同的是,read命令每次仅读取一行数据。通过下面的演示,再多学习一些文件描述符的细节技术。
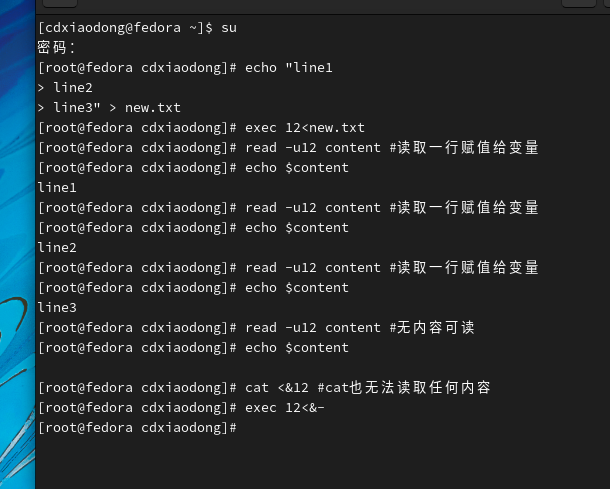
从上面这一系列的操作演示中,我们要理解,文件描述符并不是简单地对应一个文件的。文件描述符中还包含有很多文件相关的信息,如权限、文件偏移量等。文件偏移量更像一个指针,它指向某个文件的位置,默认情况下该指针指向的是文件的起始位置,当使用read命令读取一行数据后,该指针会指向下一行数据,再使用read读取一行内容,指针再往下移动一行,依此类推,直到文件结束。通过文件描述符读取文件行的流程如下图所示。

因为cat命令会读取文件的全部内容,所以当我们使用cat命令读取文件描述符时,文件描述符的指针会一次性跳到文件的末尾,一旦到了文件末尾,则再通过文件描述符读取文件的内容就为空,因为没有内容可读了。但是可以重新打开文件描述符,还可以再次从开始位置读取数据内容。
同样的道理,也可以每次仅读取文件的任意个字符。这样的话,指针就会停留在特定字符的后面,等待下一次再通过文件描述符读取文件内容时,就会继续从这个位置读取后续的内容。read命令可以通过-n选项指定读取任意字符的数据。

值得注意的是 每当一个行的所有字符读完后
下一次read -u12 -n 都是空白的 然后在下一次运行才会继续读取(只针对 read -u12 -n)
不仅查看内容会导致指针移动,写入数据同样也会导致指针移动。通过文件描述符追加写入数据后,就不能再查看了,因为指针已经移动到了文件末尾的位置。
创建文件描述符时,如果文件描述符对应的文件不存在,系统会自动创建一个新的空文件。
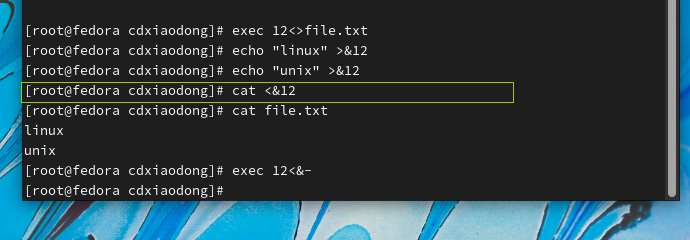
可以看到通过文件描述符查看为空
面的操作,先开启一个可读写的文件描述符,然后通过重定向输出的方式往文件中写入两行数据,同时文件描述符中的偏移量指针也随之往下移动。当使用文件描述符读取数据时,指针已经移动到最后,此时再使用cat命令查看文件后续内容则为空,但是前面写入文件的内容不会丢失,使用文件名的方式直接访问,数据都还在。
2)命名管道
接下来,学习命名管道的知识。管道是进程间通信的一种方式,前面已经介绍了匿名管道,使用|符号就可以创建一个匿名管道,顾名思义,系统会自动创建一个可以读写数据的管道,但是这个管道并没有名称。一个程序往管道中写数据,另一个程序就可以从管道中读取数据。但是匿名管道仅可以实现父进程与子进程之间的数据交换,能不能实现任意两个无关的进程之间的通信呢?答案是肯定的,使用命名管道,也叫FIFO文件。
命名管道具有如下几个特征。
1 | |

创建命名管道,不指定权限

创建命名管道,并指定全年

查看文件属性 第一列为P

写阻塞(特征 无法返回输入框)
使用echo命令将数据重定向导入管道,因为暂时没有其他进程从管道中读取数据,所以写数据的echo命令被阻塞。
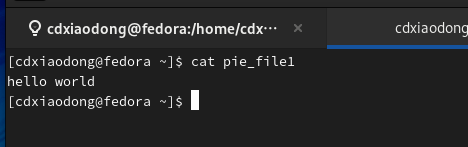

开启另一个命令终端窗口,执行读操作时,回到第一个窗口写阻塞会自动被解除(特征:返回输入框)。
与上面的演示类似,反之当从命名管道中读取数据时,如果管道中并没有数据,读进程会被阻塞。因为前面的操作已经将pie_file1中的数据读出,此时管道中已没有任何数据。

可以看到被阻塞
我们开启另一个命令终端窗口,执行写操作时,再回到第一个窗口读阻塞会自动被解除。


可以看到本来那个窗口回显123并且解除
说了这么多文件描述符与命名管道的铺垫,该进入正题了,对于多进程的脚本如何控制进程的数量呢?通过命名管道的阻塞功能就可以有效地阻止开启过多的进程!但是只有命名管道还不够,正常情况下cat命令读取命名管道数据会一次性全部读完,这里需要每次仅读取一行数据,而read命令通过文件描述符就可以读取文件的行数据。

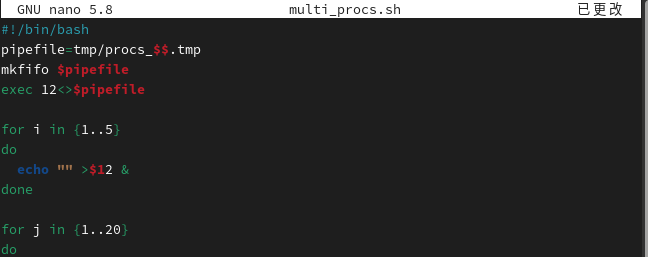
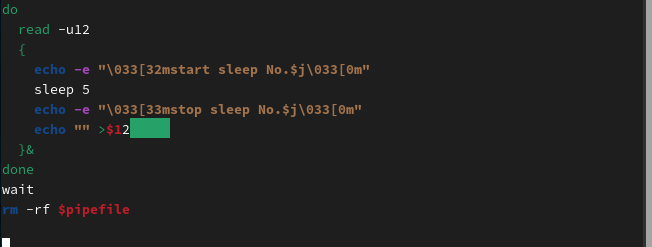
有了这样的技巧可以控制进程数量后,就可以再次修改前面的ping测试脚本,实现一个可以任意控制进程数量的多进程ping测试脚本。
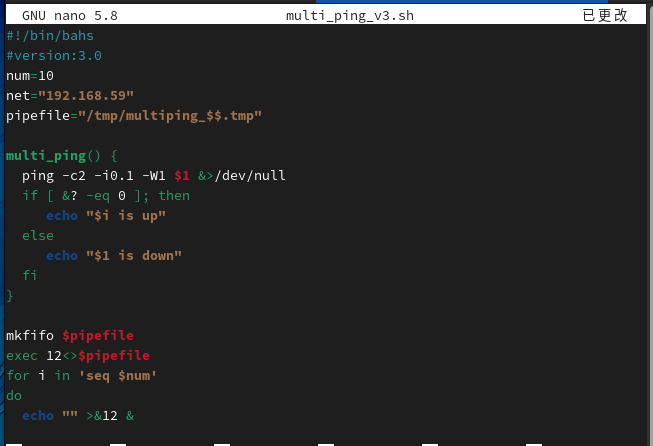


虽然这样速度很慢

而且还得再搞个重新排列 把报错弄掉
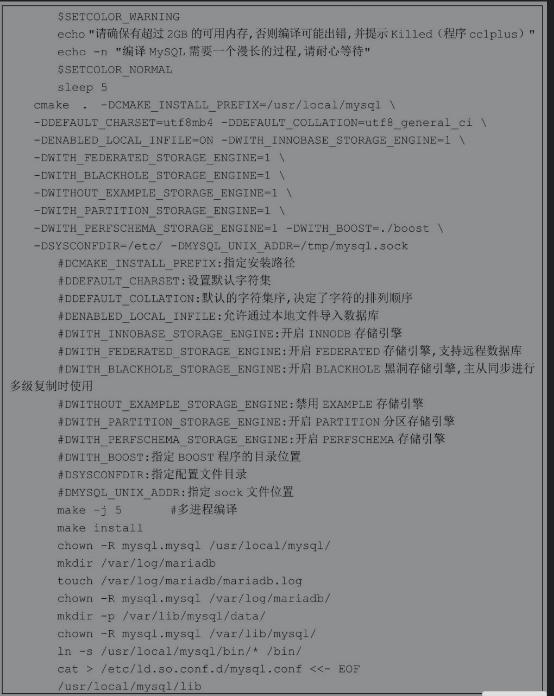
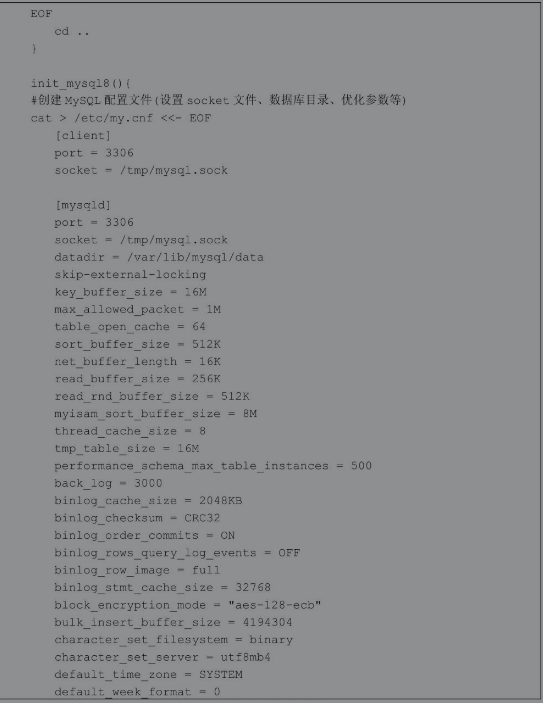
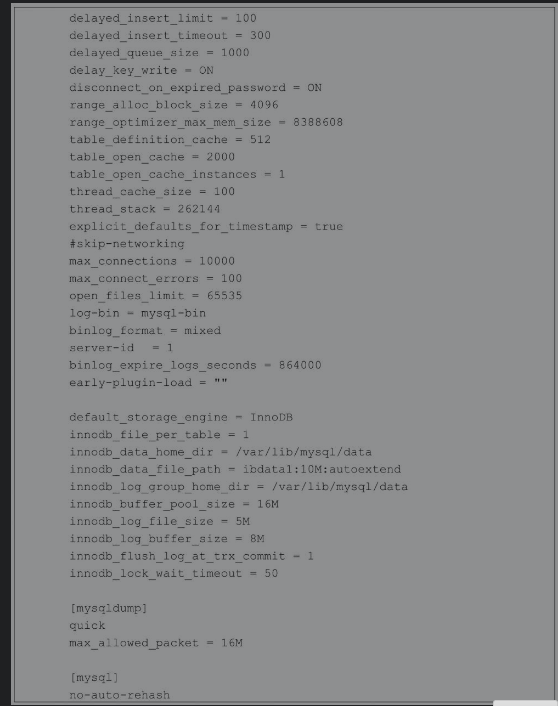
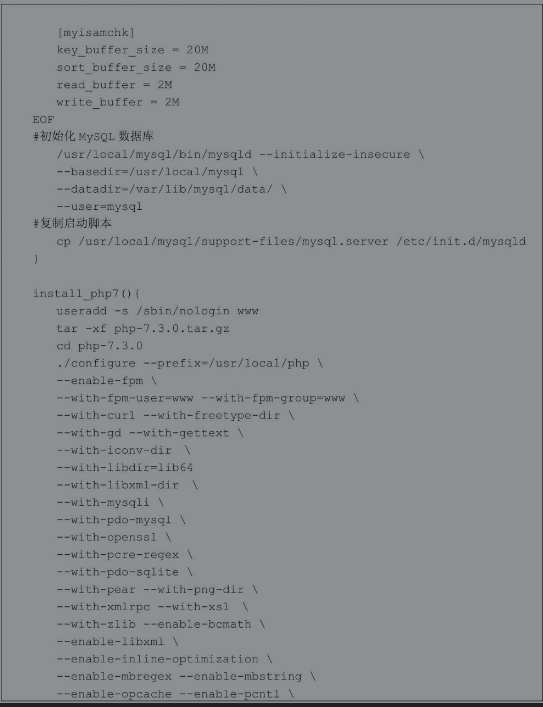
4.10 实战案例:一键源码部署LNMP的脚本
在生产环境中为服务器安装部署软件包是运维人员非常重要的一项工作,一般可以通过RPM、YUM或者源码安装部署软件包。这些方式中源码包安装方式具有很多RPM所不具备的优势,比如可以自定义安装路径、自定义模块、获得更新的版本等,但是,使用源码包安装软件往往也是最复杂的一种方式。怎么办呢?我们即需要源码包的灵活性,又不希望每次安装都很麻烦。在生产环境中一般都会选择将源码包的安装步骤写入脚本,实现一键安装软件包的功能,也有部分企业是将源码自定义制作成个性化的RPM包。
下面的案例以使用源码部署目前比较主流的LNMP环境为例,编写一个自动化部署脚本。实现这样的脚本需要编写大量的代码,如果没有函数,脚本会显得杂乱无章,本案例会使用函数的方式编写。
首先通过变量设置一些颜色属性,方便在脚本运行过程中给使用者恰当颜色的信息提示。然后测试系统的YUM源是否可以使用,如果没有YUM源则无法完成源码包相关依赖软件的安装,如果YUM源可用就可以通过install_deps函数安装LNMP相关的依赖软件包。最后就是定义一系列的函数进行源码包的安装、修改配置文件、生成systemd启动配置文件。
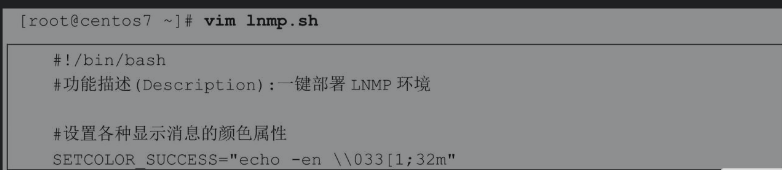


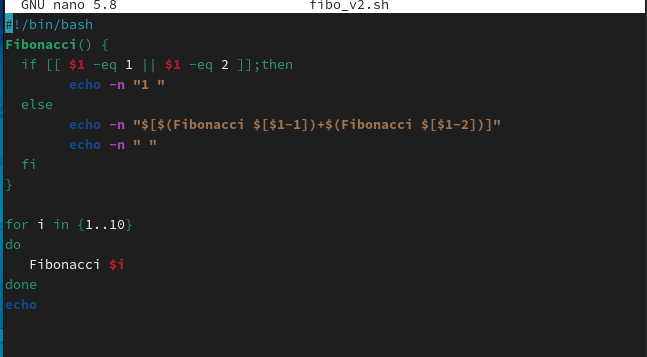
4.11 递归函数
一个会自己直接或间接调用自己的函数称为递归函数。下面用递归函数的方式再次编写一个求斐波那契数列的和的脚本。

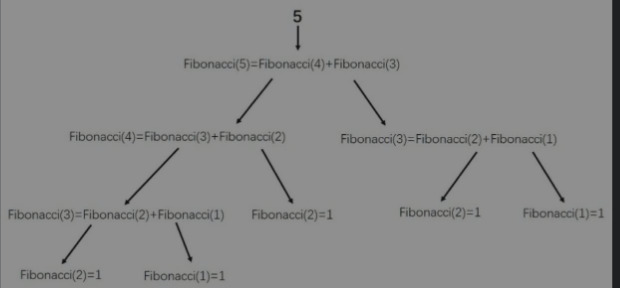
需要注意的是,因为递归函数会自己调用自己,如果不设置任何退出机制,就会变成死循环递归调用,所以一般都需要设置一个条件,当条件触发后就结束递归。另外一个需要注意的是,递归函数仅当递归结束后,之前启动的调用函数才会依次关闭,如果递归次数特别多,会有大量的函数被反复调用而不关闭,非常容易导致内存中的数据溢出,进而导致程序出错。上面的脚本随着计算数量的增大计算性能会降低,
如图4-9所示,如果想得到第五个斐波那契数,就需要将前面所有的斐波那契数重新计算一遍,所以在可使用循环解决的问题中应该尽量避免过多使用递归函数,在一些不需要递归计算的环境中可以考虑使用递归函数。
4.12 排序算法之冒泡排序
对数据进行分析时经常需要进行排序处理,比如按占用CPU的时间对进程排序、按出现的次数频率对数据排序、按大小对数据进行排序等。对数据的排序可用使用sort命令,也可尝试自己编写排序脚本,自定义排序算法。常见的排序算法有很多,如冒泡排序、插入排序、选择排序、快速排序、堆排序、归并排序、希尔排序、二叉树排序等。
冒泡排序是一种比较简单的排序算法。冒泡排序不断地比较相邻的两个数据的大小,根据大小进行排序(升序或降序),如果顺序不对则彼此交换位置,依此类推,当所有的数据都比较完成后,一定可以找出一个最大或最小的值。通过彼此交换位置慢慢把大的或小的数据浮现出来,就像气泡浮出水面一样,所以这种算法被称为“冒泡排序”。如图4-10所示是冒泡排序的流程图。假设有7个待排序的数字,我们进行完第一轮的6次比较后一定能得出一个最大值,第一个数值冒泡出来。同理,第二轮进行5次[插图]比较后一定可以获得剩余所有数字中的最大值。依此类推,进行6轮这样的比较后,所有数据会按从小到大的顺序排列。

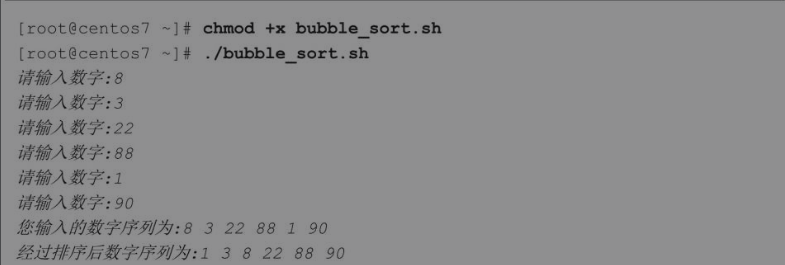
先写一个简单的6个数字排序的脚本,看看冒泡排序的代码如何实现。

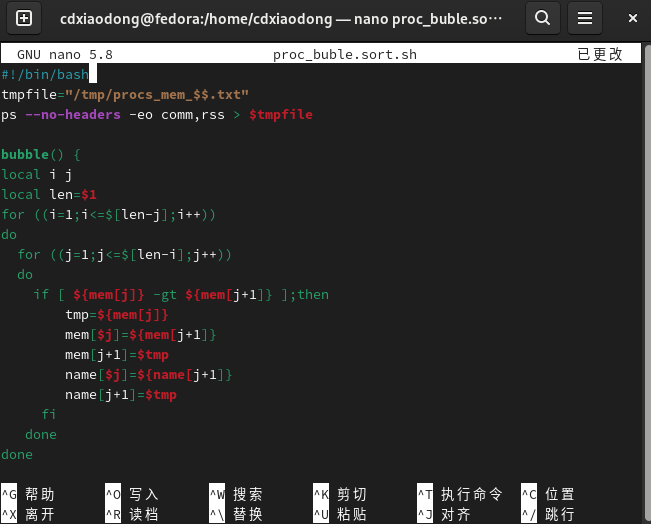
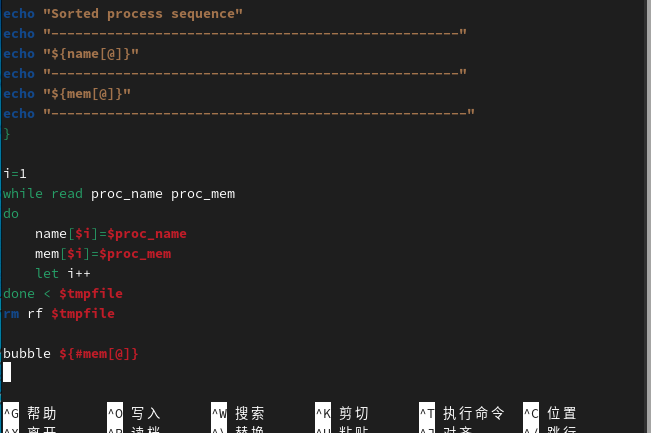
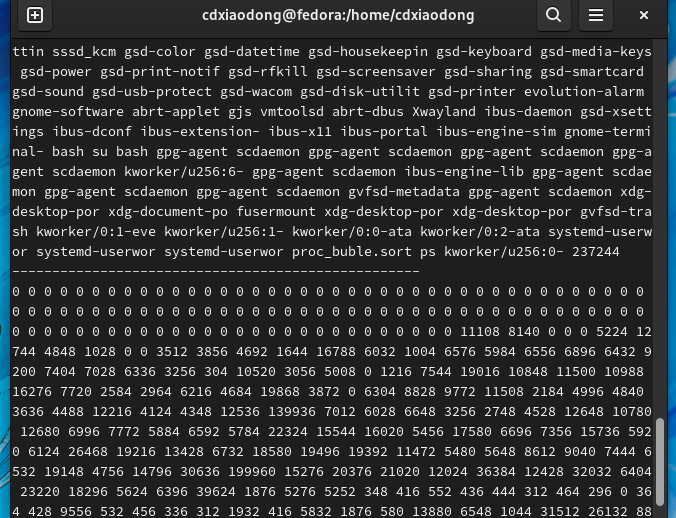
下面通过冒泡算法编写一个根据当前系统所有进程所占物理内存大小的排序脚本。

4.13 排序算法之快速排序
快速排序简称快排,是在冒泡排序的基础上演变出来的算法。这种算法的主要思想是挑选一个基准数字,然后把所有比该数字大的数字放到该数字的一边,其他比该数字小的数字放到该数字的另一边,然后递归对该基准数字两边的所有数字做相同的比较排序,直到所有数字都变为有序数字。快速排序的效率取决于挑选的基准数字,如果基准数字是一个比较折中的数字,则基准数字两边就比较均衡,这样比较的次数就会大大减少。如果基准数字偏大或偏小,就会导致基准数字两边的数字个数不均衡,最终需要进行数字比较的次数依然很多。通常我们会选择第一个元素或最后一个元素作为基准数字。
下面一起看看如何使用Shell脚本实现快速排序算法。
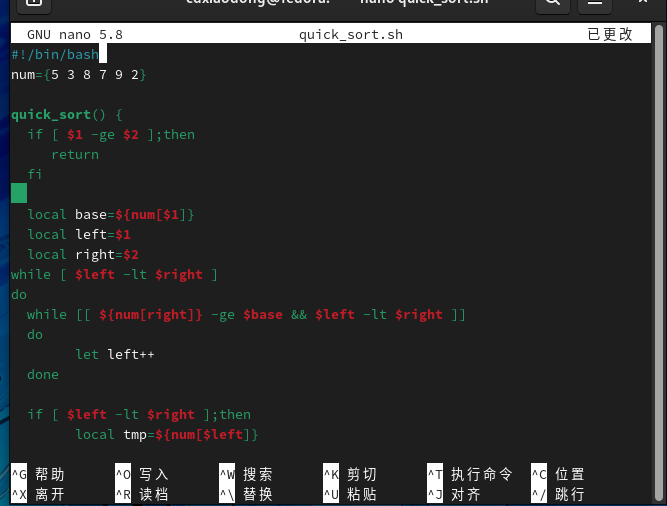

4.14 排序算法之插入排序
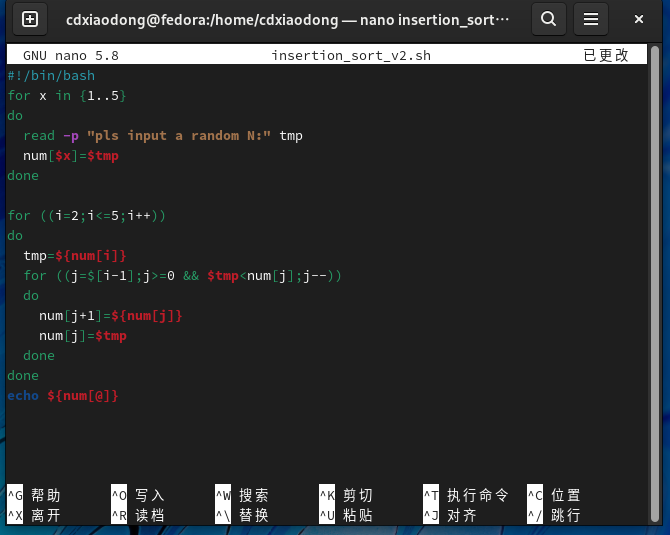
插入排序顾名思义就是提取一个数字后,对已排序的数字从后往前依次比较,选择合适的位置插入。这种算法的优点是,任意一个数字可能不需要对比所有数字就可以找到合适的位置,当然最差的情况也有可能需要对比所有数字后才能确定合适的位置。

4.15 排序算法之计数排序
前面学习的算法中无论是冒泡排序还是快速排序都是基于比较进行排序的,还有一种特殊的排序算法是不需要进行比较的,名为计数排序。这种排序算法的核心思想就是多创建一个数组,用于统计待排序数组中每个元素出现的次数。该算法的核心理念如图4-14所示,2、1、2、7、3、8是需要排序的数字,这个数字序列中的最大值为8,需要额外创建一个计数数组count,该数组有9个下标,分别为count[0]~count[8], count数组中所有元素的初始值为0,接着用待排序数组的元素值,作为计数数组的下标进行自加运算。如第一个数为2,就执行count[2]++,第三个待排序的数还是2,就再执行count[2]++。依此类推,使用count数组统计所有待排序数字出现的次数。最终,根据count数组元素的值打印对应的下标即可,如count[0]的值是0,就不打印,count[1]的值是1就打印一次1,count[2]的值是2就打印两次2,所有下标打印完就完成了数字的排序工作。
写一个可以自动分析待排序数组的最大值,自动创建计数数组赋初始值,最终实现排序功能的完整代码案例。

第5章 一大波脚本技巧正向你走来
5.1 Shell八大扩展功能之花括号
Shell脚本支持七种类型的扩展功能:花括号扩展(braceexpansion)、波浪号扩展(tilde expansion)、参数与变量替换(parameter and variable expansion)、命令替换(commandsubstitution)、算术扩展(arithmetic expansion)、单词切割(word splitting)和路径替换(pathname expansion)。这些扩展技巧在编写脚本时非常有用。
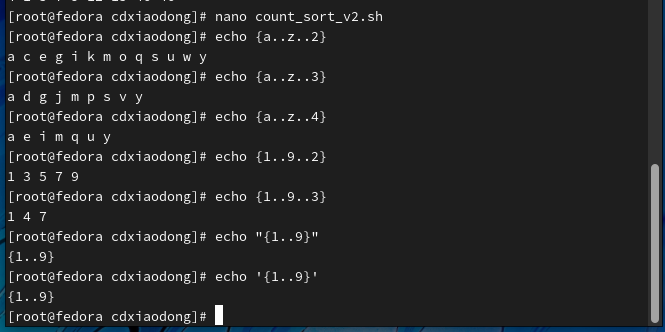
在Shell脚本中可以使用花括号对字符串进行扩展。我们可以在一对花括号中包含一组以分号分隔的字符串或者字符串序列组成一个字符串扩展,注意最终输出的结果以空格分隔。使用该扩展时花括号不可以被引号引用(单引号或双引号),在括号的数量必须是偶数个。

字符串序列后面可以跟一个可选的步长整数,该步长的默认值为1或-1。
使用花括号扩展时在花括号前面和后面都可以添加可选的字符串,且花括号扩展支持嵌套。
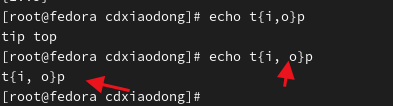
注意:花括号内两个字符的中间不能有空格,不然会原符号输出
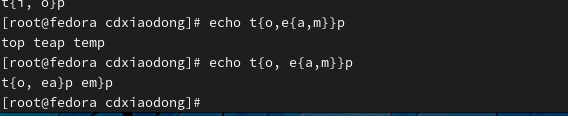
上面例子看出来花括号支持嵌套。
但是有意思的是再嵌套内添加空格 则添加空格的那一层会原符号输出,其他层则继续套接
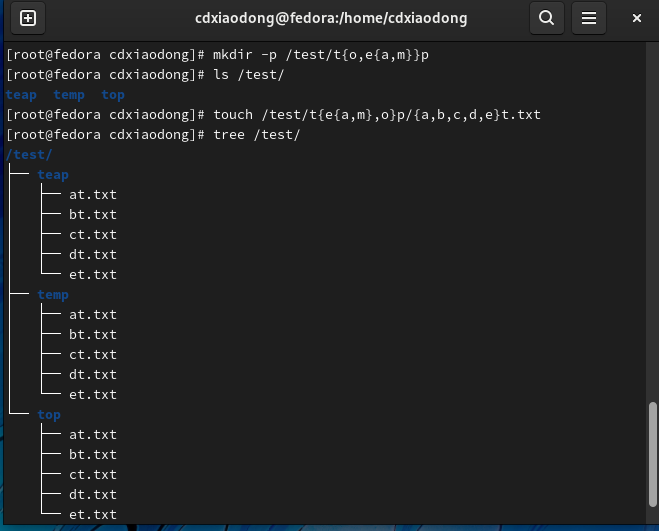
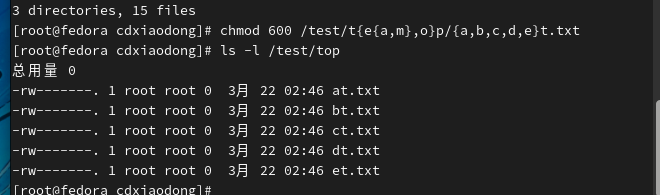

利用扩展备份文件

利用扩展重命名
5.2 Shell八大扩展功能之波浪号
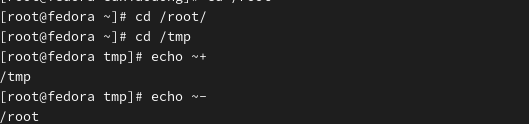
波浪号在Shell脚本中默认代表当前用户的家目录,我们也可以在波浪号后面跟一个有效的账户登录名称,可以返回特定账户的家目录。但是,注意账户必须是系统中的有效账户。
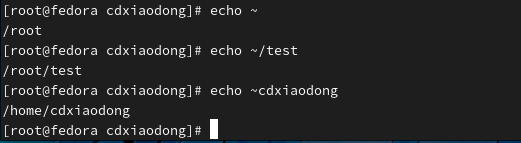
波浪号扩展中使用~+表示当前工作目录,~-则表示前一个工作目录。
5.3 Shell八大扩展功能之变量替换
在Shell脚本中我们会频繁地使用$对变量进行扩展替换,变量字符可以放到花括号中,这样可以防止需要扩展的变量字符与其他不需要扩展的字符混淆。如果$后面是位置变量且多于一个数字,必须使用{},如$1、${11}、${12}。

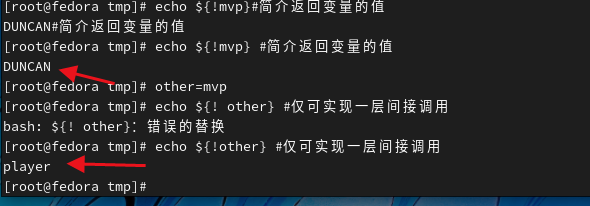
如果变量字符串前面使用感叹号(!),可以实现对变量的间接引用,而不是返回变量本身的值。感叹号必须放在花括号里面,且仅能实现对变量的一层间接引用。

变量替换操作还可以测试变量是否存在及是否为空,若变量不存在或为空,则可以为变量设置一个默认值。Shell脚本支持多种形式的变量测试与替换功能,变量测试具体语法如下表

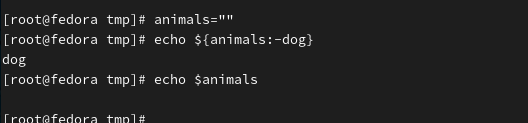
变量animals未定义,因此使用echo返回变量的结果为空。

根据变量替换的规则,当变量未定义或者变量定义了但是值为空时,返回关键字dog。但也仅仅返回关键字dog,不会因此改变animals的值,所以animals的值还是空。

我们再通过示例验证一下即便定义了animals变量,但值为空时,依然会返回关键字。
不管变量未定义还是变量的值为空,下面的示例都会返回关键字并且会修改变量的值。

而当变量的值为非空时,这种扩展将直接返回变量自身的值。

偶尔,我们还可以使用变量替换实现脚本的报错功能,判断一个变量是否有值,没有值或者值为空时就可以返回特定的报错信息。

再看一个与前面相反的结果,当变量有值且非空时,返回关键字,而当变量没有定义或值为空时,则返回空。

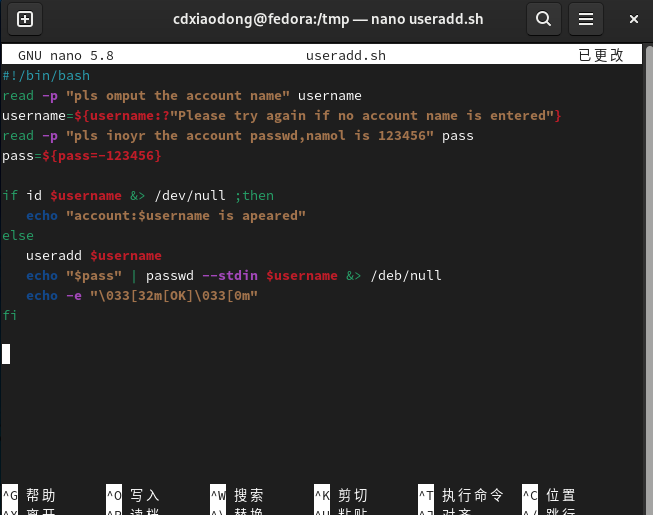
前面章节中我们已经编写了几个创建系统账户并配置密码的案例,结合这里我们学的变量替换功能,还可以继续对脚本进行优化,实现更多的功能。
变量的替换就这些吗?当然不是!变量替换还有非常实用的字符串切割与掐头去尾功能
字符串切割与掐头去尾具体语法

这几种对变量的替换方式,都不会改变变量自身的值
首先定义一个变量home,变量的偏移量从0开始递增,分别表示变量值每个字符的位置。示例中变量home的具体位置偏移量如下图所示。


从给定的位置偏移量开始对变量进行切割,如果设置了特定的长度,则截取给定长度的值后结束,如果没有指定截取的长度,则直接截取到变量的末尾。

从位置2开始截取到变量末尾

从位置14开始截取6个字符后结束
下面通过几个示例介绍对变量的掐头和去尾操作。使用#可以实现掐头,使用%可以实现去尾。

从左往右将匹配的Th删除

变量开头无法匹配oak,返回原值

匹配y及其左边的所有内容删除
因为一个#表示最短匹配,所以执行上面的命令仅删除第一个y及其左边的所有内容。
如果需要做最长匹配,也就是一直找到最后一个指定的字符,并将该字符及其前面的所有字符全部删除就需要使用两个#符号。


从右往左删除efs
从右往左删除,直到匹配d为止。一个%从右往左匹配到第一个d即停止,两个%也会从右往左匹配,但是要匹配到最后一个d才会停止

如果变量是数组类型的变量,这些扩展还有效吗?答案是肯定的,感慨Shell的强大!


根据数组的某个元素进行掐头操作


对数组的所有元素进行掐头
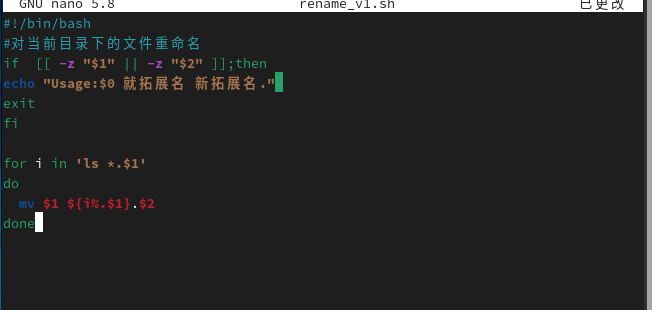
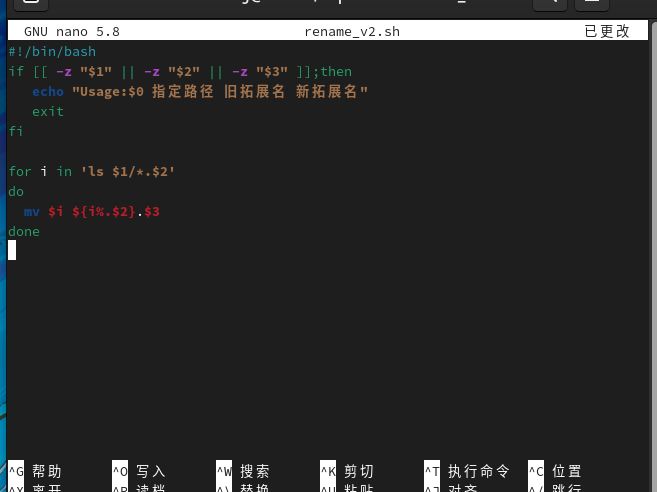
通过掐头去尾的方式可以实现对文件批量修改文件名或扩展名,下面是两个批量修改文件扩展名的案例。一个脚本是批量修改当前目录下的文件扩展名,另一个脚本是批量修改指定目录下的文件扩展名。
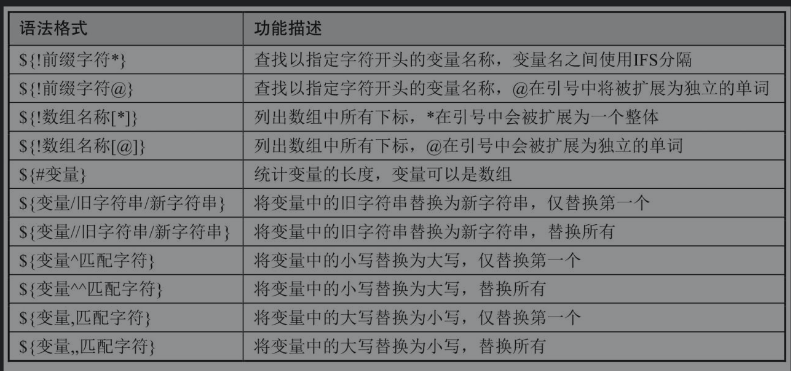
最后通过下表学习变量内容的统计与替换,通过这一组功能我们可以查找变量、统计变量内容的字符数及对变量内容进行替换操作。
变量内容的统计与替换

echo ${!x@}
echo ${!x*}列出已x开头的所有变量名
但是这两个也有差别
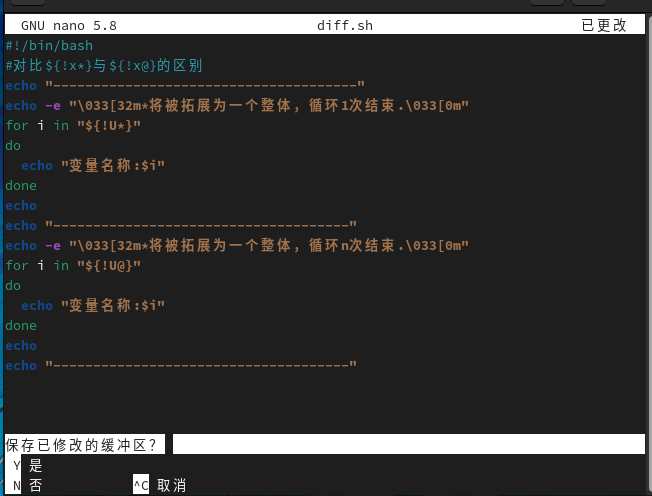
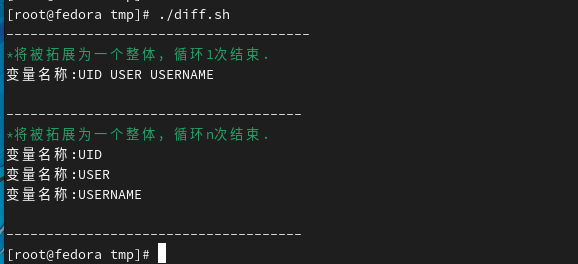

输出数组所有下标

declare定义关联数组

echo $